一种基于靶标模型的食品风险量化分级方法及系统与流程
本发明涉及食品监控领域,更具体地,涉及一种基于靶标模型的食品风险量化分级方法及系统。
背景技术:
食品安全问题与每个人的生命健康息息相关。然而,“三鹿”奶粉事件、瘦肉精、苏丹红等食品安全事故频频发生,严重损害了人们的身心健康,引发信任危机。因此食品安全问题的预防和治理愈发受到重视。借助大数据技术和适当的风险评估工具及方法,定量分析风险程度,有助于把控食品安全的整体状况,确定优先控制顺序,构建良好的食品安全环境。但是食品的检验检测项目非常多,而且不同种类食品的检验检测项存在一定差异,这会导致不同食品种类的特征不统一,若把所有的检验检测项作为模型特征,则特征维度过高;这使得现有的食品风险量化分级不全面且不可靠。
技术实现要素:
为了解决背景技术存在的现有的食品风险量化分级不全面且不可靠的问题,本发明提供了一种基于靶标模型的食品风险量化分级方法及系统,所述方法及系统通过对多样性的食品检测数据进行融合形成多个指标,通过靶标模型的建立对各指标进行评价,获得食品风险量化分级,所述一种基于靶标模型的食品风险量化分级方法包括:
获取食品的检测数据,根据检测数据所属的分类将所属检测数据划分至预设的多个指标内;所述检测数据包括检测项、检测标准、检测值以及检测结果;
计算每个指标的不合格率以及平均不合格度;所述不合格率为对应指标下不合格的检测数据所占的比例;所述平均不合格度为对应指标下每项检测数据不合格度的均值;
根据每个指标下的不合格率和不合格度,使用预设的靶标模型计算对应指标的风险等级;
输出各个指标的风险等级,并对所述各个指标的风险等级根据预设规则进行预警。
进一步的,所述预设的多个指标包括微生物指标、生物毒素指标、农药残留指标、兽药残留指标、污染物指标、食品添加剂指标、非法添加物指标以及其他指标。
进一步的,在获取食品的检测数据前,所述方法还包括:
根据需求确定待风险量化分级的食品信息,所述食品信息包括食品种类、检测时间以及抽样区域;
根据所述食品信息在数据库中获得所述食品的检测数据。
进一步的,根据预设清洗规则对所述食品的抽样检测数据进行数据清洗,获得统一数据格式的检测数据。
进一步的,所述方法基于hadoop架构,通过数据仓库工具hive实现抽样检测数据的获取。
进一步的,对于所述检测数据的检测值比最小允许限更小的情况,则该检测数据的不合格度的计算公式为:rate=1-v/min;
对于所述检测数据的检测值比最大允许限更大的情况,则该检测数据的不合格度的计算公式为:rate=1-max/v;
其中,v为检测值,min为最小允许限,max为最大允许限。
进一步的,所述预设的靶标模型以不合格率为横坐标x、以平均不合格度为纵坐标y;以
根据所述对应指标的不合格率以及平均不合格度在靶标模型中的坐标位置确定其对应的风险等级。
进一步的,所述根据预设规则进行预警,包括:
将风险等级超过预设阈值的指标进行预警;
对每个指标下的多个检测项根据其不合格度进行降序排序,将前n名的不合格度对应的检测项进行预警。
所述一种基于靶标模型的食品风险量化分级系统包括:
