任意神经网络的机器学习稀疏计算机制、用于训练机制的算术计算微架构以及稀疏性的制作方法
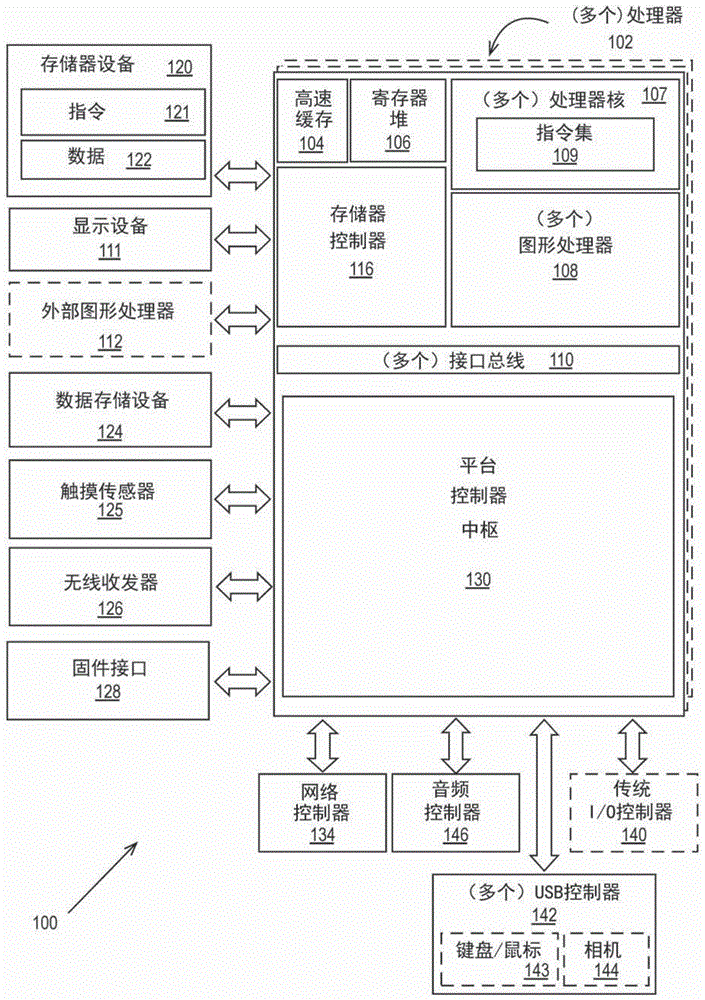
实施例大体涉及数据处理,并且更具体地涉及经由通用图形处理单元的数据处理。
背景技术:
:当前的并行图形数据处理包括开发用于对图形数据执行特定操作的系统和方法,所述特定操作诸如例如线性插值、曲面细分、光栅化、纹理映射、深度测试等。传统上,图形处理器使用固定功能计算单元来处理图形数据;然而,最近,部分图形处理器已经被制作为可编程的,使得这种处理器能够支持更广泛种类的操作来处理顶点和片段数据。为了进一步提高性能,图形处理器通常实现诸如流水线操作之类的处理技术,这些处理技术尝试贯穿图形流水线的不同部分并行地处理尽可能多的图形数据。具有单指令多线程(simt)架构的并行图形处理器被设计成使图形流水线中的并行处理量最大化。在simt架构中,多组并行线程尝试尽可能经常地一起同步执行程序指令,以提高处理效率。可以在shanecook的cuda编程(cudaprogramming)第三章,第37-51页(2013)中找到simt架构的软件和硬件的一般概述。附图说明为了以能够详细理解本实施例的以上记载特征的方式,可以通过参考实施例来对以上简要概括的实施例进行更具体的描述,这些实施例中的一些在所附附图中被示出。然而,应当注意,所附附图仅示出典型实施例,并因此不应被认为是对其范围的限制。图1是根据实施例的处理系统100的框图;图2是处理器200的实施例的框图,该处理器200具有一个或多个处理器核202a-202n、集成存储器控制器214以及集成图形处理器208;图3是图形处理器300的框图,该图形处理器300可以是分立的图形处理单元,或可以是与多个处理核集成的图形处理器;图4是根据一些实施例的图形处理器的图形处理引擎410的框图;图5是根据本文中描述的一些实施例的图形处理器核500的硬件逻辑的框图;图6a-6b示出了根据本文中描述的实施例的包括在图形处理器核中采用的处理元件阵列的线程执行电路600;图7是示出根据一些实施例的图形处理器指令格式700的框图;图8是图形处理器800的另一实施例的框图;图9a是示出根据一些实施例的图形处理器命令格式900的框图;图9b是示出根据实施例的图形处理器命令序列910的框图;图10示出了根据一些实施例的数据处理系统1000的示例性图形软件架构;图11a是示出根据实施例的可用于制造集成电路以执行操作的ip核开发系统1100的框图;图11b示出了根据本文中描述的一些实施例的集成电路封装组件1170的横截面侧视图;图12-14示出了根据本文中描述的各种实施例的可以使用一个或多个ip核制造的示例性集成电路和相关联的图形处理器;图15示出了根据实施例的机器学习软件栈。图16a-16b示出了示例性深度神经网络的层。图17示出了示例性递归神经网络。图18示出了深度神经网络的训练和部署。图19是示出分布式学习的框图。图20a示出了示例性规则神经网络。图20b示出了根据实施例的示例性任意(或不规则)神经网络。图21a示出了示例性规则神经网络。图21b示出了根据实施例的nn2100的示例性矩阵乘法操作2120。图21c示出了根据实施例的示例性任意(或不规则)神经网络。图21d示出了根据实施例的nn2150的示例性矩阵乘法操作2170。图22a示出了根据实施例的nn2150的示例性矩阵乘法操作2200。图22b示出了根据实施例的示例性增强的稀疏矩阵加速器2250。图23示出了根据实施例的示例性pe电路2300的详细视图。图24a-24c示出了根据实施例的利用增强的稀疏矩阵加速器执行的操作的示例。图25a-25b示出了根据实施例的通过同时处理多个输入向量来优化利用增强的稀疏矩阵加速器执行的操作的示例。图26示出了根据实施例的用于同时处理多个输入向量的示例性电路2600的详细视图。如图27中所示,在一个实施例中,稀疏处理机制2710(例如,增强的稀疏矩阵加速器2250、2450等)可以由gpu2714主控(host)。图28示出了用于计算的不同数字表示。图29a-b示出了内积矩阵乘法和外积矩阵乘法。图30a示出了多个输入的空间计算。图30b示出了多个输入的时间计算。图30c示出了多个输入的空间和时间计算的组合。图31示出了根据实施例的具有对可变和混合精度操作以及稀疏性的支持的示例性算术计算架构3100。图32示出了根据实施例的具有对可变和混合精度操作以及稀疏性的支持的算术计算架构的稀疏性管理单元的示例性操作(例如,内积操作)序列。图33示出了根据实施例的具有对可变和混合精度操作以及稀疏性的支持的算术计算架构的稀疏性管理单元的示例性操作(例如,外积操作)序列。图34示出了根据实施例的具有对可变和混合精度操作以及稀疏性的支持的算术计算架构的块(block)fp管理单元的示例性操作(例如,块fp操作)序列。图35示出了根据实施例的可变和混合精度计算单元的框图。图36示出了根据实施例的可变和混合精度计算单元的框图。图37示出了根据实施例的设计框架。图38示出了根据实施例的硬件加速器模板的高级架构3800。图39示出了根据实施例的加速器片(tile)的框图。图40示出了根据实施例的用于加速器片的操作的方法。图41a示出了根据实施例的用于训练具有稀疏性的数据的稀疏密集gemvgpu实现的方法。图41b示出了根据实施例的用于训练具有稀疏性的数据的稀疏密集gemvgpu实现的方法。图42示出了根据实施例的用于基于l3的稀疏密集gemv实现的各种矩阵维度和稀疏性的稀疏gemv和密集gemv的图。图43示出了根据实施例的用于训练中的稀疏性的稀疏密集gemvgpu实现的方法。图44示出了根据实施例的对于标准矩阵维度而言稀疏gemm相对于密集gemm的改进性能的图。图45是示出被配置成用于实现本文中所描述的实施例的一个或多个方面的计算机系统的框图;图46a-46d示出了根据实施例的并行处理器部件;图47a-47b是根据实施例的图形多处理器的框图;图48a-48g示出了其中多个gpu被通信地耦合至多个多核处理器的示例性架构;图49示出了根据实施例的图形处理流水线。具体实施方式在实施例中,公开了用于对任意(arbitrary)神经网络执行稀疏矩阵处理的机制。该机制有效地执行任意图形(例如,不规则的、规则的)。还公开了用于训练机制的算术计算微架构和稀疏性。在一些实施例中,一种装置包括具有数据管理单元(dmu)的图形处理单元,该dmu包括用于调度矩阵操作的调度器、用于跟踪有效(active)输入操作数的有效逻辑、以及用于跟踪要由调度器跳过的不重要输入操作数的跳过逻辑。处理电路被耦合到dmu。处理电路包括多个处理元件,处理元件包括用于读取操作数的逻辑和用于将两个或更多个操作数相乘的乘法单元。在以下描述中,阐述了很多特定细节来提供更全面的理解。然而,将对本领域技术人员显而易见的是,没有这些特定细节中的一个或多个,也可实践本文中所描述的实施例。在其他实例中,未描述公知的特征以避免使本实施例的细节变得模糊。系统概述系统概述图1是根据实施例的处理系统100的框图。在各实施例中,系统100包括一个或多个处理器102以及一个或多个图形处理器108,并且可以是单处理器台式系统、多处理器工作站系统或具有大量处理器102或处理器核107的服务器系统。在一个实施例中,系统100是被纳入到用于在移动设备、手持式设备或嵌入式设备中使用的芯片上系统(soc)集成电路内的处理平台。在一个实施例中,系统100可以包括或并入基于服务器的游戏平台、游戏控制台,包括游戏与媒体控制台、移动游戏控制台、手持式游戏控制台、或在线游戏控制台。在一些实施例中,系统100是移动电话、智能电话、平板计算设备或移动互联网设备。处理系统100还可包括可穿戴设备(诸如智能手表可穿戴设备、智能眼镜设备、增强现实设备、或虚拟现实设备)、与所述可穿戴设备耦合、或者集成在所述可穿戴设备中。在一些实施例中,处理系统100是电视或机顶盒设备,所述电视或机顶盒设备具有一个或多个处理器102以及由一个或多个图形处理器108生成的图形界面。在一些实施例中,一个或多个处理器102每个包括用于处理指令的一个或多个处理器核107,所述指令在被执行时执行系统和用户软件的操作。在一些实施例中,一个或多个处理器核107中的每个处理器核被配置成用于处理特定的指令集109。在一些实施例中,指令集109可以促进复杂指令集计算(cisc)、精简指令集计算(risc)、或经由超长指令字(vliw)的计算。多个处理器核107可以各自处理不同的指令集109,所述指令集可以包括用于促进对其他指令集进行仿真的指令。处理器核107还可以包括其他处理设备,如数字信号处理器(dsp)。在一些实施例中,处理器102包括高速缓存存储器104。取决于架构,处理器102可以具有单个内部高速缓存或内部高速缓存的多个级。在一些实施例中,在处理器102的各部件当中共享高速缓存存储器。在一些实施例中,处理器102还使用外部高速缓存(例如,3级(l3)高速缓存或末级高速缓存(llc))(未示出),可以使用已知的高速缓存一致性技术来在处理器核107当中共享外部高速缓存。另外地,寄存器堆106包括在处理器102中,所述处理器可以包括用于存储不同类型的数据的不同类型的寄存器(例如,整数寄存器、浮点寄存器、状态寄存器、和指令指针寄存器)。一些寄存器可以是通用寄存器,而其他寄存器可以特定于处理器102的设计。在一些实施例中,一个或多个处理器102与一个或多个接口总线110耦合,所述接口总线用于在处理器102与系统100中的其他部件之间传输通信信号,如地址、数据、或控制信号。在一个实施例中,接口总线110可以是处理器总线,如直接媒体接口(dmi)总线的版本。然而,处理器总线不限于dmi总线并且可以包括一个或多个外围部件互连总线(例如,pci、pciexpress)、存储器总线或其他类型的接口总线。在一个实施例中,(多个)处理器102包括集成存储器控制器116和平台控制器中枢130。存储器控制器116促进存储器设备与系统100的其他部件之间的通信,而平台控制器中枢(pch)130经由本地i/o总线提供到i/o设备的连接。存储器设备120可以是动态随机存取存储器(dram)设备、静态随机存取存储器(sram)设备、闪存设备、相变存储器设备、或具有用作处理存储器的合适性能的某种其他存储器设备。在一个实施例中,存储器设备120可以作为系统100的系统存储器来操作,用于存储数据122和指令121以供在所述一个或多个处理器102执行应用程序或进程时使用。存储器控制器116还与可选的外部图形处理器112耦合,所述外部图形处理器可以与处理器102中的所述一个或多个图形处理器108进行通信从而执行图形操作和媒体操作。在一些实施例中,显示设备111可以连接至(多个)处理器102。显示设备111可以是以下各项中的一项或多项:内部显示设备,如在移动电子设备或膝上型设备中;或经由显示接口(例如,显示端口等)附接的外部显示设备。在一个实施例中,显示设备111可以是头戴式显示器(hmd),如用于虚拟现实(vr)应用或增强现实(ar)应用中使用的立体显示设备。在一些实施例中,平台控制器中枢130使得外围设备能够经由高速i/o总线连接至存储器设备120和处理器102。i/o外围设备包括但不限于:音频控制器146、网络控制器134、固件接口128、无线收发器126、触摸传感器125、数据存储设备124(例如,硬盘驱动器、闪存等)。数据存储设备124可以经由存储接口(例如,sata)或经由如外围部件互连总线(例如,pci、pciexpress)等外围总线来进行连接。触摸传感器125可以包括触摸屏传感器、压力传感器、或指纹传感器。无线收发器126可以是wi-fi收发器、蓝牙收发器、或移动网络收发器,如3g、4g或长期演进(lte)收发器。固件接口128使得能够与系统固件进行通信,并且可以例如是统一可扩展固件接口(uefi)。网络控制器134可以使能到有线网络的网络连接。在一些实施例中,高性能网络控制器(未示出)与接口总线110耦合。在一个实施例中,音频控制器146是多声道高清音频控制器。在一个实施例中,系统100包括用于将传统(例如,个人系统2(ps/2))设备耦合至系统的可选的传统i/o控制器140。平台控制器中枢130还可以连接至一个或多个通用串行总线(usb)控制器142连接输入设备,如键盘和鼠标143组合、相机144、或其他usb输入设备。将认识到的是,所示出的系统100是示例性的而非限制性的,因为还可以使用以不同方式配置的其他类型的数据处理系统。例如,存储器控制器116和平台控制器中枢130的实例可以集成到分立式外部图形处理器,如外部图形处理器112。在一个实施例中,平台控制器中枢130和/或存储器控制器160可以在所述一个或多个处理器102外部。例如,系统100可以包括外部存储器控制器116和平台控制器中枢130,所述外部存储器控制器和外围控制器可以被配置为在与(多个)处理器102通信的系统芯片组内的存储器控制器中枢和外围控制器中枢。图2是处理器200的实施例的框图,所述处理器具有一个或多个处理器核202a至202n、集成存储器控制器214、以及集成图形处理器208。图2的具有与此处任何其他附图中的元件相同的参考号(或名称)的那些元件可采用与在本文中其他地方描述的方式相类似的任何方式进行操作或起作用,但不限于这些。处理器200可包括多达且包括由虚线框表示的附加核202n的附加核。处理器核202a至202n各自包括一个或多个内部高速缓存单元204a至204n。在一些实施例中,每个处理器核还可以访问一个或多个共享的高速缓存单元206。内部高速缓存单元204a至204n和共享高速缓存单元206表示处理器200内部的高速缓存存储器层级结构。高速缓存存储器层级结构可以包括每个处理器核内的至少一级指令和数据高速缓存以及一级或多级共享中级高速缓存,诸如2级(l2)、3级(l3)、4级(l4)、或其他级的高速缓存,其中,最高级的高速缓存在外部存储器之前被分类为llc。在一些实施例中,高速缓存一致性逻辑维持各高速缓存单元206与204a至204n之间的一致性。在一些实施例中,处理器200还可以包括一组一个或多个总线控制器单元216和系统代理核210。一个或多个总线控制器单元216管理一组外围总线,诸如一个或多个pci或pci快速总线。系统代理核210提供对各处理器部件的管理功能。在一些实施例中,系统代理核210包括一个或多个集成存储器控制器214用于管理对各外部存储器设备(未示出)的访问。在一些实施例中,处理器核202a至202n中的一个或多个包括对同步多线程的支持。在这种实施例中,系统代理核210包括用于在多线程处理过程中协调和操作核202a至202n的部件。另外,系统代理核210还可以包括功率控制单元(pcu),所述功率控制单元包括用于调节处理器核202a至202n的功率状态的逻辑和部件以及图形处理器208。在一些实施例中,另外,处理器200还包括用于执行图形处理操作的图形处理器208。在一些实施例中,图形处理器208耦合至共享高速缓存单元206集以及系统代理核210,所述系统代理核包括一个或多个集成存储器控制器214。在一些实施例中,系统代理核210还包括显示控制器211以便将图形处理器输出驱动到一个或多个耦合的显示器。在一些实施例中,显示控制器211还可以是经由至少一个互连与图形处理器耦合的单独模块,或者可以集成在图形处理器208内。在一些实施例中,基于环的互连单元212用于耦合处理器200的内部部件。然而,可以使用替代性互连单元,比如点到点互连、切换式互连、或其他技术,包括本领域众所周知的技术。在一些实施例中,图形处理器208经由i/o链路213与环形互连212耦合。示例性i/o链路213表示多个i/o互连中的多个品种中的至少一种,包括促进各处理器部件与高性能嵌入式存储器模块218(比如edram模块)之间的通信的封装体i/o互连。在一些实施例中,处理器核202a至202n中的每个处理器核以及图形处理器208将嵌入式存储器模块218用作共享末级高速缓存。在一些实施例中,处理器核202a至202n是执行相同指令集架构的同构核。在另一实施例中,处理器核202a至202n在指令集架构(isa)方面是异构的,其中,处理器核202a至202n中的一者或多者执行第一指令集,而其他核中的至少一者执行所述第一指令集的子集或不同的指令集。在一个实施例中,处理器核202a至202n就微架构而言是同质的,其中,具有相对较高功耗的一个或多个核与具有较低功耗的一个或多个功率核耦合。另外,处理器200可以实现在一个或多个芯片上或者被实现为具有除其他部件之外的所展示的部件的soc集成电路。图3是图形处理器300的框图,所述图形处理器可以是分立式图形处理单元、或者可以是与多个处理核集成的图形处理器。在一些实施例中,图形处理器经由到图形处理器上的寄存器的映射i/o接口并且利用被放置在处理器存储器中的命令与存储器进行通信。在一些实施例中,图形处理器300包括用于访问存储器的存储器接口314。存储器接口314可以是到本地存储器、一个或多个内部高速缓存、一个或多个共享外部高速缓存、和/或到系统存储器的接口。在一些实施例中,图形处理器300还包括显示控制器302,所述显示控制器用于将显示输出数据驱动到显示设备320。显示控制器302包括用于显示器的一个或多个重叠平面的硬件以及多层视频或用户接口元件的组成。显示设备320可以是内部或外部显示设备。在一个实施例中,显示设备320是头戴式显示设备,如虚拟现实(vr)显示设备或增强现实(ar)显示设备。在一些实施例中,图形处理器300包括用于编码、解码、或者向、从或在一个或多个媒体编码格式之间进行媒体代码转换的视频编解码器引擎306,包括但不限于:运动图像专家组(mpeg)格式(比如mpeg-2)、高级视频译码(avc)格式(比如h.264/mpeg-4avc)、以及电影&电视工程师协会(smpte)421m/vc-1、和联合图像专家组(jpeg)格式(比如jpeg、以及运动jpeg(mjpeg)格式)。在一些实施例中,图形处理器300包括用于执行二维(2d)光栅化器操作包括例如位边界块传递的块图像传递(blit)引擎304。然而,在一个实施例中,使用图形处理引擎(gpe)310的一个或多个部件执行2d图形操作。在一些实施例中,gpe310是用于执行图形操作的计算引擎,所述图形操作包括三维(3d)图形操作和媒体操作。在一些实施例中,gpe310包括用于执行3d操作的3d流水线312,比如使用作用于3d图元形状(例如,矩形、三角形等)的处理功能来渲染三维图像和场景。3d流水线312包括可编程且固定的功能元件,所述可编程且固定的功能元件在到3d/媒体子系统315的元件和/或生成的执行线程内执行各种任务。虽然3d流水线312可以用于执行媒体操作,但是gpe310的实施例还包括媒体流水线316,所述媒体流水线具体地用于执行媒体操作,诸如视频后处理和图像增强。在一些实施例中,媒体流水线316包括固定功能或可编程逻辑单元以便代替、或代表视频编解码器引擎306来执行一种或多种专门的媒体操作,比如视频解码加速、视频解交织、以及视频编码加速。在一些实施例中,另外,媒体流水线316还包括线程生成单元以便生成用于在3d/媒体子系统315上执行的线程。所生成的线程对3d/媒体子系统315中所包括的一个或多个图形执行单元执行对媒体操作的计算。在一些实施例中,3d/媒体子系统315包括用于执行3d流水线312和媒体流水线316生成的线程的逻辑。在一个实施例中,流水线向3d/媒体子系统315发送线程执行请求,所述3d/媒体子系统包括用于仲裁并将各请求分派到可用的线程执行资源的线程分派逻辑。执行资源包括用于处理3d和媒体线程的图形执行单元阵列。在一些实施例中,3d/媒体子系统315包括用于线程指令和数据的一个或多个内部高速缓存。在一些实施例中,所述子系统还包括共享存储器(包括寄存器和可寻址存储器)以便在线程之间共享数据并用于存储输出数据。贯穿本文档,术语“逻辑”、“模块”、“部件”、“引擎”、“机制”、“工具”、“电路”和“电路系统”可互换地引用,并且作为示例可包括软件、硬件、固件或其任意组合。图形处理引擎图4是根据一些实施例的图形处理器的图形处理引擎410的框图。在一个实施例中,图形处理引擎(gpe)410是图3所示的gpe310的一个版本。图4的具有与此处任何其他附图中的元件相同的参考号(或名称)的那些元件可采用与在本文中其他地方描述的方式相类似的任何方式进行操作或起作用,但不限于这些。例如,展示了图3的3d流水线312和媒体流水线316。媒体流水线316在gpe410的一些实施例中是可选的,并且可以不显式地地包括在gpe410内。例如以及在至少一个实施例中,单独的媒体和/或图像处理器被耦合至gpe410。在一些实施例中,gpe410与命令流转化器403耦合或包括所述命令流转化器,所述命令流转化器向3d流水线312和/或媒体流水线316提供命令流。在一些实施例中,命令流转化器403与存储器耦合,所述存储器可以是系统存储器、或者是内部高速缓存存储器和共享高速缓存存储器中的一个或多个。在一些实施例中,命令流转化器403从存储器接收命令并将这些命令发送至3d流水线312和/或媒体流水线316。所述命令是从存储用于3d流水线312和媒体流水线316的环形缓冲器获取的指示。在一个实施例中,环形缓冲器可以另外包括存储多批多命令的批命令缓冲器。用于3d流水线312的命令还可以包括对在存储器中存储的数据的引用,诸如但不限于用于3d流水线312的顶点数据和几何数据和/或用于媒体流水线316的图像数据和存储器对象。3d流水线312和媒体流水线316通过经由各自流水线内的逻辑执行操作或者通过将一个或多个执行线程分派至执行图形核阵列414来处理所述命令和数据。在一个实施例中,图形核阵列414包括一个或多个图形核块(例如,(多个)图形核415a、(多个)图形核415b),每个块包括一个或多个图形核。每个图形核包括一组图形执行资源,所述一组图形执行资源包括:用于执行图形操作和计算操作的通用执行逻辑和图形专用执行逻辑;以及固定功能纹理处理逻辑和/或机器学习和人工智能加速逻辑。在各个实施例中,3d流水线312包括:固定功能逻辑和可编程逻辑,用于通过处理指令并将执行线程分派给图形核阵列414来处理一个或多个着色器程序,诸如顶点着色器、几何着色器、像素着色器、片段着色器、计算着色器或其他着色器程序。图形核阵列414提供了供在处理这些着色器程序时使用的统一的执行资源块。图形核阵列414的(多个)图形核415a至414b内的多用途执行逻辑(例如,执行单元)包括对各种3dapi着色器语言的支持,并且可以执行与多个着色器相关联的多个同步执行线程。在一些实施例中,图形核阵列414还包括用于执行诸如视频和/或图像处理的媒体功能的执行逻辑。在一个实施例中,除了图形处理操作之外,执行单元还包括可编程以执行并行通用计算操作的通用逻辑。通用逻辑可以与图1的(多个)处理器核107或图2中的核202a至202n内的通用逻辑并行地或结合地执行处理操作。由在图形核阵列414上执行的线程生成的输出数据可以将数据输出到统一返回缓冲器(urb)418中的存储器。urb418可以存储多个线程的数据。在一些实施例中,urb418可以用于在图形核阵列414上执行的不同线程之间发送数据。在一些实施例中,urb418可以另外用于图形核阵列上的线程与共享功能电路420内的固定功能逻辑之间的同步。在一些实施例中,图形核阵列414是可缩放的,使得所述阵列包括可变数量的图形核,这些图形核各自具有基于gpe410的目标功率和性能等级的可变数量的执行单元。在一个实施例中,执行资源是动态可缩放的,从而可以根据需要启用或禁用执行资源。图形核阵列414与共享功能电路420耦合,所述共享功能逻辑包括在图形核阵列中的图形核之间共享的多个资源。共享功能电路420内的共享功能是向图形核阵列414提供专用补充功能的硬件逻辑单元。在各种实施例中,共享功能电路420包括但不限于采样器421、数学422和线程间通信(itc)423逻辑。另外,一些实施例实现共享功能电路420内的一个或多个高速缓存425。在给定的专用功能的需求不足以包含在图形核阵列414中的情况下实施共享功能。相反,所述专用功能的单个实例被实施为共享功能电路420中的独立实体并且在图形核阵列414内的执行资源之间共享。在图形核阵列414之间共享并包括在图形核阵列414内的精确的一组功能在各实施例之间变化。在一些实施例中,共享功能电路420内由图形核阵列414广泛使用的特定共享功能可以包括在图形核阵列414内的共享功能逻辑416内。在各个实施例中,图形核阵列414内的共享功能逻辑416可以包括共享功能电路420内的一些或所有逻辑。在一个实施例中,共享功能电路420内的所有逻辑元件可以在图形核阵列414的共享功能逻辑416内重复。在一个实施例中,共享功能电路420被执行以便支持图形核阵列414内的共享功能逻辑416。图5是根据本文所描述的一些实施例的图形处理器核500的硬件逻辑的框图。图5的具有与本文任何其他附图中的元件相同的参考号(或名称)的那些元件可采用与在本文中其他地方描述的方式相类似的任何方式进行操作或起作用,但不限于这些。在一些实施例中,所展示的图形处理器核500包括在图4的图形核阵列414内。图形处理器核500——有时称为核切片——可以是模块化图形处理器内的一个或多个图形核。图形处理器核500的示例是一个图形核切片,并且,基于目标功率包络线和性能包络线,如本文所描述的图形处理器可以包括多个图形核切片。每个图形核500可以包括固定功能块530,所述固定功能块与包括模块化通用逻辑块和固定功能逻辑块的多个子核501a至501f(也被称为子切片)相耦合。在一些实施例中,固定功能块530包括几何/固定功能流水线536,所述几何/固定功能流水线例如在低性能和/或低功率图形处理器实施方式中可以由图形处理器500中的所有子核共享。在各个实施例中,几何/固定功能流水线536包括3d固定功能流水线(例如,如在图3和图4中的3d流水线312)、视频前端单元、线程派生器和线程分派器、以及管理如图4的统一返回缓冲器418等统一返回缓冲器的统一返回缓冲器管理器。在一个实施例中,固定功能块530还包括图形soc接口537、图形微控制器538和媒体流水线539。图形soc接口537提供了图形核500与芯片上系统集成电路内的其他处理器核之间的接口。图形微控制器538是可配置成管理图形处理器500的包括线程分派、调度和先占(pre-emption)在内的各种功能的可编程子处理器。媒体流水线539(例如,图3和图4的媒体流水线316)包括用于促进对包括图像数据和视频数据在内的多媒体数据进行解码、编码、预处理和/或后处理的逻辑。媒体流水线539经由对子核501至501f内的计算或采样逻辑的请求来实施媒体操作。在一个实施例中,soc接口537使得图形核500能够与通用应用处理器核(例如,cpu)和/或soc内的其他部件进行通信,这些其他部件包括如共享末级高速缓存存储器等存储器层级架构元件、系统ram、和/或嵌入式片上或封装体上dram。soc接口537还可以使能与soc内如相机成像流水线等固定功能设备进行通信,并且使能使用和/或实施可以在图形核500与soc内的cpu之间共享的全局存储器原子。soc接口537还可以实施针对图形核500的功率管理控制,并且使能图形核500的时钟域与soc内的其他时钟域之间的接口。在一个实施例中,soc接口537使得能够从被配置成向图形处理器内的一个或多个图形核中的每一个提供命令和指令的命令流转化器和全局线程分派器处接收命令缓冲器。当媒体操作将要执行时,这些命令和指令可以被分派给媒体流水线539,或者当图形处理操作将要执行时,这些命令和指令可以被分派给几何和固定功能流水线(例如,几何和固定功能流水线536、几何和固定功能流水线514)。图形微控制器538可以被配置成执行针对图形核500的各种调度任务和管理任务。在一个实施例中,图形微控制器538可以对子核501a至501f内的执行单元(eu)阵列502a至502f、504a至504f内的各个图形并行引擎执行图形和/或计算工作负荷调度。在这种调度模型中,在包括图形核500的soc的cpu核上执行的主机软件可以经由多个图形处理器门铃(doorbell)之一来提交工作负荷,这调用了对适当图形引擎的调度操作。调度操作包括:确定接下来要运行哪个工作负荷、向命令流转化器提交工作负荷、对在引擎上运行的现有工作负荷进行先占、监测工作负荷的进程、以及通知主机软件何时完成工作负荷。在一个实施例中,图形微控制器538还可以促进图形核500的低功率或空闲状态,从而为图形核500提供独立于操作系统和/或系统上的图形驱动器软件跨低功率状态转换来对图形核500内的寄存器进行保存和恢复的能力。图形核500可以具有多于或少于所展示的子核501a至501f,多达n个模块化子核。对于每组n个子核,图形核500还可以包括共享功能电路510、共享存储器和/或高速缓存存储器512、几何/固定功能流水线514、以及用于加速各种图形和计算处理操作的附加固定功能电路516。