一种基于深度学习的SCADA主站负荷预测方法与流程
本发明涉及电力系统技术领域,具体是指一种基于深度学习的scada主站负荷预测方法。
背景技术:
牵引供电负荷预测可分为长期、中期以及短期负荷预测,而短期负荷预测已经成为系统调度分析和优化的基本工作,准确的负荷预测既能保证牵引供电的稳定,减少用电成本,提高供电质量,也有助于供电系统的安全运营。负荷数据不仅表现在与历史数据有关,而且还与其它因素有关,比如天气,温度,降雨量等。负荷数据与这些因素之间的关系是高度复杂且非线性的,现阶段还未能建立这种关系的量化表达式。牵引供电系统负荷分配日渐复杂化、无规律,导致供电系统的负荷预测十分困难。
目前,牵引供电系统负荷预测多采用线性预测方法,比如线性回归、自回归滑动平均模型(arma)、自回归积分滑动平均模型(arima)等,这些线性预测方法多适用于中长期负荷预测,对于短期非平稳、非线性预测情况,难以模拟数据之间的实际关系,并且这类方法考虑的因素少而且预测精度低,不适用于短期负荷预测。传统神经网络、支持向量机能较好地解决短期复杂情况,这类方法具有强大的非线性映射能力,但是神经网络模型在训练过程中极易陷入局部极小及受到过拟合的影响,支持向量机是浅层特征学习模型,对大规模训练样本难以实施,而且这两类方法的网络中没有记忆单元,缺少对时序数据时间相关性的分析。因此,如何通过大量历史数据准确预测scada主站负荷,实现准确、实时地了解未来负荷的变化波动是一个亟待解决的问题。
技术实现要素:
本发明的目的在于提供一种基于深度学习的scada主站负荷预测方法,采用自适应非线性处理技术,充分利用大量历史数据训练,提高短期负荷预测精度,使调度人员准确、实时地了解未来负荷的变化波动。
本发明通过下述技术方案实现:
一种基于深度学习的scada主站负荷预测方法,该scada主站负荷预测方法主要包括以下步骤:
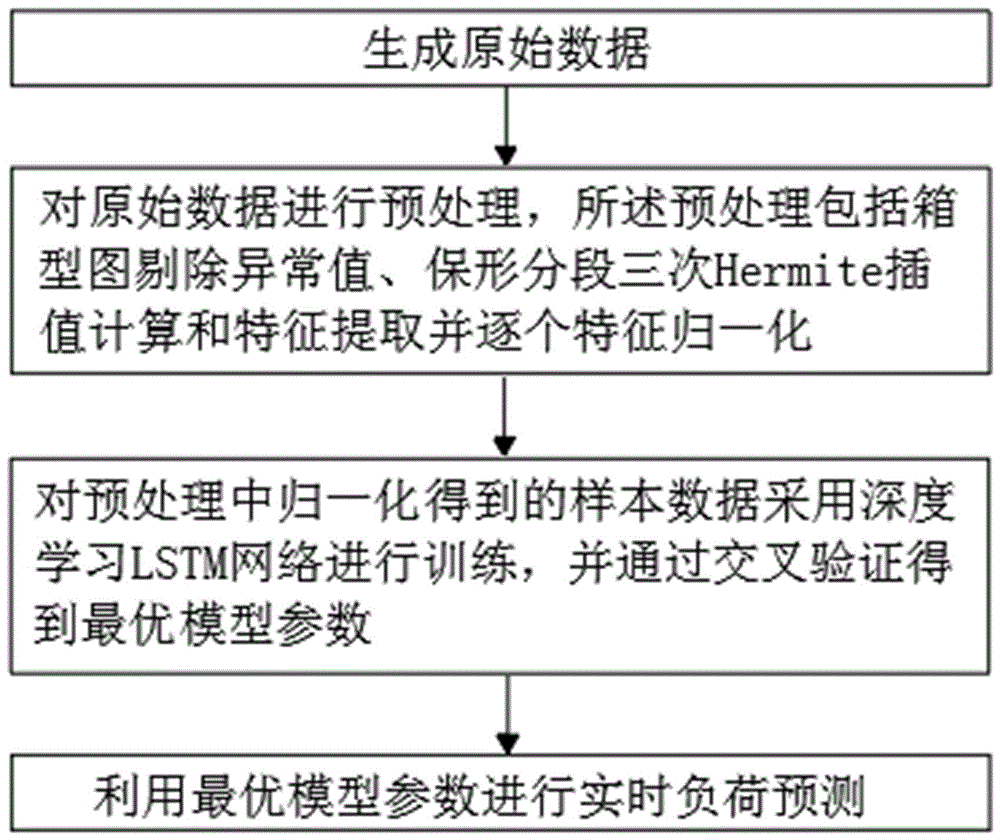
步骤一:生成原始数据;
步骤二:对原始数据进行预处理,所述预处理包括箱型图剔除异常值、保形分段三次hermite插值计算和特征提取并逐个特征归一化;
步骤三:对预处理中归一化得到的样本数据采用深度学习lstm网络进行训练,并通过交叉验证得到最优模型参数;
步骤四:利用最优模型参数进行实时负荷预测。
进一步的所述步骤一中的原始数据从scada系统中获取,且原始数据包括预测日之前若干天的历史数据、预测日之前指定时间宽度的历史数据以及天气、温度、降雨量的历史数据。
进一步的所述步骤二中特征提取先对某一段时间提取负荷的最大值、最小值和平均值,这段时间按实际需要而定,一般取5分钟。
进一步的所述步骤二的具体实现过程如下:
(1)箱型图剔除异常值:
该算法主要包含五个数据节点,分别为下四分位数q1、中位数q2、上四分位数q3、下边缘、上边缘,四分位距记为:iqr=q3-q1,上边缘记为:q3+1.5iqr,下边缘记为:q1-1.5iqr,位于下边缘与上边缘区间之外的数据为异常值;
(2)保形分段三次hermite插值计算:
设f(x)在节点a≤x0,x1,...,xn≤b处的函数值为f0,f1,...fn,设p(x)是f(x)在区间[a,b]的具有一阶导数的插值函数,要求p(x)在[a,b]上具有一阶导数,即一阶光滑度:
p(xi)=f(xi)=fi
p'(xi)=f'(xi)=f',i=0,1,...,n
p(x)是最高次数为2n+1次多项式,通过基函数构造p(x);
(3)特征提取:
提取需要预测时间段之前若干天数据的最大值、最小值、平均值,并拼接成一个训练样本,在训练样本中加入天气、温度、降雨量的数据;
(4)归一化处理:
利用归一化公式:
进一步的所述步骤三的具体实现过程如下:
(1)lstm前向传播:
通过lstm网络的网络结构分析,上一序列的隐藏状态h(t-1)和本序列数据x(t)线性组合通过激活函数,得到遗忘门输出f(t),当激活函数选择sigmoid函数时,f(t)表示遗忘上一层隐藏细胞状态的概率,表达式为:f(t)=σ(wfh(t-1)+ufx(t)+bf),输入门由两部分组成,第一部分输出为i(t),第二部分输出为a(t),表达式如下:
i(t)=σ(wih(t-1)+uix(t)+bi)
a(t)=tanh(wah(t-1)+uax(t)+ba)
在lstm进入输出门状态之前,遗忘门和输入门会作用于细胞状态c(t),
o(t)=σ(woh(t-1)+uox(t)+bo)
最后更新当前序列预测输出
(2)lstm反向传播权值更新:
本发明与现有技术相比,具有的有益效果为:
(1)本发明提出的一种基于数据处理与lstm的scada主站负荷预测技术,采用自适应非线性处理技术,充分利用大量历史数据训练,提高短期负荷预测精度,使调度人员准确、实时地了解未来负荷的变化波动,更有针对性地进行经济调度及机组协调稳定运行。
(2)本发明在对原始数据分析之前进行数据预处理,其中,选用箱型图算法将电流的异常数据剔除,然后对样本数据进行插值计算,保证样本数据在任一个时刻点都存在数据,由于电流采样频率较小,综合考虑精度以及平滑性,采用保形分段三次hermite插值算法对电流以及电压进行插值计算,提高插值计算的准确性和平滑性。
(3)本发明在对经过异常数据剔除以及插值计算之后的数据进行特征提取时,不会预测每一个时刻的负荷值,而是对某一段时间提取负荷的最大值、最小值和平均值,不仅能减轻模型训练负担,并且能快速找到决策区间。
附图说明
图1为本发明的流程图。
图2为长短时记忆神经网络(lstm)结构图。
图3为电流变化曲线图。
图4为插值计算效果图。
图5为箱型图异常数据分析图。
具体实施方式
下面结合实施例对本发明作进一步地详细说明,但本发明的实施方式不限于此。
实施例:
如图1-5所示,本发明为了克服现有技术的缺陷,提出了一种基于数据处理与lstm的scada主站负荷预测技术,采用自适应非线性处理技术,充分利用大量历史数据训练,提高短期负荷预测精度,使调度人员准确、实时地了解未来负荷的变化波动,更有针对性地进行经济调度及机组协调稳定运行。
一种基于深度学习的scada主站负荷预测方法,该scada主站负荷预测方法主要包括以下步骤:
步骤一:生成原始数据,原始数据从scada系统中获取,且原始数据包括预测日之前若干天的历史数据、预测日之前指定时间宽度的历史数据以及天气、温度、降雨量的历史数据。
步骤二:对原始数据进行预处理,所述预处理包括剔除异常值、插值计算和特征提取并逐个特征归一化,步骤二的具体实现过程如下:
(1)剔除异常值:
本发明剔除异常值的方法选用箱型图算法,如图5所示,该算法主要包含五个数据节点,分别为下四分位数q1、中位数q2、上四分位数q3、下边缘、上边缘,四分位距记为:iqr=q3-q1,上边缘记为:q3+1.5iqr,下边缘记为:q1-1.5iqr,位于下边缘与上边缘区间之外的数据为异常值。
(2)保形分段三次hermite插值计算:
在剔除异常值之后,为了后续的特征分析,需要对电流进行插值。插值算法主要有拉格朗日插值算法、牛顿插值算法、分段线性插值算法、样条插值算法、保形分段三次hermite插值算法。由于电流采样频率较小,综合考虑精度以及平滑性,本发明采用保形分段三次hermite插值算法对电流及电压进行插值运算,如图4所示,分别为分段线性插值算法和保形分段三次hermite插值算法的插值效果图,由图可见,采用保形分段三次hermite插值算法进行插值计算得出的数据更加平滑。设f(x)在节点a≤x0,x1,...,xn≤b处的函数值为f0,f1,...fn,设p(x)是f(x)在区间[a,b]的具有一阶导数的插值函数,要求p(x)在[a,b]上具有一阶导数,即一阶光滑度:
p(xi)=f(xi)=fi
p'(xi)=f'(xi)=f',i=0,1,...,n
p(x)是最高次数为2n+1次多项式,通过基函数构造p(x)。
(3)特征分析:
完成了剔除异常值和插值计算之后,即可保证历史采样数据在任一个时刻点都存在数据,并得到正常范围的完整数据。牵引供电负荷预测往往关心的是某一段时间负荷的最大值、最小值以及平均值是否在预测的区间内经济调度。因此,本发明在特征提取时,不会预测每一个时刻的负荷值,而是对某一段时间提取负荷的最大值、最小值和平均值,这段时间按实际需要而定,一般取5分钟,这样不仅能减轻模型训练负担,并且可以快速找到决策区间。
(4)特征提取:
经过上述三个步骤之后,需要准备lstm模型训练数据。按照上述指定分钟数设置移动滑动窗口,提取需要预测时间段之前若干天数据的最大值、最小值、平均值,然后拼接成一个训练样本。由于当前区间不仅与历史天数的数据相关,而且还与此时间段之前的某个时间段的数据相关,同理按照历史天数的特征提取方式提取出前段时间的最大值、最小值及平均值。此外,负荷数据不仅表现在与历史数据有关,而且还与其它因素有关,比如天气,温度,降雨量的数据。因此,训练样本中还需加入天气、温度、降雨量的数据。
(5)归一化处理:
为了满足lstm模型的输入需求,得到的训练样本需要经过归一化处理,归一化处理的具体步骤如下:
利用归一化公式:
步骤三:对预处理中归一化处理后得到的样本数据采用深度学习lstm网络进行训练,并通过交叉验证得到最优模型参数,模型并不能长时间有效,需要在一段时间之后重新按照上面步骤重新训练模型;步骤三的具体实现过程如下:
(1)lstm前向传播:
如图2所示,上一序列的隐藏状态h(t-1)和本序列数据x(t)线性组合通过激活函数,得到遗忘门输出f(t),当激活函数选择sigmoid函数时,f(t)表示遗忘上一层隐藏细胞状态的概率,表达式为:f(t)=σ(wfh(t-1)+ufx(t)+bf),输入门由两部分组成,第一部分输出为i(t),第二部分输出为a(t),表达式如下:
i(t)=σ(wih(t-1)+uix(t)+bi)
a(t)=tanh(wah(t-1)+uax(t)+ba)
在lstm进入输出门状态之前,遗忘门和输入门会作用于细胞状态c(t),
o(t)=σ(woh(t-1)+uox(t)+bo)
最后更新当前序列预测输出
(2)lstm反向传播权值更新:
步骤四:利用最优模型参数进行实时负荷预测,预测过程中同样采用滑动窗口的方式进行区间负荷最大值、最小值、平均值预测。
本发明提供了一种负荷预测数据预处理方法和一种实时负荷预测方法,首先对获取的原始数据进行预处理,提高数据质量,增加数据分析与模型训练的可靠性与精确性,然后采用数据处理与lstm的scada主站负荷预测技术以及自适应式非线性处理技术对短期负荷进行预测,不仅提高了短期负荷预测的精度,使调度人员准确、实时地了解未来负荷的变化波动,更有针对性地进行经济调度及机组协调稳定运行。
以上所述,仅是本发明的较佳实施例,并非对本发明做任何形式上的限制,凡是依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化,均落入本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!