检测数据处理单元,所述检测数据处理单元用于获取食品的检测数据,根据检测数据所属的分类将所属检测数据划分至预设的多个指标内;所述检测数据包括检测项、检测标准、检测值以及检测结果;
数据计算单元,所述数据计算单元用于计算每个指标的不合格率以及平均不合格度;所述不合格率为对应指标下不合格的检测数据所占的比例;所述平均不合格度为对应指标下每项检测数据不合格度的均值;
风险等级计算单元,所述风险等级计算单元用于根据每个指标下的不合格率和不合格度,使用预设的靶标模型计算对应指标的风险等级;所述风险等级计算单元用于输出各个指标的风险等级;
预警单元,所述预警单元用于对所述各个指标的风险等级根据预设规则进行预警。
进一步的,所述检测数据处理单元预设的多个指标包括微生物指标、生物毒素指标、农药残留指标、兽药残留指标、污染物指标、食品添加剂指标、非法添加物指标以及其他指标。
进一步的,所述系统还包括检测数据抽样单元;
所述检测数据抽样单元用于根据需求确定待风险量化分级的食品信息,所述食品信息包括食品种类、检测时间以及抽样区域;
所述检测数据抽样单元用于根据所述食品信息在数据库中获得所述食品的检测数据。
进一步的,所述检测数据抽样单元用于根据预设清洗规则对所述食品的抽样检测数据进行数据清洗,获得统一数据格式的检测数据。
进一步的,所述系统基于hadoop架构,所述检测数据抽样单元通过数据仓库工具hive实现抽样检测数据的获取。
进一步的,所述数据计算单元用于计算检测数据的不合格度;对于所述检测数据的检测值比最小允许限更小的情况,则该检测数据的不合格度的计算公式为:rate=1-v/min;对于所述检测数据的检测值比最大允许限更大的情况,则该检测数据的不合格度的计算公式为:rate=1-max/v;
其中,v为检测值,min为最小允许限,max为最大允许限。
进一步的,所述风险等级计算单元预设的靶标模型以不合格率为横坐标x、以平均不合格度为纵坐标y;以
所述风险等级计算单元根据所述对应指标的平均不合格率以及不合格度在靶标模型中的的坐标位置确定其对应的风险等级。
进一步的,所述预警单元用于将风险等级超过预设阈值的指标进行预警;
所述预警单元对每个指标下的多个检测项根据其不合格度进行降序排序,将前n名的不合格度对应的检测项进行预警。
本发明的有益效果为:本发明的技术方案,给出了一种基于靶标模型的食品风险量化分级方法及系统,所述方法及系统从食品风险量化评定的需求出发,结合检验检测数据多样性和不同食品种类的检验检测项的差异性等特点,提出根据不同的国标对检验检测项进行分类的指标融合方法,将所有的检验检测项约减为微生物指标、生物毒素指标、农药残留指标、兽药残留指标、污染物指标、食品添加剂指标、非法添加物指标和其他指标这8大类指标,以达到降维目的和实现不同食品种类之间特征的统一性。通过计算每个指标下的不合格率和不合格度,利用靶标模型计算风险系数,以实现食品风险程度的定量刻画,直观反映食品的安全概况,可帮助食品安全领域人员提升认知和分析能力,提高食品安全监管的科学性和有效性,降低食品安全事故率。
附图说明
通过参考下面的附图,可以更为完整地理解本发明的示例性实施方式:
图1为本发明具体实施方式的一种基于靶标模型的食品风险量化分级方法的流程图;
