一种基于微博文本的自杀风险识别方法与流程
本发明涉及网络技术领域,具体涉及一种基于微博文本的自杀风险识别方法。
背景技术:
目前对于临床和社区范围内的个体自杀风险评估主要采用心理量表的方法进行评估。我国现阶段比较常用的自杀风险评估量表主要来源于国外原版量表的翻译和本土化修订。李献云等修订了贝克自杀意念量表的简体中文版并测试了其在我国社区内成年人群中的信效度,发现量表对于评估个体最消沉、最忧郁和自杀倾向严重时期的效果最好。此外,梁瑛楠等翻译并修订了简体中文版的自杀可能性量表,并验证其在我国大学生群体中具有很好的信效度。
自杀风险评估工具主要包括成人自杀意念问卷、自杀概率量表(sps)和抑郁焦虑应激量表-21(dass-21),基于心理量表的自杀风险评估方法虽然针对个体比较深入,但是由于实施过程中的时效问题,与实际的干预工作之间往往存在时间差,在大批量运用于社区的时候,耗费大量的人力成本和时间成本,更难以对大量的个体进行长时间的追踪。在中国有很多具有自杀风险的个体并不主动寻求帮助,从而现有依赖自我报告的评估和筛查方法无法找到一些隐藏的具有自杀风险者。
技术实现要素:
本发明的目是解决当前自杀风险评估工作的时效低、成本高及被动性问题,提出一种基于微博文本的自杀风险识别方法,采用该技术方案有助于提升了自杀风险评估工作的覆盖面和速度,并且提高了微博自杀风险的识别精度。
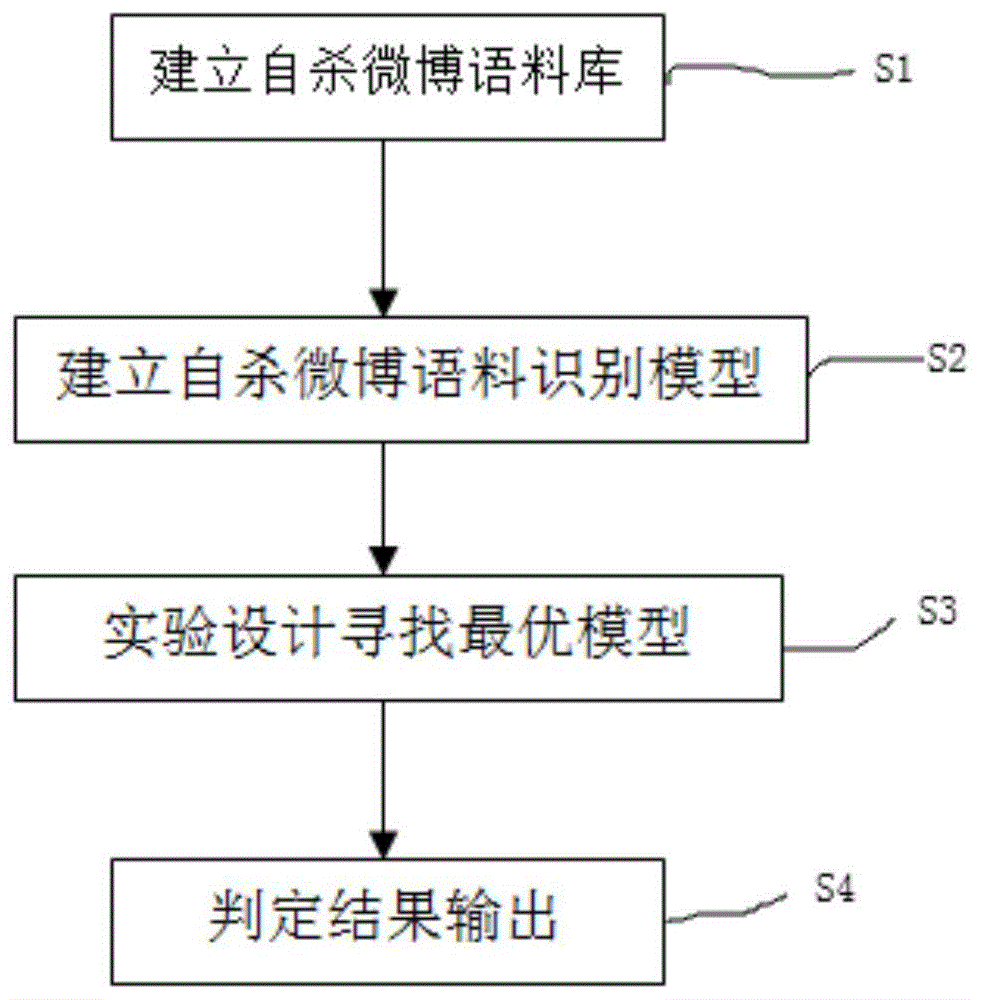
为实现上述技术目的,本发明提供的一种技术方案是,一种基于微博文本的自杀风险识别方法,包括以下几个步骤:
步骤s1:建立自杀微博语料库;
步骤s2:建立自杀微博语料识别模型;
步骤s3:实验设计寻找最优模型;
步骤s4:判定结果输出。
所述步骤s1中,自杀微博语料库的建立遵循以下两个步骤:
步骤s11:语料采集;所述语料采集是基于python语言使用cookie信息,模拟浏览器访问的新浪微博自杀文本信息自动爬取方案,获取网站数据;所述自动爬取步骤包括使用requesst来模拟登陆、url构造、网页下载、网页解析以及网页内容导出;
步骤s12:语料预处理;所述语料预处理的步骤包括对语料采集的网页内容的无效数据进行过滤、繁体字的转换、文本分词、停用词去除以及文本数字化。
本方案中,针对当前微博自杀语料库缺失问题,提出了一种基于python语言,使用cookie信息,模拟浏览器访问的新浪微博自杀文本信息自动爬取方案,使用该方案搭建的微博语料采集系统能够稳定的爬取新浪微博文本数据。其主要特点如下:
(1)可自主读取收集好的采集对象的微博id和所需爬取页数,符合本研究的需求;
(2)使用单线程低频率的爬取方式可有效避免反爬虫机制的检测;
(3)采用爬取微博移动端网页的策略,由于该网页结构简单,所以可最大限度提升爬取效率;
