特征计算方法和装置、排序方法和设备、存储介质与流程
本发明涉及搜索领域,特别涉及一种特征计算方法和装置、排序方法和设备、存储介质。
背景技术:
搜索是电子商务领域的核心技术,大部分在电子商务网站买东西的人都会通过搜索功能来搜索自己想要的东西。所以哪些东西排在前面是一个关键的问题,相关技术搜索已经实现对返回的商品进行自动排序。排序流程大致如下:
(1)通过对搜索query(查询条件)进行分析并从所有商品中选出相关商品。
(2)通过相关算法、规则进行过滤,过滤掉大部分不相关的商品。
(3)通过基础排序算法对余下的商品进行排序。
(4)最后经过个性化等一系列算法对商品进行精炼排序。
基础排序算法是搜索排序的核心,保证了整个搜索排序结果的下线。
技术实现要素:
申请人发现:相关技术基础排序算法对商品排序时所选特征是在全站所有商品这一尺度下进行归一缩放计算的,这样便会出现时效性很差的问题,其中,所谓时效性指的是诸如销量的商品特征改变时,商品排名能否产生快速、准确的变化。如果全站所有商品这一尺度下进行归一缩放计算,则在诸如销量的商品特征改变时,商品排名不能产生快速、准确的变化,即时效性很差。
例如:西游记这本书一天卖了5本,一件t恤一天也卖了5件。如果在同一尺度下计算,那么它们的最终得分增加幅度差不多。然而服饰类目销量本来就远多于书籍类目,所以如果一本书一天卖出了5本,那么它的排名会显著的提升,然而服饰的排名则不会有明显变化;也就是说图书对销量过于敏感而服饰对于销量敏感度下降。因此,所有商品在同一尺度下计算会使得销量较小的类目下的商品变得太敏感,而使销量较大的类目下的商品变得不太敏感,导致时效性较差的结果。
鉴于以上技术问题,本发明提供了一种特征计算方法和装置、排序方法和设备、存储介质,对相似类目使用同一套特征计算方法,以解决类目差异性的问题,提高时效性。
根据本发明的一个方面,提供一种特征计算方法,包括:
对商品进行特征提取;
根据商品所在类目,确定所述商品类目对应的归一化模型;
根据所述归一化模型对商品特征进行缩放,形成商品特征向量,以便进行商品的精炼排序。
在本发明的一些实施例中,所述特征计算方法还包括:
预先形成商品类目与归一化模型的对应关系。
在本发明的一些实施例中,所述预先形成商品类目与归一化模型的对应关系包括:
将商品维度的特征数据聚类为类目维度特征;
对所述类目维度特征进行非线性缩放;
对非线性缩放后的类目维度特征进行层次聚类处理;
按层次聚类结果形成商品类目与归一化模型的对应关系。
在本发明的一些实施例中,所述将商品维度的特征数据聚类为类目维度特征包括:
采用类目下商品的百分位数作为特征来模拟类目的分布。
在本发明的一些实施例中,所述对所述类目维度特征进行非线性缩放包括:
将多维二级类目特征数据缩放为二维类目特征数据;
对二维类目特征数据进行开方处理。
在本发明的一些实施例中,所述预先形成商品类目与归一化模型的对应关系还包括:
将同一商品类别下所有二级类目进行统一的层次聚类处理;
将跨类目商品加入到最相关二级类目下进行统一的层次聚类处理。
在本发明的一些实施例中,所述归一化模型为将商品特征从原数值区间统一映射到一个固定取值范围内的模型。
根据本发明的另一方面,提供一种排序方法,包括:
根据人气分进行商品进行排序,并获取粗排结果;
根据商品标题属性对粗排结果进行过滤,获取需要进行精炼排序的商品;
对需要进行精炼排序的商品进行特征计算,形成商品特征向量;
根据商品特征向量按照预定基础排序算法对需要进行精炼排序的商品进行精炼排序。