共享功能电路510可以包括与可由图形核500内的每n个子核共享的图4共享功能电路420相关联的逻辑单元(例如,采样器逻辑、数学逻辑、和/或线程间通信逻辑)。共享存储器和/或高速缓存存储器512可以是用于图形核500内的所述一组n个子核501a至501f的末级高速缓存,并且还可以充当可由多个子核访问的共享存储器。几何/固定功能流水线514可以代替几何/固定功能流水线536被包括在固定功能块530内,并且可以包括相同的或类似的逻辑单元。在一个实施例中,图形核500包括附加固定功能电路516,所述附加固定功能逻辑可以包括供由图形核500使用的各种固定功能加速逻辑。在一个实施例中,附加固定功能电路516包括供在仅位置着色中使用的附加几何流水线。在仅位置着色中,存在两个几何流水线:几何/固定功能流水线516、536内的完全几何流水线;以及拣选流水线,所述拣选流水线是可以包括在附加固定功能电路516内的附加几何流水线。在一个实施例中,拣选流水线是完全几何流水线的精简版本。完全流水线和拣选流水线可以执行同一应用的不同实例,每个实例具有单独的上下文。仅位置着色可以隐藏被丢弃三角形的较长拣选运行,从而在一些实例中使得能够更早完成着色。例如并且在一个实施例中,附件固定功能电路516内的拣选流水线逻辑可以与主应用并行地执行位置着色器,并且通常比完全流水线更快地生成关键结果,因为完全流水线仅对顶点的位置属性进行取出和着色,而不向帧缓冲器执行对像素的光栅化和渲染。拣选流水线可以使用所生成的关键结果来计算所有三角形的可见性信息,而无需考虑那些三角形是否被拣选。完全流水线(其在本实例中可以被称为重放(replay)流水线)可以消耗可见性信息以便跳过被拣选的三角形从而仅对最终被传递到光栅化阶段的可见三角形进行着色。在一个实施例中,附加固定功能电路516还可以包括用于包括针对机器学习训练或推理在内的实施方式的机器学习加速逻辑,如固定功能矩阵乘法逻辑。在每个图形子核501a至501f内包括可以用来响应于图形流水线、媒体流水线、或着色器程序的请求而执行图形操作、媒体操作和计算操作的一组执行资源。图形子核501a至501f包括:多个eu阵列502a至502f、504a至504f;线程分派和线程间通信(td/ic)逻辑503a至503f;3d(例如,纹理)采样器505a至505f;媒体采样器506a至506f;着色器处理器507a至507f;以及共享本地存储器(slm)508a至508f。eu阵列502a至502f、504a至504f各自包括多个执行单元,所述多个执行单元为能够执行浮点逻辑运算和整数/定点逻辑运算以便为图形操作、媒体操作或计算操作服务的通用图形处理单元,包括图形程序、媒体程序或计算着色器程序。td/ic逻辑503a至503f执行针对子核内的执行单元的本地线程分派和线程控制操作,并且促进在所述子核的执行单元上执行的线程之间的通信。3d采样器505a至505f可以将纹理或其他3d图形相关的数据读取到存储器中。3d采样器可以基于所配置的样本状态以及与给定纹理相关联的纹理格式来以不同方式读取纹理数据。媒体采样器506a至506f可以基于与媒体数据相关联的类型和格式来执行类似的读取操作。在一个实施例中,每个图形子核501a至501f可以交替地包括统一3d和媒体采样器。在子核501a至501f中的每一个内的执行单元上执行的线程可以利用每个子核内的共享本地存储器508a至508f,以便使得在线程组内执行的线程能够使用公共片上存储器池来执行。执行单元图6a至图6b展示了根据本文所描述的实施例的包括在图形处理器核中所采用的处理元件阵列的线程执行电路600。图6a至图6b的具有与本文任何其他附图中的元件相同的参考号(或名称)的那些元件可采用与在本文中其他地方描述的方式相类似的任何方式进行操作或起作用,但不限于这些。图6a展示了线程执行电路600(或者线程执行电路600)的概览,所述线程执行逻辑可以包括被展示为具有图5的每个子核501a至501f的硬件逻辑的变体。图6b展示了执行单元的示例性内部细节。如图6a中所示,在一些实施例中,线程执行电路600包括着色器处理器602、线程分派器604、指令高速缓存606、包括多个执行单元608a至608n的可缩放执行单元阵列、采样器610、数据高速缓存612、以及数据端口614。在一个实施例中,可缩放执行单元阵列可以通过基于工作负荷的计算需求来启用或禁用一个或多个执行单元(例如,执行单元608a,608b,608c,608d,一直到608n-1和608n中的任一个)来动态地缩放。在一个实施例中,所包括的部件经由互连结构而互连,所述互连结构链接到部件中的每个部件。在一些实施例中,线程执行电路600包括通过指令高速缓存606、数据端口614、采样器610、以及执行单元阵列608a至608n中的一者或多者到存储器(如系统存储器或高速缓存存储器)的一个或多个连接件。在一些实施例中,每个执行单元(例如,608a)是能够执行多个同步硬件线程同时针对每个线程并行地处理多个数据元素的独立可编程通用计算单元。在各种实施例中,执行单元608a至608n的阵列是可缩放的以包括任意数量的单独执行单元。在一些实施例中,执行单元608a至608n主要用于执行着色器程序。着色器处理器602可以处理各种着色器程序并且经由线程分派器604分派与着色器程序相关联的执行线程。在一个实施例中,线程分派器包括用于对来自图形和媒体流水线的线程发起请求进行仲裁并且在一个或多个执行单元608a至608n上实例化所请求的线程的逻辑。例如,几何流水线可以将顶点处理、曲面细分或几何处理线程分派至线程执行逻辑进行处理。在一些实施例中,线程分派器604还可处理来自执行着色器程序的运行时间线程生成请求。在一些实施例中,执行单元608a至608n支持指令集(所述指令集包括对许多标准3d图形着色器指令的原生支持),从而使得以最小的转换执行来自图形库(例如,direct3d和opengl)的着色器程序。这些执行单元支持顶点和几何处理(例如,顶点程序、几何程序、顶点着色器)、像素处理(例如,像素着色器、片段着色器)以及通用处理(例如,计算和媒体着色器)。执行单元608a至608n中的每一个都能够执行多发布单指令多数据(simd),并且多线程操作能够在面对较高等待时间的存储器访问时实现高效的执行环境。每个执行单元内的每个硬件线程都具有专用的高带宽寄存器堆和相关的独立线程状态。对于具有整数、单精度浮点运算和双精度浮点运算、simd分支功能、逻辑运算、超越运算和其他混杂运算的流水线,执行是每个时钟的多发布。在等待来自存储器或共享功能之一的数据时,执行单元608a至608n内的依赖性逻辑使等待线程休眠,直到所请求的数据已返回。当等待线程正在休眠时,硬件资源可能会专门用于处理其他线程。例如,在与顶点着色器操作相关联的延迟期间,执行单元可以执行像素着色器、片段着色器或包括不同顶点着色器的另一种类型的着色器程序的操作。执行单元608a至608n中的每个执行单元在数据元素阵列上进行操作。数据元素的数量是“执行大小”、或指令的信道数。执行通道是执行数据元素访问、掩蔽、和指令内的流控制的逻辑单元。通道的数量可以与针对特定图形处理器的物理算术逻辑单元(alu)或浮点单元(fpu)的数量无关。在一些实施例中,执行单元608a至608n支持整数和浮点数据类型。执行单元指令集包括simd指令。各种数据元素可作为压缩数据类型存储在寄存器中,并且执行单元将基于元素的数据大小来处理各种元素。例如,当在256位宽的向量上进行操作时,所述256位的向量存储在寄存器中,并且所述执行单元作为四个单独64位压缩数据元素(四倍字长(qw)大小的数据元素)、八个单独32位压缩数据元素(双倍字长(dw)大小的数据元素)、十六个单独16位压缩数据元素(字长(w)大小的数据元素)、或三十二个单独8位数据元素(字节(b)大小的数据元素)在所述向量上进行操作。然而,不同的向量宽度和寄存器大小是可能的。在一个实施例中,可以将一个或多个执行单元组合到融合执行单元609a至609n中,所述融合执行单元具有对于融合eu而言共同的线程控制逻辑(607a至607n)。可以将多个eu融合到一个eu组中。所述融合eu组中的每个eu可以被配置成执行单独的simd硬件线程。融合eu组中的eu数量可以根据实施例而变化。另外,可以每个eu地执行不同的simd宽度,包括但不限于simd8、simd16和simd32。每个融合图形执行单元609a至609n包括至少两个执行单元。例如,融合执行单元609a包括第一eu608a、第二eu608b、以及对于第一eu608a和第二eu608b而言共同的线程控制逻辑607a。线程控制逻辑607a控制在融合图形执行单元609a上执行的线程,从而允许融合执行单元609a至609n内的每个eu使用共同指令指针寄存器来执行。一个或多个内部指令高速缓存(例如,606)包括在所述线程执行电路600中以便高速缓存所述执行单元的线程指令。在一些实施例中,一个或多个数据高速缓存(例如,612)被包括用于高速缓存在线程执行过程中的线程数据。在一些实施例中,采样器610被包括用于为3d操作提供纹理采样并且为媒体操作提供媒体采样。在一些实施例中,采样器610包括专门的纹理或媒体采样功能,以便在向执行单元提供采样数据之前在采样过程中处理纹理或媒体数据。在执行过程中,图形和媒体流水线经由线程生成和分派逻辑向线程执行电路600发送线程发起请求。一旦一组几何对象已经被处理并被光栅化成像素数据,则着色器处理器602内的像素处理器逻辑(例如,像素着色器逻辑、片段着色器逻辑等)被调用以便进一步计算输出信息并且使得结果被写入到输出表面(例如,色彩缓冲器、深度缓冲器、模板印刷(stencil)缓冲器等)。在一些实施例中,像素着色器或片段着色器计算各顶点属性的值,所述各顶点属性跨光栅化对象被内插。在一些实施例中,着色器处理器602内的像素处理器逻辑然后执行应用编程接口(api)供应的像素或片段着色器程序。为了执行着色器程序,着色器处理器602经由线程分派器604将线程分派至执行单元(例如,608a)。在一些实施例中,着色器处理器602使用采样器610中的纹理采样逻辑来访问存储器中所存储的纹理图中的纹理数据。对纹理数据和输入几何数据的算术运算计算每个几何片段的像素颜色数据,或丢弃一个或多个像素而不进行进一步处理。在一些实施例中,数据端口614提供存储器访问机制,供线程执行电路600将经处理的数据输出至存储器以便在图形处理器输出流水线上进行进一步处理。在一些实施例中,数据端口614包括或耦合至一个或多个高速缓存存储器(例如,数据高速缓存612)从而经由数据端口来高速缓存数据以供存储器访问。如图6b中所展示的,图形执行单元608可以包括指令取出单元637、通用寄存器堆阵列(grf)624、架构寄存器堆阵列(arf)626、线程仲裁器622、发送单元630、分支单元632、一组simd浮点单元(fpu)634、以及在一个实施例中的一组专用整数simdalu635。grf624和arf626包括与在图形执行单元608中可能活跃的每个同步的硬件线程相关联的所述一组通用寄存器堆和架构寄存器堆。在一个实施例中,在arf626中维持每线程架构状态,而在线程执行期间所使用的数据被存储在grf624中。每个线程的执行状态,包括每个线程的指令指针,可以保持在arf626中的线程专用寄存器中。在一个实施例中,图形执行单元608具有作为同步多线程化(smt)与细粒度交织多线程化(imt)的组合的架构。所述架构具有模块化配置,所述模块化配置可以基于每执行单元的目标同步线程数量和目标寄存器数量而在设计时得到微调,在所述模块化配置中,跨用于执行多个同步线程的逻辑来划分执行单元资源。在一个实施例中,图形执行单元608可以共同发布多条指令,这些指令可以各自是不同的指令。图形执行单元线程608的线程仲裁器622可以将指令分派给以下各项中的一项以供执行:发送单元630、分支单元642或(多个)simdfpu634。每个执行线程可以访问grf624内的128个通用寄存器,其中,每个寄存器可以存储可作为具有32位数据元素的simd8元素向量访问的32个字节。在一个实施例中,每个执行单元线程访问grf624内的4个千字节,但是实施例并不限于此,并且在其他实施例中可以提供更多或更少的寄存器资源。在一个实施例中,多达七个线程可以同步执行,但是每执行单元的线程数量还可以根据实施例而变化。在七个线程可以访问4个千字节的实施例中,grf624可以存储总共28千字节。灵活寻址模式可以准许对多个寄存器进行一起寻址,从而高效地建立更宽的寄存器或者表示跨步矩形块数据结构。在一个实施例中,经由通过消息传递发送单元630所执行的“发送”指令来分派存储器操作、采样器操作以及其他较长时延系统通信。在一个实施例中,分支指令被分派给专用分支单元632以便促进simd发散和最终收敛。在一个实施例中,图形执行单元608包括用于执行浮点运算的一个或多个simd浮点单元(fpu)634。在一个实施例中,(多个)fpu634还支持整数计算。在一个实施例中,(多个)fpu634可以simd执行多达数量m个32位浮点(或整数)运算,或者simd执行多达2m个16位整数或16位浮点运算。在一个实施例中,(多个)fpu中的至少一个提供支持高吞吐量超越数学功能和双精度64位浮点的扩展数学能力。在一些实施例中,一组8位整数simdalu635还表示并且还可以具体地优化成执行与机器学习计算相关联的运算。在一个实施例中,可以在图形子核分组(例如,子切片)时对图形执行单元608的多个实例的阵列进行实例化。为了可伸缩性,产品架构可以选择每子核分组的确切执行单元数量。在一个实施例中,执行单元608可以跨多个执行通道来执行指令。在进一步的实施例中,在图形执行单元608上所执行的每个线程是在不同通道上执行的。图7是展示了根据一些实施例的图形处理器指令格式700的框图。在一个或多个实施例中,图形处理器执行单元支持具有多种格式的指令的指令集。实线框展示了通常包括在执行单元指令中的部件,而虚线包括可选的部件或仅包括在指令子集中的部件。在一些实施例中,所描述和展示的指令格式700是宏指令,因为它们是供应至执行单元的指令,这与从指令解码产生的微操作相反(一旦所述指令被处理)。在一些实施例中,图形处理器执行单元原生地支持采用128位指令格式710的指令。64位紧凑指令格式730可用于基于所选指令、多个指令选项和操作数数量的一些指令。原生128位指令格式710提供对所有指令选项的访问,而一些选项和操作限制在64位格式730中。64位格式730中可用的原生指令根据实施例而不同。在一些实施例中,使用索引字段713中的一组索引值将指令部分地压缩。执行单元硬件基于索引值来参考一组压缩表,并使用压缩表输出来重构采用128位指令格式710的原生指令。针对每种格式,指令操作码712限定执行单元要执行的操作。执行单元跨每个操作数的多个数据元素来并行地执行每条指令。例如,响应于添加指令,执行单元跨每个颜色通道执行同步添加操作,所述颜色通道表示纹理元素或图片元素。默认地,执行单元跨操作数的所有数据通道执行每条指令。在一些实施例中,指令控制字段714使能控制某些执行选项,诸如通道选择(例如,预测)以及数据通道排序(例如,混合)。针对采用128位指令格式710的指令,执行大小字段716限制了将并行执行的数据通道的数量。在一些实施例中,执行大小字段716不可用于64位紧凑指令格式730。一些执行单元指令具有多达三个操作数,包括两个源操作数(src0720、src1722)和一个目的地718。在一些实施例中,执行单元支持双目的地指令,其中这些目的地之一是隐式的。数据操作指令可以具有第三源操作数(例如,src2724),其中,指令操作码712确定源操作数的数量。指令的最后的源操作数可以是利用所述指令传递的即时(例如,硬编码)值。在一些实施例中,128位指令格式710包括访问/地址模式字段726,所述访问/地址模式信息例如指定了是使用直接寄存器寻址模式还是间接寄存器寻址模式。当使用直接寄存器寻址模式时,直接由指令中的位来提供一个或多个操作数的寄存器地址。在一些实施例中,128位指令格式710包括访问/地址模式字段726,所述访问/地址模式字段指定指令的地址模式和/或访问模式。在一个实施例中,访问模式用于限定针对指令的数据访问对齐。一些实施例支持访问模式,包括16字节对齐访问模式和1字节对齐访问模式,其中,访问模式的字节对齐确定了指令操作数的访问对齐。例如,当在第一模式中时,指令可以使用字节对齐寻址以用于源操作数和目的地操作数,并且当在第二模式中时,指令可以使用16字节对齐寻址以用于所有的源操作数和目的地操作数。在一个实施例中,访问/地址模式字段726的地址模式部分确定指令是使用直接寻址还是间接寻址。当使用直接寄存器寻址模式时,指令中的位直接提供一个或多个操作数的寄存器地址。当使用间接寄存器寻址模式时,可以基于指令中的地址寄存器值和地址立即数字段来计算一个或多个操作数的寄存器地址。在一些实施例中,基于操作码712位字段对指令进行分组从而简化操作码解码740。针对8位的操作码,第4、5、和6位允许执行单元确定操作码的类型。所示出的精确操作码分组仅是示例性的。在一些实施例中,移动和逻辑操作码组742包括数据移动和逻辑指令(例如,移动(mov)、比较(cmp))。在一些实施例中,移动和逻辑组742共享五个最高有效位(msb),其中移动(mov)指令采用0000xxxxb的形式,而逻辑指令采用0001xxxxb的形式。流控制指令组744(例如,调用(call)、跳(jmp))包括采用0010xxxxb形式(例如,0x20)的指令。混杂指令组746包括指令的混合,包括采用0011xxxxb形式(例如,0x30)的同步指令(例如,等待(wait)、发送(send))。并行数学指令组748包括采用0100xxxxb形式(例如,0x40)的按分量的算术指令(例如,加(add)、乘(mul))。并行数学组748跨数据通道并行地执行算术运算。向量数学组750包括采用0101xxxxb形式(例如,0x50)的算术指令(例如,dp4)。向量数学组对向量操作数执行算术运算,诸如点积运算。图形流水线图8是图形处理器800的另一个实施例的框图。图8的具有与此处任何其他附图中的元件相同的参考号(或名称)的那些元件可采用与在本文中其他地方描述的方式相类似的任何方式进行操作或起作用,但不限于这些。在一些实施例中,图形处理器800包括几何流水线820、媒体流水线830、显示引擎840、线程执行逻辑850、以及渲染输出流水线870。在一些实施例中,图形处理器800是包括一个或多个通用处理核的多核处理系统内的图形处理器。图形处理器受到至一个或多个控制寄存器(未示出)的寄存器写入的控制或者经由环形互连802经由发布至图形处理器800的命令被控制。在一些实施例中,环形互连802将图形处理器800耦合至其他处理部件,比如其他图形处理器或通用处理器。来自环形互连802的命令通过命令流转化器803被解译,所述命令流转化器将指令供应至几何流水线820或媒体流水线830的单独部件。在一些实施例中,命令流转化器803引导顶点获取器805的操作,所述顶点获取器从存储器读取顶点数据并执行由命令流转化器803所提供的顶点处理命令。在一些实施例中,顶点获取器805将顶点数据提供给顶点着色器807,所述顶点着色器对每个顶点执行坐标空间变换和照明操作。在一些实施例中,顶点获取器805和顶点着色器807通过经由线程分派器831向执行单元852a至852b分派执行线程来执行顶点处理指令。在一些实施例中,执行单元852a至852b是具有用于执行图形和媒体操作的指令集的向量处理器阵列。在一些实施例中,执行单元852a至852b具有附接的l1高速缓存851,所述高速缓存专用于每个阵列或在阵列之间共享。高速缓存可以被配置为数据高速缓存、指令高速缓存、或单个高速缓存,所述单个高速缓存被分区为包含不同分区中的数据和指令。在一些实施例中,几何流水线820包括用于执行3d对象的硬件加速曲面细分的曲面细分部件。在一些实施例中,可编程的外壳着色器811配置曲面细分操作。可编程域着色器817提供对曲面细分输出的后端评估。曲面细分器813在外壳着色器811的方向上进行操作并且包含专用逻辑,所述专用逻辑用于基于粗糙几何模型来生成详细的几何对象集合,所述粗糙几何模型作为输入被提供至几何流水线820。在一些实施例中,如果未使用曲面细分,则可以对曲面细分部件(例如,外壳着色器811、曲面细分器813、域着色器817)进行旁路。在一些实施例中,完整的几何对象可以由几何着色器819经由被分派至所述执行单元852a至852b的一个或多个线程来处理、或者可以直接行进至剪辑器829。在一些实施例中,几何着色器在整个几何对象(而非顶点或者如图形流水线的先前级中的顶点补片(patch))上进行操作。如果禁用曲面细分,则几何着色器819从顶点着色器807接收输入。在一些实施例中,几何着色器819可由几何着色器程序编程以便在曲面细分单元被禁用时执行几何曲面细分。在光栅化之前,剪辑器829处理顶点数据。剪辑器829可以是固定功能的剪辑器或者具有剪辑和几何着色器功能的可编程剪辑器。在一些实施例中,渲染输出流水线870中的光栅化器和深度测试部件873分派像素着色器以将几何对象转换成每像素表示。在一些实施例中,像素着色器逻辑包括在线程执行逻辑850中。在一些实施例中,应用可对光栅化器和深度测试部件873进行旁路并且经由流出单元823访问未光栅化的顶点数据。图形处理器800具有互连总线、互连结构、或某个其他的互连机制,所述互连机制允许数据和消息在所述图形处理器的主要部件之中传递。在一些实施例中,执行单元852a至852b和相关联的逻辑单元(例如,l1高速缓存851、采样器854、纹理高速缓存858等)经由数据端口856进行互连,以便执行存储器访问并且与处理器的渲染输出流水线部件进行通信。在一些实施例中,采样器854、高速缓存851、858以及执行单元852a至852b各自具有单独的存储器访问路径。在一个实施例中,纹理高速缓存858还可被配置成采样器高速缓存。在一些实施例中,渲染输出流水线870包含光栅化器和深度测试部件873,所述光栅化器和深度测试部件将基于顶点的对象转换为相关联的基于像素的表示。在一些实施例中,光栅化器逻辑包括用于执行固定功能三角形和线光栅化的窗口器/掩蔽器单元。相关联的渲染高速缓存878和深度高速缓存879在一些实施例中也是可用的。像素操作部件877对数据进行基于像素的操作,然而在一些实例中,与2d操作(例如,利用混合的位块图像传递)相关联的像素操作由2d引擎841执行、或者在显示时间由显示控制器843使用重叠显示平面来代替。在一些实施例中,共享的l3高速缓存875可用于所有的图形部件,从而允许在无需使用主系统存储器的情况下共享数据。在一些实施例中,图形处理器媒体流水线830包括媒体引擎837和视频前端834。在一些实施例中,视频前端834从命令流转化器803接收流水线命令。在一些实施例中,媒体流水线830包括单独的命令流转化器。在一些实施例中,视频前端834在将所述命令发送至媒体引擎837之前处理媒体命令。在一些实施例中,媒体引擎837包括用于生成线程以用于经由线程分派器831分派至线程执行逻辑850的线程生成功能。在一些实施例中,图形处理器800包括显示引擎840。在一些实施例中,显示引擎840在处理器800外部并且经由环形互连802、或某个其他互连总线或机构与图形处理器耦合。在一些实施例中,显示引擎840包括2d引擎841和显示控制器843。在一些实施例中,显示引擎840包含能够独立于3d流水线而操作的专用逻辑。在一些实施例中,显示控制器843与显示设备(未示出)耦合,所述显示设备可以是系统集成显示设备(如在膝上型计算机中)、或者经由显示设备连接器附接的外部显示设备。在一些实施例中,几何流水线820和媒体流水线830可被配置成用于基于多个图形和媒体编程接口执行操作并且并非专用于任何一种应用编程接口(api)。在一些实施例中,图形处理器的驱动器软件将专用于特定图形或媒体库的api调度转换成可由图形处理器处理的命令。在一些实施例中,为全部来自khronosgroup的开放图形库(opengl)、开放计算语言(opencl)和/或vulkan图形和计算api提供了支持。在一些实施例中,也可以为微软公司的direct3d库提供支持。在一些实施例中,可以支持这些库的组合。还可以为开源计算机视觉库(opencv)提供支持。如果可做出从未来api的流水线到图形处理器的流水线的映射,则具有兼容3d流水线的未来api也将受到支持。图形流水线编程图9a是展示了根据一些实施例的图形处理器命令格式900的框图。图9b是展示了根据实施例的图形处理器命令序列910的框图。图9a中的实线框展示了通常包括在图形命令中的部件,而虚线包括是可选的或者仅包括在所述图形命令的子集中的部件。图9a的示例性图形处理器命令格式900包括用于标识客户端902、命令操作代码(操作码)904、以及用于命令的数据906的数据字段。一些命令中还包括子操作码905和命令大小908。在一些实施例中,客户端902指定了处理命令数据的图形设备的客户端单元。在一些实施例中,图形处理器命令解析器检查每个命令的客户端字段以便调整对命令的进一步处理并将命令数据路由至合适的客户端单元。在一些实施例中,图形处理器客户端单元包括存储器接口单元、渲染单元、2d单元、3d单元、和媒体单元。每个客户端单元具有对命令进行处理的相应处理流水线。一旦命令被客户端单元接收到,客户端单元就读取操作码904以及子操作码905(如果存在的话)从而确定要执行的操作。客户端单元使用数据字段906内的信息来执行命令。针对一些命令,期望显式的命令大小908来指定命令的大小。在一些实施例中,命令解析器基于命令操作码自动地确定命令中的至少一些命令的大小。在一些实施例中,经由双倍字长的倍数对命令进行对齐。图9b中的流程图示出了示例性图形处理器命令序列910。在一些实施例中,以图形处理器的实施例为特征的数据处理系统的软件或固件使用所示出的命令序列的版本来启动、执行并终止图形操作集合。仅出于示例性目的示出并描述了样本命令序列,如实施例并不限于这些特定命令或者此命令序列。而且,所述命令可以作为一批命令以命令序列被发布,从而使得图形处理器将以至少部分同时的方式处理命令序列。在一些实施例中,图形处理器命令序列910可以以流水线转储清除命令912开始以便使得任一活跃图形流水线完成针对所述流水线的当前未决命令。在一些实施例中,3d流水线922和媒体流水线924不同时进行操作。执行流水线转储清除以使得活动图形流水线完成任何未决命令。响应于流水线转储清除,用于图形处理器的命令解析器将停止命令处理直到活跃绘画引擎完成未决操作并且使得相关的读高速缓存失效。可选地,渲染高速缓存中被标记为‘脏’的任何数据可以被转储清除到存储器中。在一些实施例中,流水线转储清除命令912可以用于流水线同步或者用在将图形处理器置于低功率状态之前。在一些实施例中,当命令序列需要图形处理器在流水线之间显式地地切换时,使用流水线选择命令913。在一些实施例中,在发布流水线命令之前在执行情境中仅需要一次流水线选择命令913,除非所述情境要发布针对两条流水线的命令。在一些实施例中,在经由流水线选择命令913的流水线切换之前正好需要流水线转储清除命令912。在一些实施例中,流水线控制命令914配置用于操作的图形流水线并且用于对3d流水线922和媒体流水线924进行编程。在一些实施例中,流水线控制命令914配置活跃流水线的流水线状态。在一个实施例中,流水线控制命令914用于流水线同步并且用于在处理一批命令之前清除来自活跃流水线内的一个或多个高速缓存存储器中的数据。在一些实施例中,返回缓冲器状态命令916用于配置返回缓冲器的集合以供相应的流水线写入数据。一些流水线操作需要分配、选择、或配置一个或多个返回缓冲器,在处理过程中所述操作将中间数据写入所述一个或多个返回缓冲器中。在一些实施例中,图形处理器还使用一个或多个返回缓冲器以便存储输出数据并且执行跨线程通信。在一些实施例中,返回缓冲器状态916包括选择返回缓冲器的大小和数量以用于流水线操作集合。命令序列中的剩余命令基于用于操作的活跃流水线而不同。基于流水线判定920,所述命令序列被定制用于以3d流水线状态930开始的3d流水线922、或者在媒体流水线状态940处开始的媒体流水线924。用于配置3d流水线状态930的命令包括用于顶点缓冲器状态、顶点元素状态、常量颜色状态、深度缓冲器状态、以及有待在处理3d图元命令之前配置的其他状态变量的3d状态设置命令。这些命令的值至少部分地基于使用中的特定3dapi来确定。在一些实施例中,3d流水线状态930命令还能够选择性地禁用或旁路掉特定流水线元件(如果将不使用那些元件的话)。在一些实施例中,3d图元932命令用于提交待由3d流水线处理的3d图元。经由3d图元932命令传递给图形处理器的命令和相关联参数将被转发到所述图形流水线中的顶点获取功能。顶点获取功能使用3d图元932命令数据来生成多个顶点数据结构。所述顶点数据结构被存储在一个或多个返回缓冲器中。