图2为本发明具体实施方式的基于不合格率以及不合格度的靶标模型的示意图;
图3为本发明具体实施方式的一种基于靶标模型的食品风险量化分级系统的结构图。
具体实施方式
现在参考附图介绍本发明的示例性实施方式,然而,本发明可以用许多不同的形式来实施,并且不局限于此处描述的实施例,提供这些实施例是为了详尽地且完全地公开本发明,并且向所属技术领域的技术人员充分传达本发明的范围。对于表示在附图中的示例性实施方式中的术语并不是对本发明的限定。在附图中,相同的单元/元件使用相同的附图标记。
除非另有说明,此处使用的术语(包括科技术语)对所属技术领域的技术人员具有通常的理解含义。另外,可以理解的是,以通常使用的词典限定的术语,应当被理解为与其相关领域的语境具有一致的含义,而不应该被理解为理想化的或过于正式的意义。
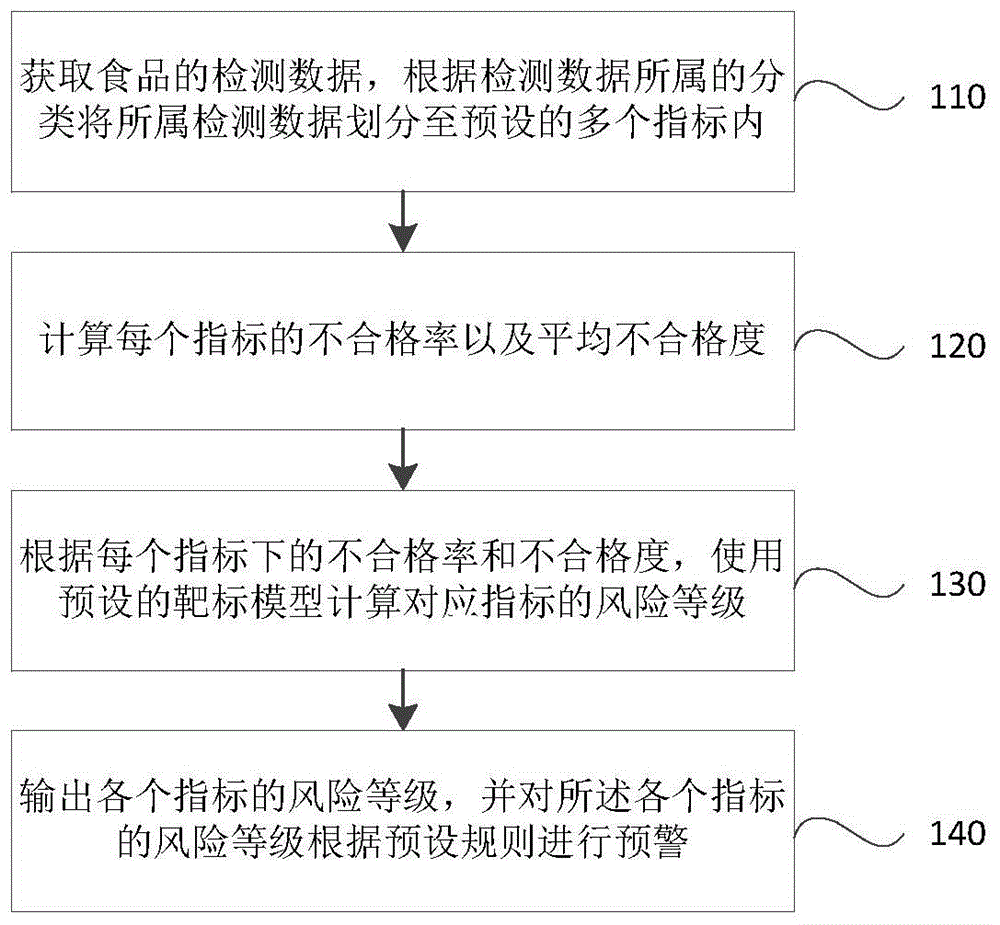
图1为本发明具体实施方式的一种基于靶标模型的食品风险量化分级方法的流程图;如图1所示,所述方法包括:
步骤110,获取食品的检测数据,根据检测数据所属的分类将所属检测数据划分至预设的多个指标内;所述检测数据包括检测项、检测标准、检测值以及检测结果;
进一步的,在获取食品的检测数据前,所述方法还包括获得检测数据的具体步骤:
根据需求确定待风险量化分级的食品信息,所述食品信息包括食品种类、检测时间以及抽样区域;
例如,需要进行风险量化的是某城市在某一段时间内的某一种食品种类;则根据这样的需求确定待风险量化分级的食品信息;抽样区域即为该城市、检测时间为所需时间;例如,需要风险量化的食品信息为北京市区在2018年12月全月的大豆;则在数据库中调取以“北京市区”为抽样区域、“2018年12月”为检测时间、食品种类为“大豆”。
根据所述食品信息在数据库中获得所述食品的检测数据。
本实施例中,所述方法基于hadoop架构,通过数据仓库工具hive实现抽样检测数据的获取。
进一步的,根据预设清洗规则对所述食品的检测数据进行数据清洗,获得统一数据格式的检测数据;所述数据清洗可以使用etl清洗工具,对数据进行抽取、转换和加载。
进一步的,所述预设的多个指标包括微生物指标、生物毒素指标、农药残留指标、兽药残留指标、污染物指标、食品添加剂指标、非法添加物指标以及其他指标。
本实施例中,根据检测数据所属的分类将所属检测数据划分至上述的8个指标内的评定依据,如下表所示:
步骤120,计算每个指标的不合格率以及平均不合格度;所述不合格率为对应指标下不合格的检测数据所占的比例;所述平均不合格度为对应指标下每项检测数据不合格度的均值;
所述不合格率即以该指标下所有的检测数据的数量作为分母,检测结果为不合格的检测数据为分子,进一步获得不合格检测数据所占比例,作为不合格率;
对于所述平均不合格度的计算,为对应指标下每项检测数据不合格度的均值;所述每个不合格度的计算是指其检测值与判断其是否合格的允许限的相关关系;因检测值存在望大和望小两种情况,故所述不合格度的计算方式包括:
对于所述检测数据的检测值比最小允许限更小的情况,则该检测数据的不合格度的计算公式为:rate=1-v/min;
