一种公文自动分办方法以及计算机设备与流程
本发明涉及一种公文自动分办方法以及计算机设备。
背景技术:
公文分办指由办公室文书或业务部门的负责人及有关人员对需要办理的公文提出建议性处理意见的参谋性活动。公文分办的意见能为领导决策提供支持。分办中对公文如何处理的建设性意见,是分办人系统研究、个人经验总结的成果,能为领导的批办提供初选方案。通过分办,能充分发挥文秘部门及其人员的工作积极性和主观能动性,提高其综合处理各种事务的能力,履行其辅助决策和参谋助手的职责。切实可行的分办意见能够方便领导批办公文时参考,能使领导的批办意见在拟办意见的基础上高度明确而具体,有助于节省领导人大量的时间和精力。
但是,传统的公文分办都是由人工判断来完成,根据个人的经验,对公文的标题、来文单位、文号、正文内容等信息进行判断,决定公文应该发给具体的某个部门或者领导,主观随意性较大,当分办人员变更时,相关的分办经验难以传承,容易出现分办纰漏的情况,无法辅助领导的决策。
技术实现要素:
本发明要解决的技术问题,在于提供一种公文自动分办方法以及计算机设备,对公文的标题、来文单位、文号、正文内容进行自动分析,增加分办规则库,实现公文内容与分办部门或领导的对应关系,若无法通过规则库匹配到,则通过机器学习技术对历史分办文件的分析,实现公文分办结果的自动推荐,解决分办结果人工判断不准确的问题。
本发明之一是这样实现的:一种公文自动分办方法,包括:
步骤1、根据历史公文,建立分办规则库;
步骤2、根据历史公文,建立语义关联模型文件;
步骤3、在公文分办时,将当前公文根据规则库进行匹配,若匹配成功,则根据匹配结果进行分办;若匹配不成功,则提取当前公文的关键字,通过查询语义关联模型文件得到匹配结果,之后根据匹配结果进行分办。
进一步地,所述步骤1进一步具体为:根据历史公文,建立公文的标题、来文单位、文号以及意见内容与领导以及部门的关联关系,完成建立分办规则库。
进一步地,所述步骤2进一步具体为:根据历史公文,通过hanlp自然语言技术处理得到关键字,之后采用语义分析引擎word2vec将关键字进行处理,得到语义关联模型文件。
进一步地,所述步骤2进一步具体为:从所述历史公文中提取语料,根据提取的语料通过hanlp自然语言技术对历史公文进行处理得到关键字,之后采用语义分析引擎word2vec将关键字进行处理,得到语义关联模型文件。
进一步地,所述步骤3中所述提取当前公文的关键字进一步具体为:根据hanlp自然语言处理技术提取当前公文的关键字。
本发明之二是这样实现的:一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现以下步骤:
步骤1、根据历史公文,建立分办规则库;
步骤2、根据历史公文,建立语义关联模型文件;
步骤3、在公文分办时,将当前公文根据规则库进行匹配,若匹配成功,则根据匹配结果进行分办;若匹配不成功,则提取当前公文的关键字,通过查询语义关联模型文件得到匹配结果,之后根据匹配结果进行分办。
进一步地,所述步骤1进一步具体为:根据历史公文,建立公文的标题、来文单位、文号以及意见内容与领导以及部门的关联关系,完成建立分办规则库。
进一步地,所述步骤2进一步具体为:根据历史公文,通过hanlp自然语言技术处理得到关键字,之后采用语义分析引擎word2vec将关键字进行处理,得到语义关联模型文件。
进一步地,所述步骤2进一步具体为:从所述历史公文中提取语料,根据提取的语料通过hanlp自然语言技术对历史公文进行处理得到关键字,之后采用语义分析引擎word2vec将关键字进行处理,得到语义关联模型文件。
