一种基于统计分析的云数据中心服务异常根因定位方法与流程
本发明涉及一种基于统计分析的云数据中心服务异常根因定位方法,属于软件技术领域。
背景技术:
云数据中心时常会出现大规模服务降级和服务中断,从而严重影响服务可靠性与性能。服务性能衰减通常会表现为系统层的度量异常,以反映服务内部或底层基础设施中存在的问题,例如ddos攻击、服务升级以及工作负载激增带来的异常资源使用。虚拟化技术将应用服务整合到少量的服务器中以降低操作成本(如,能源消耗)并最大化资源使用。然而,基于虚拟化的资源共享会造成相同主机上共享资源的服务之间竞争有限的系统资源(如,计算、带宽或内存),从而造成性能衰减。因此,不断检测系统异常(如异常的资源行为)以防止服务降级,并通过快速控制意外服务中断来提高服务可靠性,成为云服务监测的主要目标。然而,云服务规模巨大、体系结构复杂性,以及工作负载呈现多样性和动态性,使得在线异常检测具有挑战性。首先,异常检测方法需要在不明确正常状态或异常定义的情况下,能够自动适应云服务行为的变化。此外,能够应对多个层次的云服务抽象,从而分析处理多个服务度量。
当前的异常检测方法通常基于假设分布预先定义度量的阈值(m.peiris,j.h.hill,j.thelin,s.bykov,g.kliot,andc.konig,“pad:performanceanomalydetectioninmulti-serverdistributedsystems,”in7thieeeinternationalconferenceoncloudcomputing.ieee,2014,pp.769–776.),然而,阈值对工作负载的变化非常敏感,并且很难扩展到数百个度量。某些方法基于统计学方法自动设定阈值(p.xiong,c.pu,x.zhu,andr.griffith,“vperfguard:anautomatedmodel-drivenframeworkforapplicationperformancediagnosisinconsolidatedcloudenvironments,”inproceedingsofthe4thacm/specinternationalconferenceonperformanceengineering.acm,2013,pp.271–282.),然而其分别考虑单个资源度量,忽略了度量之间依赖关系。某些方法建模资源使用率和工作负载之间的关联关系(t.wang,j.wei,w.zhang,h.zhong,andt.huang,“workloadawareanomalydetectionforwebapplications,”journalofsystemsandsoftware,vol.89,pp.19–32,2014.),然而其依赖于qos和资源度量之间的相关性。基于多变量统计的机器学习方法建立多个指标之间的关联(t.huang,y.zhu,y.wu,s.bressan,andg.dobbie,“anomalydetectionandidentificationschemeforvmlivemigrationincloudinfrastructure,”futuregenerationcomputersystems,vol.56,pp.736–745,2016.),但是当qos和工作负载度量无法获取时,该方法就难以适用。云计算运营商投入大量精力监测资源,发现异常的资源使用模式。然而,虚拟化云数据中心的复杂性对异常检测技术提出了要求:(1)非侵入,云服务提供者通常不知道租户的源码;(2)无监督学习,能够处理未分类为正常或异常的无标注数据;(3)在线自适应不断变化的系统行为,而不需要离线训练和人工干预。
技术实现要素:
本发明的原理:提出了一种基于统计分析的云数据中心服务异常根因定位方法,监测云数据中心节点的多维度资源度量,使用向量自回归模型预测节点的资源使用情况,通过比较度量预测值与监测值来检测云服务的度量异常,根据数据中心节点之间复杂依赖关系的知识建立依赖图,对组件异常程度进行排序以减少报警风暴。
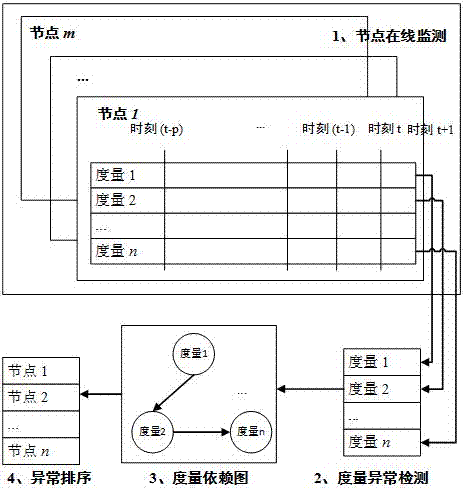
本发明技术解决方案:一种基于统计分析的云数据中心服务异常根因定位方法,如图1所示,实现步骤如下:
1.节点资源预测
本发明提出一种自适应向量自回归方法刻画基于滑动窗口的数据中心节点的序列化监测数据的资源使用模式,建模度量之间的关联关系,从历史数据中估计正常资源使用,用作预测近期的资源使用作为基准。
假设
其中,p表示滞后监测数据的数量,即需要考虑的此前监测周期数量,
需要确定模型中包含滞后监测数据数量p,该参数会影响模型的复杂性。由于滞后值会随时间改变,本发明使用长度为k的时间序列窗口,将历史资源使用进行分段,构建了基准训练模型,以在线方式更新模型。
假设
本发明定义最大滞后监测数据
其中,n表示度量数量,
给定训练集x,
当p在
2.节点异常资源检测
计算多维空间中预期残差的统计距离,作为识别异常数据点的依据,当检测到异常则发出警报。在每个时间点,本发明使用基准pw来检测异常时间点,预期下个时间周期的资源使用:
计算预测误差为监测与预测之间的差值:
检测异常资源使用的问题可以抽象为多元基于距离的离群点检测,使用预测误差到训练集中残差的统计距离以表示异常程度:
其中,
为了异常值计算具有鲁棒性,本发明使用协方差最小行列式估计协方差矩阵
使用min-max规范化e和
3.自适应模型演化
本发明由一系列长度为k的滑动窗口构建而成,每个窗口包含最新的监测数据以估计时变参数,如最优滞后数量
假设滑动窗口大小k,当k值较大,由于模型系数增加的时间平滑,会忽略数据中的瞬时变化。当k值较小,由于在时间窗口内未出现变量之间的时间相关性,会忽略数据中的动态变化。因此,k应该能够捕获数据中有用的时序变化以及变量间的动态依赖性。对于具有时间滞后数量为p和变量数量为n的预测模型,需要估计
4.全局异常资源排序
将所有警报从分布式节点合并,以固定周期进行异常报警,基于空间依赖性产生关联映射到异常或发现可能引起该异常的组件。由于节点之间具有依赖关系,表现为级联行为,例如,一个节点的异常资源使用可以传播到其他节点。虚拟化数据中心规模巨大,系统运维管理员会被多个警报所淹没,因此需要基于领域知识将警报或问题关联到数据中心内部或外部的依赖关系以隔离问题根源。此外,为了减少服务降级,自动化的云计算管理系统可以采取纠正措施,如通过自动伸缩调整资源容量或通过自动迁移实现跨数据中心的重新负载分配。同时,当警报太多,无法判断哪个警报更重要。因此,由于处理重要异常可能解决其他共同发生的警报,需要在集群级别自动对异常警报进行排序,以便于进行根源分析,从而提高纠正措施的效果。
本发明使用依赖关系图表示数据中心拓扑结构,描述了异常节点如何在给定的时间内与其他共同发生异常节点的关联关系,然后根据节点之间的因果关系对警报进行排序。景观图是一个有向无环图g=(v,e),其中,节点
附图说明
图1为方法步骤。
图2为部署实施环境。
具体实施方式
系统实施的部署环境如图2所示,包括web服务器、数据库服务器、监测代理、背景服务以及负载发生器,实施具体分为以下阶段:
(1)应用部署:物理机配置8个2.66ghzintelxeon处理器、16gb内存和250gb磁盘,虚拟化两台xen虚拟机(vm),分别部署web服务器apache2.0和数据库服务器mysql5.0。部署类似于e-bay的二层电子商务应用rubis(http://rubis.ow2.org/index.html),提供出售、浏览、出价等服务。
(2)数据采集:监测代理部署在云数据中心的虚拟基础设施的每个节点(vm和pm)上,基于unix的开源监测工具dstat(https://github.com/dagwieers/dstat)和psutil(https://pythonhosted.org/psutil/),以固定时间间隔采样(1分钟),实时监测计算、内存、磁盘io和网络资源等度量。
(3)负载生成:使用开源http负载生成器httpmon(https://github.com/cloud-control/httpmon)模拟虚拟web用户并发与应用程序交互,采用支持封闭和开放模型,以指数分布发出不同密度的httpget或post请求,动态模拟产生真实的应用行为。
(4)异常注入:在vm中部署资源使用工具,通过占用额外资源以模拟资源竞争,导致目标服务的异常资源使用或性能衰减,包括以下三种资源竞争情况:
1)cpu资源竞争:在给定的一段时间内,自动运行并行sudoku(http://norvig.com/sudoku.html),以解决随机猜谜问题。每个求解器的数量和持续时间,符合以某个设定值为均值的泊松分布。基于符合指数分布的运行间隔时间和平均运行次数,重复进行该实验过程。
2)网络拥塞:在vm上的单个iperf服务器和客户端之间建立串行tcp通信,设定每个串行连接之间为随机等待时间,模拟过量的网络带宽占用,每次运行的持续时间符合设定均值的指数分布。
3)磁盘io饱和:通过间歇性生成应用程序stress-ng(http://kernel.ubuntu.com/cking/stress-ng/)以模拟后台备份操作,从而导致磁盘i/o资源使用率过高。一个进程向磁盘写入平均50mb的数据,而另一个进程以特定周期执行线性搜索32位整数,操作时间的间隔符合以设定值为均值的指数分布。
(5)异常检测:分阶段进行3个小时,采样周期为30秒,每个实验节点搜集360个监测数据,基于交叉训练、测试策略,使用最近1.5小时的监测数据(180个实例)作为基准,设置参数k=180,n=4和pmax=10,剩余时间在线检测异常。基于statsmodels(http://statsmodels.sourceforge.net)实现度量的在线预测,基于scikit-learn(http://scikit-learn.org)实现基于距离的异常检测,对节点以及度量的异常程度进行排序:
1)定时搜集各节点的多度量监测数据,
2)根据历史监测数据,使用线性组合建模并预测度量值,其中,p表示滞后监测数据的数量,参数
3)计算预测误差为监测与预测之间的差值:,其中,为预测值,为监测值,这样检测异常资源使用的问题可以抽象为多元基于距离的离群点检测,使用预测误差到训练集中残差的统计距离以表示异常程度:,其中,为e的均值,se为e的协方差矩阵;
4)建立有向无环图g=(v,e),其中,节点v∈v表示数据中心组件的节点或属性,边e∈e表示每个层内部或者层之间的依赖关系;
5)异常节点列表集合
6)
- 还没有人留言评论。精彩留言会获得点赞!