在一些实施例中,3d图元932命令用于经由顶点着色器对3d图元执行顶点操作。为了处理顶点着色器,3d流水线922将着色器执行线程分派至图形处理器执行单元。在一些实施例中,经由执行934命令或事件触发3d流水线922。在一些实施例中,寄存器写入触发命令执行。在一些实施例中,经由命令序列中的‘前进’(‘go’)或‘拣选’(‘kick’)命令来触发执行。在一个实施例中,使用流水线同步命令来触发命令执行以便通过图形流水线转储清除命令序列。3d流水线将针对3d图元来执行几何处理。一旦完成操作,则对所产生的几何对象进行光栅化,并且像素引擎对所产生的像素进行着色。对于这些操作,还可以包括用于控制像素着色和像素后端操作的附加命令。在一些实施例中,当执行媒体操作时,图形处理器命令序列910跟随在媒体流水线924路径之后。一般地,针对媒体流水线924进行编程的具体用途和方式取决于待执行的媒体或计算操作。在媒体解码过程中,特定的媒体解码操作可以被卸载到所述媒体流水线。在一些实施例中,还可对媒体流水线进行旁路,并且可使用由一个或多个通用处理核提供的资源来整体地或部分地执行媒体解码。在一个实施例中,媒体流水线还包括用于通用图形处理器单元(gpgpu)操作的元件,其中,所述图形处理器用于使用计算着色器程序来执行simd向量运算,所述计算着色器程序与渲染图形图元不是显式地相关的。在一些实施例中,以与3d流水线922相似的方式对媒体流水线924进行配置。将用于配置媒体流水线状态940的一组命令分派或放置到命令队列中,在媒体对象命令942之前。在一些实施例中,用于媒体流水线状态的命令940包括用于配置媒体流水线元件的数据,所述媒体流水线元件将用于处理媒体对象。这包括用于在媒体流水线内配置视频解码和视频编码逻辑的数据,诸如编码或解码格式。在一些实施例中,用于媒体流水线状态的命令940还支持将一个或多个指针用于包含一批状态设置的“间接”状态元件。在一些实施例中,媒体对象命令942将指针供应至媒体对象以用于由媒体流水线进行处理。媒体对象包括存储器缓冲器,所述存储器缓冲器包含待处理的视频数据。在一些实施例中,在发布媒体对象命令942之前,所有的媒体流水线状态必须是有效的。一旦流水线状态被配置并且媒体对象命令942被排队,则经由执行944命令或等效的执行事件(例如,寄存器写入)来触发媒体流水线924。然后可以通过由3d流水线922或媒体流水线924提供的操作对来自媒体流水线924的输出进行后处理。在一些实施例中,以与媒体操作类似的方式来配置和执行gpgpu操作。图形软件架构图10展示了根据一些实施例的数据处理系统1000的示例性图形软件架构。在一些实施例中,软件架构包括3d图形应用1010、操作系统1020、以及至少一个处理器1030。在一些实施例中,处理器1030包括图形处理器1032以及一个或多个通用处理器核1034。图形应用1010和操作系统1020各自在数据处理系统的系统存储器1050中执行。在一些实施例中,3d图形应用1010包含一个或多个着色器程序,所述一个或多个着色器程序包括着色器指令1012。着色器语言指令可以采用高级着色器语言,诸如高级着色器语言(hlsl)或opengl着色器语言(glsl)。所述应用还包括可执行指令1014,所述可执行指令采用适合用于由通用处理器核1034执行的机器语言。所述应用还包括由顶点数据限定的图形对象1016。在一些实施例中,操作系统1020是来自微软公司的操作系统、专用unix式操作系统、或使用linux内核变体的开源unix式操作系统。操作系统1020可以支持图形api1022,诸如direct3dapi、openglapi或vulkanapi。当direct3dapi正在使用时,操作系统1020使用前端着色器编译器1024以将hlsl中的任何着色器指令1012编译成较低级的着色器语言。所述编译可以是即时(jit)编译,或者所述应用可执行着色器预编译。在一些实施例中,在对3d图形应用1010进行编译的过程中,将高级着色器编译成低级着色器。在一些实施例中,着色器指令1012以中间形式提供,诸如由vulkanapi使用的标准便携式中间表示(spir)的版本。在一些实施例中,用户模式图形驱动器1026包含后端着色器编译器1027,所述后端着色器编译器用于将着色器指令1012转换成硬件专用的表示。当在使用openglapi时,将采用glsl高级语言的着色器指令1012传递至用户模式图形驱动器1026以用于编译。在一些实施例中,用户模式图形驱动器1026使用操作系统内核模式功能1028来与内核模式图形驱动器1029进行通信。在一些实施例中,内核模式图形驱动器1029与图形处理器1032进行通信以便分派命令和指令。ip核实现至少一个实施例的一个或多个方面可以由存储在机器可读介质上的代表性代码实现,所述机器可读介质表示和/或限定集成电路诸如处理器内的逻辑。例如,机器可读介质可以包括表示处理器内的各个逻辑的指令。当由机器读取时,所述指令可以使机器制造用于执行本文所述的技术的逻辑。这类表示(称为“ip核”)是集成电路的逻辑的可重复使用单元,所述可重复使用单元可以作为对集成电路的结构进行描述的硬件模型而存储在有形、机器可读介质上。可以将硬件模型供应至在制造集成电路的制造机器上加载硬件模型的各消费者或制造设施。可以制造集成电路,从而使得电路执行与本文所述的实施例中的任一实施例相关联地描述的操作。图11a是展示了根据实施例的可以用于制造集成电路以执行操作的ip核开发系统1100的框图。ip核开发系统1100可以用于生成可并入到更大的设计中或用于构建整个集成电路(例如,soc集成电路)的模块化、可重复使用设计。设计设施1130可采用高级编程语言(例如,c/c++)生成对ip核设计的软件仿真1110。软件仿真1110可用于使用仿真模型1112来设计、测试并验证ip核的行为。仿真模型1112可以包括功能、行为和/或时序仿真。然后可由仿真模型1112来创建或合成寄存器传输级(rtl)设计1115。rtl设计1115是对硬件寄存器之间的数字信号的流动进行建模的集成电路(包括使用建模的数字信号执行的相关联逻辑)的行为的抽象。除了rtl设计1115之外,还可以创建、设计或合成逻辑电平或晶体管电平处的较低层次设计。由此,初始设计和仿真的具体细节可以发生变化。可以由设计设施将rtl设计1115或等效方案进一步合成为硬件模型1120,所述硬件模型可以采用硬件描述语言(hdl)或物理设计数据的某种其他表示。可以进一步仿真或测试hdl以验证ip核设计。可使用非易失性存储器1140(例如,硬盘、闪存、或任何非易失性存储介质)来存储ip核设计以用于递送至第3方制造设施1165。可替代地,可以通过有线连接1150或无线连接1160来传输(例如,经由互联网)ip核设计。制造设施1165然后可以制造至少部分地基于ip核设计的集成电路。所制造的集成电路可被配置用于执行根据本文所述的至少一个实施例的操作。图11b展示了根据本文所描述的一些实施例的集成电路封装体组件1170的截面侧视图。集成电路封装体组件1170展示了如本文所描述的一个或多个处理器或加速器设备的实施方式。封装体组件1170包括连接至衬底1180的多个硬件逻辑单元1172、1174。逻辑1172、1174可以至少部分地在可配置逻辑或固定功能逻辑硬件中实施,并且可以包括(多个)处理器核、(多个)图形处理器或本文所描述的其他加速器设备中的任何的一个或多个部分。每个逻辑单元1172、1174可以在半导体管芯内实施并且经由互连结构1173与衬底1180耦合。互连结构1173可以被配置成在逻辑1172、1174与衬底1180之间路由电信号,并且可以包括互连,如但不限于凸块或支柱。在一些实施例中,互连结构1173可以被配置成路由电信号,如例如,与逻辑1172、1174的操作相关联的输入/输出(i/o)信号和/或功率或接地信号。在一些实施例中,衬底1180是基于环氧树脂的层压衬底。在其他实施例中,封装体衬底1180可以包括其他合适类型的衬底。封装体组件1170可以经由封装体互连1183连接至其他电气设备。封装体互连1183可以耦合至衬底1180的表面以便将电信号路由到其他电气设备,如母板、其他芯片组或多芯片模块。在一些实施例中,逻辑单元1172、1174与桥接器1182电耦合,所述桥接器被配置成在逻辑1172、1174之间路由电信号。桥接器1182可以是为电信号提供路由的密集互连结构。桥接器1182可以包括由玻璃或合适的半导体材料构成的桥式衬底。电路由特征可以在桥接器衬底上形成以便提供逻辑1172、1174之间的芯片到芯片连接。尽管展示了两个逻辑单元1172、1174和桥接器1182,但是本文所描述的实施例可以包括一个或多个管芯上的更多或更少的逻辑单元。所述一个或多个管芯可以由零个或多个桥接器连接,因为在单个管芯上包括逻辑时,可以排除桥接器1182。替代性地,多个管芯或逻辑单元可以由一个或多个桥接器连接。另外,多个逻辑单元、管芯和桥接器可以以包括三维配置等其他可能的配置连接在一起。示例性芯片上系统集成电路图12至图14展示了根据本文所述的各种实施例的可以使用一个或多个ip核来制造的示例性集成电路和相关图形处理器。除了所展示的之外,还可以包括其他逻辑和电路,包括附加的图形处理器/核、外围接口控制器或通用处理器核。图12是展示了根据实施例的可以使用一个或多个ip核来制造的示例性芯片上系统集成电路1200的框图。示例性集成电路1200包括一个或多个应用处理器1205(例如,cpu)、至少一个图形处理器1210,并且另外还可以包括图像处理器1215和/或视频处理器1220,其中的任一项都可以是来自相同或多个不同设计设施的模块化ip核。集成电路1200包括外围或总线逻辑,包括usb控制器1225、uart控制器1230、spi/sdio控制器1235和i2s/i2c控制器1240。另外,集成电路还可以包括显示设备1245,所述显示设备耦合至高清晰度多媒体接口(hdmi)控制器1250和移动行业处理器接口(mipi)显示界面1255中的一项或多项。可以由闪存子系统1260(包括闪存和闪存控制器)来提供存储。可以经由存储器控制器1265来提供存储器接口以访问sdram或sram存储器设备。另外,一些集成电路还包括嵌入式安全引擎1270。图13a至图13b是框图,展示了根据本文所描述的实施例的用于在soc内使用的示例性图形处理器。图13a展示了根据实施例的可以使用一个或多个ip核来制造的芯片上系统集成电路的示例性图形处理器1310。图13b展示了根据实施例的可以使用一个或多个ip核来制造的芯片上系统集成电路的附加示例性图形处理器1340。图13a的图形处理器1310是低功率图形处理器核的示例。图13b的图形处理器1340是较高性能图形处理器核的示例。图形处理器1310、1340中的每一个可以是图12的图形处理器1210的变体。如图13a中所示,图形处理器1310包括顶点处理器1305以及一个或多个片段处理器1315a至1315n(例如,1315a、1315b、1315c、1315d,一直到1315n-1和1315n)。图形处理器1310可以经由单独的逻辑执行不同的着色器程序,使得顶点处理器1305被优化以执行顶点着色器程序的操作,而所述一个或多个片段处理器1315a至1315n执行片段(例如,像素)着色操作以用于片段或像素着色器程序。顶点处理器1305执行3d图形流水线的顶点处理阶段并生成图元和顶点数据。(多个)片段处理器1315a至1315n使用由顶点处理器1305生成的图元和顶点数据来产生显示在显示设备上的帧缓冲器。在一个实施例中,(多个)片段处理器1315a至1315n被优化以执行openglapi中提供的片段着色器程序,这些片段着色器程序可以用于执行与direct3dapi中提供的像素着色器程序相似的操作。另外,图形处理器1310还包括一个或多个存储器管理单元(mmu)1320a至1320b、一个或多个高速缓存1325a至1325b以及一个或多个电路互连1330a至1330b。所述一个或多个mmu1320a至1320b为图形处理器1310包括为顶点处理器1305和/或(多个)片段处理器1315a至1315n提供虚拟到物理地址映射,除了存储在所述一个或多个高速缓存1325a至1325b中的顶点或图像/纹理数据之外,所述虚拟到物理地址映射还可以引用存储在存储器中的顶点或图像/纹理数据。在一个实施例中,所述一个或多个mmu1320a至1320b可以与系统内的包括与图12的所述一个或多个应用处理器1205、图像处理器1215和/或视频处理器1220相关联的一个或多个mmu在内的其他mmu同步,使得每个处理器1205至1220可以参与共享或统一的虚拟存储器系统。根据实施例,所述一个或多个电路互连1330a至1330b使得图形处理器1310能够经由soc的内部总线或经由直接连接来与soc内的其他ip核交互。如图13b中所示,图形处理器1340包括图13a的图形处理器1310的所述一个或多个mmu1320a至1320b、高速缓存1325a至1325b、以及电路互连1330a至1330b。图形处理器1340包括一个或多个着色器核1355a至1355n(例如,1455a、1355b、1355c、1355d、1355e、1355f,一直到1355n-1和1355n),所述一个或多个着色器核提供统一的着色器核架构,在所述统一的着色器核架构中,单个核或类型或核可以执行所有类型的可编程着色器代码包括着色器程序代码以实施顶点着色器、片段着色器和/或计算着色器。存在的确切着色器核数量可以在实施例和实施方式中变化。另外,图形处理器1340包括核间任务管理器1345,所述核间任务管理器充当用于将执行线程分派给一个或多个着色器核1355a至1355n的线程分派器和用于加速分块操作以进行基于分块的渲染的分块单元1358,在所述基于分块的渲染中,针对某一场景的渲染操作在图像空间中被细分,例如以利用场景内的局部空间一致性或优化内部高速缓存的使用。图14a至图14b展示了根据本文所描述的实施例的附加示例性图形处理器逻辑。图14a展示了图形核1400,所述图形核可以包括在图12的图形处理器1210内并且可以是如图13b中的统一着色器核1355a至1355n。图14b展示了适合于部署在多芯片模块上的高度并行的通用图形处理单元1430。如图14a中所示,图形核1400包括对于图形核1400内的执行资源而言共同的共享指令高速缓存1402、纹理单元1418和高速缓存存储器/共享存储器1420。图形核1400可以包括多个切片1401a至1401n或针对每个核分区,并且图形处理器可以包括图形核1400的多个实例。切片1401a至1401n可以包括支持逻辑,所述支持逻辑包括本地指令高速缓存1404a至1404n、线程调度器1406a至1406n、线程分派器1408a至1408n、以及一组寄存器1410a。为了执行逻辑运算,切片1401a至1401n可以包括一组附加功能单元(afu1412a至1412n)、浮点单元(fpu1414a至1414n)、整数算术逻辑单元(alu1416至1416n)、寻址计算单元(acu1413a至1413n)、双精度浮点单元(dpfpu1415a至1415n)、以及矩阵处理单元(mpu1417a至1417n)。这些计算单元中的一些以特定精度进行操作。例如,fpu1414a至1414n可以执行单精度(32位)和半精度(16位)浮点运算,而dpfpu1415a至1415n执行双精度(64位)浮点运算。alu1416a至1416n可以以8位精度、16位精度和32位精度执行可变精度整数运算,并且可以被配置用于混合精度运算。mpu1417a至1417n还可以被配置用于混合精度矩阵运算,包括半精度浮点运算和8位整数运算。mpu1417至1417n可以执行各种各样的矩阵运算以便加速机器学习应用框架,包括使能支持加速的通用矩阵到矩阵乘法(gemm)。afu1412a至1412n可以执行不受浮点单元或整数单元支持的附加逻辑运算,包括三角函数运算(例如,正弦、余弦等)。如图14b中所示出的,通用处理单元(gpgpu)1430可以被配置成使得能够由图形处理单元阵列执行高度并行的计算操作。另外,gpgpu1430可以直接链接到gpgpu的其他实例以便创建多gpu集群,从而提高尤其是深度神经网络的训练速度。gpgpu1430包括用于实现与主机处理器的连接的主机接口1432。在一个实施例中,主机接口1432是pciexpress接口。然而,主机接口还可以是供应方特定的通信接口或通信结构。gpgpu1430从主机处理器接收命令并且使用全局调度器1434将与那些命令相关联的执行线程分发给一组计算集群1436a至1436h。计算集群1436a至1436h共享高速缓存存储器1438。高速缓存存储器1438可以充当计算集群1436a至1436h内的高速缓存存储器的更高级高速缓存。gpgpu1430包括经由一组存储器控制器1442a至1442b与计算集群1436a至1436h耦合的存储器1434a至1434b。在各个实施例中,存储器1434a至1434b可以包括各种类型的存储器设备,包括动态随机存取存储器(dram)或图形随机存取存储器,如同步图形随机存取存储器(sgram),包括图形双倍数据速率(gddr)存储器。在一个实施例中,计算集群1436a至1436h各自包括一组图形核,如图14a的图形核1400,所述图形核可以包括多种类型的整数逻辑单元和浮点逻辑单元,所述多种类型的整数逻辑单元和浮点逻辑单元可以在一定精度范围内执行包括适合于机器学习计算的计算操作。例如并且在一个实施例中,计算集群1436a至1436h中的每一个中的浮点单元中的至少一个子集可以被配置成执行16位或32位浮点运算,而浮点单元的不同子集可以被配置成执行64位浮点运算。gpgpu1430的多个实例可以被配置成作为计算集群进行操作。由计算集群用来进行同步和数据交换的计算机制跨实施例而变化。在一个实施例中,gpgpu1430的多个实例通过主机接口1432进行通信。在一个实施例中,gpgpu1430包括i/o中枢1439,所述i/o中枢将gpgpu1430与实现到gpgpu的其他实例的直接连接的gpu链路1440耦合。在一个实施例中,gpu链路1440耦合至实现gpgpu1430的多个实例之间的通信和同步的专用gpu到gpu桥接器。在一个实施例中,gpu链路1440与高速互连耦合以便向其他gpgpu或并行处理器发射和接收数据。在一个实施例中,gpgpu1430的多个实例位于单独的数据处理系统中并且经由可经由主机接口1432访问的网络设备进行通信。在一个实施例中,除了或作为到主机接口1432的替代方案,gpu链路1440可以被配置成实现到主机处理器的连接。尽管gpgpu1430的所展示配置可以被配置成训练神经网络,但是一个实施例提供了gpgpu1430的替代配置,所述替代配置可以被配置成部署在高性能或低功率推断平台内。在推断配置中,gpgpu1430包括计算集群1436a至1436h中与训练配置有关的更少计算集群。另外,与存储器1434a至1434b相关联的存储器技术可以在推断配置与训练配置之间不同,其中,更高带宽存储器技术专用于训练配置。在一个实施例中,gpgpu1430的推断配置可以支持推断特定指令。例如,推断配置可以提供对一个或多个8位整数点积指令的支持,所述指令通常在部署的神经网络的推断操作期间使用。机器学习概述机器学习算法是可以基于一组数据来学习的算法。机器学习算法的实施例可以被设计成对数据集内的高阶抽象进行建模。例如,图像识别算法可以用于确定给定的输入属于若干种类别中的哪一种;回归算法可以在给定输入的情况下输出数值;并且模式识别算法可以用于生成翻译文本或执行文本至语音和/或语音识别。一种示例类型的机器学习算法是神经网络。存在许多类型的神经网络;一种简单类型的神经网络是前馈网络。可将前馈网络实现为无环图,其中节点布置在层中。通常,前馈网络拓扑包括输入层和输出层,输入层和输出层通过至少一个隐藏层分开。隐藏层将由输入层接收到的输入变换为对在输出层中生成输出有用的表示。网络节点经由边缘全连接至相邻层中的节点,但每个层内的节点之间不存在边缘。在前馈网络的输入层的节点处接收的数据经由激活函数被传播(即,“前馈”)至输出层的节点,所述激活函数基于系数(“权重”)来计算网络中的每个连续层的节点的状态,所述系数分别与连接这些层的边缘中的每一个相关联。取决于由执行的算法所表示的特定模型,来自神经网络算法的输出可以采用各种形式。在可以使用机器学习算法来对具体问题进行建模之前,使用训练数据集来训练所述算法。训练神经网络涉及:选择网络拓扑;使用表示被网络建模的问题的一组训练数据;以及调节权重,直到网络模型针对训练数据集的所有实例表现为具有最小误差。例如,在用于神经网络的监督式学习训练过程期间,将由网络响应于表示训练数据集中的实例的输入所产生的输出与所述实例的“正确”的已标记输出相比较;计算表示所述输出与已标记输出之间的差异的误差信号;以及当将误差信号向后传播穿过网络的层时,调节与所述连接相关联的权重以最小化所述误差。当从训练数据集的实例中生成的每个输出的误差被最小化时,网络被视为“已经过训练”。机器学习算法的准确度会受到用于训练所述算法的数据集的质量的很大影响。训练过程可以是计算密集型的,并且在常规通用处理器上可能需要大量的时间。因此,使用并行处理硬件来训练许多类型的机器学习算法。这对于优化神经网络的训练是特别有用的,因为在调节神经网络中的系数时执行的计算本身自然地适于并行实现方式。具体地,许多机器学习算法和软件应用已被适配成在通用图形处理设备内使用并行处理硬件。图8是机器学习软件堆叠800的广义图。机器学习应用802可以被配置成使用训练数据集来训练神经网络或使用已训练的深度神经网络来实现机器智能。机器学习应用802可以包括神经网络和/或专用软件的训练和推断功能,所述功能可以用于在部署之前训练神经网络。机器学习应用802可以实现任何类型的机器智能,包括但不限于:图像识别、映射和定位、自主导航、语音合成、医学成像或语言翻译。可以经由机器学习框架804来实现针对机器学习应用802的硬件加速。机器学习框架804可以提供机器学习图元(primitive)库。机器学习图元是机器学习算法通常执行的基本操作。在没有机器学习框架804的情况下,将需要机器学习算法的开发者创建和优化与机器学习算法相关联的主要计算逻辑,然后在开发出新的并行处理器时重新优化所述计算逻辑。相反,机器学习应用可以被配置成使用由机器学习框架804提供的图元来执行必要的计算。示例性图元包括张量卷积、激活函数和池化,它们是在训练卷积神经网络(cnn)时执行的计算操作。机器学习框架804还可以提供图元以用于实现由许多机器学习算法执行的基本线性代数子程序,比如矩阵和向量运算。机器学习框架804可以处理从机器学习应用802接收的输入数据,并生成至计算框架806的适当输入。计算框架806可以使提供给gpgpu驱动器808的底层指令抽象化,以使得机器学习框架804能够经由gpgpu硬件810来利用硬件加速而无需机器学习框架804非常熟悉gpgpu硬件810的架构。另外,计算框架806可以跨越多种类型和各代gpgpu硬件810来实现针对机器学习框架804的硬件加速。gpgpu机器学习加速图9展示根据实施例的高度并行的通用图形处理单元900。在一个实施例中,通用处理单元(gpgpu)900可以被配置成在处理与训练深度神经网络相关联的这种类型的计算工作负荷中特别高效。另外,gpgpu900可以直接链接至gpgpu的其他实例以用于创建多gpu集群,从而改进特别深的神经网络的训练速度。gpgpu900包括主机接口902以用于实现与主机处理器的连接。在一个实施例中,主机接口902是pciexpress接口。然而,主机接口还可以是供应方特定的通信接口或通信组构。gpgpu900从主机处理器接收命令,并使用全局调度器904以将与那些命令相关联的执行线程分布至一组计算集群906a至906h。计算集群906a至906h共享高速缓存存储器908。高速缓存存储器908可以充当计算集群906a至906h内的高速缓存存储器中的高级高速缓存。gpgpu900包括存储器914a至914b,所述存储器经由一组存储器控制器912a至912b与计算集群906a至906h耦合。在各种实施例中,存储器914a至914b可以包括各种类型的存储器设备,包括动态随机存取存储器(dram)或图形随机存取存储器(比如,同步图形随机存取存储器(sgram),包括图形双数据速率(gddr)存储器),并且还可包括3d堆叠式存储器,包括但不限于高带宽存储器(hbm)。在一个实施例中,每个计算集群906a至906h包括一组图形多处理器,比如本文中一些附图的图形多处理器400。计算集群的图形多处理器包括多种类型的整数和浮点逻辑单元,这些单元可以在一系列精度(包括适合于机器学习计算的精度)下执行计算操作。例如且在一个实施例中,计算集群906a至906h中的每一者的浮点单元的至少一个子集可以被配置成执行16位或32位浮点运算,而浮点单元的一不同子集可以被配置成执行64位浮点运算。gpgpu900的多个实例可以被配置成作为计算集群来操作。由计算集群用于同步和数据交换的通信机制跨实施例变化。在一个实施例中,gpgpu900的多个实例通过主机接口902来通信。在一个实施例中,gpgpu900包括使gpgpu900与gpu链路910耦合的i/o中枢908,所述gpu链路实现至gpgpu的其他实例的直接连接。在一个实施例中,gpu链路910耦合至专用gpu-gpu桥,所述gpu-gpu桥实现gpgpu900的多个实例之间的通信和同步。在一个实施例中,gpu链路910与高速互连耦合,以用于将数据传输和接收至其他gpgpu或并行处理器。在一个实施例中,gpgpu900的多个实例位于单独的数据处理系统中并且经由网络设备来通信,所述网络设备可经由主机接口902来访问。在一个实施例中,除主机接口902之外或作为主机接口的替代例,gpu链路910也可以被配置成使得能够连接至主机处理器。虽然gpgpu900的所展示配置可以被配置成训练神经网络,但是一个实施例提供了gpgpu900的替代性配置,其可以被配置成用于部署在高性能或低功率推断用平台内。在推断配置中,gpgpu900包括相对于训练配置更少的计算集群906a至906h。另外,与存储器914a至914b相关联的存储器技术可在推断和训练配置之间有所不同。在一个实施例中,gpgpu900的推断配置可以支持推断特定的指令。例如,推断配置可以提供对一个或多个8位整数点积指令的支持,这些指令通常在用于已部署神经网络的推断操作期间使用。图10展示根据实施例的多gpu计算系统1000。多gpu计算系统1000可以包括处理器1002,所述处理器经由主机接口开关1004耦合至多个gpgpu1006a至1006d。在一个实施例中,主机接口开关1004是将处理器1002耦合至pciexpress总线的pciexpress开关设备,处理器1002可以通过所述pciexpress总线与这组gpgpu1006a至1006d通信。多个gpgpu1006a至1006d中的每一个可以是图9的gpgpu900的实例。gpgpu1006a至1006d可以经由一组高速点对点gpu-gpu链路1016互连。高速gpu-gpu链路可以经由专用gpu链路(比如,如图9中的gpu链路910)连接至gpgpu1006a至1006d中的每一个。p2pgpu链路1016使得gpgpu1006a至1006d中的每一个之间能够直接通信,而无需通过主机接口总线(处理器1002连接至所述主机接口总线)来通信。在gpu-gpu业务针对p2pgpu链路的情况下,主机接口总线仍然可用于系统存储器访问或与多gpu计算系统1000的其他实例通信(例如,经由一个或多个网络设备)。虽然在所展示的实施例中gpgpu1006a至1006d经由主机接口开关1004连接至处理器1002,但是在一个实施例中,处理器1002包括对p2pgpu链路1016的直接支持并且可以直接连接至gpgpu1006a至1006d。机器学习神经网络实现方式由本文描述的实施例提供的计算架构可以被配置成执行特别适合于训练和部署用于机器学习的神经网络的这些类型的并行处理。可以将神经网络一般化为具有图表关系的函数的网络。如本领域中所公知的,存在机器学习中所使用的多种类型的神经网络实现方式。一种示例性类型的神经网络是如先前描述的前馈网络。第二种示例性类型的神经网络是卷积神经网络(cnn)。cnn是用于处理具有已知的、网格状拓扑的数据(比如,图像数据)的专用前馈神经网络。因此,cnn通常用于计算机视觉和图像识别应用,但它们也可用于其他类型的模式识别,比如语音和语言处理。cnn输入层中的节点被组织为一组“滤波器”(受视网膜中发现的感受野启发的特征检测器),并且每一组滤波器的输出被传播至网络的连续层中的节点。用于cnn的计算包括将卷积数学运算应用于每个滤波器以产生所述滤波器的输出。卷积是由两个函数执行以产生第三个函数的一种专门的数学运算,所述第三个函数是两个原始函数中的一个的修改版本。在卷积网络术语中,关于卷积的第一个函数可以被称为输入,而第二个函数可以被称为卷积核。