进一步地,所述步骤3中所述提取当前公文的关键字进一步具体为:根据hanlp自然语言处理技术提取当前公文的关键字。
本发明具有如下优点:一种公文自动分办方法以及计算机设备,采用本方案进行收文拟办、分办工作,提升了信息服务质量,有效提升了收文拟办、分办工作效率30%,同时固化了岗位工作经验,避免因工作岗位变动及人员轮岗导致的工作错误及公文办理效率降低。
附图说明
下面参照附图结合实施例对本发明作进一步的说明。
图1为本发明方法执行流程图。
图2为本发明具体实施方式结构框图。
具体实施方式
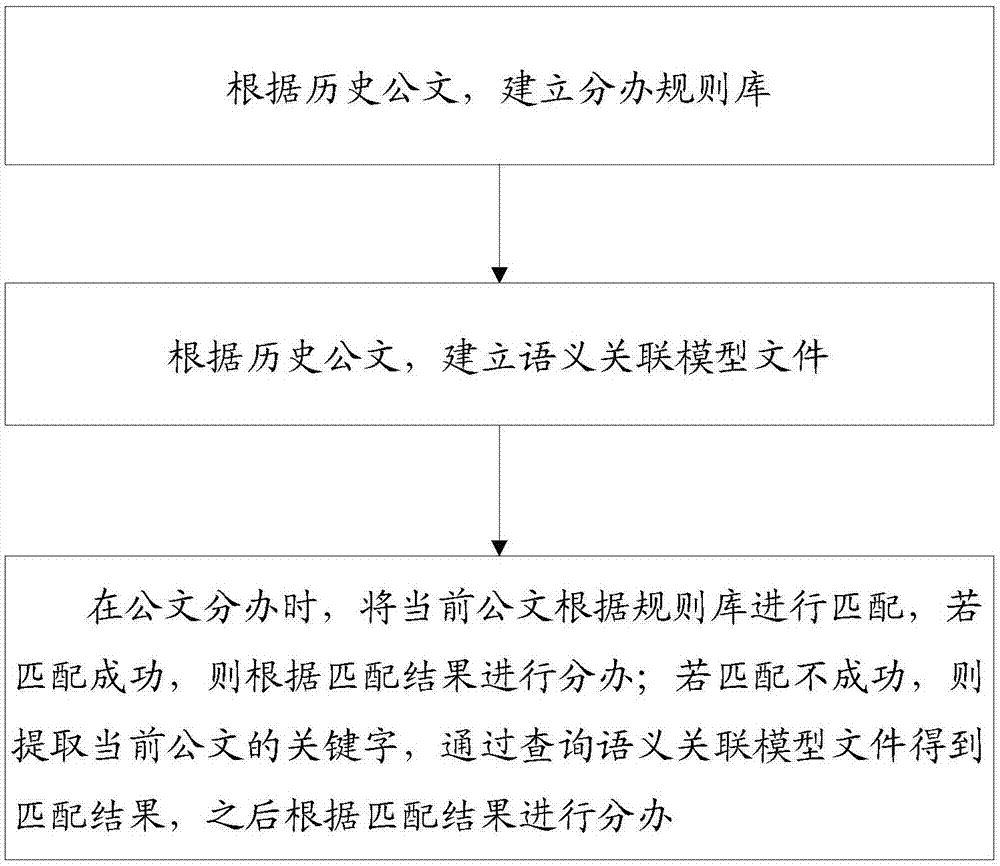
如图1所示,本发明公文自动分办方法,包括:
步骤1、根据历史公文,建立公文的标题、来文单位、文号以及意见内容与领导以及部门的关联关系,完成建立分办规则库;
步骤2、从所述历史公文中提取语料,根据提取的语料通过hanlp自然语言技术对历史公文进行处理得到关键字,之后采用语义分析引擎word2vec将关键字进行处理,得到语义关联模型文件;
步骤3、在公文分办时,将当前公文根据规则库进行匹配,若匹配成功,则根据匹配结果进行分办;若匹配不成功,则根据hanlp自然语言处理技术提取当前公文的关键字,通过查询语义关联模型文件得到匹配结果,之后根据匹配结果进行分办。
如图1所示,本发明计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现以下步骤:
步骤1、根据历史公文,建立公文的标题、来文单位、文号以及意见内容与领导以及部门的关联关系,完成建立分办规则库;
步骤2、从所述历史公文中提取语料,根据提取的语料通过hanlp自然语言技术对历史公文进行处理得到关键字,之后采用语义分析引擎word2vec将关键字进行处理,得到语义关联模型文件;
步骤3、在公文分办时,将当前公文根据规则库进行匹配,若匹配成功,则根据匹配结果进行分办;若匹配不成功,则根据hanlp自然语言处理技术提取当前公文的关键字,通过查询语义关联模型文件得到匹配结果,之后根据匹配结果进行分办。
本发明一种具体实施方式:
如图2所示,运用于电力领域时,该系统主要解决公文分办结果的自动推荐,优先通过分办的规则库进行推荐,当通过规则库无法匹配至结果时,则使用机器学习的推荐技术。具体操作步骤:
(1)建立分办规则库,建立公文的标题、来文单位、文号、意见内容等与领导、部门的关联关系。
(2)从海量的历史公文的非结构化数据中提取出语料,对每一条历史公文正文进行分析处理,通过hanlp自然语言处理,经过去停用词、滤重、中文分词、词性标注等处理后,抽取出关键词,形成一个个分词文本,采用自然语言处理技术对分词文本进行概念发现、实体抽取、领域分词,再通过语义分析引擎word2vec将分词文本进行关联计算、关系抽取最终形成适合办公业务领域的语义关联模型文件。
(3)公文分办时,优先使用规则库进行匹配,若无法匹配至部门或领导,则采用机器学习的推荐方式。
(4)抽取出当前登记公文的标题、来文单位、正文内容等数据,进行分词抽取,并提交至近义词服务,通过查询语义模型文件,返回相关度较高的、词性为机构名称的近义词将出现频率较高的机构名称进行排序计算,最终分析出推荐的收文部门。
虽然以上描述了本发明的具体实施方式,但是熟悉本技术领域的技术人员应当理解,我们所描述的具体的实施例只是说明性的,而不是用于对本发明的范围的限定,熟悉本领域的技术人员在依照本发明的精神所作的等效的修饰以及变化,都应当涵盖在本发明的权利要求所保护的范围内。
- 还没有人留言评论。精彩留言会获得点赞!