基于数据质量检测规则挖掘结果的进一步挖掘方法与流程
本发明属于数据挖掘技术领域,特别涉及一种基于数据质量检测规则挖掘结果的进一步挖掘方法。
背景技术:
在数据呈爆炸性增长的今天,所有的数据都有一定程度的质量。数据质量(dataquality)指的是在业务环境中,数据满足用户需求的程度以及在完整性、有效性、一致性等方面的完善程度。数据质量检测规则是检测数据质量的关键,是一种使用语义、语法等限定方法对数据、知识和业务范围进行限制的方式。自动发现数据质量检测规则可以减少领域专家设计、配置数据质量检测规则的周期,减少领域专家的工作量,提高工作效率,加快数据质量的建设进程。
随着组织对数据质量建设的重视,对数据质量检测规则的挖掘也越来越具有发展潜力,但是如何在数据质量检测规则挖掘结果的基础上再进一步地挖掘出数据值背后所潜藏的规律,成为了一个新的发展方向。目前虽然已有一些对数据质量检测规则进行挖掘的方法,但并未在挖掘结果之上做进一步的研究,因此对于数据所潜在的应用价值也未进行充分地利用,未能从数据中提炼出潜在的发展规律,从长远的发展角度来看,未能很好地适应当前结合人工智能技术进行持续发展的现状和要求。
技术实现要素:
本发明的目的在于通过进行数据质量检测规则的挖掘,在挖掘结果的基础上分析、提炼出属性值之间潜藏的规律,为决策者进行相应的决策调整提供强有力的数据支撑。
一种基于数据质量检测规则挖掘结果的进一步挖掘方法,包括以下步骤:
s1、挖掘数据质量检测规则;
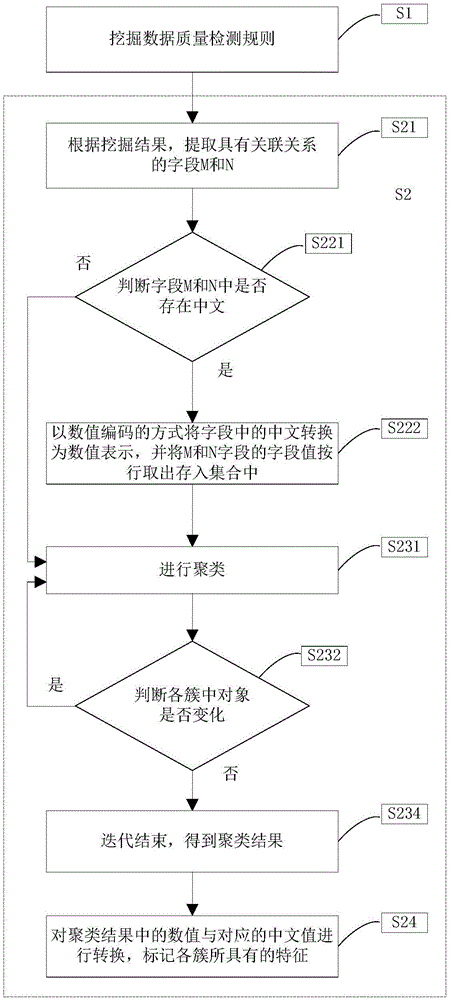
s2、根据挖掘结果,得到m字段和n字段的关联关系,将m字段和n字段的字段值进行聚类,对聚类结果中每一簇的特征进行转换,并标记各簇的特征。
进一步地,所述步骤s1包括以下流程:
r为关系模式,r的一实例为r,attr(r)为关系模式r的所有属性的集合,x为关系模式r的一属性子集,a为关系模式r的单个属性,tp为包含了x和a中属性的模式元组,挖掘到的数据质量检测规则的表达形式为cfd:(x→a,tp)。
进一步地,所述步骤s1中挖掘数据质量检测规则的过程包括以下流程:
s11、扫描数据库,在所述关系模式r中通过将所有先行值(即x→a中的x)集合建模得到属性包含格,搜索时,先考虑所有由单个属性组成的节点,再逐次考虑多属性组成的节点,直到达到(n-1)级,其中,n为关系模式r中的属性个数;
s12、为本层各节点(x,tp)计算其c+(x,tp),其中,c+(x,tp)={(a,ca)};判断本层各个(x,tp)是否有相应的cfd:(x\{a}→a,tp[x\{a}]||tp[a])成立,若cfd成立,则修改本层中所有比节点(x,tp)更具体的(x,up)的c+(x,up),从c+(x,up)中除去节点(a,ca)及(b,cb),其中b属于关系模式r上去除了属性集x的属性集;
s13、检查本层各个(x,tp),若c+(x,tp)为空,则剪去(x,tp);
s14、若两节点(x,sp)、(y,tp)的前缀相同,,即x与y、sp与tp各自的前k-1个值对应相同,则为lk+1层生成新节点(z,up)=(xuy[k],sputp[k]),并令lk=lk+1,直至lk+1为空集。
进一步地,所述步骤s2包括以下流程:
s21、根据所述步骤s1的挖掘结果,提取具有关联关系的m字段和n字段,对其中一个字段进行数据列剖析,得到该列字段值中存在的不同值个数,以此作为聚类的簇数m;
s22、判断m字段和n字段中是否存在中文,若存在中文,则以数值编码的方式将中文转换为数值进行表示,将两字段的字段值按行取出存入集合中;
s23、进行聚类,创建初始划分,从数据集中随机选择m个对象,每个对象初始代表一个簇中心;对于除簇中心m个对象以外的其它对象,计算其与每个簇中心的距离,将其划入到距离最近的簇,采用欧几里得距离公式计算距离;采用迭代的方法,当有新的对象加入簇或已有对象离开簇的时候,重新计算簇中心的值,对对象进行重新分配;直到各簇中对象不再变化,迭代结束,得到聚类结果;
s24,对聚类结果中每一个簇的特征进行转换,将数值与对应的中文值进行映射,并标记各簇的特征。
本发明的有益效果:本发明提供了一种基于数据质量检测规则挖掘结果的进一步挖掘方法,本发明从数据质量检测规则挖掘结果出发,在挖掘结果的基础上分析、提炼,从数据值中发现出潜在的知识与规律,为数据管理者做出决策提供强有力的数据支撑。
附图说明
图1为本发明实施例的流程图。
具体实施方式
下面结合附图对本发明的实施例做进一步的说明。
请参阅图1,本发明提出的一种基于数据质量检测规则挖掘结果的进一步挖掘方法,通过以下步骤实现:
s1、挖掘数据质量检测规则。