在本发明的一些实施例中,所述对需要进行精炼排序的商品进行特征计算,形成商品特征向量包括:采用如上述任一实施例所述的特征计算方法对需要进行精炼排序的商品进行特征计算,形成商品特征向量。
根据本发明的另一方面,提供一种特征计算装置,包括:
特征提取模块,用于对商品进行特征提取;
模型确定模块,用于根据商品所在类目,确定所述商品类目对应的归一化模型;
特征缩放模块,用于根据所述归一化模型对商品特征进行缩放,形成商品特征向量,以便进行商品的精炼排序。
在本发明的一些实施例中,所述特征计算装置用于执行实现如上述任一实施例所述的特征计算方法的操作。
根据本发明的另一方面,提供一种特征计算装置,包括:
存储器,用于存储指令;
处理器,用于执行所述指令,使得所述特征计算装置执行实现如上述任一实施例所述的特征计算方法的操作。
根据本发明的另一方面,提供一种排序设备,包括:
粗排装置,用于根据人气分进行商品进行排序,并获取粗排结果;
过滤装置,用于根据商品标题属性对粗排结果进行过滤,获取需要进行精炼排序的商品;
特征计算装置,用于对需要进行精炼排序的商品进行特征计算,形成商品特征向量;
精炼排序装置,用于根据商品特征向量按照预定基础排序算法对需要进行精炼排序的商品进行精炼排序。
在本发明的一些实施例中,所述特征计算装置为如上述任一实施例所述的特征计算装置。
根据本发明的另一方面,提供一种计算机可读存储介质,其中,所述计算机可读存储介质存储有计算机指令,所述指令被处理器执行时实现如上述任一实施例所述的特征计算方法、或如上述任一实施例所述的排序方法。
本发明通过对相似类目使用同一套特征计算方法,解决了类目差异性的问题,提高时效性,同时本发明解决方法不复杂。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
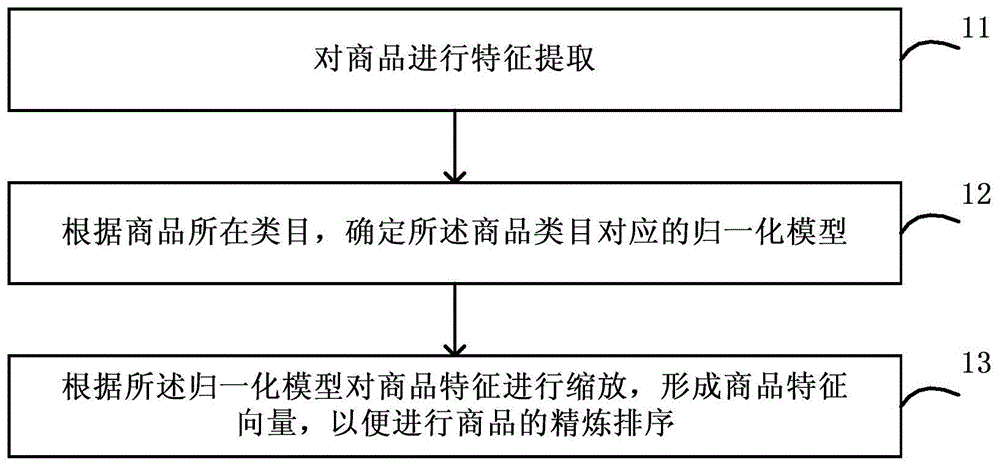
图1为本发明特征计算方法一些实施例的示意图。
图2为本发明特征计算方法另一些实施例的示意图。
图3为本发明一些实施例中预先对商品按类目进行聚类的示意图。
图4为本发明一些实施例中将多维二级类目特征数据缩放为二维类目特征数据后的散点示意图。
图5为本发明一些实施例中对二维类目特征数据进行开方处理后的示意图。
图6为本发明一些实施例中层次聚类处理后的效果示意图。
图7为本发明排序方法一些实施例的示意图。
图8为本发明特征计算装置一些实施例的示意图。
图9为本发明特征计算装置另一些实施例的示意图。
图10为本发明排序设备一些实施例的示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。以下对至少一个示例性实施例的描述实际上仅仅是说明性的,决不作为对本发明及其应用或使用的任何限制。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
除非另外具体说明,否则在这些实施例中阐述的部件和步骤的相对布置、数字表达式和数值不限制本发明的范围。
同时,应当明白,为了便于描述,附图中所示出的各个部分的尺寸并不是按照实际的比例关系绘制的。
对于相关领域普通技术人员已知的技术、方法和设备可能不作详细讨论,但在适当情况下,所述技术、方法和设备应当被视为授权说明书的一部分。
在这里示出和讨论的所有示例中,任何具体值应被解释为仅仅是示例性的,而不是作为限制。因此,示例性实施例的其它示例可以具有不同的值。