输出可被称为特征图。例如,至卷积层的输入可以是多维数据阵列,其定义输入图像的各种颜色分量。卷积核可以是多维参数阵列,其中通过针对神经网络的训练过程来适配所述参数。递归神经网络(rnn)是一类前馈神经网络,其包括层之间的反馈连接。rnn使得能够通过跨神经网络的不同部分共享参数数据来对序列数据进行建模。rnn的架构包括循环。这些循环表示变量的当前值在未来的时间对其自身值的影响,因为来自rnn的输出数据的至少一部分被用作反馈以用于处理序列中的后续输入。由于语言数据可被组成的可变本质,这个特征使rnn变得对语言处理特别有用。下文描述的图呈现了示例性前馈、cnn和rnn网络,以及描述了用于分别训练和部署那些类型的网络中的每一种的通用过程。将理解,这些描述就本文描述的任何特定实施例而论是示例性且非限制性的,并且一般说来可以通常将所展示的概念应用于深度神经网络和机器学习技术。上文描述的示例性神经网络可以用于执行深度学习。深度学习是使用深度神经网络进行的机器学习。与仅包括单个隐藏层的浅层神经网络相反,深度学习中使用的深度神经网络是由多个隐藏层组成的人工神经网络。更具深度的神经网络通常训练起来更具计算密集性。然而,网络的附加隐藏层实现了多步模式识别,所述多步模式识别相对于浅层机器学习技术导致减少的输出误差。深度学习中使用的深度神经网络通常包括前端网络以用于执行耦合至表示数学模型的后端网络的特征识别,所述数学模型可以基于提供给所述模型的特征表示来执行操作(例如,目标分类、语音识别等)。深度学习使得能够执行机器学习,而无需针对所述模型执行手工特征工程。相反,深度神经网络可以基于输入数据内的统计结构或相关性来学习特征。所学习的特征可以提供给数学模型,所述数学模型可以将所检测的特征映射至输出。由网络使用的数学模型通常专用于待执行的特定任务,并且不同的模型将用于执行不同的任务。一旦将神经网络结构化,就可以将学习模型应用于网络以将网络训练成执行特定任务。学习模型描述如何在模型内调节权重以减少网络的输出误差。反向传播误差是一种用于训练神经网络的常用方法。向网络呈现输入向量以供处理。使用损失函数将网络的输出与期望的输出相比较,并且为输出层中的每个神经元计算误差值。然后,向后传播这些误差值,直到每个神经元具有粗略地表示其对原始输出的贡献的相关联误差值。然后,网络可以使用算法(比如,随机梯度下降算法)从那些误差中学习,以更新神经网络的权重。图11a和图11b展示示例性卷积神经网络。图11a展示cnn内的各个层。如图11a中所示,用于对图像处理进行建模的示例性cnn可以接收输入1102,所述输入描述输入图像的红、绿和蓝(rgb)分量。输入1102可以由多个卷积层(例如,卷积层1104、卷积层1106)处理。可选地,来自所述多个卷积层的输出可由一组全连接层1108处理。全连接层中的神经元具有至前一层中的所有激活函数的完全连接,如先前针对前馈网络所描述的。来自全连接层1108的输出可以用于从网络中生成输出结果。可以使用矩阵乘法而非卷积来计算全连接层908内的激活函数。并非所有的cnn实现方式都使用全连接层1108。例如,在一些实现方式中,卷积层1106可以生成cnn的输出。卷积层被稀疏地连接,这不同于全连接层1108中发现的传统神经网络配置。传统神经网络层被全连接,使得每个输出单元与每个输入单元相互作用。然而,卷积层被稀疏地连接,这是因为感受野的卷积的输出(而非感受野中的每个节点的相应状态值)被输入至后续层的节点,如所展示。与卷积层相关联的核执行卷积运算,所述卷积运算的输出被发送至下一个层。在卷积层内执行的降维是使得cnn能够进行缩放以处理大图像的一个方面。图11b展示在cnn的卷积层内的示例性计算阶段。可以在卷积层1114的三个阶段中处理至cnn的卷积层的输入1112。这三个阶段可以包括卷积阶段1116、检测器阶段1118和池化阶段1120。然后,卷积层1114可以将数据输出至连续的卷积层。网络的最后一个卷积层可以生成输出特征图数据或提供至全连接层的输入,例如以生成至cnn的输入的分类值。在卷积阶段1116中并行执行若干个卷积,以产生一组线性激活函数。卷积阶段1116可以包括仿射变换,所述仿射变换是可以被指定为线性变换外加平移的任何变换。仿射变换包括旋转、平移、缩放和这些变换的组合。卷积阶段计算连接至输入中特定区域的函数的输出(例如,神经元),所述特定区域可以被确定为与神经元相关联的本地区域。神经元计算神经元的权重与本地输入(神经元连接至所述本地输入)中的区域之间的点积。来自卷积阶段1116的输出定义由卷积层1114的连续阶段处理的一组线性激活函数。线性激活函数可以由检测器阶段1118处理。在检测器阶段1118中,每个线性激活函数由非线性激活函数处理。非线性激活函数增加整体网络的非线性性质,而不影响卷积层的感受野。可使用若干种类型的非线性激活函数。一个具体的类型是修正线性单元(relu),其使用被定义为f(x)=max(0,x)的激活函数,使得激活函数被阈值化为零。池化阶段1120使用池化函数,所述池化函数用附近输出的概括统计数值来代替卷积层1106的输出。池化函数可以用于将平移不变性引入到神经网络中,使得至输入的轻微平移不改变池化输出。本地平移的不变性在输入数据的特征存在性比特征的精确位置更加重要的情况下可以是有用的。可以在池化阶段1120期间使用各种类型的池化函数,包括最大池化、平均池化和l2范数池化。另外,一些cnn实现方式不包括池化阶段。相反,这样的实现方式代用附加的卷积阶段,所述附加的卷积阶段相对于先前的卷积阶段具有增大的步幅。然后,来自卷积层1114的输出可以由下一个层1122处理。下一个层1122可以是附加的卷积层或是全连接层1108中的一者。例如,图11a的第一卷积层1104可以输出至第二卷积层1106,而第二卷积层可以输出至全连接层1108中的第一层。图12展示了示例性递归神经网络1200。在递归神经网络(rnn)中,网络的先前状态影响网络的当前状态的输出。可以使用各种各样的函数以各种各样的方式来建立rnn。rnn的使用通常围绕使用数学模型以基于先前的输入序列来预测未来。例如,rnn可用于执行统计语言建模以在给定先前的字序列的情况下预测即将来临的字。可以将所展示的rnn1200描述为具有以下各项:输入层1202,其接收输入向量;隐藏层1204,用于实现递归函数;反馈机制1205,用于实现先前状态的‘存储器’;以及输出层1206,用于输出结果。rnn1200基于时间步长来操作。经由反馈机制1205基于先前的时间步长来影响rnn在给定的时间步长的状态。针对给定的时间步长,由先前状态和在当前时间步长的输入来定义隐藏层1204的状态。在第一时间步长的初始输入(x1)可以由隐藏层1204处理。第二输入(x2)可以由隐藏层1204使用在处理初始输入(x1)期间所确定的状态信息来处理。可以将给定的状态计算为st=f(uxt+wst-1),其中,u和w是参数矩阵。函数f通常为非线性,比如双曲正切函数(tanh)或修正函数f(x)=max(0,x)的变体。然而,隐藏层1004中使用的特定数学函数可以取决于rnn1200的特定实现方式细节而变化。除所描述的基本cnn和rnn网络之外,还可实现那些网络的变化。一个示例rnn变体是长短期记忆(lstm)rnn。lstmrnn能够学习对于处理更长的语言序列来说可有必要的长期依赖。cnn的变体是卷积深度置信网络,所述卷积深度置信网络具有类似于cnn的结构并且以类似于深度置信网络的方式受训练。深度置信网络(dbn)是由随机性(随机)变量的多个层组成的生成式神经网络。可以使用贪婪式无监督式学习来逐层训练dbn。然后,dbn的学习权重可以用于通过确定用于神经网络的一组最佳初始权重来提供预训练神经网络。图13展示深度神经网络的训练和部署。一旦已针对任务将给定的网络结构化,就使用训练数据集1302来训练神经网络。已开发出各种训练框架1304以用于实现对训练过程的硬件加速。例如,图8的机器学习框架804可被配置为训练框架1304。训练框架1304可以跟未训练的神经网络1306挂钩,并且使得能够使用本文描述的并行处理资源来训练未训练的神经网以生成已训练的神经网1308。为了开始训练过程,可随机地或通过使用深度置信网络进行预训练来选择初始权重。然后,以监督或无监督的方式来执行训练循环。监督式学习是一种学习方法,其中将训练作为仲裁操作来执行,比如当训练数据集1302包括输入(其与所述输入的期望输出成对)时,或在训练数据集包括具有已知的输出的输入并且神经网络的输出被手动地分级的情况下。网络处理输入,并且将所得输出与一组预期或期望的输出相比较。然后,通过系统反向传播误差。训练框架1304可以进行调节,以调节控制未训练的神经网络1306的权重。训练框架1304可以提供工具以用于监测未训练的神经网络1306在多大程度上收敛于适合基于已知的输入数据生成正确的答案的模型。当调节网络的权重以改善由神经网络生成的输出时,反复地出现训练过程。训练过程可以继续,直到神经网络达到与已训练的神经网1308相关联的统计上期望的准确度。然后,可以部署已训练的神经网络1308以实现任何数量的机器学习操作。无监督式学习是一种学习方法,其中网络试图使用未标记数据来训练其自身。因此,针对无监督式学习,训练数据集1302将包括输入数据而无任何关联的输出数据。未训练的神经网络1306可以学习未标记输入内的分组,并且可以确定个别输入如何与整体数据集相关。无监督式训练可以用于生成自组织映射,所述自组织映射是能够执行在数据降维中有用的操作的一种类型的已训练神经网络1307。无监督式训练还可以用于执行异常检测,所述异常检测允许识别输入数据集中偏离数据正常模式的数据点。还可采用监督式和无监督式训练的变化。半监督式学习是一项技术,其中训练数据集1302包括相同分布的已标记数据和未标记数据的混合。增量学习是监督式学习的变体,其中连续地使用输入数据以用于进一步训练模型。增量学习使得已训练的神经网络1308能够适配于新数据1312,而不忘记在初始训练期间根植在网络内的知识。不管是监督式还是无监督式,用于特别深的神经网络的训练过程对于单个计算节点而言可能是过于计算密集的。可以使用计算节点的分布式网络而非使用单个计算节点来加速训练过程。图14是展示分布式学习的框图。分布式学习是训练模型,其使用多个分布式计算节点来执行神经网络的监督式或无监督式训练。所述分布式计算节点可以各自包括一个或多个主机处理器以及通用处理节点中的一者或多者,诸如,如图9中的高度并行通用图形处理单元900。如所展示,分布式学习可以执行模型并行化1402、数据并行化1404或模型和数据并行化1204的组合。在模型并行化1402中,分布式系统中的不同计算节点可以针对单个网络的不同部分执行训练计算。例如,可以由分布式系统的不同处理节点来训练神经网络的每个层。模型并行化的益处包括能够缩放到特别大的模型。分裂与神经网络的不同层相关联的计算使得能够训练超大神经网络,其中所有层的权重将不纳入(fitinto)单个计算节点的存储器中。在一些实例中,模型并行化在执行大型神经网络的无监督式训练中可以是特别有用的。在数据并行化1404中,分布式网络的不同节点具有模型的完整实例,并且每个节点接收数据的不同部分。然后,组合来自不同节点的结果。虽然用于数据并行化的不同方法是有可能的,但是数据并行训练方法都需要一项组合结果并使每个节点之间的模型参数同步的技术。用于组合数据的示例性方法包括参数求平均和基于更新的数据并行化。参数求平均训练在训练数据的子集上的每个节点,并且将全局参数(例如,权重、偏差)设定至来自每个节点的参数的平均值。参数求平均使用保持参数数据的中心参数服务器。基于更新的数据并行化类似于参数求平均,除了以下情况之外:传递模型的更新而非将来自节点的参数传递到参数服务器。另外,可以以分散的方式执行基于更新的数据并行化,其中更新被压缩并且在节点之间传递。例如,可以在分布式系统中实现经组合的模型和数据并行化1406,在所述分布式系统中,每个计算节点包括多个gpu。每个节点可以具有模型的完整实例,其中每个节点内的单独gpu用于训练模型的不同部分。分布式训练相对于单个机器上的训练具有增加的开销。然而,本文描述的并行处理器和gpgpu可以各自实现各项技术以用于减少分布式训练的开销,包括用于实现高带宽gpu-gpu数据传递和加速的远程数据同步的技术。机器学习概述机器学习算法是可以基于一组数据来学习的算法。机器学习算法的实施例可以被设计成对数据集内的高阶抽象进行建模。例如,图像识别算法可以用于确定给定的输入属于若干种类别中的哪一种;回归算法可以在给定输入的情况下输出数值;并且模式识别算法可以用于生成翻译文本或执行文本至语音和/或语音识别。一种示例类型的机器学习算法是神经网络。存在许多类型的神经网络;一种简单类型的神经网络是前馈网络。可将前馈网络实现为无环图,其中节点布置在层中。通常,前馈网络拓扑包括输入层和输出层,输入层和输出层通过至少一个隐藏层分开。隐藏层将由输入层接收到的输入变换为对在输出层中生成输出有用的表示。网络节点经由边缘全连接至相邻层中的节点,但每个层内的节点之间不存在边缘。在前馈网络的输入层的节点处接收的数据经由激活函数被传播(即,“前馈”)至输出层的节点,所述激活函数基于系数(“权重”)来计算网络中的每个连续层的节点的状态,所述系数分别与连接这些层的边缘中的每一个相关联。取决于由执行的算法所表示的特定模型,来自神经网络算法的输出可以采用各种形式。在可以使用机器学习算法来对具体问题进行建模之前,使用训练数据集来训练所述算法。训练神经网络涉及:选择网络拓扑;使用表示被网络建模的问题的一组训练数据;以及调节权重,直到网络模型针对训练数据集的所有实例表现为具有最小误差。例如,在用于神经网络的监督式学习训练过程期间,将由网络响应于表示训练数据集中的实例的输入所产生的输出与所述实例的“正确”的已标记输出相比较;计算表示所述输出与已标记输出之间的差异的误差信号;以及当将误差信号向后传播穿过网络的层时,调节与所述连接相关联的权重以最小化所述误差。当从训练数据集的实例中生成的每个输出的误差被最小化时,网络被视为“已经过训练”。机器学习算法的准确度会受到用于训练所述算法的数据集的质量的很大影响。训练过程可以是计算密集型的,并且在常规通用处理器上可能需要大量的时间。因此,使用并行处理硬件来训练许多类型的机器学习算法。这对于优化神经网络的训练是特别有用的,因为在调节神经网络中的系数时执行的计算本身自然地适于并行实现方式。具体地,许多机器学习算法和软件应用已被适配成在通用图形处理设备内使用并行处理硬件。图15是机器学习软件堆叠1500的广义图。机器学习应用1502可以被配置成使用训练数据集来训练神经网络或使用已训练的深度神经网络来实现机器智能。机器学习应用1502可以包括神经网络和/或专用软件的训练和推断功能,所述功能可以用于在部署之前训练神经网络。机器学习应用1502可以实现任何类型的机器智能,包括但不限于:图像识别、映射和定位、自主导航、语音合成、医学成像或语言翻译。可以经由机器学习框架1504来实现针对机器学习应用1502的硬件加速。机器学习框架1504可以提供机器学习图元(primitive)库。机器学习图元是机器学习算法通常执行的基本操作。在没有机器学习框架1504的情况下,将需要机器学习算法的开发者创建和优化与机器学习算法相关联的主要计算逻辑,然后在开发出新的并行处理器时重新优化所述计算逻辑。相反,机器学习应用可以被配置成使用由机器学习框架1504提供的图元来执行必要的计算。示例性图元包括张量卷积、激活函数和池化,它们是在训练卷积神经网络(cnn)时执行的计算操作。机器学习框架1504还可以提供图元以用于实现由许多机器学习算法执行的基本线性代数子程序,比如矩阵和向量运算。机器学习框架1504可以处理从机器学习应用1502接收的输入数据,并生成至计算框架1506的适当输入。计算框架1506可以使提供给gpgpu驱动器1508的底层指令抽象化,以使得机器学习框架1504能够经由gpgpu硬件1510来利用硬件加速而无需机器学习框架1504非常熟悉gpgpu硬件1510的架构。另外,计算框架1506可以跨越多种类型和各代gpgpu硬件1510来实现针对机器学习框架1504的硬件加速。机器学习神经网络实现方式由本文描述的实施例提供的计算架构可以被配置成执行特别适合于训练和部署用于机器学习的神经网络的这些类型的并行处理。可以将神经网络一般化为具有图表关系的函数的网络。如本领域中所知道的,存在机器学习中所使用的多种类型的神经网络实现方式。一种示例性类型的神经网络是如先前描述的前馈网络。第二种示例性类型的神经网络是卷积神经网络(cnn)。cnn是用于处理具有已知的、网格状拓扑的数据(比如,图像数据)的专用前馈神经网络。因此,cnn通常用于计算机视觉和图像识别应用,但它们也可用于其他类型的模式识别,比如语音和语言处理。cnn输入层中的节点被组织为一组“滤波器”(受视网膜中发现的感受野启发的特征检测器),并且每一组滤波器的输出被传播至网络的连续层中的节点。用于cnn的计算包括将卷积数学运算应用于每个滤波器以产生所述滤波器的输出。卷积是由两个函数执行以产生第三个函数的一种专门的数学运算,所述第三个函数是两个原始函数中的一个的修改版本。在卷积网络术语中,关于卷积的第一个函数可以被称为输入,而第二个函数可以被称为卷积核。输出可被称为特征图。例如,至卷积层的输入可以是多维数据阵列,其定义输入图像的各种颜色分量。卷积核可以是多维参数阵列,其中通过针对神经网络的训练过程来适配所述参数。递归神经网络(rnn)是一类前馈神经网络,其包括层之间的反馈连接。rnn使得能够通过跨神经网络的不同部分共享参数数据来对序列数据进行建模。rnn的架构包括循环。这些循环表示变量的当前值在未来的时间对其自身值的影响,因为来自rnn的输出数据的至少一部分被用作反馈以用于处理序列中的后续输入。由于语言数据可被组成的可变本质,这个特征使rnn变得对语言处理特别有用。下文描述的图呈现了示例性前馈、cnn和rnn网络,以及描述了用于分别训练和部署那些类型的网络中的每一种的通用过程。将理解,这些描述就本文描述的任何特定实施例而论是示例性且非限制性的,并且一般说来可以通常将所展示的概念应用于深度神经网络和机器学习技术。上文描述的示例性神经网络可以用于执行深度学习。深度学习是使用深度神经网络进行的机器学习。与仅包括单个隐藏层的浅层神经网络相反,深度学习中使用的深度神经网络是由多个隐藏层组成的人工神经网络。更具深度的神经网络通常训练起来更具计算密集性。然而,网络的附加隐藏层实现了多步模式识别,所述多步模式识别相对于浅层机器学习技术导致减少的输出误差。深度学习中使用的深度神经网络通常包括前端网络以用于执行耦合至表示数学模型的后端网络的特征识别,所述数学模型可以基于提供给所述模型的特征表示来执行操作(例如,目标分类、语音识别等)。深度学习使得能够执行机器学习,而无需针对所述模型执行手工特征工程。相反,深度神经网络可以基于输入数据内的统计结构或相关性来学习特征。所学习的特征可以提供给数学模型,所述数学模型可以将所检测的特征映射至输出。由网络使用的数学模型通常专用于待执行的特定任务,并且不同的模型将用于执行不同的任务。一旦将神经网络结构化,就可以将学习模型应用于网络以将网络训练成执行特定任务。学习模型描述如何在模型内调节权重以减少网络的输出误差。反向传播误差是一种用于训练神经网络的常用方法。向网络呈现输入向量以供处理。使用损失函数将网络的输出与期望的输出相比较,并且为输出层中的每个神经元计算误差值。然后,向后传播这些误差值,直到每个神经元具有粗略地表示其对原始输出的贡献的相关联误差值。然后,网络可以使用算法(比如,随机梯度下降算法)从那些误差中学习,以更新神经网络的权重。图16a-16b展示示例性卷积神经网络。图16a展示cnn内的各个层。如图16a中所示,用于对图像处理进行建模的示例性cnn可以接收输入1602,所述输入描述输入图像的红、绿和蓝(rgb)分量。输入1602可以由多个卷积层(例如,第一卷积层1604、第二卷积层1606)处理。可选地,来自所述多个卷积层的输出可由一组全连接层1608处理。全连接层中的神经元具有至前一层中的所有激活函数的完全连接,如先前针对前馈网络所描述的。来自全连接层1608的输出可以用于从网络中生成输出结果。可以使用矩阵乘法而非卷积来计算全连接层1608内的激活函数。并非所有的cnn实现方式都使用全连接层1608。例如,在一些实现方式中,第二卷积层1606可以生成cnn的输出。卷积层被稀疏地连接,这不同于全连接层1608中发现的传统神经网络配置。传统神经网络层被全连接,使得每个输出单元与每个输入单元相互作用。然而,卷积层被稀疏地连接,这是因为感受野的卷积的输出(而非感受野中的每个节点的相应状态值)被输入至后续层的节点,如所展示。与卷积层相关联的核执行卷积运算,所述卷积运算的输出被发送至下一个层。在卷积层内执行的降维是使得cnn能够进行缩放以处理大图像的一个方面。图16b展示在cnn的卷积层内的示例性计算阶段。可以在卷积层1614的三个阶段中处理至cnn的卷积层的输入1612。这三个阶段可以包括卷积阶段1616、检测器阶段1618和池化阶段1620。然后,卷积层1614可以将数据输出至连续的卷积层。网络的最后一个卷积层可以生成输出特征图数据或提供至全连接层的输入,例如以生成至cnn的输入的分类值。在卷积阶段1616中并行执行若干个卷积,以产生一组线性激活函数。卷积阶段1616可以包括仿射变换,所述仿射变换是可以被指定为线性变换外加平移的任何变换。仿射变换包括旋转、平移、缩放和这些变换的组合。卷积阶段计算连接至输入中特定区域的函数的输出(例如,神经元),所述特定区域可以被确定为与神经元相关联的本地区域。神经元计算神经元的权重与本地输入(神经元连接至所述本地输入)中的区域之间的点积。来自卷积阶段1616的输出定义由卷积层1614的连续阶段处理的一组线性激活函数。线性激活函数可以由检测器阶段1618处理。在检测器阶段1618中,每个线性激活函数由非线性激活函数处理。非线性激活函数增加整体网络的非线性性质,而不影响卷积层的感受野。可使用若干种类型的非线性激活函数。一个具体的类型是修正线性单元(relu),其使用被定义为f(x)=max(0,x)的激活函数,使得激活函数被阈值化为零。池化阶段1620使用池化函数,所述池化函数用附近输出的概括统计数值来代替第二卷积层1606的输出。池化函数可以用于将平移不变性引入到神经网络中,使得至输入的轻微平移不改变池化输出。本地平移的不变性在输入数据的特征存在性比特征的精确位置更加重要的情况下可以是有用的。可以在池化阶段1620期间使用各种类型的池化函数,包括最大池化、平均池化和l2范数池化。另外,一些cnn实现方式不包括池化阶段。相反,这样的实现方式代用附加的卷积阶段,所述附加的卷积阶段相对于先前的卷积阶段具有增大的步幅。然后,来自卷积层1614的输出可以由下一个层1622处理。下一个层1622可以是附加的卷积层或是全连接层1608中的一者。例如,图16a的第一卷积层1604可以输出至第二卷积层1606,而第二卷积层可以输出至全连接层1608中的第一层。图17展示了示例性递归神经网络。在递归神经网络(rnn)中,网络的先前状态影响网络的当前状态的输出。可以使用各种各样的函数以各种各样的方式来建立rnn。rnn的使用通常围绕使用数学模型以基于先前的输入序列来预测未来。例如,rnn可用于执行统计语言建模以在给定先前的字序列的情况下预测即将来临的字。可以将所展示的rnn1700描述为具有以下各项:输入层1702,其接收输入向量;隐藏层1704,用于实现递归函数;反馈机制1705,用于实现先前状态的‘存储器’;以及输出层1706,用于输出结果。rnn1700基于时间步长来操作。经由反馈机制1705基于先前的时间步长来影响rnn在给定的时间步长的状态。针对给定的时间步长,由先前状态和在当前时间步长的输入来定义隐藏层1704的状态。在第一时间步长的初始输入(x1)可以由隐藏层1704处理。第二输入(x2)可以由隐藏层1704使用在处理初始输入(x1)期间所确定的状态信息来处理。可以将给定的状态计算为st=f(uxt+wst-1),其中,u和w是参数矩阵。函数f通常为非线性,比如双曲正切函数(tanh)或修正函数f(x)=max(0,x)的变体。然而,隐藏层1704中使用的特定数学函数可以取决于rnn1700的特定实现方式细节而变化。除所描述的基本cnn和rnn网络之外,还可实现那些网络的变化。一个示例rnn变体是长短期记忆(lstm)rnn。lstmrnn能够学习对于处理更长的语言序列来说可有必要的长期依赖。cnn的变体是卷积深度置信网络,所述卷积深度置信网络具有类似于cnn的结构并且以类似于深度置信网络的方式受训练。深度置信网络(dbn)是由随机性(随机)变量的多个层组成的生成式神经网络。可以使用贪婪式无监督式学习来逐层训练dbn。然后,dbn的学习权重可以用于通过确定用于神经网络的一组最佳初始权重来提供预训练神经网络。图18展示深度神经网络的训练和部署。一旦已针对任务将给定的网络结构化,就使用训练数据集1802来训练神经网络。已开发出各种训练框架以用于实现对训练过程的硬件加速。例如,图15的机器学习框架1504可被配置为训练框架1804。训练框架1804可以跟未训练的神经网络1806挂钩,并且使得能够使用本文描述的并行处理资源来训练未训练的神经网以生成已训练的神经网1808。为了开始训练过程,可随机地或通过使用深度置信网络进行预训练来选择初始权重。然后,以监督或无监督的方式来执行训练循环。监督式学习是一种学习方法,其中将训练作为仲裁操作来执行,比如当训练数据集1802包括输入(其与所述输入的期望输出成对)时,或在训练数据集包括具有已知的输出的输入并且神经网络的输出被手动地分级的情况下。网络处理输入,并且将所得输出与一组预期或期望的输出相比较。然后,通过系统反向传播误差。训练框架1804可以进行调节,以调节控制未训练的神经网络1806的权重。训练框架1804可以提供工具以用于监测未训练的神经网络1806在多大程度上收敛于适合基于已知的输入数据生成正确的答案的模型。当调节网络的权重以改善由神经网络生成的输出时,反复地出现训练过程。训练过程可以继续,直到神经网络达到与已训练的神经网1808相关联的统计上期望的准确度。然后,可以部署已训练的神经网络1808以实现任何数量的机器学习操作。无监督式学习是一种学习方法,其中网络试图使用未标记数据来训练其自身。因此,针对无监督式学习,训练数据集1802将包括输入数据而无任何关联的输出数据。未训练的神经网络1806可以学习未标记输入内的分组,并且可以确定个别输入如何与整体数据集相关。无监督式训练可以用于生成自组织映射,所述自组织映射是能够执行在数据降维中有用的操作的一种类型的已训练神经网络1807。无监督式训练还可以用于执行异常检测,所述异常检测允许识别输入数据集中偏离数据正常模式的数据点。还可采用监督式和无监督式训练的变化。半监督式学习是一项技术,其中训练数据集1802包括相同分布的已标记数据和未标记数据的混合。增量学习是监督式学习的变体,其中连续地使用输入数据以用于进一步训练模型。增量学习使得已训练的神经网络1808能够适配于新数据1812,而不忘记在初始训练期间根植在网络内的知识。不管是监督式还是无监督式,用于特别深的神经网络的训练过程对于单个计算节点而言可能是过于计算密集的。可以使用计算节点的分布式网络而非使用单个计算节点来加速训练过程。图19是展示分布式学习的框图。分布式学习是训练模型,其使用多个分布式计算节点来执行神经网络的监督式或无监督式训练。所述分布式计算节点可以各自包括一个或多个主机处理器以及通用处理节点中的一者或多者。如所展示,分布式学习可以执行模型并行化1902、数据并行化1904或模型和数据并行化1904的组合。在模型并行化1902中,分布式系统中的不同计算节点可以针对单个网络的不同部分执行训练计算。例如,可以由分布式系统的不同处理节点来训练神经网络的每个层。模型并行化的益处包括能够缩放到特别大的模型。分裂与神经网络的不同层相关联的计算使得能够训练超大神经网络,其中所有层的权重将不纳入(fitinto)单个计算节点的存储器中。在一些实例中,模型并行化在执行大型神经网络的无监督式训练中可以是特别有用的。在数据并行化1904中,分布式网络的不同节点具有模型的完整实例,并且每个节点接收数据的不同部分。然后,组合来自不同节点的结果。虽然用于数据并行化的不同方法是有可能的,但是数据并行训练方法都需要一项组合结果并使每个节点之间的模型参数同步的技术。用于组合数据的示例性方法包括参数求平均和基于更新的数据并行化。参数求平均训练在训练数据的子集上的每个节点,并且将全局参数(例如,权重、偏差)设定至来自每个节点的参数的平均值。参数求平均使用保持参数数据的中心参数服务器。基于更新的数据并行化类似于参数求平均,除了以下情况之外:传递模型的更新而非将来自节点的参数传递到参数服务器。另外,可以以分散的方式执行基于更新的数据并行化,其中更新被压缩并且在节点之间传递。