基于半监督学习和细粒度特征学习的分类优化方法与流程
本发明涉及计算机视觉的技术领域,更具体地,涉及基于半监督学习和细粒度特征学习的分类优化方法。
背景技术:
细粒度图像识别是图像分类领域中一个子任务,它的目标是在一个大类中的数百数千个子类中正确识别目标。相同的子类中物体的差异可能大不相同,不同的子类中物体可能又有着较高的相似度,再加上可用于训练的细分类数据集小,这是识别他们的三大难点。
如何有效地对输入对象进行检测,并从中找到重要的局部区域信息,成为了细粒度图像分类算法要解决的关键问题,现有的方法解决细粒度分类问题按照其使用的监督信息的多少可以分为两类:基于强监督信息的分类模型和弱监督信息的分类模型两大类。
基于强监督信息的细粒度图像分类模型是指,在模型训练时,除了图像的类别标签外,还使用了物体标注框和部位标注点等额外的人工标注信息,以此来获得更好的分类精度。基于弱监督信息的细粒度图像分类模型则希望在不借助partannotation的情况下,依赖于本身的算法来完成物体和局部区域的检测,也可以捕捉到所需要的局部信息,以达到结合全局信息和局部信息来做细粒度级别的分类。
对于训练集不足的问题,一般可以通过迁移学习和半监督学习来解决,迁移学习通过大型数据集上训练好模型来在新的任务上做微调,半监督学习通过使用无标记数据来扩充可训练数据集样本。训练一个卷积神经网络往往需要较高的gpu内存和长时间的迭代训练,而如何把无标记样本正确利用起来是半监督学习一个难题。
目前尚未发现在具备高精确度、能解决训练样本不足并且能极大缩短运行时间,节省内存,提高时效的专利或者文献。
技术实现要素:
本发明为克服上述现有技术所述的至少一种缺陷,提供基于半监督学习和细粒度特征学习的分类优化方法,兼顾精准和内存、时间平衡的方法,通过半监督学习来扩充数据集,利用多尺度的细粒度特征来提高分类精确性,降低错误率。
本发明的技术方案是:基于半监督学习和细粒度特征学习的分类优化方法,其中,包括以下步骤:
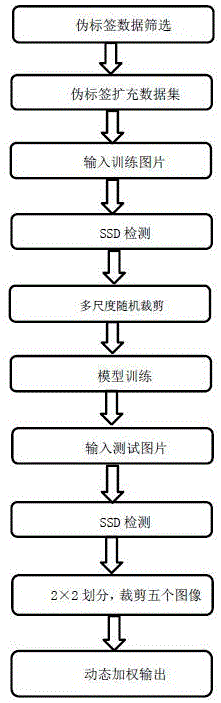
s1.对无标记数据做投票操作,挑选具有一致的结果且不属于混淆类的数据当做伪标签;
s2.用挑选好的伪标签扩充训练集;
s3.选定一张有标记图片,得到检测结果图a;
s4.将上一步得到的图a进行随机裁剪得到图片;
s5.将裁剪得到的图像块和图a一起送进网络去学习;
s6.选定待测试图片,得到检测结果图b;
s7.将图b划分大小,裁剪图像块;
s8.将裁剪得到图像块以及图b一起做预测;
s9.对上一步得到的每张图像块的预测结果,用最大预测概率减去次大预测概率作为他们的权重,累加加权后的概率,取最大概率所在类别当做测试图片的最终结果。
本发明中,结合半监督学习来挑选伪标签,用伪标签扩充数据集,用裁剪的图像块帮助模型学习细粒度特征,对要预测的图片做加权的结果输出。
进一步的,所述的步骤s3和s6中,用ssd检测,得到检测结果。ssd(singleshotmultiboxdetector)是一种目标检测算法,该算法于2016年提出,是目前最主要的检测算法之一,相比fasterrcnn有明显的速度优势,相比yolo又有明显的map优势。ssd具有如下主要特点:1、从yolo中继承了将detection转化为regression的思路,同时一次即可完成网络训练;2、基于fasterrcnn中的anchor,提出了相似的priorbox;3、加入基于特征金字塔(pyramidalfeaturehierarchy)的检测方式,相当于半个fpn思路。
进一步的,所述的步骤s4中,图a以两种尺度,即图a的1/2和1/4,进行随机裁剪各得到8张图。
所述的步骤s5中,将16张裁剪得到的图像块和图a一起送进网络去学习,训练网络时,在输出的时候,对每个输出概率向量,用最大预测概率减去次大预测概率作为他们的权重,累加加权后的概率,取最大概率所在类别当做测试图片的最终结果。
所述的步骤s7中,将图b划分成2×2大小,裁剪五个图像块。所述的步骤s8中,将裁剪得到的4张图像块以及图b一起做预测。