系统开发完成之后就将正式进入到微博语料的采集工作,最终,使用系统一共收集7817条微博语料,其中网络识别自杀死亡用户群体的语料共3827条,将它们定义为有自杀风险语料,网络识别未自杀死亡用户群体的语料共3990条,将它们定义为无自杀风险语料;随后通过一系列语料预处理操作,最终建立了自杀研究微博语料库。
所述步骤s2中,自杀微博语料识别模型分为四个层次,分别为词嵌入层、多路并行cnn层、bi-lstm层和全连接层,所述多路并行cnn层包括有卷积层和池化层。本方案中,本发明针对微博自杀文本特征较为稀疏的问题,并根据cnn和bi-lstm的特点,考虑将单行的cnn变为多个并行的cnn,且其中的卷积层使用多个不同尺寸的卷积核,这样可以分别提取文本数据中不同宽度视野下的局部特征,使获得的特征向量更全面,模型效果也会更好;同时为了进一步挖掘微博文本的深层上下文语义特征,考虑通过模型组合的方式将上述的多并行cnn和bi-lstm结合起来,这样既可以提取文本数据的各局部特征,又可提取出文本的上下文语义关联信息。
所述的词嵌入层将语料预处理的微博数字化文本序列中的每一个字词映射为一个具有固定长度且较短的连续实向量,每个词向量在该空间内的距离表示它们之间的相似度。本方案中,词嵌入层的作用就是将原先字词所在空间嵌入到一个新的向量空间中去,每个词向量在该空间内的距离表示它们之间的相似度,这样就保留了文本的语义特征。
所述的多路并行cnn层通过多个卷积核尺寸不一的cnn并行组成,每个cnn通路由一个卷积层和一个池化层叠加组成;所述卷积层从词嵌入层的输出序列中提取出序列的特征向量;所述池化层通过对数据进行降维,输出局部最优特征,减少模型复杂度。
所述bi-lstm层的输入为多路并行cnn的输出特征向量x,bi-lstm层通过组合两个方向相反的lstm即可实现bi-lstm层,所述两个方向相反的lstm分别记做前向lstm和后向lstm;
所述前向lstm的输出q表示如下:
q=[q1,q2,q3,…qn],qt∈q,t=1,2,3,…,n;
后向lstm的输出h表示如下:
h=[h1,h2,h3,…hn],ht∈h,t=1,2,3,…,n;
bi-lstm的输出y表示如下:
其中符号
所述全连接层用于生成更高阶的特征表示,使之更容易分离成我们想要区分的不同类;所述全连接层的输入为bi-lstm的输出向量y=[y1,y2,y3,…yn],采用反向传播算法对网络模型中的参数进行梯度更新。
所述步骤s3中,为了寻找最优自杀微博语料识别模型,设计nc-bilstm模型,分别做了1到a路并行cnn的模型训练,即并行路数n分别取值{1,2,3,…,a},其中a为整数;试验采取了精准率、召回率和f测量值作为评价标准,
所述精准率计算公式如下:
pr=tp/(tp+fp);
所述召回率计算公式如下:
re=tp/(tp+fn);
所述f测量值计算公式如下:
f=2*(pr*re)/(pr+re);
其中tp表示无自杀风险文本预测为无自杀风险文本的数目,tn表示有自杀风险文本预测为有自杀风险文本的数目,fn表示无自杀风险样本预测为有自杀风险样本的数目,fp表示有自杀风险文本预测为无自杀风险文本的数目。