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步讨论。
图1为本发明特征计算方法一些实施例的示意图。优选的,本实施例可由本发明特征计算装置执行。该方法包括以下步骤:
步骤11,对需要进行精炼排序的商品进行特征提取。
步骤12,根据商品所在类目,确定所述商品类目对应的归一化模型。
在本发明的一些实施例中,所述归一化模型为将商品特征从原数值区间统一映射到一个固定取值范围内的模型。
在本发明的一些实施例中,所述归一化模型为bin模型,其中,bin模型是一种特征归一方法,不同于普通归一是把特征归一到0-1,而bin模型方法则是归一到预定的固定取值范围。
步骤13,根据所述归一化模型对商品特征进行缩放,形成商品特征向量,以便进行商品的精炼排序。
在本发明的一些实施例中,步骤13可以包括:根据所述归一化模型对商品部分特征(主要是一些数值较大的特征,比如几十万、几百万)进行缩放,形成商品特征向量。
因为商品特征的范围是不一样的,比如销量销售额这种可能一天有几十万、几千万,而商品价格则大部分不会超过几万,为了使不同特征可以放在同一尺度下计算,本发明上述实施例使用划bin的方法,即把所有特征统一映射到一个固定范围以内的数值。其中,划bin原理为:针对一维数据点采用聚类方法聚成n类,类的左右边界即为类所在区间的范围;然后根据各个类别在原区间的比例关系映射到新区间。
例如:假设销量的取值范围为0到1600,映射后的分数区间范围为0到10。那么本发明上述实施例可以把销量取值分成5份,分别为0-30、30-80、80-440、440-850、850-1600,相应的映射后的分数区间也可以分成5份,分别为0-0.1、0.1-0.3、0.3-1、1-4.8、4.8-10。如果商品a的销量为75,那么它便落到30-80这个区间内,对应的分数便落到0.1-0.3这个区间内,则商品a最后的分数便为(75-30)/(80-30)*(0.3-0.1)+0.1=0.28,即最后商品a的销量值为0.28。
申请人发现:由于不同类目下商品的数据存在差异性同时电商又有成百上千的二级类目,因此不能为每个二级类目都提供一个特征计算方法,这样过于繁琐复杂。
基于本发明上述实施例提供的特征计算方法,使用聚类算法,通过对相似类目使用同一套特征计算方法,解决了类目差异性的问题,本发明上述实施例在诸如销量的商品特征改变时,商品排名能够产生快速、准确的变化,由此大大提高了时效性。同时本发明上述实施例的解决方法不复杂。
图2为本发明特征计算方法另一些实施例的示意图。优选的,本实施例可由本发明特征计算装置执行。该方法包括以下步骤:
步骤10,预先对商品按类目进行聚类,形成商品类目与归一化模型的对应关系。
步骤11,对需要进行精炼排序的商品进行特征提取。
步骤12,根据商品所在类目,确定所述商品类目对应的归一化模型。
步骤13,根据所述归一化模型对商品特征进行缩放,形成商品特征向量,以便进行商品的精炼排序。
图3为本发明一些实施例中预先对商品按类目进行聚类的示意图。如图3所示,图2实施例的步骤10可以包括:
步骤101,将商品维度的特征数据聚类为类目维度特征。
在本发明的一些实施例中,步骤101可以包括:采用类目下商品的百分位数percentile作为特征来模拟类目的分布,其中,percentile为统计学术语,如果将一组数据从小到大排序,并计算相应的累计百分位,则某一百分位所对应数据的值就称为这一百分位的百分位数。