本发明利用了迁移学习,冻结卷积层,只训练全连接层大大缩短训练时间,节省内存。半监督学习、细粒度特征学习、迁移学习都运用到以上步骤中。
与现有技术相比,有益效果是:在本发明中,使用了半监督学习解决了可训练数据集不足的问题,通过裁剪,捕捉细粒度图像特征,加权输出类别概率,都极大提高了准确度。通过冻结卷积层,只训练全连接层,极大地节省内存,缩短了训练时间,因此本发明在精确性和时效性方面做到了很好的平衡,这在目前来看并没有别的文献和专利做到过。
附图说明
图1表示整套算法的流程图。
图2表示三个分类网络(vgg19、resnet18、googlenet)在cifar10数据集上的分类准确率柱状图。
图3表示半监督学习方法扩充数据集后给各个单模型带来的提升前后对比。
图4表示训练时随机裁剪方式得到得到的一些结果图。
图5表示测试时对检测后图片的裁剪方式。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。附图中描述位置关系仅用于示例性说明,不能理解为对本专利的限制。
本实施例中,使用ssd来对分类目标进行检测,以放大目标在图像中所占比例。
步骤一中,我们三个经典的卷积神经网络vgg19、resnet18和googlenet来做投票操作。首先在目标数据集上训练三个网络,然后让训练好的网络各自对验证集做出分类判断,然后对三个网络得到各个类别的准确率做平均,可得到各类别判断准确率如图2所示,将柱状图中远低于平均值的类别视为混淆类(如图2中红色和橘色和红色柱子所示类别),即难分类类别。将无标记样本中,三个模型分类结果一致且不属于混淆类类别的样本挑选出来,视为伪标签,即把三个模型的共同分类结果视为该无标记样本的类别。
步骤二中,将步骤一中挑选出来的伪标签加入到训练集,以此来扩充数据集,扩充前后的模型分类效果对比表格如图3所示。
步骤三中,将训练数据先用ssd进行检测,得到要分类目标的位置,对此位置进行裁剪,裁剪时进行短边延伸,即使得到的图片块长和宽大小一致,记为图a,裁剪出的部分快如图4所示。
步骤四中,从图a的中心点出发,以图a大小的1/4和1/9两种尺度随机裁剪各得到8张图片,共16张。裁剪得到部分图像块可视化结果如图2所示。
步骤五中,将上一步得到的十六张图片块都标记上和图a一样的类别,然后和图a一起送入网络中去学习,训练网络,在网络输出的时候,对每个输出概率向量,用最大预测概率减去次大预测概率作为他们的权重,累加加权后的概率,取最大概率所在类别当做测试图片的最终结果。
步骤六中,测试的时候,对于待测试图片,用ssd检测,得到检测结果记为图b。
步骤七中,将上一步得到的图b以2×2的大小进行划分,然后裁剪,得到四个图像块,再从图片的中心点出发,裁剪一个为图b的1/4大小的图像块,总的裁剪过程如图5所示。
步骤八中,将划分的四个部分裁剪下来得到四个图像块,将这四个图像块和图a一起送入网络去做预测,得到五个预测概率向量。
步骤九中,对上一步得到的五个预测概率向量,我们分别用每个概率向量的最大值减去次大值作为它们各自的权重w1、w2、w3、w4、w5,将这五个权重乘以他们的概率向量,然后累加,最后取最大概率所在类别当做是待测试图片的真实类别,加权输出削弱了背景在训练时带来的影响,提高了判断的准确性。
在本发明中,我们多次使用半监督学习、迁移学习、细粒度特征学习,并且优化了训练方式,冻结了分类网络的卷积层,只训练全连接层,都极大提高了运算效率和准确率。通过投票和非混淆类筛选,得到伪标签,用伪标签扩充数据集,解决训练样本不足问题。用ssd+随机裁剪的方法捕捉细粒度特征,在模型输出,用最大概率值减去次大值作为权重,减轻背景块带来的影响。整个一套流程因为有数据集的扩充和细粒度特征的加入,使得分类结果精确性得以提高,而选择使用迁移学习、冻结卷积层也使得训练测试速度得到了保证,因此本发明在精确性和时效性方面做到了很好的平衡,这在目前来看并没有别的文献和专利做到过。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!