一种基于强化学习网络训练的自动泊车方法与流程
本发明涉及智能汽车自动泊车规划技术领域,尤其是涉及一种基于强化学习网络训练的自动泊车方法。
背景技术:
传统采用轨迹规划和轨迹跟踪的自动泊车系统,因为可能存在轨迹跟踪误差、执行器控制误差、以及环境扰动等状况,导致规划的轨迹和实际的轨迹不一致,泊车效果不佳。强化学习是一种端到端的控制算法,强化学习理论上将跟踪和控制环节的误差考虑在了模型的策略之中,从而理论上跟踪和控制误差造成的负面影响。但是强化学习的建模和训练需要一定的经验和技巧,考虑到车载控制器的处理性能,强化学习网络的输入为相对自车的库位角点坐标,输出为方向盘转角、油门、刹车控制指令。现有技术中的强化学习的训练结果不稳定,且训练收敛速度不佳,存在大量试错和陷入局部最优的可能。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种训练结果稳定、提高收敛速度的基于强化学习的自动泊车方法。
本发明的目的可以通过以下技术方案来实现:
一种基于强化学习网络训练的自动泊车方法,该方法包括下列步骤:
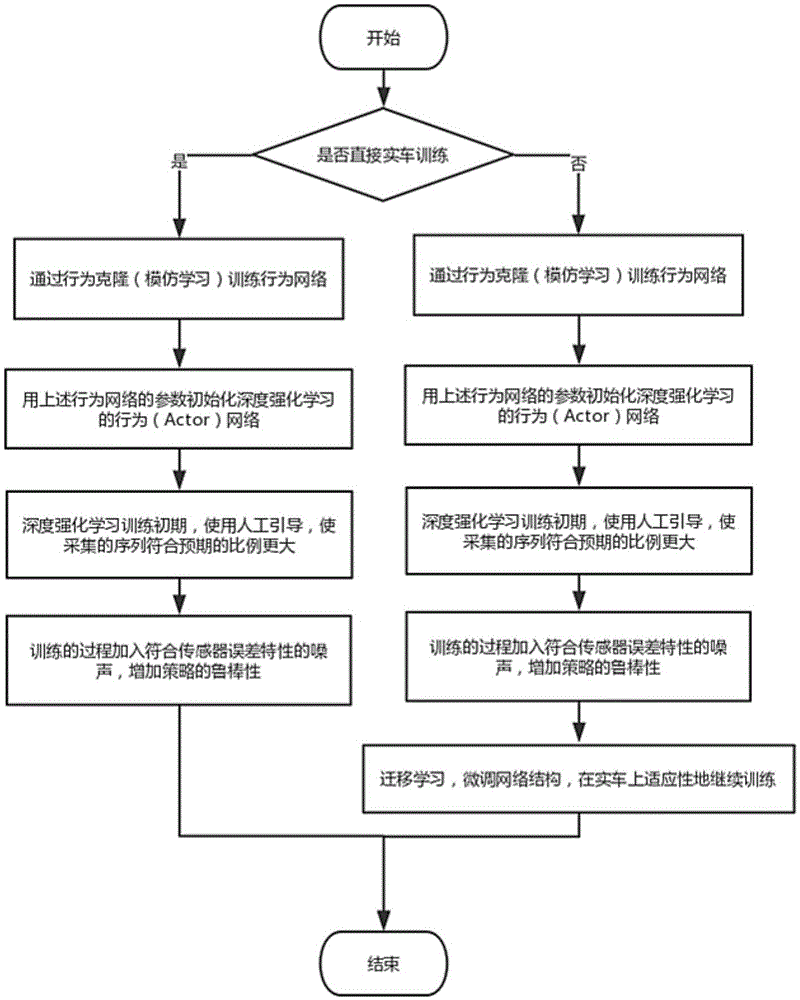
s1:对待泊车的车辆判断是否直接进行实车训练,若是,则执行步骤s2后进入步骤s6,否则,执行步骤s3后依次进入步骤s4、s5、s6。
优选地,可根据需要选择是否直接进行实车训练,因实车训练具有一定的危险性,同时耗时较久,若先进行仿真训练再进行实车训练有利于加速训练过程。
s2:针对自动泊车工况建立强化学习网络模型,并对强化学习网络进行训练,获取与车辆控制对应的驾驶策略模型,将车辆与库位的相对位姿及车辆的状态信息作为驾驶策略模型的输入,输出车辆的控制指令。
s3:针对自动泊车工况建立强化学习网络模型,并对强化学习网络进行仿真训练,获取与车辆控制对应的驾驶策略模型。具体包括以下步骤:
301)通过行为克隆训练行为网络,获取行为网络参数;
302)利用获取的行为网络参数对深度强化学习网络的行为网络进行初始化;
303)在深度强化学习的训练初期阶段进行经验序列积累,针对车辆相对库位的初始位姿人工设定控制指令,并对人工设定的控制指令叠加噪声;
304)在深度强化学习的训练过程中对输入的状态量中叠加符合传感器误差特性的噪声。
优选地,所述的深度强化学习网络采用ac网络、ddpg网络、dpg网络或ppo网络。
当采用ac网络时,将步骤301)的行为网络训练获取的参数初始化深度强化学习ac网络中的行为网络。
当采用ddpg网络时,将步骤301)的行为网络训练获取的参数初始化深度强化学习ddpg网络中的行为网络和目标行为网络。
优选地,所述的经验序列包括当前观察环境信息、所选择的动作信息、动作回报信息和下一观察环境信息。
优选地,所述的状态量包括当前环境信息、车辆的状态信息及位姿信息。
s4:采用迁移学习,在仿真训练获取的驾驶策略模型的最后添加一层或替换原强化学习网络的最后一层,并在实车上继续进行适应性训练。
s5:完善驾驶策略模型,将车辆与库位的相对位姿及车辆的状态信息作为驾驶策略模型的输入,输出车辆的控制指令。具体包括以下步骤:
501)车辆在当前的环境和状态下,基于驾驶策略信息执行相应的驾驶操作,确定回馈函数值;
502)通过回馈函数的设置,控制车辆与其所处环境发生交互的循环过程,调整车辆的驾驶策略信息,逐步训练并完善与车辆控制对应的驾驶策略模型;
503)将车辆与库位的相对位姿及车辆的状态信息作为驾驶策略模型的输入,输出车辆的方向盘转角控制指令、油门控制指令及刹车控制指令。
s6:根据驾驶策略模型输出的车辆的控制指令对车辆进行泊车控制。
与现有技术相比,本发明具有以下优点:
(1)本发明提供了从仿真训练迁移到实车使用的思路,避免了大量试错和陷入局部最优的可能的问题,且能够提高本发明方法的应用性;
(2)本发明在训练过程中,对深度强化学习的训练过程中输入的状态量加入符合传感器误差特性的噪声,增强了模型输出的鲁棒性;
(3)本发明在人工设定的控制指令的基础上加上一定的噪声便于探索更优秀的策略,使得在采集的状态行为反馈序列库中,相比采取随机探索,会有更大比例的反馈,进而能够让训练更快地实现收敛,此外,本发明使用了行为克隆进行预训练,可进一步提了训练收敛速度。
附图说明