例如,可以在分布式系统中实现经组合的模型和数据并行化1906,在所述分布式系统中,每个计算节点包括多个gpu。每个节点可以具有模型的完整实例,其中每个节点内的单独gpu用于训练模型的不同部分。分布式训练相对于单个机器上的训练具有增加的开销。然而,本文描述的并行处理器和gpgpu可以各自实现各项技术以用于减少分布式训练的开销,包括用于实现高带宽gpu-gpu数据传递和加速的远程数据同步的技术。示例性机器学习应用可以应用机器学习以解决多项技术问题,包括但不限于计算机视觉、自主驾驶和导航、语音识别以及语言处理。计算机视觉传统上已是机器学习应用的最活跃研究领域之一。计算机视觉的应用范围为从重现人类视觉能力(比如,识别人脸)到创建新类别的视觉能力。例如,计算机视觉应用可以被配置成从视频中可见的物体中所诱导的振动来识别声波。并行处理器加速的机器学习使得能够使用明显大于先前可行的训练数据集的训练数据集来训练计算机视觉应用,并且使得能够使用低功率并行处理器来部署推断用系统。并行处理器加速的机器学习具有自主驾驶应用,包括车道和道路标志识别、障碍回避、导航和驾驶控制。加速的机器学习技术可以用于基于数据集来训练驱动模型,所述数据集定义对特定训练输入的适当响应。本文描述的并行处理器可以使得能够快速训练用于自主驾驶解决方案的日益复杂的神经网络,并且使得能够将低功率推断用处理器部署在适合于集成到自主车辆中的移动平台中。并行处理器加速的深度神经网络已实现用于自动语音识别(asr)的机器学习方法。asr包括创建在给定的输入声序列的情况下计算最可能的语言序列的函数。使用深度神经网络的加速的机器学习已实现代替先前用于asr的隐马尔可夫模型(hmm)和高斯混合模型(gmm)。并行处理器加速的机器学习还可以用于加速自然语言处理。自动学习程序可以使用统计推断算法以产生对于误差的或不熟悉的输入具有鲁棒性的模型。示例性自然语言处理器应用包括人类语言之间的自动机器翻译。用于机器学习的并行处理平台可以被划分成训练平台和部署平台。训练平台通常高度并行并且包括优化以加速多gpu单节点训练和多节点多gpu训练,而部署的机器学习(例如,推断)平台通常包括适合于在如相机、自主机器人和自主车辆等产品中使用的较低功率并行处理器。神经网络(nn)是图形。传统的nn遵循某些类型的图形结构(即,被组织为完美分层的节点的图形,其中边缘跨这些层连接)。然而,较新的nn的图形结构变得更加任一和不规则。例如,在推理中,从传统的神经网络图开始,工具可以对图形进行编译/重构,以将其转换为更加不规则得多的任意图形,该图形被优化,使得其包含比原始图形少得多的操作。然而,与原始图形不同,这种经优化的不规则图形可能不再可以直接映射到规则的矩阵操作序列中。另一示例是对于在数据集上使用的神经网络,该数据集本身就是图形(例如,社交网络图、知识图等)。本设计提供了一种增强的稀疏矩阵加速器,用于处理遍布于任何层的任意连接,而不仅仅是到相邻层的连接。在一个示例中,利用计算资源在芯片上处理较小的图形(例如,高达100兆字节的数据存储)。在另一示例中,在芯片外处理较大的图形(例如,超过100兆字节的数据存储)。图20a示出了示例性规则神经网络。每个输入或输入块连接到神经网络2000的每个输出。在nn的相邻层之间形成连接。调整nn的权重(w)以细化由神经网络生成的输出。图20b示出了根据实施例的示例性任意(或不规则)神经网络。任意一组输入或输入块(例如,输入2063)连接到神经网络2000的输出2080-2082。其他输入(例如,输入2060-2062)连接到临时节点(t)(该临时节点(t)连接到输出2080-2082)。调整网络的权重(w)以细化由神经网络生成的输出。任意nn允许定制,尤其是用于推理的定制。重构导致二进制和三进制网络中的重复模式被移除。本设计能够有效地处理包括不规则或规则图形的任意神经网络。图21a示出了示例性规则神经网络。每个输入或输入块(例如,i0,i1,i2,i3)连接到神经网络2100的每个输出。在nn的相邻层之间形成连接。调整nn的权重(w)以细化由神经网络生成的输出。在该示例中,12个边缘在这12个连接间进行连接,并产生12个处理机制的指令。图21b示出了根据实施例的nn2100的示例性矩阵乘法操作2120。具有输入或输入块(例如,i0,i1=0,i2,i3)的输入矩阵2122与具有权重值(例如,vo,v1,v2,v3)的矩阵2124相乘以生成输出矩阵2126。矩阵2124的列2128具有冗余(redundant)值v0,v1,v2。激活(输入)和权重在具有零值或不重要值方面可以是稀疏的。图21c示出了根据实施例的示例性任意(或不规则)神经网络。任意一组输入或输入块(例如,输入i3)连接到神经网络2150的输出。其他输入(例如,输入i0,i1=0,i2,i3)连接到临时节点(t)(该临时节点(t)连接到输出)。调整网络的权重(w)以细化由神经网络生成的输出。在该示例中,临时节点共享冗余权重,以将nn2100的12个指令减少为nn2150的仅8个指令,使得8个边缘在8个连接间进行连接并且产生8个用于处理机制的指令。图21d示出了根据实施例的nn2150的示例性矩阵乘法操作2170。具有输入或输入块(例如,i0,i1=0,i2,i3)、临时节点和输出的向量2180与具有权重值的邻接矩阵2190(例如,vo,v1,v2,v3,v5)相乘,以生成具有输入、临时节点和输出的向量2195。利用经典的再形成(reformulation)生成邻接矩阵2190。对于该示例,矩阵2190是稀疏且不规则的(例如,大约12%的非零值)。图22a示出了根据实施例的nn2150的示例性矩阵乘法操作2200。x向量2210包括输入或输入块(例如,i0,i1,i2,i3)、临时节点以及输出。y向量2230包括输入或输入块(例如,i0,i1,i2,i3)、临时节点以及输出。邻接矩阵2220是用于表示有限图的方矩阵。矩阵的元素指示顶点对是否彼此相邻。权重值(例如,w0,w1)被应用于输入。每个xy基指针(例如,2235-2237)指向存储器地址并指示向量2230的区域的开始。利用经典的再形成生成邻接矩阵2220。对于该示例,矩阵2220是稀疏且不规则的(例如,大约12%的非零值)。有效逻辑2240(或有效电路2240)包括用于图形的子集的有效x元素(例如,非零操作数、重要操作数)。跳过逻辑2242(或跳过电路2242)动态地跟踪零值和不重要的值(例如,零值操作数、不重要的操作数)以跳过或忽略。图22b示出了根据实施例的示例性增强的稀疏矩阵加速器2250。加速器2250包括数据管理单元2260(dmu)、处理元件(pe)电路2270、存储器2280、和存储器2290,处理元件(pe)电路2270用于处理元件2271(例如,2271a,2271b,...,2271n)以进行处理操作,存储器2280具有用于存储xy基指针的指针逻辑2281,存储器2290用于存储数据(例如,xy向量)。dmu2260包括用于调度操作(例如,矩阵操作、向量操作)的调度器2262、有效逻辑2264(或有效电路2264)和跳过逻辑2266(或跳过电路2266)。图23示出了根据实施例的示例性pe电路2300的详细视图。pe电路2300(例如,图22b的电路2271)包括逻辑2312(例如,输入缓冲器、拆包单元)、w列指针逻辑2320、w数据逻辑2330、逻辑2350、y缓冲器2340和逻辑2360(例如,累加器)。在一个示例中,电路2300接收x元素2310作为逻辑2312的输入,逻辑2312生成x值,该x值被发送到逻辑2350(例如,乘法器2350、乘法单元2350),同时x向量的存储器地址或位置的标识符(例如,用于标识i0,i1,i2等的x索引(xidx))被发送到w列指针2320。指向矩阵2220的加权系数的存储器地址的列指针被生成并被发送到w数据2330。w数据2330生成由列指针标识的加权系数值(wval)并将其发送到逻辑2350。w数据2330还向y缓冲器2340发送y向量的存储器地址或位置的标识符(例如,y索引(yidx)以指示y向量的行)。在一个示例中,逻辑2350将x值乘以对应的w系数值(权重值)并生成被发送到逻辑2360的结果2351。y缓冲器将y值发送到逻辑2360(例如,累加器电路2360)。逻辑2360可以是累加器,用于基于从逻辑2350接收到的结果来更新y向量的y值。y缓冲器从逻辑2360接收输出,并将输出发送到图22b的存储器2280。图24a-24c示出了根据实施例的利用增强的稀疏矩阵加速器执行的操作的示例。图24a示出了根据实施例的nn(例如,nn2150)的示例性矩阵乘法操作。x向量2410包括输入或输入块(例如,i0,i1,i2,i3)、临时节点以及输出。y向量2430包括输入或输入块(例如,i0,i1,i2,i3)、临时节点以及输出。邻接矩阵2420是用于表示有限图的方矩阵。矩阵的元素指示顶点对是否彼此相邻。权重值(例如,w0,w1)被应用于输入。利用经典的再形成生成邻接矩阵2420。对于该示例,矩阵2420是稀疏且不规则的(例如,大约12%的非零值)。图24b示出了有效逻辑2440和2441,该有效逻辑2440和2441包括用于图形的子集的有效x元素(例如,非零操作数、重要操作数)。跳过逻辑2442和2443动态地跟踪零值和不重要的值(例如,零值操作数、不重要的操作数)以跳过或忽略。图24c示出了根据实施例的示例性增强的稀疏矩阵加速器2450。加速器2450包括数据管理单元2460(dmu)、用于具有矩阵的权重值(w)的处理元件2471(例如,2471a,2471b,...2471n)的pe电路2470、具有指针逻辑2481的存储器2480、以及用于存储数据(例如,xy向量)的存储器2490。dmu2460包括用于调度矩阵操作的调度器2462、有效逻辑2464、跳过逻辑2466和用于访问加速器2450的不同部件(例如,2464、2466、2470、2480、2490)的存储器控制器2468、以及耦合到存储器控制器的其他部件。在一个示例中,输入i1具有由跳过逻辑2466、2442跟踪到的零值,并因此由调度器2462跳过以用于调度算术操作。在另一示例中,临时节点具有由跳过逻辑2466、2443跟踪到的零值,并因此由调度器2462跳过以用于调度算术操作。图25a-25b示出了根据实施例的通过同时处理多个输入向量来优化利用增强的稀疏矩阵加速器执行的操作的示例。图25a示出了根据实施例的nn的示例性矩阵乘法操作。每个x向量(例如,2510…2515)包括输入或输入块(例如,i0,i1,i2,i3)、临时节点以及输出。不同x向量的输入可被一起处理或者打包,如图25a-25b中的以i0值2505示出的。每个y向量(例如,2530…2534)包括输入或输入块(例如,i0,i1,i2,i3)、临时节点以及输出。邻接矩阵2520的元素指示顶点对是否彼此相邻。加权的值(例如,w0,w1)被应用于输入。对于该示例,矩阵2520是稀疏且不规则的(例如,大约12%的非零值)。图25b示出了根据实施例的用于同时处理多个输入向量的示例性电路2550的详细视图。pe电路2550(例如,图22b的pe2271)包括用于接收不同x向量(例如,2510...2515)的x元素的逻辑2562(例如,输入缓冲器、拆包单元)、w列指针逻辑2564、w数据逻辑2570、逻辑2585、y缓冲器2580和逻辑2590。在一个示例中,电路2550接收x元素2560作为逻辑2562的输入,逻辑2562生成多个x值,这些x值被发送到逻辑2585(例如,乘法器2585、乘法单元2585),同时x向量的存储器地址或位置的标识符(例如,x索引)被发送到w列指针2564。指向矩阵2520的加权系数的存储器地址的列指针被生成并被发送到w数据2570。w数据2570生成由列指针标识的加权系数值(wval)并将其发送到逻辑2585。w数据2570还向y缓冲器2580发送y向量的存储器地址或位置的标识符(例如,y索引,用以指示y向量的行)。在一个示例中,逻辑2585具有针对所接收的输入的跳过能力(例如,跳过不重要或零值操作数)和乘法功能。逻辑2585生成被发送到逻辑2590的输出值(例如,nzx值,y值)和指令。y缓冲器将y值发送到逻辑2585。在一个示例中,逻辑2585将x值乘以对应的w系数值(加权值)。y缓冲器2580将y值发送到逻辑2590。逻辑2590可以是累加器,用于基于从逻辑2585接收到的输出来更新y向量的y值。y缓冲器从逻辑2590接收输出,并将输出发送到图22b的存储器2280。图26示出了根据实施例的用于同时处理多个输入向量的示例性电路2600的详细视图。电路2600类似于电路2550(例如,图22b的电路2271),除了乘法功能已从逻辑2650中移除。电路2600包括用于接收不同x向量(例如,2510...2515)的x元素的逻辑2612(例如,输入缓冲器、拆包单元)、w列指针逻辑2620、w数据逻辑2630、逻辑2650、y缓冲器2640和用于算术操作的逻辑2660。在一个示例中,电路2600接收x元素2610作为逻辑2612的输入,逻辑2612生成多个x值,这些多个x值被发送到逻辑2650,同时x向量的存储器地址或位置的标识符(例如,x索引)被发送到w列指针2620。指向矩阵2520的加权系数的存储器地址的列指针被生成并被发送到w数据2630。w数据2630生成由列指针标识的加权系数值(wval)并将其发送到逻辑2650。w数据2630生成加权值(wval,1,0,-1的三进制权重,以及1,-1等的二进制权重)并将其发送到逻辑2650。w数据2630还向y缓冲器2640发送y向量的存储器地址或位置的标识符(例如,y索引,用以指示y向量的行)。逻辑2650具有针对所接收的输入的跳过能力(例如,跳过零值操作数,跳过不重要的操作数)。逻辑2650生成被发送到逻辑2660的输出值(例如,nzx值,y值)和指令(例如,操作(op))。y缓冲器将y值发送到逻辑2650。逻辑2660可以是累加器,用于基于从逻辑2650接收到的输出来更新y向量的y值。y缓冲器从逻辑2650接收输出,并将输出发送到图22b的存储器2280。如图27中所示,在一个实施例中,稀疏处理机制2710(例如,增强的稀疏矩阵加速器2250、2450等)可以由gpu2714主控。然而,在其他实施例中,稀疏矩阵处理机制2710可以在图形驱动器2716中被主控。在又一其他实施例中,稀疏矩阵处理机制2710可以由中央处理单元(“cpu”或“应用处理器”)2712的固件来主控或者是其一部分。为了简洁、清楚并易于理解,贯穿本文档的其余部分,稀疏矩阵处理机制2710可以作为图形驱动器2716的一部分而被讨论;然而,实施例不限于此。在再一实施例中,稀疏矩阵处理机制2710可作为软件或固件逻辑由操作系统2706来主控。在又进一步的实施例中,稀疏矩阵处理机制2710可以由计算设备600的多个部件(诸如图形驱动器2716、gpu2714、gpu固件、cpu2712、cpu固件、操作系统2706等中的一个或多个)部分地且同时地主控。可以预见,稀疏矩阵处理机制2710或其部件中的一个或多个可以被实现为硬件、软件和/或固件。稀疏矩阵乘法操作在各种应用(包括神经网络)中很重要。稀疏矩阵是其中大多数元素为零(或一些其他数学上无关的值)的矩阵。稀疏矩阵通常是接收的图像数据的结果,该图像数据指示图像(或图像区域)包括无用的信息。因此,传统的gpu将两个输入矩阵块作为输入并产生输出矩阵块。然而,当在稀疏矩阵上操作时,这些输入块主要包括零值,零值对输出矩阵处的累加结果没有贡献(例如,与零相乘产生零)。根据一个实施例,稀疏矩阵处理机制2710包括数据管理单元2715(dmu)、用于具有加权值(w)的矩阵操作的电路2717、用于存储xy基指针的指针逻辑2720(或指针电路2720)、以及用于存储数据(例如,xy向量)的存储器2730。dmu2715(例如,2260、2460)包括用于调度矩阵操作的调度器、有效逻辑和跳过逻辑。在一个实施例中,调度器与存储器控制器协调以跟踪存储在存储器设备处的数据。在其他实施例中,调度器在高速缓存层级结构级别跟踪信息。在又一些其他实施例中,调度器经由os2706在页表级跟踪信息。在进一步的实施例中,可以实现调度器以在大量密集数据中进行解析以确定可以作为稀疏操作处理的段。如以上所讨论的,可以绕过用于稀疏操作的矩阵乘法,从而减少gpu2714处的处理负荷。gpu2714可以被实现为用于执行其他深度学习操作。例如,gpu2714可以执行神经网络的层处理。几乎所有深度神经网络中频繁执行的模式是卷积(c)层跟随偏置(b)层,接着是整流线性单元(relu(r))层,接着是池化(p)层。现今,大多数系统或者是一个接一个地执行这些层(例如,在gpu上c、b,、r和p被映射为个体内核),或者被映射为融合cbr,然后将p映射为两个分开的内核。在这两种情况下,都需要不止一个内核调用;因此产生额外的数据传递开销。根据一个实施例,gpu2714被配置为使得eu被加以划分并被分配用以执行某些操作,并且在它们之间转发中间结果以实现高产出。根据一个实施例,可以基于领域知识预先建立eu的分区和分配。在这样的实施例中,计算机制eu可以被静态地分区,使得eu分配在特定应用的寿命期间保持相同。在其他实施例中,可以针对gpu2714执行的每次调用来最优地划分eu。在又一其他实施例中,配置可以是动态的,使得在分派期间每个线程组地改变它。在更进一步的实施例中,除了c、b、r和p层之外,可以通过确定公共模式并建立流水线以在gpu上更快地执行它们而不是单独地执行它们来实现划分以执行对于其他类型的神经网络层的处理。神经网络(nn)的趋势包括低精度、自定义精度和混合精度(例如,自定义位宽、固定点、块浮点(fp)、fp)。除了通过减少计算、存储和数据移动来提高效率同时维持仍良好的准确性之外,还支持用于稀疏性(具有零或通常不重要的值)的缩减计算。一种现有技术方法提供低至int8但不低于8位的低精度。另一种现有技术方法支持混合精度(例如,fp16/fp32混合)。另一种现有技术方法支持稀疏性。另一种现有技术方法提供可变精度但没有块fp/稀疏性/外积。本设计提供了算术计算架构,以适应nn的上述趋势,包括对精度动态调整(即可变精度)的有效支持、对混合精度(即,操作数具有不同的精度)的有效支持、对极低精度(少于8位)的有效支持、对固定点以及动态浮点(或块浮点)的有效支持,以及对稀疏性的有效支持。本设计可以用不同的架构变型来实现,包括内积和外积矩阵制定。图28示出了用于计算的不同数字表示。对于浮点表示2810,变量1和2各自具有符号、不同范围(指数)和不同精度(尾数)。对于定点表示2820,变量1和2各自具有符号、共享范围(共享指数)和不同精度(尾数)。nn2850具有不同的范围。对于动态的定点或块浮点表示2860,输入(i)的变量1和2各自具有符号、共享范围(共享指数)和不同精度(尾数)。加权系数(w)的变量1和2各自具有符号、共享范围(共享指数)和不同精度(尾数)。输出(o)的变量1和2各自具有符号、共享范围(共享指数)和不同精度(尾数)。图29a-b示出了内积矩阵乘法和外积矩阵乘法。对于内积矩阵乘法,输出c基于以下等式确定:c0,0=(a0,0xb0,0)+(a0,1xb1,0)+(a0,2xb2,0)+(a0,3xb3,0)c0,1=(a0,0xb0,1)+(a0,1xb1,1)+(a0,2xb2,1)+(a0,3xb3,1)c0,2=(a0,0xb0,2)+(a0,1xb1,2)+(a0,2xb2,2)+(a0,3xb3,2)c0,3=(a0,0xb0,3)+(a0,1xb1,3)+(a0,2xb2,3)+(a0,3xb3,3)对于外积矩阵乘法,输出c基于以下等式确定:c0,0+=(a0,0xb0,0);c0,1+=(a0,0xb0,1);c0,2+=(a0,0xb0,2);c0,3+=(a0,0xb0,3);c0,0+=(a0,1xb1,0);c0,1+=(a0,1xb1,1);c0,2+=(a0,1xb1,2);c0,3+=(a0,1xb1,3);c0,0+=(a0,2xb2,0);c0,1+=(a0,2xb2,1);c0,2+=(a0,2xb2,2);c0,3+=(a0,2xb2,3);c0,0+=(a0,3xb3,0);c0,1+=(a0,3xb3,1);c0,2+=(a0,3xb3,2);c0,3+=(a0,3xb3,3);图30a示出了多个输入的空间计算。在一个示例中,使用一个乘法器利用一次操作执行第一输入(a为3)与第二输入(b为3)的4位乘法,以产生4位输出(c为9)。该乘法器比加法器消耗更多的硬件资源。图30b示出了多个输入的时间计算。在一个示例中,连续地使用一个加法器利用4次操作执行第一输入(a=3)与第二输入(b=3)的4位乘法,以产生4位输出(c=9)。该加法器比乘法器消耗更少的硬件资源。图30c示出了多个输入的空间和时间计算的组合。在一个示例中,连续地使用两个加法器利用两次操作执行第一输入(a)与第二输入(b)的4位乘法,以产生4位输出(c=9)。图31示出了根据实施例的具有对可变和混合精度操作和稀疏性的支持的示例性算术计算架构3100。算术计算架构3100包括用于管理稀疏性操作的稀疏性管理单元3110(例如,稀疏性管理电路3110)、用于块fp操作的块fp管理单元3120(例如,块fp管理电路3120)、可变和混合精度计算单元3130(例如,可变和混合精度计算电路3130)和用于同时处理多个向量的打包管理单元3140。稀疏性管理单元3110包括值检查机制3112,用于检测不重要的值(例如,零值)并跳过这些不重要的输入向量值。调度器3114基于调度由值检查机制3112检测到的输入向量的重要值并跳过由值检查机制3112检测到的输入向量的不重要值来确定计算的调度。当输入是块fp或动态fp时,块fp管理单元3120为下一个计算阶段准备输入。块fp管理单元3120包括选择逻辑3122,用于如果输入向量具有块fp和不同的指数,则选择输入向量的共享指数。然后,对齐逻辑3124使得具有指数变化的输入向量的尾数对齐。如果输入向量不是块fp也不是动态fp,则输入向量通过块fp管理单元3120以用于后续计算阶段以执行正常定点计算。可变和混合精度计算单元3130利用计算单元3132执行输入向量的计算并更新累加器3134。计算可以使用空间和时间计算中的至少一个,包括任何空间和时间组合。如果利用时间计算,则可以跳过输入向量的不重要项(例如,零值)以提高效率并减少计算时间。对于混合精度,可以利用具有不同位宽的断裂(fractured)计算单元来提高计算效率。累加器3134准备并写入输出结果。打包管理单元3140同时处理多个向量。打包管理单元3140从累加器3134读取输出,并在以期望格式(例如,共享指数、正常固定点)输出向量(例如,c输出)之前打包这些输出的值。如果包管理单元3140的输出具有块fp输出值,则打包管理单元3140可以将共享指数级联(concatenate)到输出值上。图32示出了根据实施例的具有对可变和混合精度操作和稀疏性的支持的算术计算架构的稀疏性管理单元的示例性操作(例如,内积操作)序列。根据一个实施例,稀疏性管理单元(例如,稀疏性管理单元3110)执行操作3200。在操作3220处,稀疏性管理单元的值检查机制在操作3220处接收输入(例如,输入向量3210和3212)并标识重要值(例如,非零值)。然后,值检查机制生成具有重要值和不重要值的输出(例如,向量3230)。例如,对于内积乘法,如果向量3210对于a0,1具有零值并且向量3212对于b3,0具有零值,则值检查机制由于检测到向量3210的a0,1的零值和向量3212的b3,0的零值而生成对于第一位和第三位具有非零值、对于向量3230的第2位和第4位具有零值的4位向量3230。在操作3240处,稀疏性管理单元的调度器接收向量3230并跳过不重要的值(例如,向量3230的第2和第4位的零值)。调度器基于调度由值检查机制检测到的输入向量的重要值,并跳过由值检查机制检测到的输入向量的不重要值来确定计算的调度。在该示例中,调度器生成向量3250和3260以用于利用计算单元来调度计算。向量3250包括a0,1和a0,2的重要值。向量3250不包括a0,1,因为在该示例中a0,1具有零值。向量3250不包括a0,3,因为在该示例中a0,3与b3,0的零值相乘。向量3260包括b0,0和b2,0的重要值。向量3260不包括b3,0,因为在该示例中b3,0具有零值。向量3260不包括b1,0,因为在该示例中b1,0与a0,1的零值相乘。该示例包括4位输入向量和2位输出向量,但是可以用该方法3200处理任何数量的位(例如,2,3,4,8,16,32,64等)。图33示出了根据实施例的具有对可变和混合精度操作以及稀疏性的支持的算术计算架构的稀疏性管理单元的示例性操作(例如,外积操作)序列。根据一个实施例,稀疏性管理单元(例如,稀疏性管理单元3110)执行操作3300。在操作3320处,稀疏性管理单元的值检查机制在操作3220处接收输入(例如,输入向量3310、3312、3314)并标识重要值(例如,非零值)。然后,值检查机制生成具有重要值和不重要值的输出(例如,向量3330、3332和3334)。例如,对于外积乘法,如果向量3310对于a0,1具有零值,向量3312对于b0,0和b0,1具有零值,并且向量3314对于b1,3具有零值,则值检查机制生成具有重要的非零值和不重要的零值两者的向量(例如,2位向量3330,4位向量3332和3334)。例如,向量3330对于第一位具有重要值并且对于第二位具有零值。向量3332对于第3和第4位可以具有重要值,而对于第1位和第2位具有零值。向量3334对于第1、第2位、第3位可以具有重要值,而对于第4位具有零值。在操作3340处,稀疏性管理单元的调度器接收向量3330、3332和3334并跳过不重要的值(例如,向量3230的第2和第4位的零值)。调度器基于调度由值检查机制检测到的输入向量的重要值并跳过由值检查机制检测到的输入向量的不重要值来确定计算的调度。在该示例中,调度器生成向量3352和3362以用于利用计算单元来调度计算。向量3350、3351、3353、3360、3361和3363由于包含不重要的值(例如,零值)或者与不重要的值(例如,零值)相乘而未被调度用于利用计算单元来计算。该示例包括2位和4位输入向量以及要发送到2位宽计算单元的1位和2位输出向量,但任意数量的位(例如,2,3,4,8,16,32,64等)都可以利用这种方法3300来处理。图34示出了根据实施例的具有对可变和混合精度操作以及稀疏性的支持的算术计算架构的块fp管理单元的示例性操作(例如,块fp操作)序列。根据一个实施例,块fp管理单元(例如,块fp管理单元3120)执行操作3400。块fp管理单元的选择机制接收输入(例如,输入向量3410、3412),(这些输入具有向量的每个元素的符号、指数和尾数),并标识重要值(例如,非零值)。在操作3420处,选择机制分析输入的每个元素的指数。在操作3421处,选择机制确定输入是否是动态fp或块fp。如果是,则在操作3422处,选择机制标识输入的指数以用作每个输入的共享指数,并确定对齐要求。在一个示例中,输入中的最大指数被选择为共享指数。基于对齐要求(例如,要移位多少位),对齐机制为每个元素生成具有对齐的尾数的输出。具有对齐的尾数的输出的计算可以由变量和混合精度计算单元利用固定功能计算来处理。如果在操作3421处输入不是动态fp或块fp,则在操作3470处,输入通过块fp单元。在这种情况下,输入进入下一阶段进行计算。图35示出了根据实施例的可变和混合精度计算单元的框图。可变和混合精度计算单元3500利用计算单元3550、3560(例如,移位,n次加法)来执行输入向量(例如,输入3510、3512、3520)的计算并更新累加器3570和3580。计算可以使用空间和时间计算中的至少一个,包括任何空间和时间组合。可变精度函数通过组合任何位宽的空间和时间计算,为自定义精度提供动态调整的计算。如果利用时间计算,则可以跳过输入向量的不重要项(例如,零值)以提高效率并减少计算时间。对于混合精度,输入可以具有不同的精度。计算块的总产量取决于输入的精度、计算单元的加法器的数量以及加法器的宽度。具有不同位宽的断裂(fractured)计算单元可用于提高计算效率。累加器3570和3580准备并写入输出结果(例如,c0,0和c0,n)。在外积乘法的一个示例中,输入3510是具有值0011的4位向量a0,0。输入3512是具有值011的3位向量b0,0。输入3520是具有值110的3位向量b0,n。时间方法可以应用于输入a和b两者。用于处理输入b的时间操作的次数基于计算单元的加法器的数量n。用于处理输入a的时间操作的次数基于计算单元的加法器的位宽n。跳位逻辑3530、3532和3540用具有不重要值(例如,零值)的位来过滤或跳过输入,并输出具有重要值的其他位。跳位逻辑3530的输出被加载到具有移位和n位加法器逻辑的计算单元3550和3560中。