本发明上述实施例其他特征的聚类方法和聚类销量的使用方法一致,因此本发明上述实施例就以销量举例说明。
在本发明的一些实施例中,步骤101可以包括:
步骤1011,由于时效性主要体现在随着销量上升排名,因此这里选择销量等作为主要特征;以销量为例,同时考虑到商品短期和长期销量对商品排名的影响都很重要,本文采用短期、长期销量作为商品的特征,比如去4天销量和作为短期销量,7天销量作为长期销量。
步骤1012,本发明没有采用类目下商品销量和、或者商品销量的均值来刻画该类目的销量。因为同一类目下不同商品的销量差异还是比较大的,商品销量和、或者均值不能反映出类目之间的差异性。因此本发明上述实施例采用类目下商品销量的percentile作为类目的特征。
具体做法为:将二级类目下的商品按销量从小到大排序,区间为[0.05,0.95],每隔0.05便取一个值,这样便可取得19个值,以这19个特征来刻画销量分布,这样便可很好的刻画二级类目销量的分布。
本发明上述实施例采用类目下商品的percentile的多个值作为特征来模拟类目的分布,这样可以更好的表示类目信息。
步骤102,对所述类目维度特征进行非线性缩放。
在本发明的一些实施例中,步骤102可以包括:
步骤1021,将多维二级类目特征数据缩放为二维类目特征数据。
在本发明的一些实施例中,步骤1021可以包括:为了更好的观察数据效果,本发明上述实施例使用诸如tsne的降维方法将多维数据点缩放到二维。通过tsne将二级类目特征数据缩放到二维可得到如图4所示的散点图。图4为本发明一些实施例中将多维二级类目特征数据缩放为二维类目特征数据后的散点示意图。
tsne是一种降维方法,对每个数据点近邻的分布进行建模,其中近邻是指相互靠近数据点的集合。在原始高维空间中,我们将高维空间建模为高斯分布,而在二维输出空间中,我们可以将其建模为t分布。该过程的目标是找到将高维空间映射到二维空间的变换,并且最小化所有点在这两个分布之间的差距。与高斯分布相比t分布有较长的尾部,这有助于数据点在二维空间中更均匀地分布。
步骤1022,对二维类目特征数据进行开方(开根号)处理。
通过观察图4申请人发现:数据之间区分不是很明显,因此本发明上述实施例对原数据进行开根号处理,这样便可拉进销量比较大的类目的距离,同时又可以增大销量比较小的类目的距离。同时根号是单调递增函数并不会对原数据的分布造成巨大的影响。开根号后的数据如图5所示。图5为本发明一些实施例中对二维类目特征数据进行开方处理后的示意图。
本发明上述实施例对二级类目样本数据通过开根号处理,减小了销量过大商品之间的差距,这样使得样本之间距离变小同时又不影响样本特征值的大小关系,更便于聚类。
步骤103,对非线性缩放后的类目维度特征进行层次聚类处理。
通过观察图5申请人发现:图5所示数据并没有分成一团一团的,因此本发明决定使用层次聚类的方法进行类目聚类。
在本发明的一些实施例中,步骤103可以包括:层次聚类的合并算法通过计算两类数据点间的相似性,对所有数据点中最为相似的两个数据点进行组合,并反复迭代这一过程。本发明上述实施例中层次聚类的合并算法是通过计算每一个类别的数据点与所有数据点之间的距离来确定它们之间的相似性,距离越小,相似度越高;并将距离最近的两个数据点或类别进行组合,生成聚类树。最后效果如图6所示,
图6为本发明一些实施例中层次聚类处理后的效果示意图。如图6所示,横坐标表示样本的index(索引),如果有多个样本则表示样本数据,并用小括号括住;纵坐标表示两个子树间的距离。因此只需选定子树之间距离的阈值,便可将样本分成多类。