本实施例中,r为关系模式,r的一实例为r,attr(r)为关系模式r的所有属性的集合,x为关系模式r的一属性子集,a为关系模式r的单个属性,tp为包含了x和a中属性的模式元组,挖掘到的数据质量检测规则的表达形式为cfd:(x→a,tp),且cfd(条件函数依赖,conditionalfunctionaldependency,cfd)必须满足以下两个条件:
最小性:指的是若(x→a,tp)成立,则对于x的任何一个子集y,都没有(y→a,tp)成立;
非平凡性:指的是若(x→a,tp)成立,则属性a不属于属性集x。
本实施例中,步骤s1的挖掘过程通过以下流程实现:
s11、扫描数据库,在关系模式r中通过将所有先行值(即x→a中的x)集合建模得到属性包含格,搜索时,先考虑所有由单个属性组成的节点,再逐次考虑多属性组成的节点,直到达到(n-1)级,其中,n为关系模式r中的属性个数。
s12、为本层各节点(x,tp)计算其c+(x,tp),其中,c+(x,tp)={(a,ca)};判断本层各个(x,tp)是否有相应的cfd:(x\{a}→a,tp[x\{a}]||tp[a])成立,若cfd成立,则修改本层中所有比节点(x,tp)更具体的(x,up)的c+(x,up),从c+(x,up)中除去节点(a,ca)及(b,cb),其中b属于关系模式r上去除了属性集x的属性集。
s13、检查本层各个(x,tp),若c+(x,tp)为空,则剪去(x,tp)。
s14、若两节点(x,sp)、(y,tp)的前缀相同,即x与y、sp与tp各自的前k-1个值对应相同,则为lk+1层生成新节点(z,up)=(xuy[k],sputp[k]),并令lk=lk+1,直至lk+1为空集。
在产生的cfd的基础上为了获得感兴趣,或者说达到了指定要求的数据质量检测规则,可以使用三种兴趣度度量指标来进行最终的检验,即支持度、卡方检验和置信度。支持度是一种频率度量,它基于的观点是经常共同出现的值有更多的证据来表明他们是相关的。卡方检验就是统计样本的实际观测值与理论推断值之间的偏离程度,实际观测值与理论推断值之间的偏离程度就决定卡方值的大小。置信度测量了在条件q下,给定p,发生a的可能性。
s2、根据挖掘结果,得到m字段和n字段的关联关系,将m字段和n字段的字段值进行聚类,对聚类结果中每一簇的特征进行转换,并标记各簇的特征。
本实施例中,步骤s2通过以下流程实现:
s21、根据步骤s1的挖掘结果,提取具有关联关系的m字段和n字段,对其中一个字段进行数据列剖析,得到该列字段值中存在的不同值的个数,以此作为聚类的簇数m。
s22、判断m字段和n字段中是否存在中文,若存在中文,则以数值编码的方式将中文转换为数值进行表示,将两字段的字段值按行取出存入集合中。
本实施例中,步骤s22通过以下流程实现:
s221、判断m字段和n字段中是否存在中文;
s222、若存在中文,则以数值编码的方式将中文转换为数值进行表示,将两字段的字段值按行取出存入集合中,流程进入s23;
s223、若不存在中文,则流程直接进入s23。
s23、进行聚类。
本实施例中,步骤s23通过以下流程实现:
s231创建初始划分,从数据集中随机选择m个对象,每个对象初始代表一个簇中心;
对于除簇中心m个对象以外的其它对象,计算其与每个簇中心的距离,将其划入到距离最近的簇;
采用欧几里得距离公式计算距离,计算公式为
采用迭代的方法,当有新的对象加入簇或已有对象离开簇的时候,重新计算簇中心的值,对对象进行重新分配。
s232、判断各簇中对象是否变化。
s233、若各簇中对象仍在变化,则迭代尚未结束,流程回到s231,继续迭代。
s234、若各簇中对象不再发生变化,则迭代结束,得到聚类结果,流程进入s24。
s24,对聚类结果中每一个簇的特征进行转换,将数值与对应的中文值进行映射,并标记各簇的特征。
本实施例中,对聚类结果中每一个簇所独有的特征进行自动转换,即自动将数值与对应的中文值进行映射,并标记各簇所具有的特征。比如,簇1中学生的成绩范围是85~100,所在寝室号的范围为301~318,簇2中学生的成绩范围为70~84,所在寝室号的范围为202~209,以此可以得出哪些寝室的学生成绩较好的这一信息,为数据管理者做出相应的决策提供了数据支撑。
本领域的普通技术人员将会意识到,这里的实施例是为了帮助读者理解本发明的原理,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。本领域的普通技术人员可以根据本发明公开的这些技术启示做出各种不脱离本发明实质的其它各种具体变形和组合,这些变形和组合仍然在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!