跳位逻辑3532和3540的输出分别用作累加器3570和3580的启用信号3533和3541。启用信号确定是否用来自计算单元3550和3560的新值更新累加器。在一个示例中,如果对于计算单元n=1位加法器,则将需要3次累加操作来计算3位的输入b。在另一示例中,如果对于计算单元n=2位加法器,则将需要2次累加操作来计算4位的输入a。因此,对于该示例,输入b的3次操作乘以输入a的2次操作导致6次操作来处理输入对a和b。图36示出了根据实施例的可变和混合精度计算单元的框图。可变和混合精度计算单元3600利用空间和时间乘法单元3640-3649、加法器树电路3650和计算单元3660(例如,移位,n次加法)对输入向量(例如,输入3610、3620、3622、3630)执行计算,并更新累加器3670。计算可以使用空间和时间计算中的至少一个,包括任何空间和时间组合。对于该示例,对于内积制定,可变精度函数通过组合任何位宽的空间和时间计算来为自定义精度提供动态调整的计算。空间/时间乘法单元(例如,电路)可以从纯时间(例如,and逻辑门)调谐到n比特时间(例如,n个加法器)再到纯空间(例如,硬件乘法器)。纯时间方法使用较少的硬件资源,但利用多次操作来执行乘法。相比之下,纯空间方法使用更多的硬件资源,但操作更少。对于混合精度,输入可以具有不同的精度。具有不同位宽的断裂(fractured)计算单元可用于改进计算效率。累加器3670准备并写入输出结果(例如,c0,0)。在内积乘法的一个示例中,输入3610是具有值0011的4位向量a0,0,并且输入3620是具有值0101的4位向量an,0。输入3612是具有值011的3位向量b0,0。输入3630是具有值110的3位向量b0,n。如以上所讨论的,空间和时间方法可以利用空间/时间乘法单元3640和3649用于输入a和b。空间/时间乘法单元3640和3649的输出被加载到加法器树电路3650中以进行算术操作,然后加法器树的输出被加载到具有移位和n位加法器逻辑的计算单元3660中。计算单元3660的输出被加载到累加器3670中,累加器3670产生输出(例如,c0,0)。图形分析依赖于图形算法以提取关于被表示为图形的数据之间的关系的知识。(来自诸如社交媒体之类的源的)图形数据的激增已导致对图形分析的强烈需求和对图形分析的广泛使用。因此,尽可能高效地执行图形分析将是至关重要的。为解决这一需求,本设计包括框架,该框架用于自动地将用户定义的图形算法映射至被定制成给定的输入图形算法的硬件加速器架构“模板”。加速器适合于(amenable)在硬件(例如,fpga、asic)中实现,这种硬件可以极高效率地执行。在一个实施例中,本设计包括硬件加速器架构模板,该硬件加速器架构模板基于广义稀疏矩阵向量乘法(gspmv)加速器。它支持任意图形算法,因为已表明图形算法可被制定为矩阵操作。本设计包括自动方式,用于将广泛使用的“顶点中心”(“vertexcentric”)图形编程抽象映射并调节至所推荐的架构模板。现有的图形分析框架主要是软件框架(即,在gpgpu的cpu上运行)。现有文献中的一些先前图形框架将图形算法映射到定制的硬件。然而,这些先前的图形框架针对的是不基于广义稀疏矩阵向量乘法的硬件加速器架构。现有的稀疏矩阵乘法硬件加速器不支持可定制性以允许图形算法的映射。本设计框架在用户将其图形算法指定为在以顶点为中心的图形编程抽象之后的“顶点程序”的情况下进行操作。顶点程序不暴露硬件细节,因此不具备硬件专业知识的用户(例如,数据科学家)可创建该程序。与图形算法一起,框架接受包括要生成的目标硬件加速器的参数(例如,芯片上ram的最大量)的输入。这些参数可由用户提供,或者当以现有系统(例如,特定的fpga板)为目标时从已知参数的现有库获取。框架还接收设计优化目标(例如,最大性能,最小区域)和目标图形数据的属性(例如,图形的类型)或图形数据本身。这是可任选的,并且用于辅助自动调节。给定这些接收到的输入,框架执行自动调节以确定应用于硬件模板的定制集以优化输入图形算法;将这些参数映射到架构模板上以在可合成寄存器传输级(rtl)中产生加速器实例;以及对照从输入图形算法规范中导出的功能和性能软件模型来执行对所生成rtl的功能和性能验证。与软件框架相比,本设计的框架允许通过使用为这些算法定制的优化硬件加速器实现来允许图形算法的更有效执行。该框架的用例包括将图形算法自动映射到fpga平台和asic实现中的至少一个。本硬件架构模板支持存储在芯片外存储器(例如,图14的gpgpu本地存储器1434a-1434b)中的大型图形数据的有效处理。在一个实施例中,稀疏计算加速器架构2100还可以直接对存储在高带宽非易失性存储器(诸如3dxpoint或nano-ram)中的数据进行操作。相比之下,先前方法的目标硬件架构假设图形数据存储在芯片上ram中。因此,它无法支持对大型图形数据进行操作的图形问题。本硬件架构模板基于广义稀疏矩阵向量乘法。因此,它不依赖于指令的概念。该模板可定制以接受定制硬件块,这些硬件块可由各种现有的高级综合(hls)技术来生成。另一方面,先前方法将图形算法映射到定制的图形处理器,该图形处理器执行由从用户提供的顶点程序导出的应用专用的指令组成的图形程序。指令的使用导致开销。这使执行顺序化。进一步地,它限制了定制的机会,因为映射到图形处理器的图形操作必须符合特定的指令格式。用于描述对图形数据的计算的最流行的模型之一是顶点编程模型。本设计支持顶点编程模型。顶点程序包括:与图形中的边/顶点相关联的数据类型(例如,边缘数据的edata,顶点数据的vdata),遍及图形中的顶点而发送的消息(例如,消息的mdata)和临时数据(例如,tdata)。无状态的用户定义的计算函数使用预定义的api,该预定义的api读取并更新定义的图形数据。用户定义的计算函数的示例包括以下内容:tdataprocessmsg(mdatam,edatae,vdatav){//用户定义}tdatareduce(tdatat,tdatar){//用户定义}tdataapply(vdatav,tdatat){//用户定义}mdatasendmsg(vdatav){//用户定义}以下算法执行顶点程序:runvertexprogram(matrix<edata>a,vector<vdata>y)fori=1tomaxiterationx=newvector<mdata>foriinyifiisactive{x.insert(sendmsg(i))}t=gspmv(a,x,y)resetallmembersofytonon-activeforiintwheretisupdatenew_val=apply(yi,ti);ifnewval!=yi{yi=newval;setyiactive}ifnumberofactivey==0break边缘数据被表示为邻接矩阵a,顶点数据被表示为向量y,并且消息被表示为稀疏向量x。通过由用户定义的process_msg()和reduce()替换稀疏矩阵向量乘法(spmv)中的multiply()和add()操作来概括广义稀疏矩阵向量乘法(gspmv)制定。在此的重要观察结果是,执行顶点程序所需的gspmv变量执行稀疏矩阵a(即,邻接矩阵)与稀疏向量x(即,消息)的面向列的乘法以产生输出向量y(即,顶点数据)。本设计通过以下方式支持顶点程序的执行:(1)使其成为可定制的硬件模板;以及(2)支持顶点程序所需的功能。基于此模板,提供了设计框架以将用户供应的顶点程序映射至硬件模板以产生为该顶点程序所优化的可合成rtl(例如,verilog)实现实例。该框架也执行自动验证和调节以确保所产生的rtl是正确且经优化的。对于此框架有多个用例。例如,所产生的可合成rtl可部署在fpga平台中以高效地执行给定的顶点程序。替代地,可进一步细化所产生的可合成rtl以产生asic实现。图37示出了根据实施例的设计框图。框架3700接收输入,该输入包括用户指定的顶点程序3702、优化目标3704(例如,最大性能、最小面积)以及目标硬件设计约束3703(例如,芯片上ram的最大量、存储器接口宽度)。作为用于辅助自动调节的可任选输入,该框架也接受图形数据属性(例如,类型=自然图形)或样本图形数据。给定这些输入,框架将输入顶点程序映射到硬件加速器架构模板3710,并产生为执行顶点程序所优化的加速器实例3740的rtl实现。框架执行自动调节3730以针对给定设计目标优化所生成的rtl,同时满足硬件(hw)设计约束并生成调整报告3744。此外,框架利用验证模块3720自动地对照从输入导出的功能和性能模型来验证所生成的rtl。验证测试台3742与rtl一起生成。图38示出了根据实施例的硬件加速器模板的高级架构3800。架构3800包括存储器系统目标3860和硬件加速器模板3810。可定制的接口控制器3850在存储器系统目标3860与硬件加速器模板3810的片(tile)3820至3830之间进行连接。接口控制器包括用于频繁访问的数据的高速缓存存储器3852。每个片(tile)包括可定制的数据管理单元(例如,3822、3832)和多个可定制的处理元件(例如,3824、3834)。该架构3800通过在每个pe内提供可定制的逻辑块以支持顶点程序所需的process_msg()、reduce()、apply和send_msg()来支持顶点程序的执行。该架构3800提供可定制的芯片上存储结构和打包/拆包逻辑以支持用户定义的图形数据(即,vdata、edata、mdata、tdata)。修改各种控制状态机以支持执行顶点程序。图39示出了根据实施例加速器片的框图。可定制的接口控制器3950在芯片外存储器(未示出)和加速器片3900之间进行连接。每个片包括可定制的数据管理单元3910和多个可定制的处理元件(例如,3920、3940)。该片3900通过提供顶点程序所需的可定制逻辑块3921-3925(例如,process_msg()3922、reduce()3923、apply3924和send_msg()3925、单源最短路径等)来支持顶点程序的执行。该片3900提供可定制的芯片上存储结构(例如,具有vdataold3931、vdatanew3932和tdata3933的芯片上peram3930)和打包/拆包逻辑(例如,输入缓冲器/拆包3921)以支持用户定义的图形数据(例如,vdata、edata、mdata、tdata)。在另一实施例中,加速器3900还包括图22b、23、24b、25b和26的加速器的特征和功能,包括用于跟踪要跳过的不重要操作数的跳过逻辑(例如,2266、2466)并且还有用于x和y向量的指针的指针逻辑(例如,2281、2481)。图40示出了根据实施例的用于加速器片的操作的方法。根据一个实施例,加速器片(例如,加速器片3900、硬件加速器)执行操作4000。在操作4002处,加速器将顶点数据(y向量)加载到芯片上peram。在操作4004处,加速器将x向量和列指针加载到辅助缓冲器3914中。在操作4006处,每个x向量元素的加速器在边缘数据中流动,并且pe执行定制的函数(例如,proc_msg()、reduce())。在操作4008处,加速器的pe执行定制函数(例如,apply())。在操作4010处,加速器的pe执行定制函数(例如,send_msg())以产生消息,并且dmu将消息(例如,x向量)写入芯片外存储器中。在操作4012处,dmu将更新的顶点数据(y向量)从peram写入芯片外存储器。方法4000符合顶点程序执行算法。为了放大性能,该架构允许增加片中pe的数量和/或增加设计中片的数量。以此方式,该架构可利用图形中的多级并行性,换言之,跨数个子图形(跨数个邻接矩阵的块)或在每一个子图形内。表1概述了加速器模板的可自定制参数。分配跨数个片的非对称参数(例如,一个片比另一片有更多的pe)以用于优化的也是可能的。基于输入,框架执行自动调节以确定用于定制硬件架构模板的最佳设计参数,以便为输入顶点程序和(可任选地)图形数据优化该硬件架构模板。表2列出了调节注意事项和受影响的模板参数的示例。表1表2在该阶段,框架取得由调节阶段确定的模板参数,并且通过“填”入模板的可定制部分来产生加速器实例。用户定义的计算函数可使用现有的高级合成(hls)工具从输入规范被映射至合适的pe计算块。存储结构(例如,ram、缓冲器、高速缓存)和存储器接口使用其对应的设计参数来实例化。打包/拆包逻辑是根据数据类型规范自动生成的。控制fsm的部分也基于所提供的设计参数(例如,pe调度方案)来生成。在验证期间,由模板映射产生的加速器架构实例(可合成的rtl)被自动验证。为此目的,框架导出将用作最佳参考的顶点程序的功能模型。测试台(testbrench)被生成以将对此最佳参引的执行与对架构实例的rtl实现的模拟进行比较。该框架还通过将rtl模拟与分析性能模型和周期精确的软件模拟器进行比较来执行性能验证。该架构报告运行时崩溃并精确定位影响性能的设计瓶颈。稀疏性存在于神经网络(nn)中,这是由于若干因素所致,其中包括relu整流线性单元(例如,主要在cnn中-卷积)导致的固有稀疏性、修剪导致的权重稀疏性、以及对低精度(例如,1位、2位)的量化以及重新训练。用于作为前馈神经网络的递归神经网络的rnn矩阵中的高稀疏性包括层之间的反馈连接。可以使完全连接的层变得稀疏。出版物已经表明,稀疏激活和权重数据的数量可以增长到95%。最近的出版物描述了一种硬件架构,该硬件架构随着权重/激活密度的因素减少而减少用于推理的等待时间(周期)。稀疏性在训练中也是明显的,并且可以使用本公开的硬件加速器来加速。训练包括前向传播和反向传播。前向传播可以与推理相同。训练算法通常针对每个训练样本在nn上运行前向传播,然后在相反方向上运行反向传播,以便计算梯度。不重要的权重(例如,零值)继续无理由地乘以梯度。本gpu架构可以通过利用硬件技术利用这种行为来利用这一点。一种先前的方法使用逐渐修剪技术对语音应用进行稀疏训练,并且实现了90%的权重稀疏性。另一种先前的方法模拟超过2亿个参数并且修剪高达80%,而在重新训练之后没有精确度损失。在本设计中,已经在经修剪的lstm/rnn模型中观察到稀疏场景,所述lstm/rnn模型包括稀疏密集的一般矩阵向量乘法(gemv)(例如,权重是稀疏的,并且密集激活向量具有批量大小,n=1),稀疏密集瘦小(skinny)的一般矩阵矩阵乘法(gemm)(例如,稀疏的权重,密集激活矩阵具有n=2、4、8和16)和稀疏密集gemm(例如,稀疏的权重,密集激活矩阵具有n>1)。在一个示例中,本设计在gpu硬件上加速了上述每稀疏密集场景中的每一个。本设计测量具有不同稀疏度水平(例如,从50%到95%)的内核的性能,并将其与密集版本进行比较。使用直接存储方案(例如,压缩稀疏行(csr)、压缩稀疏列(csc)、坐标列表(coo))来存储稀疏矩阵,本设计目标是大于50%的稀疏性以获得加速,因为通常存在用于存储索引信息的2倍开销。在小批量方案(例如批量大小==1)中,加载rnn权重的成本通常大于执行数学运算的成本,因此预期会有与存储网络所需的存储器减少成正比的加速。在一个示例中,观察到的加速以csr表示而出现。通过使用具有运行长度编码的csr的修改版本或通过使用2个字节而不是4个字节来表示索引阵列中的每个索引,可以进一步提高带宽效率,因为在lstm模型中矩阵大小不会超过2^16。长的短期记忆块或网络可以是递归的神经网络。在一个实施例中,稀疏密集gemvgpu实现包括基于l3的gpu内核或基于共享本地存储器(slm)的内核。稀疏矩阵表现为压缩稀疏行格式,该压缩稀疏行格式通过三个(一维)阵列来表示矩阵m,该三个阵列分别包含非零值、行的范围和列索引。该格式允许快速行访问和矩阵向量乘法(mx)。csr格式使用三个(一维)阵列(a,ia,ja)以行形式存储稀疏m×n矩阵m。nnz表示m中非零项的数量。阵列a的长度为nnz,并保存m的所有非零项。阵列ia的长度为m+1。第三个阵列ja包含a的每个元素的m中的列索引,并因此也具有nnz的长度。图41a示出了根据实施例的用于训练具有稀疏性的数据的稀疏密集gemvgpu实现的方法。根据一个实施例,gpu(例如,基于l3的gpu内核)或多核cpu执行操作4100。在操作4102处,经由高速缓存存储器(例如,l3高速缓存)直接从存储器(例如,dram)读取压缩(csr)稀疏矩阵a和密集矩阵b(十进制)或密集向量b。在操作4104处,频繁访问的数据元素可选地存储在用于基于l3的gpu内核的l3高速缓存中。在操作4106处,软件线程的子组(例如,simd(单指令多数据)通道或opencl工作项)在锁定步骤中与硬件线程运行(例如,1到n个硬件线程)相关联。换言之,软件线程的子组(例如,8、16、32个线程)和相关联的硬件线程在操作4108处全都运行相同的指令。每个硬件线程(和相关联的软件线程)在操作4110处理矩阵a中的非零元素的行(或至少一行),并且与具有匹配索引的矩阵b的对应元素相乘以生成输出元素。在操作4112处,累加器对乘法的输出元素执行累加操作,然后生成gpu实现(例如,稀疏密集gemvgpu实现)的输出以用于训练中的稀疏性。软件线程(例如,simd通道8、16、32)与用于预测的硬件线程并行运行。基于l3的实现可以针对多种矩阵维度提供优于slm版本的良好性能。对于基于l3的gpu内核,由于从密集b向量读取的元素不是连续的,这导致分散的l3读取。如果发生高速缓存未命中,则这将导致分散的dram读取。可以通过将密集的瘦小矩阵(或向量b)存储在共享本地存储器(slm)中来减轻这种情况。slm由(由程序员)显式地控制为像存储器等的低延迟高速缓存。现在,分散的读取发生在slm中,这导致slm区块冲突、对slm中相同的区块的1次或多次读取。对于某些矩阵维度,slm区块冲突比分散或未合并的l3读取问题少。图41b示出了根据实施例的用于训练具有稀疏性的数据的稀疏密集gemvgpu实现的方法。根据一个实施例,gpu(例如,基于共享本地存储器(slm)的gpu内核)或多核cpu执行操作4150。在操作4152处,从存储器获得压缩(csr)稀疏矩阵a和密集矩阵b(或向量b)。在该实现中,在操作4154处,由每个工作组以合并的方式将相同的矩阵b或向量b从存储器(例如,dram)卸载到共享本地存储器(slm)。这引入了冗余的全局内存读取。稀疏gemv是带宽束缚操作。因此,为了改善这些内核的性能(例如,功能),应该提高带宽效率。这通过减少一些全局存储器读取来实现。为了获得slm使用的全部好处,本设计减少了到slm的全局负载的数量。这可以通过减少启动稀疏gemv内核所需的总工作组的数量来完成。工作组是在单个计算单元上执行的相关工作项的集合。组中的工作项执行相同的内核并共享本地存储器和工作组障碍。在操作4156处,本设计仅启动少数(afew)工作组(例如,最小数量的工作组),其包括等于由gpu支持的硬件线程总数的硬件线程(例如,gpu支持的最大硬件线程数)。在一个示例中,gpu上支持的硬件线程的总数是56*6=336个线程。要启动以最小化全局读取的工作组总数(例如,最小工作组数)基于(simd_width*硬件线程总数)除以workgroup_size。simd_width通常为8、16或32。在一个示例中,在操作4158处,本设计确定要启动以最小化全局存储器读取(或最小化到slm的全局负载)的工作组的总数(例如,最小工作组数),并选择工作组大小(例如,workgroup_size=224)。在此示例中,可以选择224,因为它均匀地划分分子并且没有线程的浪费。此示例肯定会减少冗余全局读取的总数,但可能无法完全消除冗余的全局读取。对于大型工作负载(例如,输入矩阵大小很大),本设计在操作4160处对硬件线程应用负载平衡技术。在该技术中,在操作4162处,每个硬件线程完成第一数据块,并处理可用的第二数据块。重复使用相同的硬件线程来处理下一部分数据,直到处理完所有数据。这发生在内核中的for循环中,直到不再有剩余的数据要处理。在操作4164处,gpu的硬件线程生成用于稀疏密集gemvgpu实现的输出以用于训练中的稀疏性。对于某些矩阵维度,这种slm技术相对于基于l3的实现给出良好的性能。对于其他维度,分散的l3读取似乎比slm区块冲突和冗余全局读取更好。因此,对于其他维度,使用slm技术不会发生加速。图42示出了根据实施例的用于基于l3的稀疏密集gemv实现的各种矩阵维度和稀疏性的稀疏gemv和密集gemv的图。垂直轴4210表示利用l3实现的稀疏gemv相对于密集gemv的x倍加速(例如,2倍加速,4倍加速等)。水平轴4220表示稀疏矩阵的稀疏度的不同水平(例如,百分比)。对于稀疏度大于约70%,稀疏gemv胜过密集gemv。对于高稀疏度水平(例如,大于90%),本设计实现了约3x至6x(3倍至6倍)的性能加速。在一个示例中,对于某些矩阵向量维度,基于slm的稀疏gemv实现实现了相对于基于l3的稀疏gemv实现的14%至28%的加速。与基于l3的实现相比,测量slm的性能加速(例如,参见稀疏度95%、90%列中的值),如下表3中所示。mkn稀疏度95%稀疏度90%2048204811.171.184096409611.241.181760176011.241.142560256011.331.123072307211.241.033568356811.281.217680256011.251.22图43示出了根据实施例的用于训练中的稀疏性的稀疏密集gemvgpu实现的方法。根据一个实施例,gpu或多核cpu执行操作4300。在操作4302处,gpu将稀疏矩阵编码成csr编码矩阵。在操作4304处,gpu使用稀疏矩阵的csr编码实现稀疏矩阵乘以密集矩阵乘法。在操作4306处,软件线程的每个子组(例如,simd(单指令多数据)通道、工作项)在稀疏矩阵的一个(经压缩csr)行和密集矩阵的第一数量的列(例如,密集矩阵的16个列,任意数量的列,任意数量的行)上操作。在操作4308处,软件线程的每个子组彼此之间共享数据以计算输出。在操作4310处,调度软件线程(例如,工作组)的每个子组,以提高高速缓存利用率,使得对于稀疏矩阵的所有行重复使用密集矩阵的第一数量的列(例如,密集矩阵的16个列,任意数量的列,任何数量的行),以生成输出用于训练中的稀疏性。随后,在操作4312处,从高速缓存存储器中取出密集矩阵的下一第二数量的列(例如,密集矩阵的16个列,任意数量的列,任意数量的行)。在操作4314处,软件线程的每个子组(例如,simd(单指令多数据)通道、工作项)在稀疏矩阵的一个(经压缩csr)行和密集矩阵的第二数量的列(例如,密集矩阵的16个列,任意数量的列,任意数量的行)上操作。在操作4316处,调度软件线程的每个子组,以提高高速缓存利用率,使得对于稀疏矩阵的所有行重复使用密集矩阵的第二数量的列(例如,密集矩阵的16个列,任意数量的列,任何数量的行),以生成输出用于训练中稀疏性。随后,在操作4318处,从高速缓存存储器中取出密集矩阵的下一第三数量的列(例如,密集矩阵的16个列,任意数量的列,任意数量的行)。方法4300继续,直到已经从高速缓存存储器中取出密集矩阵的所有列用于矩阵操作,以生成输出用于训练中的稀疏性。图44示出了根据实施例的,对于标准矩阵维度而言,稀疏gemm相对于密集gemm的改进性能的图。垂直轴4410表示对于标准矩阵维度而言,稀疏gemm相对于密集gemm的x倍加速(例如,1倍加速,2倍加速等)。水平轴4420表示不同的标准矩阵维度(例如,稀疏矩阵的mxn,乘以密集矩阵的列)。对于高稀疏度水平(例如,大约95%),本设计随着矩阵维度增大实现了增加的性能加速。在一个实施例中,用于非重要操作数的检测逻辑(例如,零操作数检测逻辑)可以可选地在本公开的任何fpu中实现。在一个示例中,用于非重要操作数的检测逻辑634a-d(例如,零操作数检测逻辑)已被插入到图6b的fpu634中。硬件线程内的所有simd通道都在锁定步骤中执行指令。如果对应于用于乘法和累加操作(mad)指令的任何simd通道的任何输入操作数包括不重要的值(例如,零),则跳过对应于那些特定通道的mad操作。由于此设计跳过某些通道的计算操作,因此这节省了功率。然而,对于该示例,本设计不节省带宽,因为在从寄存器读取不重要的操作数(例如,零操作数)之后发生不重要操作数检测(例如,零操作数检测)。在一些实施例中,图形处理单元(gpu)被可通信地耦合到主机/处理器核以加速图形操作、机器学习操作、模式分析操作、以及各种通用gpu(gpgpu)功能。gpu可通过总线或另一互连(例如,诸如pcie或nvlink之类的高速互连)被可通信地耦合到主机处理器/核。在其他实施例中,gpu可被集成在与核相同的封装或芯片上,并通过内部处理器总线/互连(即,在封装或芯片的内部)被可通信地耦合到核。不管gpu被连接的方式,处理器核可以以工作描述符中所包含的命令/指令的序列的形式将工作分配给gpu。gpu随后使用专用电路/逻辑以用于高效地处理这些命令/指令。在以下描述中,阐述了很多特定细节来提供更全面的理解。然而,将对本领域技术人员显而易见的是,没有这些特定细节中的一个或多个,也可实践本文中所描述的实施例。在其他实例中,未描述公知的特征以避免使本实施例的细节变得模糊。系统概述图45是展示了被配置成实现本文所述的实施例的一个或多个方面的计算机系统4500的框图。计算系统4500包括处理子系统4501,所述处理子系统具有一个或多个处理器4502和系统存储器4504,所述一个或多个处理器和所述系统存储器经由互连路径进行通信,所述互连路径可以包括存储器中枢4505。存储器中枢4505可以是芯片组部件内的单独的部件,也可以集成在一个或多个处理器4502内。存储器中枢4505经由通信链路4506与i/o子系统4511耦合。i/o子系统4511包括i/o中枢4507,所述i/o中枢可以使得计算系统4500能够从一个或多个输入设备4508接收输入。另外,i/o中枢4507可以使得显示控制器(所述显示控制器可以被包括在一个或多个处理器4502中)能够向一个或多个显示设备4510a提供输出。在一个实施例中,与i/o中枢4507耦合的一个或多个显示设备4510a可以包括本地显示设备、内部显示设备或嵌入式显示设备。在一个实施例中,处理子系统4501包括一个或多个并行处理器4512,所述一个或多个并行处理器经由总线或其他通信链路4513耦合至存储器中枢4505。通信链路4513可以是任意数量的基于标准的通信链路技术或协议(诸如但不限于pciexpress)中的一个,也可以是供应方特定的通信接口或通信结构。在一个实施例中,一个或多个并行处理器4512形成以计算为中心的并行或向量处理系统,所述系统包括大量处理核和/或处理集群诸如集成众核(mic)处理器。在一个实施例中,一个或多个并行处理器4512形成图形处理子系统,所述图形处理子系统可以向经由i/o中枢4507耦合的一个或多个显示设备4510a中的一个输出像素。一个或多个并行处理器4512还可以包括显示控制器和显示接口(未示出)以实现到一个或多个显示设备4510b的直接连接。在i/o子系统4511内,系统存储4514可以连接至i/o中枢4507来为计算系统4500提供存储机制。i/o开关4516可以用于提供接口机制以实现i/o中枢4507和可以集成到平台中的其他部件诸如网络适配器4518和/或无线网络适配器4519以及可以经由一个或多个插入式设备4520添加的各种其他设备之间的连接。网络适配器4518可以是以太网适配器或另一种有线网络适配器。无线网络适配器4519可以包括wi-fi、蓝牙、近场通信(nfc)或包括一个或多个无线电装置的其他网络设备中的一个或多个。计算系统4500可以包括未明确示出的其他部件,这些部件包括usb或其他端口连接件、光存储驱动器、视频捕获设备等,也可以连接至i/o中枢4507。图45中将各种部件互连的通信路径可以使用任何合适的协议诸如基于pci(外围部件互连)的协议(例如,pci-express),或(多个)任何其他总线或点对点通信接口和/或协议诸如nv-link高速互连或本领域中已知的互连协议来实现。在一个实施例中,一个或多个并行处理器4512并入有为进行图形和视频处理而优化的电路,包括例如视频输出电路,并且所述电路构成图形处理单元(gpu)。在另一个实施例中,一个或多个并行处理器4512并入有为进行通用处理而优化的电路,同时保留了本文更详细描述的基础计算架构。在又一个实施例中,计算系统4500的各部件可以与一个或多个其他系统元件集成在单个集成电路上。例如,一个或多个并行处理器4512、存储器中枢4505、(多个)处理器4502和i/o中枢4507可以集成到芯片上系统(soc)集成电路中。可替代地,计算系统4500的各部件可以集成到单个封装中以形成封装中系统(sip)配置。在其他实施例中,计算系统4500的各部件的至少一部分可以集成到多芯片模块(mcm)中,所述多芯片模块可以与其他多芯片模块互连成模块化计算系统。应当理解,本文所示的计算系统4500是例示性的并且变型和修改是可能的。