步骤104,按层次聚类结果形成商品类目与归一化模型的对应关系。
在本发明的一些实施例中,步骤104最后所有类目形成多个bin模型,针对每个query查询条件,可以通过其最相关的二级类目从bin模型池中选择相应的bin模型。
在本发明的一些实施例中,所述预先形成商品类目与归一化模型的对应关系还可以包括:将同一商品类别下所有二级类目进行统一的层次聚类处理;将跨类目商品加入到最相关二级类目下进行统一的层次聚类处理。
本发明上述实施例将同一类别的二级类目进行统一划bin(就是把该类别中的所有商品聚类,最后映射到新的特征空间),但是这里会涉及到商品跨类目的问题。
例如:在当前的搜索query查询条件为登山鞋的情况下,召回来的商品中除了有户外鞋服二级类目下的登山鞋,还有流行男鞋二级类目下的休闲鞋。即一个query查询条件下会召回两个不同二级类目的商品,但是一个query不能走两个bin逻辑,这里每个query都走其最相关的二级类目所划bin逻辑。
为了解决该问题,本发明上述实施例把每个query下的其他二级类目下的商品加入到数据中一同进行划bin。
本发明上述实施例为了解决跨类目问题,将跨类目商品加入到最相关二级类目下进行一同划bin。
本发明上述实施例对商品按类目进行聚类,从而可以解决某一商品在所有商品纬度下计算特征的弊端。
本发明上述实施例的聚类方法也可以实现为密度聚类等方法。
图7为本发明排序方法一些实施例的示意图。优选的,本实施例可由本发明排序设备执行。该方法包括以下步骤:
步骤71,根据人气分过滤获得粗排结果。
电子商务网站有几十亿的商品,经过正排倒排索引召回的商品数量均很多,这部分商品大部分都是无关的商品,因此必须通过一些规则、算法过滤掉这些无用的商品。本发明上述实施例通过对商品按人气分排序并进行截断,人气分是根据商品全站(全站包括搜索、广告、推荐等渠道)的特征算出的一个分数。本发明上述实施例经过粗排后大约只剩下几万个商品。
步骤72,由于剩余商品还是比较多,需进行再次过滤。根据商品标题属性等文本和query查询条件的之间相关性进行再次截断需要进行精炼排序的商品。
步骤73,对需要进行精炼排序的商品进行特征计算,形成商品特征向量。
在本发明的一些实施例中,步骤73可以包括:采用如上述任一实施例(例如图1-图6任一实施例)所述的特征计算方法,对需要进行精炼排序的商品进行特征计算,形成商品特征向量。
步骤74,按照预定基础排序算法进行精炼排序。
本发明上述实施例的预定基础排序是对商品进行一个综合排序,该排序使用包括商品文本相关、销量相关、广告相关等多个维度的特征来对商品进行线性拟合,从而得到一个分数,然后根据分数对商品进行排序。
步骤75,返回排序结果。
基于本发明上述实施例提供的排序方法,使用聚类算法,通过对相似类目使用同一套特征计算方法,解决了类目差异性的问题,本发明上述实施例在诸如销量的商品特征改变时,商品排名能够产生快速、准确的变化,由此大大提高了时效性。同时本发明上述实施例的解决方法不复杂。
本发明上述实施例对商品按类目进行聚类,从而可以解决某一商品在所有商品纬度下计算特征的弊端。
本发明上述实施例采用类目下商品的percentile的多个值作为特征来模拟类目的分布,这样可以更好的表示类目信息。
本发明上述实施例对二级类目样本数据通过开根号处理,减小了销量过大商品之间的差距,这样使得样本之间距离变小同时又不影响样本特征值的大小关系,更便于聚类。
本发明上述实施例为了解决跨类目问题,将跨类目商品加入到最相关二级类目下进行一同划bin。