对于所述检测数据的检测值比最大允许限更大的情况,则该检测数据的不合格度的计算公式为:rate=1-max/v;
其中,v为检测值,min为最小允许限,max为最大允许限;所述不合格度的值介于0-1之间。
步骤130,根据每个指标下的不合格率和不合格度,使用预设的靶标模型计算对应指标的风险等级;
进一步的,所述预设的靶标模型以不合格率为横坐标x、以平均不合格度为纵坐标y;以
如图2所示,所述多个预设的界线参数r分别为0.25、0.5、0.75以及1;通过所述多个界线参数将所述靶标模型的行程坐标的第一象限分割成了四个风险等级区间;通过将某一指标的不合格率和不合格度以坐标的形式带入,确认其落入具体哪一风险等级区间,即可确认其风险等级;在不参考图的情况下,也可根据
所述指标对应的坐标离原点越远,其风险系数越高,食品不安全的可能性就越大。
步骤140,输出各个指标的风险等级,并对所述各个指标的风险等级根据预设规则进行预警。
进一步的,所述根据预设规则进行预警,包括:
将风险等级超过预设阈值的指标进行预警;
对每个指标下的多个检测项根据其不合格度进行降序排序,将前n名的不合格度对应的检测项进行预警。
图3为本发明具体实施方式的一种基于靶标模型的食品风险量化分级系统的结构图。如图3所示,所述系统包括:
检测数据处理单元310,所述检测数据处理单元310用于获取食品的检测数据,根据检测数据所属的分类将所属检测数据划分至预设的多个指标内;所述检测数据包括检测项、检测标准、检测值以及检测结果;
进一步的,所述检测数据处理单元310预设的多个指标包括微生物指标、生物毒素指标、农药残留指标、兽药残留指标、污染物指标、食品添加剂指标、非法添加物指标以及其他指标。
数据计算单元320,所述数据计算单元320用于计算每个指标的不合格率以及平均不合格度;所述不合格率为对应指标下不合格的检测数据所占的比例;所述平均不合格度为对应指标下每项检测数据不合格度的均值;
进一步的,所述数据计算单元320用于计算检测数据的不合格度;对于所述检测数据的检测值比最小允许限更小的情况,则该检测数据的不合格度的计算公式为:rate=1-v/min;对于所述检测数据的检测值比最大允许限更大的情况,则该检测数据的不合格度的计算公式为:rate=1-max/v;
其中,v为检测值,min为最小允许限,max为最大允许限。
风险等级计算单元330,所述风险等级计算单元330用于根据每个指标下的不合格率和不合格度,使用预设的靶标模型计算对应指标的风险等级;所述风险等级计算单元330用于输出各个指标的风险等级;
进一步的,所述风险等级计算单元330预设的靶标模型以不合格率为横坐标x、以平均不合格度为纵坐标y;以
所述风险等级计算单元330根据所述对应指标的平均不合格率以及不合格度在靶标模型中的的坐标位置确定其对应的风险等级。
预警单元340,所述预警单元340用于对所述各个指标的风险等级根据预设规则进行预警。
进一步的,所述预警单元340用于将风险等级超过预设阈值的指标进行预警;
所述预警单元340对每个指标下的多个检测项根据其不合格度进行降序排序,将前n名的不合格度对应的检测项进行预警。