连接拓扑可以根据需要进行修改,所述连接拓扑包括桥的数量和安排、(多个)处理器4502的数量和(多个)并行处理器4512的数量。例如,在一些实施例中,系统存储器4504直接而不是通过桥连接至(多个)处理器4502,而其他设备经由存储器中枢4505和(多个)处理器4502与系统存储器4504进行通信。在其他替代性拓扑中,(多个)并行处理器4512连接至i/o中枢4507或直接连接至一个或多个处理器4502中的一个,而不是连接至存储器中枢4505。在其他实施例中,i/o中枢4507和存储器中枢4505可以集成到单个芯片中。一些实施例可以包括经由多个插座附接的(多个)处理器4502的两个或更多个组,这两个或更多个组可以与(多个)并行处理器4512的两个或更多个实例耦合。本文示出的一些特定部件是可选的并且可能不被包括在计算系统4500的所有实现中。例如,可以支持任意数量的插入式卡或外围装置,或者可以省去一些部件。此外,一些架构可以使用不同的术语来描述与图45所示类似的部件。例如,在一些架构中,存储器中枢4505可以被称为北桥,而i/o中枢4507可以被称为南桥。图46a展示了根据实施例的并行处理器4600。并行处理器4600的各种部件可以使用诸如可编程处理器、专用集成电路(asic)或现场可编程门阵列(fpga)的一个或多个集成电路设备来实现。根据实施例,所展示的并行处理器4600是图45所示的一个或多个并行处理器4512的变体。在一个实施例中,并行处理器4600包括并行处理单元4602。所述并行处理单元包括i/o单元4604,所述i/o单元实现与其他设备包括并行处理单元4602的其他实例的通信。i/o单元4604可以直接连接至其他设备。在一个实施例中,i/o单元4604经由诸如存储器中枢4505的中枢或开关接口的使用来与其他设备连接。存储器中枢4505与i/o单元4604之间的连接形成通信链路4513。在并行处理单元4602内,i/o单元4604与主机接口4606和存储器交叉开关4616连接,其中主机接口4606接收涉及执行处理操作的命令,并且存储器交叉开关4616接收涉及执行存储器操作的命令。当主机接口4606经由i/o单元4604接收命令缓冲器时,主机接口4606可以将用于执行那些命令的工作操作引导至前端4608。在一个实施例中,前端4608与调度器4610耦合,所述调度器被配置成将命令或其它工作项目分配给处理集群阵列4612。在一个实施例中,调度器4610确保在将任务分配给处理集群阵列4612中的处理集群之前,处理集群阵列4612正在被正确地配置并且处于有效状态。在一个实施例中,经由在微控制器上执行的固件逻辑来实现调度器4610。微控制器实现的调度器4610可配置成在粗粒度和细粒度下执行复杂的调度和工作分配操作,从而能够实现对在处理阵列4612上执行的线程的快速抢占和上下文切换。在一个实施例中,主机软件可以经由多个图形处理门铃机制中的一者来证实用于在处理阵列4612上调度的工作负荷。这些工作负荷随后可以由调度器微控制器内的调度器4612逻辑遍及处理阵列4610地自动地分发。处理集群阵列4612可以包括多达“n”个处理集群(例如,集群4614a,集群4614b,一直到集群4614n)。处理集群阵列4612的每个集群4614a至4614n均可执行大量并发线程。调度器4610可以使用各种调度和/或工作分发算法来向处理集群阵列4612的集群4614a至4614n分配工作,这些算法可以依据每种类型的程序或计算引起的工作负荷而变化。调度可以由调度器4610动态地处置,或者可以在编译被配置成由处理集群阵列4612执行的程序逻辑的过程中由编译器逻辑部分地协助。在一个实施例中,处理集群阵列4612的不同集群4614a至4614n可以被分配用于处理不同类型的程序或用于执行不同类型的计算。处理集群阵列4612可以被配置成执行各种类型的并行处理操作。在一个实施例中,处理集群阵列4612被配置成执行通用并行计算操作。例如,处理集群阵列4612可以包括用于执行处理任务包括视频和/或音频数据的过滤,执行建模操作包括物理操作,以及执行数据变换的逻辑。在一个实施例中,处理集群阵列4612被配置成执行并行图形处理操作。在其中并行处理器4600被配置成执行图形处理操作的实施例中,处理集群阵列4612可以包括用于支持此类图形处理操作的执行的附加逻辑,包括但不限于用于执行纹理操作的纹理采样逻辑以及曲面细分逻辑和其他顶点处理逻辑。另外,处理集群阵列4612可以被配置成执行与图形处理相关的着色器程序,诸如但不限于顶点着色器、曲面细分着色器、几何着色器和像素着色器。并行处理单元4602可以经由i/o单元4604从系统存储器传递数据以进行处理。在处理期间,可以在处理期间将经传递的数据存储到片上存储器(例如,并行处理器存储器4622),然后写回到系统存储器。在一个实施例中,当并行处理单元4602用于执行图形处理时,调度器4610可以被配置成将处理工作负荷分成大致相等大小的任务,以更好地使得图形处理操作能够分发到处理集群阵列4612的多个集群4614a至4614n。在一些实施例中,处理集群阵列4612的各部分可以被配置成执行不同类型的处理。例如,第一部分可以被配置成执行顶点着色和拓扑生成,第二部分可以被配置成执行曲面细分和几何着色,第三部分可以被配置成执行像素着色或其他屏幕空间操作,以产生渲染的图像进行显示。由集群4614a至4614n中的一个或多个产生的中间数据可以存储在缓冲器中以允许中间数据在集群4614a至4614n之间传输以用于进一步处理。在操作期间,处理集群阵列4612可以接收将经由调度器4610执行的处理任务,所述调度器从前端4608接收定义处理任务的命令。对于图形处理操作,处理任务可以包括要处理的数据例如表面(补片(patch))数据、图元数据、顶点数据和/或像素数据以及定义如何处理数据的状态参数和命令(例如,要执行哪个程序)的索引。调度器4610可以被配置成获取对应于任务的索引或者可以从前端4608接收索引。前端4608可以被配置成确保处理集群阵列4612在由传入命令缓冲器(例如,批处理缓冲器、入栈缓冲器等)指定的工作负荷被发起之前被配置成有效状态。并行处理单元4602的一个或多个实例中的每一个均可与并行处理器存储器4622耦合。并行处理器存储器4622可以经由存储器交叉开关4616来访问,所述存储器交叉开关可以从处理集群阵列4612以及i/o单元4604接收存储器请求。存储器交叉开关4616可以经由存储器接口4618访问并行处理器存储器4622。存储器接口4618可以包括多个分区单元(例如,分区单元4620a,分区单元4620b,一直到分区单元4620n),这些分区单元可以各自耦合至并行处理器存储器4622的一部分(例如,存储器单元)。在一个实现中,分区单元4620a至4620n的数量被配置成等于存储器单元的数量,使得第一分区单元4620a具有对应的第一存储器单元4624a,第二分区单元4620b具有对应的存储器单元4624b,以及第n分区单元4620n具有对应的第n存储器单元4624n。在其他实施例中,分区单元4620a至4620n的数量可能不等于存储器设备的数量。在各种实施例中,存储器单元4624a至4624n可以包括各种类型的存储器设备,包括动态随机存取存储器(dram)或图形随机存取存储器,诸如同步图形随机存取存储器(sgram),包括图形双倍数据速率(gddr)存储器。在一个实施例中,存储器单元4624a至4624n还可以包括3d堆叠式存储器,包括但不限于高带宽存储器(hbm)。本领域技术人员将会理解,存储器单元4624a至4624n的具体实现可以变化,并且可以由各种常规设计之一进行选择。诸如帧缓冲器或纹理映射的渲染目标可存储在存储器单元4624a至4624n上,从而允许分区单元4620a至4620n并行地写入每个渲染目标的各部分,以高效使用并行处理器存储器4622的可用带宽。在一些实施例中,为了支持利用系统存储器连同本地高速缓存存储器的统一存储器设计,可以将并行处理器存储器4622的本地实例排除在外。在一个实施例中,处理集群阵列4612的集群4614a至4614n中的任一个可以处理将写入并行处理器存储器4622内的存储器单元4624a至4624n中的任一个的数据。存储器交叉开关4616可以被配置成将每个集群4614a至4614n的输出传递到任何分区单元4620a至4620n或另一个集群4614a至4614n,这可以对所述输出执行附加处理操作。每个集群4614a至4614n均可通过存储器交叉开关4616与存储器接口4618进行通信以针对各种外部存储器设备进行读取或写入操作。在一个实施例中,存储器交叉开关4616可连接至存储器接口4618以与i/o单元4604通信,并且可连接至并行处理器存储器4622的本地实例,从而使得不同处理集群4614a至4614n内的处理单元能够与系统存储器或对于并行处理单元4602并非本地的其他存储器进行通信。在一个实施例中,存储器交叉开关4616可以使用虚拟信道来分离集群4614a至4614n与分区单元4620a至4620n之间的业务流。虽然并行处理单元4602的单个实例展示为在并行处理器4600内,但并行处理单元4602的任意数量的实例也可以被包括在内。例如,可以在单个插入式卡上提供并行处理单元4602的多个实例,或者可以使多个插入式卡互连。即使不同实例具有不同的处理核数量、不同的本地并行处理器存储量和/或其他配置差异,并行处理单元4602的不同实例也可以被配置成交互操作。例如,在一个实施例中,并行处理单元4602的一些实例可以包括相对于其他实例的较高精度的浮点单元。并入有并行处理单元4602或并行处理器4600的一个或多个实例的系统可以以各种配置和形状因数来实现,包括但不限于台式计算机、膝上型计算机或手持式个人计算机、服务器、工作站、游戏控制台和/或嵌入式系统。图46b是根据实施例的分区系统4620的框图。在一个实施例中,分区系统4620是图46a的分区单元4620a至4620n中的一个的实例。如图所示,分区单元4620包括l2高速缓存4621、帧缓冲器接口4625和rop4626(光栅操作单元)。l2高速缓存4621是被配置成执行从存储器交叉开关4616和rop4626所接收的加载和存储操作的读取/写入高速缓存。由l2高速缓存4621向帧缓冲器接口4625输出读未命中和紧急回写请求以进行处理。也可以经由帧缓冲器接口4625向帧缓冲器发送更新以用于处理。在一个实施例中,帧缓冲器接口4625与并行处理器存储器中的存储器单元中的一个诸如图46的存储器单元4624a至4624n(例如,在并行处理器存储器4622内)交互。在图形应用中,rop4626是执行光栅操作(诸如,模板印制(stencil)、z测试、混合等等)的处理单元。rop4626随后输出经处理的图形数据,所述经处理的图形数据被存储在图形存储器中。在一些实施例中,rop4626包括压缩逻辑,所述压缩逻辑用于压缩被写入至存储器的深度或颜色数据,并解压缩从存储器读取的深度或颜色数据。压缩逻辑可以是利用多种压缩算法中的一种或多种的无损压缩逻辑。由rop4626执行的压缩的类型可以基于待压缩的数据的统计特性而变化。例如,在一个实施例中,逐图块地对深度和颜色数据执行δ色彩压缩。在一些实施例中,rop4626被包括在每个处理集群(例如,图46的集群4614a至4614n)内而不是分区单元4620内。在这个实施例中,通过存储器交叉开关4616而不是像素片段数据来传输对像素数据的读取和写入请求。经处理图形数据可以显示在显示设备诸如图45的一个或多个显示设备4510中的一个上,由(多个)处理器4502路由以用于进一步处理,或者由图46a的并行处理器4600内的处理实体中的一个路由以用于进一步处理。图46c是根据实施例的并行处理单元内的处理集群4614的框图。在一个实施例中,处理集群是图46的处理集群4614a至4614n中的一个的实例。处理集群4614可以被配置成并行地执行多个线程,其中术语“线程”是指在特定输入数据集上执行的特定程序的实例。在一些实施例中,使用单指令多数据(simd)指令发布技术来支持大量线程的并行执行,而无需提供多个独立的指令单元。在其他实施例中,使用单指令多线程(simt)技术来使用被配置成向处理集群的每一个内的一组处理引擎发出指令的公共指令单元来支持大量大致同步线程的并行执行。与所有处理引擎通常执行相同指令的simd执行机制不同,simt执行允许不同线程更容易地遵循穿过给定线程程序的发散执行路径。本领域技术人员将会理解,simd处理机制表示simt处理机制的功能子集。处理集群4614的操作可以经由向simt并行处理器分发处理任务的流水线管理器4632来控制。流水线管理器4632从图46的调度器4610接收指令并且经由图形多处理器4634和/或纹理单元4636来管理那些指令的执行。所展示的图形多处理器4634是simt并行处理器的示例性实例。然而,不同架构的各种类型的simt并行处理器可以被包括在处理集群4614内。图形多处理器4634的一个或多个实例可以被包括在处理集群4614内。图形多处理器4634可以处理数据,并且数据交叉开关4640可以用于将经处理数据分配到包括其他着色单元的多个可能目的地中的一个。流水线管理器4632可以通过为将经由数据交叉开关4640分发的数据指定目的地来促进经处理数据的分发。处理集群4614内的每个图形多处理器4634均可包括相同的功能执行逻辑组(例如,算术逻辑单元、加载存储单元等)。功能执行逻辑可以通过流水线方式进行配置,其中可以在完成先前的指令之前发出新的指令。功能执行逻辑支持各种运算,包括整数和浮点算数、比较运算、布尔运算、位移位和各种代数函数的计算。在一个实施例中,可以利用相同的功能单元硬件来执行不同的操作,并且可以存在功能单元的任意组合。传输到处理集群4614的指令构成线程。在一组并行处理引擎上执行的一组线程是线程组。线程组在不同的输入数据上执行相同的程序。线程组内的每个线程均可被分配到图形多处理器4634内的不同处理引擎。线程组可以包括比图形多处理器4634内的处理引擎的数量更少的线程。当线程组包括比处理引擎的数量更少的线程时,处理引擎中的一个或多个处理引擎可能在处理所述线程组的周期期间空闲。线程组还可以包括比图形多处理器4634内的处理引擎的数量更多的线程。当线程组包括比图形多处理器4634内的处理引擎的数量更多的线程时,可以在连续的时钟周期上执行处理。在一个实施例中,可以在图形多处理器4634上同时执行多个线程组。在一个实施例中,图形多处理器4634包括用于执行加载和存储操作的内部高速缓存存储器。在一个实施例中,图形多处理器4634可以放弃内部高速缓存而是在处理集群4614内使用高速缓存存储器(例如,l1高速缓存308)。每个图形多处理器4634还可以访问在所有处理集群4614之间共享的分区单元(例如,图46的分区单元4620a至4620n)内的l2高速缓存,并且可以用于在线程之间传递数据。图形多处理器4634还可以访问片外全局存储器,所述片外全局存储器可以包括本地并行处理器存储器和/或系统存储器中的一个或多个。并行处理单元4602外部的任何存储器可以用作全局存储器。其中处理集群4614包括图形多处理器4634的多个实例的实施例可以共享可以在l1高速缓存308中存储的公共指令和数据。每个处理集群4614均可包括被配置成将虚拟地址映射到物理地址的mmu4645(存储器管理单元)。在其他实施例中,mmu4645中的一个或多个实例可以驻留在图46的存储器接口4618内。mmu4645包括用于将虚拟地址映射到图块(tile)的物理地址和可选地高速缓存行索引的一组页表条目(pte)。mmu4645可以包括可以驻留在图形多处理器4634或l1高速缓存或处理集群4614内的地址转换后备缓冲器(tlb)或高速缓存。对物理地址进行处理以分发表面数据访问局部性以实现分区单元之间的高效请求交错。可以使用高速缓存行索引来确定对高速缓存行的请求是命中还是未命中。在图形和计算应用中,处理集群4614可以被配置成使得每个图形多处理器4634均耦合至纹理单元4636以执行纹理映射操作,例如确定纹理样本位置、读取纹理数据和过滤纹理数据。纹理数据是从内部纹理l1高速缓存(未示出)或者在一些实施例中从图形多处理器4634内的l1高速缓存读取,并且是根据需要从l2高速缓存、本地并行处理器存储器或系统存储器获取。每个图形多处理器4634向数据交叉开关4640输出经处理任务以向另一个处理集群4614提供经处理任务以用于进一步处理或经由存储器交叉开关4616在l2高速缓存、本地并行处理器存储器或系统存储器中存储经处理任务。prerop4642(预先光栅操作单元)被配置成从图形多处理器4634接收数据,将数据引导到rop单元,这些rop单元可以如本文所述的那样用分区单元(例如,图46的分区单元4620a至4620n)定位。prerop4642单元可以对颜色混合进行优化、组织像素颜色数据并执行地址转换。应当理解,本文所述的核架构是例示性的并且变型和修改是可能的。例如图形多处理器4634、纹理单元4636、prerop4642等任意数量的处理单元可以被包括在处理集群4614内。此外,虽然仅示出一个处理集群4614,但如本文所述的并行处理单元可以包括处理集群4614的任意数量的实例。在一个实施例中,每个处理集群4614均可被配置成使用单独的和不同的处理单元、l1高速缓存等来独立于其他处理集群4614而操作。图46d示出了根据一个实施例的图形多处理器4634。在这样的实施例中,图形多处理器4634与处理集群4614的流水线管理器4632耦合。图形多处理器4634具有执行流水线,所述执行流水线包括但不限于指令高速缓存4652、指令单元4654、地址映射单元4656、寄存器堆4658、一个或多个通用图形处理单元(gpgpu)核4662和一个或多个加载/存储单元4666。gpgpu核4662和加载/存储单元4666经由存储器和高速缓存互连4668与高速缓存存储器4672和共享存储器4670耦合。在一个实施例中,指令高速缓存4652从流水线管理器4632接收要执行的指令流。将这些指令高速缓存在指令高速缓存4652中并分派用于由指令单元4654执行。指令单元4654可以将指令作为线程组(例如,经线)进行分派,线程组的每个线程均被分配到gpgpu核4662内的不同执行单元。指令可以通过在统一地址空间内指定地址来访问本地、共享或全局地址空间中的任一个。地址映射单元4656可以用于将统一地址空间中的地址转换成可由加载/存储单元4666访问的不同存储器地址。寄存器堆4658为图形多处理器4624的功能单元提供一组寄存器。寄存器堆4658为连接至图形多处理器4624的功能单元(例如,gpgpu核4662、加载/存储单元4666)的数据路径的操作数提供临时存储。在一个实施例中,寄存器堆4658在功能单元中的每一个之间进行划分,使得每个功能单元均被分配寄存器文件4658的专用部分。在一个实施例中,寄存器堆4658在正由图形多处理器4624执行的不同经线之间进行划分。gpgpu核4662可以各自包括用于执行图形多处理器4624的指令的浮点单元(fpu)和/或整数算数逻辑单元(alu)。根据实施例,gpgpu核4662的架构可以类似,也可以不同。例如,在一个实施例中,gpgpu核4662的第一部分包括单精度fpu和整数alu,而gpgpu核的第二部分包括双精度fpu。在一个实施例中,fpu可以实现ieee754-2008浮点算数标准或启用可变精度浮点算数。另外,图形多处理器4624还可以包括用于执行诸如复制矩形或像素混合操作的特定功能的一个或多个固定功能或特殊功能单元。在一个实施例中,gpgpu核中的一个或多个还可以包含固定或特殊功能逻辑。在一个实施例中,gpgpu核4662包括能够对多组数据执行单指令的simd逻辑。在一个实施例中,gpgpu核4662可以物理地执行simd4、simd8和simd16指令,并且逻辑地执行simd1、simd2和simd32指令。针对gpgpu核的simd指令可以由着色器编译器在编译时间生成,或在执行针对单程序多数据(spmd)或simt架构而写并且被编译的程序时自动地生成。可以经由单个simd指令来执行被配置成用于simt执行模型的程序的多个线程。例如且在一个实施例中,可以经由单个simd8逻辑单元来并行执行八个simt线程,这八个simt线程执行相同或类似的操作。存储器和高速缓存互连4668是互连网络,所述互连网络将图形多处理器4624的功能单元中的每一个连接至寄存器堆4658和共享存储器4670。在一个实施例中,存储器和高速缓存互连4668是允许加载/存储单元4666在共享存储器4670与寄存器堆4658之间实现加载和存储操作的交叉开关互连。寄存器堆4658可以以与gpgpu核4662相同的频率操作,因此gpgpu核4662与寄存器堆4658之间的数据传递具有非常低的等待时间。共享存储器4670可以用于实现在图形多处理器4634内的功能单元上执行的线程之间的通信。例如,高速缓存存储器4672可以用作数据高速缓存,以高速缓存在功能单元与纹理单元4636之间通信的纹理数据。共享存储器4670也可以用作经高速缓存的受管理的程序。除了在高速缓存存储器4672内存储的经自动高速缓存的数据之外,在gpgpu核4662上执行的线程还可以在共享存储器内以编程方式存储数据。图47a至图47b示出了根据实施例的附加图形多处理器。所展示的图形多处理器4725、4750是图46c的图形多处理器4634的变体。所展示的图形多处理器4725、4750可以被配置成能够同时执行大量执行线程的流式多处理器(sm)。图47a展示了根据附加实施例的图形多处理器4725。图形多处理器4725包括相对于图46d的图形多处理器4634的执行资源单元的多个附加实例。例如,图形多处理器4725可以包括指令单元4732a至4732b、寄存器堆4734a至4734b和(多个)纹理单元4744a至4744b的多个实例。图形多处理器4725还包括多组图形或计算执行单元(例如,gpgpu核4736a至4736b、gpgpu核4737a至4737b、gpgpu核4738a至4738b)和多组加载/存储单元4740a至4740b。在一个实施例中,执行资源单元具有公共指令高速缓存4730、纹理和/或数据高速缓存存储器4742和共享存储器4746。各种部件可以经由互连结构(interconnectfabric)4727进行通信。在一个实施例中,互连结构4727包括一个或多个交叉开关以实现在图形多处理器4725的各部件之间的通信。在一个实施例中,互连结构4727是单独的、高速网络结构层,图形多处理器4725的每个部件堆叠在该网络结构层上。图形多处理器4725的部件经由互连结构4727与远程部件通信。例如,gpgpu核4736a-4736b、4737a-4737b以及47378a-4737b可以各自经由互连结构4727与共享存储器4746通信。互连结构4727可以仲裁图形多处理器4725内的通信,以确保部件之间公平的带宽分配。图47b展示了根据附加实施例的图形多处理器4750。如图46d和图47a所示,图形处理器包括多组执行资源4756a至4756d,其中每组执行资源均包括多个指令单元、寄存器堆、gpgpu核和加载存储单元。执行资源4756a至4756d可以与(多个)纹理单元4760a至4760d一起工作以进行纹理操作,同时共享指令高速缓存4754和共享存储器4762。在一个实施例中,执行资源4756a至4756d可以共享指令高速缓存4754和共享存储器4762以及纹理和/或数据高速缓存存储器4758a至4758b的多个实例。各种部件可以经由与图47a的互连结构4727类似的互连结构4752进行通信。本领域的技术人员将理解,图45、图46a至图46d和图47a至图47b中所述的架构是描述性的,而不限制本发明的实施例的范围。因此,本文所述的技术可以在任何适当配置的处理单元上实现,包括但不限于:一个或多个移动应用处理器;一个或多个台式计算机或服务器中央处理单元(cpu),包括多核cpu;一个或多个并行处理单元诸如图46的并行处理单元4602;以及一个或多个图形处理器或专用处理单元,而不脱离本文所述的实施例的范围。在一些实施例中,如本文所述的并行处理器或gpgpu通信地耦合至主机/处理器核以加快图形操作、机器学习操作、模式分析操作和各种通用gpu(gpgpu)功能。gpu可以通过总线或其他互连(例如,诸如pcie或nvlink的高速互连)通信地耦合至主机处理器/核。在其他实施例中,gpu可以与核一样集成在相同的封装或芯片上并且通过内部处理器总线/互连(即,在封装或芯片内部)通信地耦合至所述核。不管gpu连接的方式如何,处理器核都可以以工作描述符中包含的命令/指令序列的形式向gpu分配工作。然后,gpu使用专用电路/逻辑来高效地处理这些命令/指令。用于gpu到主机处理器互连的技术图48a展示了其中多个gpu4910至4913通过高速链路4940至4943(例如,总线、点对点互连等)通信地耦合至多个多核处理器4905至4906的示例性架构。在一个实施例中,高速链路4940至4943支持4gb/s、30gb/s、80gb/s或更高的通信吞吐量,这取决于实现。可以使用各种互连协议,包括但不限于pcie4.0或5.0和nvlink2.0。然而,本发明的基本原理不限于任何特定的通信协议或吞吐量。此外,在一个实施例中,gpu4910至4913中的两个或更多个通过高速链路4944至4945互连,这可以使用与用于高速链路4940至4943的协议/链路相同或不同的协议/链路来实现。类似地,多核处理器4905至4906中的两个或更多个可以通过高速链路4933连接,所述高速链路可以是以20gb/s、30gb/s、120gb/s或更高的速度运行的对称多处理器(smp)总线。可替代地,图48a中所示的各种系统部件之间的所有通信均可使用相同的协议/链路(例如,通过公共互连结构)来完成。然而,如所提及的,本发明的基本原理不限于任何特定类型的互连技术。在一个实施例中,每个多核处理器4905至4906分别经由存储器互连4930至4931通信地耦合至处理器存储器4901至4902,并且每个gpu4910至4913分别通过gpu存储器互连4950至4953通信地耦合至gpu存储器4920至4923。存储器互连4930至4931和4950至4953可以利用相同或不同的存储器访问技术。以示例而不是限制的方式,处理器存储器4901至4902和gpu存储器4920至4923可以是诸如动态随机存取存储器(dram)(包括堆叠式dram)、图形ddrsdram(gddr)(例如,gddr5、gddr6)或高带宽存储器(hbm)的易失性存储器,和/或可以是诸如3dxpoint或nano-ram的非易失性存储器。在一个实施例中,存储器的某个部分可以是易失性存储器,而另一个部分可以是非易失性存储器(例如,使用两级存储器(2lm)层级结构)。如下所述,尽管各种处理器4905至4906和gpu4910至4913均可分别物理地耦合至特定存储器4901至4902、4920至4923,但可以实现统一存储器架构,其中相同的虚拟系统地址空间(也称为“有效地址”空间)分发在所有各种物理存储器中。例如,处理器存储器4901至4902可以各自包括64gb的系统存储器地址空间,并且gpu存储器4920至4923可以各自包括32gb的系统存储器地址空间(导致在所述示例中产生总共256gb的可寻址存储空间)。图48b展示了根据一个实施例的多核处理器4907与图形加速模块4946之间的互连的附加细节。图形加速模块4946可以包括集成在经由高速链路4940耦合至处理器4907的线卡上的一个或多个gpu芯片。可替代地,图形加速模块4946可以与处理器4907一样集成在相同的封装或芯片上。所展示的处理器4907包括多个核4960a至4960d,这些核各自具有转换后备缓冲器4961a至4961d和一个或多个高速缓存4962a至4962d。这些核可以包括用于执行指令和处理未展示的数据以避免模糊本发明的基本原理的各种其他部件(例如,指令获取单元、分支预测单元、解码器、执行单元、重排序缓冲器等)。高速缓存4962a至4962d可以包括1级(l1)和2级(l2)高速缓存。此外,一个或多个共享高速缓存4926可以被包括在高速缓存层级结构中并由各组核4960a至4960d共享。例如,处理器4907的一个实施例包括24个核,这些核各自具有它自己的l1高速缓存、12个共享l2高速缓存和12个共享l3高速缓存。在这个实施例中,l2高速缓存和l3高速缓存中的一个由两个相邻核共享。处理器4907和图形加速器集成模块4946与系统存储器4941连接,所述系统存储器可以包括处理器存储器4901至4902。通过一致性总线4964经由核间通信来为各种高速缓存4962a至4962d、4956和系统存储器4941中存储的数据和指令保持一致性。例如,每个高速缓存均可具有与其关联的高速缓存一致性逻辑/电路,以响应于所检测的对特定高速缓存行的读取或写入而通过一致性总线4964进行通信。