图8为本发明特征计算装置一些实施例的示意图。如图8所示,所述特征计算装置可以包括特征提取模块81、模型确定模块82和特征缩放模块83,其中:
特征提取模块81,用于对需要进行精炼排序的商品进行特征提取。
模型确定模块82,用于根据商品所在类目,确定所述商品类目对应的归一化模型。
在本发明的一些实施例中,所述归一化模型为将商品特征从原数值区间统一映射到一个固定取值范围内的模型。
在本发明的一些实施例中,所述归一化模型为bin模型,其中,bin模型是一种特征归一方法,不同于普通归一是把特征归一到0-1,而bin模型方法则是归一到预定的固定取值范围。
特征缩放模块83,用于根据所述归一化模型对商品特征进行缩放,形成商品特征向量,以便进行商品的精炼排序。
在本发明的一些实施例中,特征缩放模块83可以用于根据所述归一化模型对商品部分特征(主要是一些数值较大的特征,比如几十万、几百万)进行缩放,形成商品特征向量。
在本发明的一些实施例中,所述特征计算装置用于执行实现如上述任一实施例(例如图1-图6任一实施例)所述的特征计算方法的操作。
在本发明的一些实施例中,如图8所示,所述特征计算装置还可以包括对应关系建立模块84,其中:
对应关系建立模块84,用于预先形成商品类目与归一化模型的对应关系。
在本发明的一些实施例中,对应关系建立模块可以包括
对应关系建立模块84可以用于将商品维度的特征数据聚类为类目维度特征;对所述类目维度特征进行非线性缩放;对非线性缩放后的类目维度特征进行层次聚类处理;按层次聚类结果形成商品类目与归一化模型的对应关系。
在本发明的一些实施例中,对应关系建立模块84在将商品维度的特征数据聚类为类目维度特征的情况下,具体可以用于采用类目下商品的百分位数percentile作为特征来模拟类目的分布,其中,percentile为统计学术语,如果将一组数据从小到大排序,并计算相应的累计百分位,则某一百分位所对应数据的值就称为这一百分位的百分位数。
在本发明的一些实施例中,对应关系建立模块84在对所述类目维度特征进行非线性缩放的情况下,具体可以用于使用诸如tsne的降维方法将多维二级类目特征数据缩放为二维类目特征数据,得到如图4所示的结果;对二维类目特征数据进行开方处理,得到如图5所示的结果。
在本发明的一些实施例中,对应关系建立模块84还可以用于将同一商品类别下所有二级类目进行统一的层次聚类处理;将跨类目商品加入到最相关二级类目下进行统一的层次聚类处理。
基于本发明上述实施例提供的特征计算装置,使用聚类算法,通过对相似类目使用同一套特征计算方法,解决了类目差异性的问题,本发明上述实施例在诸如销量的商品特征改变时,商品排名能够产生快速、准确的变化,由此大大提高了时效性。同时本发明上述实施例的解决方法不复杂。
本发明上述实施例对商品按类目进行聚类,从而可以解决某一商品在所有商品纬度下计算特征的弊端。
图9为本发明特征计算装置另一些实施例的示意图。如图9所示,所述特征计算装置可以包括存储器91和处理器92,其中:
存储器91,用于存储指令。
处理器92,用于执行所述指令,使得所述特征计算装置执行实现如上述任一实施例(例如图1-图6任一实施例)所述的特征计算方法的操作。
本发明上述实施例采用类目下商品的percentile的多个值作为特征来模拟类目的分布,这样可以更好的表示类目信息。
本发明上述实施例对二级类目样本数据通过开根号处理,减小了销量过大商品之间的差距,这样使得样本之间距离变小同时又不影响样本特征值的大小关系,更便于聚类。