图1为本发明实施例中强化学习应用于自动泊车场景的建模和训练方法的流程示意图。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。
实施例
基于强化学习的训练过程不局限为某一具体强化学习算法,而是基于actor-critic(演员-评论家)的这一类别的强化学习算法。为了较为具体地介绍,本实施例以ddpg(deepdeterministicpolicygradient,深度确定性策略梯度)为例对本发明方法进行说明。
本发明涉及一种基于强化学习网络训练的自动泊车方法,该方法包括以下步骤:
步骤1:对待泊车的车辆判断是否直接进行实车训练。
若直接进行实车训练,则执行步骤2),进行构建强化学习网络模型并进行训练;若不直接进行实车训练,则按步骤2)进行仿真训练后,进行迁移学习,将训练后的模型应用于实车。
因为直接上实车进行强化学习训练需要耗费大量的人力、时间和资源,所以先在仿真环境中训练再将迁移到实车是更优的选择。但是因为仿真环境中,车辆模型、传感器模型等物流模型可能和现实中不一致,即使相同的控制指令所产生的结果(下一观察)都是不一样的,因此需要对仿真训练好的深度强化学习网络模型进行迁移学习训练,具体执行方法可以选择在原ddpg的actor(行为)网络和targetactor(目标行为)网络中的最后再添加一层,或去除原来的最后一层网络,再替换一层随机初始化的网络,或不改变网络结构;在上述操作结束后,进行实车的强化学习训练。
步骤2:针对自动泊车工况建立合适的强化学习网络模型,并对强化学习网络进行训练。
首先通过轨迹规划加轨迹跟踪的方式,使车辆在不同的初始位姿下能够准确泊入库位的经验序列库,并利用经验序列库,采用行为克隆(模仿学习)的方法训练bp神经网络,bp神经网络的输入为库位相对车辆的位姿和车辆的状态信息,输出为车辆控制指令,例如方向盘转角和车速。
在上述训练完成后,获取bp神经网络的行为网络参数,并应用该参数权值初始化ddpg的actor网络和targetactor网络,并随机初始化ddpg的critic(评论家)和targetcritic(目标评论家)网络。
在深度强化学习网络训练之前,需要先进行探索,用来积累初始的经验序列库,经验序列包括当前观察、所选择的动作、回报和下一观察。这个探索过程可以加以人工引导,例如,通过专家经验,针对当前观察选择一个合适的动作(控制指令),在此控制指令的基础上叠加适当程度的噪声给予模型探索更好策略和试错的空间,但又能够保证一定概率上生成符合预期的经验序列。这样可以缩短强化学习在初期探索的试错探索时间,使强化学习训练的自动泊车控制指令尽快收敛到符合正常驾驶预期的控制指令。
在进行深度强化学习的训练过程中,采用off-policy(离线训练策略),为了加速训练进程,可以在训练初期采集经验序列(s,a,r,s’)的时候,加以人工引导,即不采取随机试探,而是针对自车相对库位的初始位姿,人工设定一系列的控制指令,使车辆能够较好地泊入库位中。因为在实际过程中,观察是带有噪声的,因此可以在强化学习的训练过程中,对观察的数据加上符合传感器误差特性的噪声,在这个人工设定的控制指令的基础上加上一定的噪声便于探索更优秀的策略。这样在采集的状态行为反馈序列库中,相比采取随机探索,会有更大比例的反馈是较好的,这样可以让训练更快地收敛到优秀的策略。例如,仿真过程中,库位角点相对自车的坐标可能是不带误差的,而实际实车上,库位角点可能是通过环视相机检测得到的,而环视相机检测目标的坐标带有高斯误差,则应该在仿真训练过程中对库位角点坐标加上高斯噪声。
在对仿真训练好的深度强化学习网络模型进行迁移学习训练时,对获取的驾驶策略模型进行完善,即通过回馈函数的设置,控制所车辆与其所处环境发生交互的循环过程,调整车辆的驾驶策略信息,从而逐步训练并完善与车辆控制对应的驾驶策略模型。
步骤3:训练结束,将车辆与库位的相对位姿及车辆的状态信息作为驾驶策略模型的输入,输出车辆的控制指令。根据车辆的控制指令对自动泊车进行控制。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的工作人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!