在一个实现中,通过一致性总线4964实现高速缓存窥探协议以窥探高速缓存访问。本领域技术人员可以很好理解高速缓存窥探/一致性技术,以避免模糊本发明的基本原理,这里不再详细描述。在一个实施例中,代理电路4925将图形加速模块4946通信地耦合至一致性总线4964,从而允许图形加速模块4946作为核的对等体参与缓存一致性协议。具体地讲,接口4935通过高速链路4940(例如,pcie总线、nvlink等)向代理电路4925提供连接性,并且接口4937将图形加速模块4946连接至链路4940。在一个实现中,加速器集成电路4936代表图形加速模块4946的多个图形处理引擎4931、4932、n提供高速缓存管理、存储器访问、上下文管理和中断管理服务。图形处理引擎4931、4932、n可以各自包括单独的图形处理单元(gpu)。可替代地,图形处理引擎4931、4932、n可以在gpu内包括不同类型的图形处理引擎诸如图形执行单元、媒体处理引擎(例如,视频编码器/解码器)、采样器和块图像传输引擎。换句话讲,图形加速模块可以是具有多个图形处理引擎4931、4932、n的gpu,或图形处理引擎4931至4932、n可以是集成在公共包、线卡或芯片上的单独gpu。在一个实施例中,加速器集成电路4936包括存储器管理单元(mmu)4939,所述存储器管理单元用于执行诸如虚拟到物理存储器转换(也称为有效到实际存储器转换)的各种存储器管理功能和用于访问系统存储器4941的存储器访问协议。mmu4939还可以包括用于高速缓存虚拟/有效到物理/实际地址转换的转换后备缓冲器(tlb)(未示出)。在一个实现中,高速缓存4938存储用于由图形处理引擎4931至4932、n高效访问的命令和数据。在一个实施例中,使高速缓存4938和图形存储器4933至4934、n中存储的数据与核高速缓存4962a至4962d、4956和系统存储器4911保持一致。如所提及的,这可以经由代理电路4925来完成,所述代理电路代表高速缓存4938和存储器4933至4934、n参与高速缓存一致性机制(例如,向高速缓存4938发送与处理器高速缓存4962a至4962d、4956上的高速缓存行的修改/访问相关的更新并从高速缓存4938接收更新)。一组寄存器4945存储由图形处理引擎4931至4932、n执行的线程的上下文数据,并且上下文管理电路4948管理线程上下文。例如,上下文管理电路4948可以执行保存和恢复操作以在上下文切换期间保存和恢复各种线程的上下文(例如,其中第一线程被保存并且第二线程被存储,使得第二线程可以由图形处理引擎执行)。例如,在上下文切换时,上下文管理电路4948可以将当前寄存器值存储到存储器中的指定区域(例如,由上下文指针标识)。所述上下文管理电路可以在返回上下文时恢复寄存器值。在一个实施例中,中断管理电路4947接收并处理从系统设备所接收的中断。在一个实现中,由mmu4939将来自图形处理引擎4931的虚拟/有效地址转换为系统存储器4911中的实际/物理地址。加速器集成电路4936的一个实施例支持多个(例如,4个、8个、16个)图形加速器模块4946和/或其他加速器设备。图形加速器模块4946可以专用于在处理器4907上执行的单个应用,或者可以在多个应用之间共享。在一个实施例中,呈现虚拟图形执行环境,其中图形处理引擎4931至4932、n的资源与多个应用或虚拟机(vm)共享。资源可以被细分为基于与vm和/或应用相关联的处理要求和优先级而分配给不同的vm和/或应用的“分片”。因此,加速器集成电路充当图形加速模块4946的系统的桥,并提供地址转换和系统存储器高速缓存服务。此外,加速器集成电路4936可以为主机处理器提供虚拟化设施以管理图形处理引擎、中断和存储器管理的虚拟化。由于图形处理引擎4931至4932、n的硬件资源显式地地映射到由主机处理器4907看到的实际地址空间,因此任何主处理器都可以使用有效地址值来为这些资源直接寻址。在一个实施例中,加速器集成电路4936的一个功能是图形处理引擎4931至4932、n的物理分离,使得它们作为独立单元出现在系统上。如所提及的,在所展示的实施例中,一个或多个图形存储器4933至4934、m分别耦合至图形处理引擎4931至4932、n中的每一个。图形存储器4933至4934、m存储正由图形处理引擎4931至4932、n中的每一个处理的指令和数据。图形存储器4933至4934,m可以是诸如dram(包括堆叠式dram)、gddr存储器(例如,gddr5、gddr6)或hbm的易失性存储器,和/或可以是诸如3dxpoint或nano-ram的非易失性存储器。在一个实施例中,为了减少链路4940上的数据流量,使用偏置技术来确保图形存储器4933至4934、m中存储的数据是图形处理引擎4931至4932、n最频繁使用,并且核4960a至4960d优选不使用(至少不频繁使用)的数据。类似地,偏置机制试图使核(并且优选地不是图形处理引擎4931至4932、n)所需的数据保持在核和系统存储器4911的高速缓存4962a至4962d、4956内。图48c展示了其中加速器集成电路4936集成在处理器4907内的另一个实施例。在这个实施例中,图形处理引擎4931至4932、n经由接口4937和接口4935来直接通过高速链路4940与加速器集成电路4936进行通信(这也可以利用任何形式的总线或接口协议)。加速器集成电路4936可以执行与关于图48b所描述的操作相同的操作,但考虑到其与一致性总线4962和高速缓存4962a至4962d、4926紧密接近,可能以较高的吞吐量进行操作。一个实施例支持不同的编程模型,包括专用进程编程模型(不具有图形加速模块虚拟化)和共享编程模型(具有虚拟化)。共享编程模型可以包括由加速器集成电路4936控制的编程模型和由图形加速模块4946控制的编程模型。在专用进程模型的一个实施例中,图形处理引擎4931至4932、n在单个操作系统下专用于单个应用或进程。单个应用可以将其他应用请求集中到图形引擎4931至4932、n,从而在vm/分区内提供虚拟化。在专用进程编程模型中,图形处理引擎4931至4932、n可以由多个vm/应用分区共享。共享模型需要系统管理程序,所述系统管理程序用于将图形处理引擎4931至4932、n虚拟化,以允许由每个操作系统进行访问。对于没有管理程序的单分区系统,图形处理引擎4931至4932、n由操作系统拥有。在这两种情况下,操作系统都可以将图形处理引擎4931至4932、n虚拟化以提供对每个进程或应用的访问。对于共享编程模型,图形加速模块4946或单独图形处理引擎4931至4932、n使用进程句柄来选择进程要素。在一个实施例中,进程要素被存储在系统存储器4911中并且可使用本文所述的有效地址到实际地址转换技术来寻址。所述进程句柄可以是在向图形处理引擎4931至4932、n注册它的上下文(即,调用系统软件以向进程要素链表添加进程要素)时向主机进程提供特定于实现的值。所述进程句柄的低16位可以是进程要素链表内的进程要素的偏移量。图48d展示了示例性加速器集成分片4990。如本文所用,“分片”包括加速器集成电路4936的处理资源的指定部分。系统存储器4911内的应用有效地址空间4982存储进程要素4983。在一个实施例中,进程要素4983响应于来自在处理器4907上执行的应用4980的gpu调用4981而被存储。进程要素4983包含相应应用4980的处理状态。进程要素4983中包含的工作描述符(wd)4984可以是应用所请求的单个作业,或者可以包含指向作业队列的指针。在后一种情况下,wd4984是指向应用地址空间4982中的作业请求队列的指针。图形加速模块4946和/或单独图形处理引擎4931至4932、n可以由系统中的全部或部分进程共享。本发明的实施例包括用于建立处理状态并向图形加速模块4946发送wd4984以在虚拟环境中开始作业的基础结构。在一个实现中,专用进程编程模型是特定于具体实施的。在这个模型中,单个进程拥有图形加速模块4946或单独的图形处理引擎4931。由于图形加速模块4946由单个进程拥有,因此管理程序初始化加速器集成电路4936以获得所属分区,并且操作系统在图形加速模块4946被分配时初始化加速器集成电路4936以获取所属进程。在操作中,加速器集成分片4990中的wd获取单元4991获取下一个wd4984,所述wd包括将由图形加速模块4946的图形处理引擎之一进行的工作的指示。如图所示,来自wd4984的数据可以被存储在寄存器4945中并由mmu4939、中断管理电路4947和/或上下文管理电路4946使用。例如,mmu4939的一个实施例包括用于访问os虚拟地址空间4985内的段/页表4986的段/页步行(walk)电路。中断管理电路4947可以处理从图形加速模块4946所接收的中断事件4992。当执行图形操作时,由图形处理引擎4931至4932、n生成的有效地址4993由mmu4939转换为实际地址。在一个实施例中,针对每个图形处理引擎4931至4932、n和/或图形加速模块4946复制同一组寄存器4945,并且可以由管理程序或操作系统初始化这一组寄存器。这些复制的寄存器中的每一个均可被包括在加速器集成分片4990中。表4中示出了可以由管理程序初始化的示例性寄存器。表4-管理程序初始化寄存器表5中示出了可以由操作系统初始化的示例性寄存器。表5-操作系统初始化寄存器1进程和线程标识2有效地址(ea)上下文保存/恢复指针3虚拟地址(ra)加速器利用记录指针4虚拟地址(ra)存储段表指针5授权掩码6工作描述符在一个实施例中,每个wd4984均特定于特定图形加速模块4946和/或图形处理引擎4931至4932、n。所述wd包含图形处理引擎4931至4932、n完成其工作所需的所有信息,或者所述wd可以是指向应用已经建立了要完成的工作命令队列的存储器位置的指针。图48e展示了共享模型的一个实施例的附加细节。所述实施例包括其中存储了进程要素列表4999的管理程序实际地址空间4998。管理程序实际地址空间4998可经由管理程序4996来访问,所述管理程序将操作系统4995的图形加速模块引擎虚拟化。共享编程模型允许来自系统中的全部或部分分区的全部或部分进程使用图形加速模块4946。有两种编程模型,其中图形加速模块4946由多个进程和分区共享:时间分片共享和图形直接共享。在这个模型中,系统管理程序4996拥有图形加速模块4946并且使其功能对所有操作系统4995可用。为使图形加速模块4946支持系统管理程序4996的虚拟化,图形加速模块4946可遵守以下要求:1)应用作业请求必须是自主的(即,不需要维持作业之间的状态),或者图形加速模块4946必须提供上下文保存和恢复机制。2)图形加速模块4946保证在指定时间量内完成应用作业请求,包括任何转换错误,或者图形加速模块4946提供抢占作业处理的能力。3)当以直接共享编程模型操作时,必须保证进程中图形加速模块4946的公平性。在一个实施例中,对于共享模型,需要应用4980来利用图形加速模块4946类型、工作描述符(wd)、授权掩码寄存器(amr)值以及上下文保存/恢复区域指针(csrp)来进行操作系统4995系统调用。图形加速模块4946类型描述了系统调用的目标加速功能。图形加速模块4946类型可以是特定于系统的值。所述wd专门针对图形加速模块4946来格式化,并且可以呈以下形式:图形加速模块4946命令;指向用户定义结构的有效地址指针;指向命令队列的有效地址指针;或用于描述将由图形加速模块4946进行的工作的任何其他数据结构。在一个实施例中,amr值是用于当前进程的amr状态。传递给操作系统的值与设置amr的应用类似。如果加速器集成电路4936和图形加速模块4946的实现不支持用户授权掩码覆盖寄存器(uamor),则操作系统可以在管理程序调用中传递amr之前向amr值应用当前uamor值。在将amr置于进程要素4983之前,管理程序4996可以可选地应用当前授权掩码覆盖寄存器(amor)值。在一个实施例中,csrp是包含应用地址空间4982中供图形加速模块4946保存和恢复上下文状态的区域的有效地址的寄存器4945中的一个。如果不需要在作业之间保存状态或当作业被抢占时,这个指针是可选的。所述上下文保存/恢复区域可以是插接的系统存储器。在接收到系统调用时,操作系统4995可以验证应用4980已注册并被授权使用图形加速模块4946。操作系统4995然后利用表6中所示的信息来调用管理程序4996。表6-操作系统对管理程序的调用参数在接收到管理程序调用时,管理程序4996可以验证操作系统4995已注册并被授权使用图形加速模块4946。管理程序4996然后将进程要素4983针对对应图形加速模块4946类型放入进程要素链表中。进程要素可以包含表7中所示的信息。表7-进程要素信息1工作描述符(wd)2授权掩码寄存器(amr)值(可能已掩蔽)3有效地址(ea)上下文保存/恢复区域指针(csrp)4进程id(pid)和可选的线程id(tid)5虚拟地址(va)加速器利用记录指针(aurp)6存储段表指针(sstp)的虚拟地址7逻辑中断服务号(lisn)8中断向量表,从管理程序调用参数导出9状态寄存器(sr)值10逻辑分区id(lpid)11实际地址(ra)管理程序加速器利用记录指针12存储描述符寄存器(sdr)在一个实施例中,管理程序将寄存器4945的多个加速器集成分片4990初始化。如图48f所展示,本发明的一个实施例采用可经由用于访问物理处理器存储器4901至4902和gpu存储器4920至4923的公共虚拟存储器地址空间来寻址的统一存储器。在这个实现中,在gpu4910至4913上执行的操作利用相同的虚拟/有效存储器地址空间来访问处理器存储器4901至4902,反之亦然,由此简化可编程性。在一个实施例中,将虚拟/有效地址空间的第一部分分配给处理器存储器4901,将第二部分分配给第二处理器存储器4902,将第三部分分配给gpu存储器4920,以此类推。整个虚拟/有效存储器空间(有时称为有效地址空间)由此分布在处理器存储器4901至4902和gpu存储器4920至4923中的每一个上,从而允许任何处理器或gpu访问具有映射到所述存储器的虚拟地址的任何物理存储器。在一个实施例中,mmu4939a至4939e中的一个或多个内的偏置/一致性管理电路4994a至4994e确保了主机处理器(例如,4905)与gpu4910至4913的高速缓存之间的高速缓存一致性,并且实现了指示其中应当存储某些类型的数据的物理存储器的偏置技术。尽管在图48f中展示了偏置/一致性管理电路4994a至4994e的多个实例,但偏置/一致性电路也可以在一个或多个主机处理器4905的mmu内和/或在加速器集成电路4936内实现。一个实施例允许将gpu附接的存储器4920至4923映射为系统存储器的一部分,并使用共享虚拟存储器(svm)技术进行访问,但不会遭受与全系统高速缓存一致性相关的典型性能缺陷。gpu附接的存储器4920至4923作为系统存储器来访问的能力不会造成繁重的高速缓存一致性开销,这为gpu卸载提供了有利的操作环境。这种安排允许主机处理器4905软件设置操作数并访问计算结果,而不具有传统i/odma数据拷贝的开销。这些传统拷贝涉及驱动器调用、中断和存储器映射i/o(mmio)访问,这些访问相对于简单内存访问来说都是低效的。同时,在不具有高速缓存一致性开销的情况下访问gpu附接存储器4920至4923的能力对于卸载计算的执行时间可能是关键的。例如,在具有大量流式写入存储器业务的情况下,高速缓存一致性开销可以显著降低由gpu4910至4913看到的有效写入带宽。操作数设置的效率、结果访问的效率以及gpu计算的效率都在确定gpu卸载的有效性方面发挥着重要作用。在一个实现中,gpu偏置与主机处理器偏置之间的选择由偏置跟踪器数据结构驱动。例如,可以使用偏置表,所述偏置表可以是每个gpu附接存储器页包括1或2个位的页粒度结构(即,以存储器页的粒度来控制)。偏置表可以在一个或多个gpu附接存储器4920至4923的被盗存储器范围内实现,在gpu4910至4913中具有或不具有偏置高速缓存(例如,以高速缓存频繁/最近使用的偏置表的条目)。可替代地,整个偏置表均可保持在gpu内。在一个实现中,在实际访问gpu存储器之前访问与对gpu附接存储器4920至4923的每次访问相关联的偏置表条目,从而使得以下操作。首先,将来自gpu4910至4913的在gpu偏置中发现其页的本地请求直接转发到对应的gpu存储器4920至4923。将来自gpu的在主机偏置中发现其页的本地请求转发给处理器4905(例如,如上所述通过高速链路)。在一个实施例中,来自处理器4905的在主机处理器偏置中发现所请求的页的请求完成了像正常存储器读取那样的请求。可替代地,可以将针对gpu偏置页的请求转发给gpu4910至4913。如果gpu当前未使用所述页,则gpu可以将所述页转换为主机处理器偏置。页的偏置状态可以通过基于软件的机制、基于硬件辅助软件的机制,或者对于一组有限的情况,基于仅硬件的机制来改变。一种用于改变偏置状态的机制采用api调用(例如opencl),所述api调用继而调用gpu设备驱动器,所述驱动器继而向gpu发送消息(或将命令描述符入队),从而引导所述gpu改变偏置状态,并且对于某些转换,在主机中执行高速缓存转储清除操作。所述高速缓存转储清除操作是从主机处理器4905偏置到gpu偏置的转换所必需的,而对于相反转换则不是必需的。在一个实施例中,通过暂时呈现主机处理器4905不可高速缓存的gpu偏置页来保持缓存一致性。为了访问这些页,处理器4905可以请求来自gpu4910的访问,gpu可以依据实现立即授权访问也可以不授权访问。因此,为了减少处理器4905与gpu4910之间的通信,有利的是确保gpu偏置页是gpu所需但不是主机处理器4905所需的页,反之亦然。图48g示出了根据实施例的多gpu计算系统。多gpu计算系统可以包括经由主机接口开关4904耦合到多个gpu4914a-4914d的处理器4903。在一个实施例中,主机接口开关404是pciexpress开关设备,其将处理器49803耦合到pciexpress总线,处理器4903可以通过pciexpress总线与该组gpu4914a-4914d进行通信。gpu4914a-4914d可以经由一组高速点对点gpu与gpu链路4916互连。高速gpu到gpu链路可以经由专用gpu链路连接到gpu4914a-4914d中的每一个,所述gpu链路诸如如图dplab中的gpu链路dplab10。p2pgpu链路4916使得能够在gpu4914a-4914d中的每一个之间进行直接通信,而不需要通过处理器4903所连接的主机接口总线进行通信。利用指向p2pgpu链路的gpu到gpu话务,主机接口总线保持可用于系统存储器访问或者与多gpu计算系统4900的其他实例通信,例如,经由一个或多个网络设备。虽然在所示实施例中,gpu4914a-4914d经由主机接口开关4904连接到处理器4903,但在一个实施例中,处理器4903包括对p2pgpu链路4916的直接支持,并且可以直接连接到gpu4914a-4914d。图形处理流水线图49展示了根据实施例的图形处理流水线5000。在一个实施例中,图形处理器可以实现所展示的图形处理流水线5000。所述图形处理器可以被包括在如本文所述的并行处理子系统诸如图46的并行处理器4600内,在一个实施例中,所述并行处理器是图45的(多个)并行处理器4512的变体。如本文所述,各种并行处理系统可以经由并行处理单元(例如,图46的并行处理单元4602)的一个或多个实例来实现图形处理流水线5000。例如,着色器单元(例如,图47的图形多处理器4734)可以被配置成执行顶点处理单元5004、曲面细分控制处理单元5008、曲面细分评估处理单元5012、几何处理单元5016和片段/像素处理单元5024中的一个或多个的功能。数据组装器5002,图元组装器5006、5014、5018,曲面细分单元5010,光栅化器5022和光栅操作单元5026的功能还可以由处理集群(例如,图47的处理集群4714)内的其他处理引擎和对应的分区单元(例如,图46的分区单元4620a至4620n)执行。图形处理流水线5000还可以使用一个或多个功能的专用处理单元来实现。在一个实施例中,图形处理流水线5000的一个或多个部分可以由通用处理器(例如,cpu)内的并行处理逻辑执行。在一个实施例中,图形处理流水线5000的一个或多个部分可经由存储器接口5028访问片上存储器(例如,如图46所示的并行处理器存储器4622),所述存储器接口可以是图46的存储器接口4618的实例。在一个实施例中,数据组装器5002是收集表面和图元的顶点数据的处理单元。数据组装器5002然后向顶点处理单元5004输出包括顶点属性的顶点数据。顶点处理单元5004是可编程执行单元,所述可编程执行单元执行顶点着色器程序,从而照明和变换如顶点着色器程序所指定的顶点数据。顶点处理单元5004读取高速缓存、本地或系统存储器中存储的用于处理顶点数据的数据,并且可以编程为将顶点数据从基于对象的坐标表示变换为世界空间坐标空间或归一化设备坐标空间。图元组装器5006的第一实例从顶点处理单元5000接收顶点属性。图元组装器5006根据需要读取所存储的顶点属性并构造图形图元以由曲面细分控制处理单元5008进行处理。图形图元包括如各种图形处理应用编程接口(api)所支持的三角形、线段、点、补片等等。曲面细分控制处理单元5008将输入顶点视为几何补片的控制点。这些控制点从来自补片的输入表示(例如,补片的基础)变换为适用于由曲面细分评估处理单元5012进行表面评估的表示。曲面细分控制处理单元5008还可以计算几何补片的边缘的曲面细分因子。曲面细分因子适用于单个边缘,并量化与边缘相关的依赖于视图的细节等级。曲面细分单元5010被配置成接收补片的边缘的曲面细分因子并将补片细分为多个几何图元诸如线、三角形或四边形图元,所述多个几何图元被传输到曲面细分评估处理单元5012。曲面细分评估处理单元5012对细分的补片的参数化坐标进行操作以生成与几何图元相关的每个顶点的表面表示和顶点属性。图元组装器5014的第二实例从曲面细分评估处理单元5012接收顶点属性,根据需要读取所存储的顶点属性,并构造图形图元以由几何处理单元5016处理。几何处理单元5016是可编程执行单元,所述可编程执行单元执行几何着色器程序,以变换如几何着色器程序所指定的从图元组装器5014所接收的图形图元。在一个实施例中,几何处理单元5016被编程为将图形图元细分为一个或多个新的图形图元并且计算用于将新的图形图元光栅化的参数。在一些实施例中,几何处理单元5016可以添加或删除几何流中的元素。几何处理单元5016向图元组装器5018输出指定新图形图元的参数和顶点。图元组装器5018从几何处理单元5016接收参数和顶点,并构建图形图元以由视口缩放、拣选和剪辑单元5020进行处理。几何处理单元5016读取并行处理器存储器或系统存储器中存储的数据以用于处理几何数据。视口缩放、拣选和剪辑单元5020执行剪辑、拣选和视口缩放,并向光栅化器5022输出经处理的图形图元。光栅化器5022可以执行深度拣选和其他基于深度的优化。光栅化器5022还对新图形图元执行扫描转换以生成段并向段/像素处理单元5024输出这些段和关联的覆盖数据。片段/像素处理单元5024是被配置成执行片段着色器程序或像素着色器程序的可编程执行单元。片段/像素处理单元5024变换从光栅化器5022所接收的片段或像素,如片段或像素着色器程序所指定的。例如,片段/像素处理单元5024可以被编程为执行包括但不限于纹理映射、着色、混合、纹理校正和透视校正的操作,以产生输出到光栅操作单元5026的着色片段或像素。片段/像素处理单元5024可以读取并行处理器存储器或系统存储器中存储的数据,以在处理片段数据时使用。片段或像素着色器程序可以被配置成依据针对处理单元进行配置的采样速率以样本、像素、图块或其他粒度着色。光栅操作单元5026是执行包括但不限于模板印刷、z测试、混合等光栅操作的处理单元,并且将像素数据作为经处理图形数据输出以存储在图形存储器中(例如,图46中的并行处理器存储器4622,和/或如图45中的系统存储器4504,以在一个或多个显示设备4510上显示或者由一个或多个处理器4502或(多个)并行处理器4512中的一个进一步处理。在一些实施例中,光栅操作单元5026被配置成压缩写入存储器的z或颜色数据,并解压缩从存储器读取的z或颜色数据。前述说明和附图应当被认为是说明性的,而不是限制性的。本领域技术人员将理解,可对本文中所描述的实施例作出各种修改和改变,而不背离如所附权利要求中所阐述的本发明的更宽泛精神和范围。一些实施例涉及示例1,示例1包括一种用于促进处理用于任意神经网络的稀疏矩阵的装置,该装置包括图形处理单元,该图形处理单元包括数据管理单元(dmu),该数据管理单元具有:调度器,用于调度矩阵操作;有效电路,用于跟踪有效输入操作数;以及跳过电路,用于跟踪要由调度器跳过的不重要输入操作数。处理电路被耦合到dmu。处理电路包括多个处理元件,处理元件包括用于读取操作数的电路和用于使任意神经网络的两个或更多个操作数相乘的乘法单元。示例2包括示例1的主题,其中,调度器用于在乘法单元处调度非零操作数。示例3包括示例1和示例2的主题,进一步包括具有指针电路的存储器,,以及用于存储输入向量和输出向量的存储器,该指针电路用于存储输入向量和输出向量的基指针。示例4包括示例1-3的主题,其中,每个处理元件包括:用于读取操作数的电路、用于提供指向矩阵的加权系数的存储器地址的列指针的指针电路、用于产生由列指针标识的加权系数值并将其发送到乘法单元的数据电路。示例5包括示例1-4的主题,其中,数据电路将输出向量的存储器地址或位置的标识符发送到输出缓冲器。示例6包括示例1-5的主题,进一步包括,其中图形处理单元用于支持遍及(across)任意不规则神经网络的任何层的任意连接。一些实施例涉及示例7,示例7包括一种用于促进处理任意神经网络的稀疏矩阵的硬件加速器,该硬件加速器包括:数据管理单元(dmu),该数据管理单元具有用于调度矩阵操作的调度器和用于存储有效输入操作数的辅助缓冲器;以及多个处理元件,其被耦合到dmu,每个处理元件包括用于边缘数据和消息数据的输入缓冲器,以及用于支持任意神经网络的输入顶点程序的可定制电路。示例8包括示例7的主题,其中用于支持输入顶点程序的可定制电路支持乘法、累加、激活和发送消息功能。示例9包括示例7-8的主题,其中,每个处理元件进一步包括芯片上存储器,用于经由dmu从芯片外存储器接收向量数据。示例10包括示例7-9的主题,其中dmu用于基于定制的函数从芯片上存储器获得更新的向量数据,并随后将更新的向量数据发送到芯片外存储器。示例11包括示例7-10的主题,其中,硬件加速器用于支持遍及(across)任意不规则神经网络的任何层的任意连接。一些实施例涉及示例12,示例12包括图形处理单元,该图形处理单元包括用于管理稀疏性操作的稀疏性管理单元、用于支持块fp操作的块浮点(fp)管理单元3120、以及用于支持可变和混合精度操作的可变和混合精度计算单元。示例13包括示例12的主题,其中,稀疏性管理单元包括:值检查机制,该值检查机制用于检测包括零操作数的不重要值并跳过这些不重要的输入向量值;以及调度器,该调度器用于基于调度重要值并跳过由值检查机制检测到的输入向量的不重要值,来确定对计算的调度。示例14包括示例12-13的主题,其中,块fp管理单元包括选择电路,该选择电路用于如果输入向量具有块fp并因此具有不同的指数,则为输入向量选择共享指数。示例15包括示例12-14的主题,其中,块fp管理单元包括对齐电路,用于使具有指数变化的输入向量的尾数对齐。示例16包括示例12-15的主题,其中,可变和混合精度计算单元包括用于执行输入向量的计算的计算单元和累加器,其中,计算包括空间和时间计算中的至少一个,所述空间和时间计算包括任何空间和时间组合。一些实施例涉及示例17,示例17包括一种用于训练数据的方法,该方法包括:获得利用压缩稀疏行(csr)和第二密集矩阵编码的第一稀疏矩阵,以合并的方式将第二密集矩阵从存储器卸载到共享本地存储器(slm),以及启动至少一个工作组(例如,最小数量的工作组),该至少一个工作组包括由图形处理单元(gpu)支持的大约硬件线程总数。示例18包括示例17的主题,进一步包括:确定要启动以最小化到slm的全局存储器负载的最小数量的工作组并选择工作组大小。示例19包括示例17-18的主题,进一步包括对硬件线程应用负载平衡技术,使得每个硬件线程完成第一数据块并处理可用的第二数据块。示例20包括示例17-19的主题,进一步包括生成稀疏密集gemvgpu实现的输出以用于数据的训练。前述说明和附图应当被认为是说明性的,而不是限制性的。本领域技术人员将理解,可对本文中所描述的实施例作出各种修改和改变,而不背离如所附权利要求中所阐述的本发明的更宽泛精神和范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1