进一步的,所述系统还包括检测数据抽样单元;
所述检测数据抽样单元用于根据需求确定待风险量化分级的食品信息,所述食品信息包括食品种类、检测时间以及抽样区域;
所述检测数据抽样单元用于根据所述食品信息在数据库中获得所述食品的检测数据。
进一步的,所述检测数据抽样单元用于根据预设清洗规则对所述食品的抽样检测数据进行数据清洗,获得统一数据格式的检测数据。
进一步的,所述系统基于hadoop架构,所述检测数据抽样单元通过数据仓库工具hive实现抽样检测数据的获取。
在此处所提供的说明书中,说明了大量具体细节。然而,能够理解,本公开的实施例可以在没有这些具体细节的情况下实践。在一些实例中,并未详细示出公知的方法、结构和技术,以便不模糊对本说明书的理解。
本领域那些技术人员可以理解,可以对实施例中的设备中的模块进行自适应性地改变并且把它们设置在与该实施例不同的一个或多个设备中。可以把实施例中的模块或单元或组件组合成一个模块或单元或组件,以及此外可以把它们分成多个子模块或子单元或子组件。除了这样的特征和/或过程或者单元中的至少一些是相互排斥之外,可以采用任何组合对本说明书(包括伴随的权利要求、摘要和附图)中公开的所有特征以及如此公开的任何方法或者设备的所有过程或单元进行组合。除非另外明确陈述,本说明书(包括伴随的权利要求、摘要和附图)中公开的每个特征可以由提供相同、等同或相似目的的替代特征来代替。本说明书中涉及到的步骤编号仅用于区别各步骤,而并不用于限制各步骤之间的时间或逻辑的关系,除非文中有明确的限定,否则各个步骤之间的关系包括各种可能的情况。
此外,本领域的技术人员能够理解,尽管在此所述的一些实施例包括其它实施例中所包括的某些特征而不是其它特征,但是不同实施例的特征的组合意味着处于本公开的范围之内并且形成不同的实施例。例如,在权利要求书中所要求保护的实施例的任意之一都可以以任意的组合方式来使用。
本公开的各个部件实施例可以以硬件实现,或者以在一个或者多个处理器上运行的软件模块实现,或者以它们的组合实现。本公开还可以实现为用于执行这里所描述的方法的一部分或者全部的设备或者系统程序(例如,计算机程序和计算机程序产品)。这样的实现本公开的程序可以存储在计算机可读介质上,或者可以具有一个或者多个信号的形式。这样的信号可以从因特网网站上下载得到,或者在载体信号上提供,或者以任何其他形式提供。
应该注意的是上述实施例对本公开进行说明而不是对本公开进行限制,并且本领域技术人员在不脱离所附权利要求的范围的情况下可设计出替换实施例。单词“包含”不排除存在未列在权利要求中的元件或步骤。位于元件之前的单词“一”或“一个”不排除存在多个这样的元件。本公开可以借助于包括有若干不同元件的硬件以及借助于适当编程的计算机来实现。在列举了若干系统的单元权利要求中,这些系统中的若干个可以是通过同一个硬件项来具体体现。
以上所述仅是本公开的具体实施方式,应当指出的是,对于本领域的普通技术人员来说,在不脱离本公开精神的前提下,可以作出若干改进、修改、和变形,这些改进、修改、和变形都应视为落在本申请的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!