本发明上述实施例为了解决跨类目问题,将跨类目商品加入到最相关二级类目下进行一同划bin。
图10为本发明排序设备一些实施例的示意图。如图10所示,所述排序设备可以包括粗排装置101、过滤装置102、特征计算装置103和精炼排序装置104,其中:
粗排装置101,用于根据人气分进行商品进行排序,并获取粗排结果。
在本发明的一些实施例中,粗排装置101可以用于通过对商品按人气分排序并进行截断,其中,人气分是根据商品全站(全站包括搜索、广告、推荐等渠道)的特征算出的一个分数。
过滤装置102,用于根据商品标题属性对粗排结果进行过滤,获取需要进行精炼排序的商品。
在本发明的一些实施例中,过滤装置102可以用于根据商品标题属性等文本和query查询条件的之间相关性进行再次截断需要进行精炼排序的商品。
特征计算装置103,用于对需要进行精炼排序的商品进行特征计算,形成商品特征向量。
在本发明的一些实施例中,所述特征计算装置103可以实现为如上述任一实施例(例如图8或图9实施例)所述的特征计算装置。
精炼排序装置104,用于根据商品特征向量按照预定基础排序算法对需要进行精炼排序的商品进行精炼排序。
在本发明的一些实施例中,所述预定基础排序算法是对商品进行一个综合排序,该排序使用包括商品文本相关、销量相关、广告相关等多个维度的特征来对商品进行线性拟合,从而得到一个分数,然后根据分数对商品进行排序。
基于本发明上述实施例提供的排序设备,使用聚类算法,通过对相似类目使用同一套特征计算方法,解决了类目差异性的问题,本发明上述实施例在诸如销量的商品特征改变时,商品排名能够产生快速、准确的变化,由此大大提高了时效性。同时本发明上述实施例的解决方法不复杂。
本发明上述实施例对商品按类目进行聚类,从而可以解决某一商品在所有商品纬度下计算特征的弊端。
根据本发明的另一方面,提供一种计算机可读存储介质,其中,所述计算机可读存储介质存储有计算机指令,所述指令被处理器执行时实现如上述任一实施例所述的特征计算方法、或如上述任一实施例所述的排序方法。
基于本发明上述实施例提供的计算机可读存储介质,使用聚类算法,通过对相似类目使用同一套特征计算方法,解决了类目差异性的问题,本发明上述实施例在诸如销量的商品特征改变时,商品排名能够产生快速、准确的变化,由此大大提高了时效性。
本发明上述实施例对商品按类目进行聚类,从而可以解决某一商品在所有商品纬度下计算特征的弊端。
在上面所描述的特征计算装置和排序设备可以实现为用于执行本申请所描述功能的通用处理器、可编程逻辑控制器(plc)、数字信号处理器(dsp)、专用集成电路(asic)、现场可编程门阵列(fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件或者其任意适当组合。
至此,已经详细描述了本发明。为了避免遮蔽本发明的构思,没有描述本领域所公知的一些细节。本领域技术人员根据上面的描述,完全可以明白如何实施这里公开的技术方案。
本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
本发明的描述是为了示例和描述起见而给出的,而并不是无遗漏的或者将本发明限于所公开的形式。很多修改和变化对于本领域的普通技术人员而言是显然的。选择和描述实施例是为了更好说明本发明的原理和实际应用,并且使本领域的普通技术人员能够理解本发明从而设计适于特定用途的带有各种修改的各种实施例。
- 还没有人留言评论。精彩留言会获得点赞!