本方案中,提出一种基于多并行cnn、bi-lstm的微博文本自杀风险识别模型nc-bilstm(其中n表示cnn并行路数)。该模型主要由两部分组成,选择多路并行的cnn作为文本局部特征信息的提取器,将时间序列模型bi-lstm作为上下文序列特征的提取器,将前者的输出特征向量拼接融合后输入后者,最后特征全部提取完毕进行分类。
最佳自杀微博语料识别模型确定后,使用sigmoid分类器输出自杀风险判定的结果,输出表示如公式:
p(result|y,wx,bx)=sigmoidx(wx*y+bx)
其中,sigmoidx代表分类器,wx和bx为sigmoid分类器的参数,下标x代表迭代处于第x轮,result表示自杀风险识别的结果,result∈{有自杀风险,无自杀风险}。
本发明的有益效果:1、通过对社交媒体用户的文本分析进行自杀风险评估可以有效解决其它方法的局限性问题,因为该方法可以迅速并且主动识别出具有自杀风险的用户,能够在个体的自杀意念形成的早期阶段,及时发现并加以有效干预,这极大地提升了自杀风险评估工作的覆盖面和速度;2、通过搭建微博语料采集系统实现了对特定用户微博文本数据的自动抓取功能,随后再通过一系列语料预处理操作,最终建立了自杀研究微博语料库,弥补了以往研究中普遍存在的自杀文本数据的缺乏问题;3、解决了当前神经网络单一结构在预测精度提升上的瓶颈问题,提出了一种混合架构的神经网络模型nc-bilstm,并将其应用于微博文本自杀风险识别,nc-bilstm模型的识别精准率、召回率、f值均优于其他模型,可应用到自杀干预的早期预防中,具有良好的社会效益和经济效益。
附图说明
图1为本发明的一种基于微博文本的自杀风险识别方法的实现流程图。
图2为本发明的一种基于微博文本的自杀风险识别方法的nc-bilstm模型架构图。
具体实施方式
为使本发明的目的、技术方案以及优点更加清楚明白,下面结合附图和实施例对本发明作进一步详细说明,应当理解的是,此处所描述的具体实施方式仅是本发明的一种最佳实施例,仅用以解释本发明,并不限定本发明的保护范围,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例:如图1所示,一种基于微博文本的自杀风险识别方法,包括以下几个步骤:步骤s1:建立自杀微博语料库;
步骤s2:建立自杀微博语料识别模型;
步骤s3:实验设计寻找最优模型;
步骤s4:判定结果输出。
本实施例中,通过搭建微博语料采集系统实现了对特定用户微博文本数据的自动抓取功能。随后再通过一系列语料预处理操作,最终建立了自杀研究微博语料库,搭建一种混合架构的神经网络模型nc-bilstm,利用多路不同卷积核的卷积层提取局部特征信息,同时使用双向长短期记忆网络层提取句子的上下文语义特征信息,可应用到自杀干预的早期预防中,具有良好的社会效益和经济效益。
所述步骤s1中,自杀微博语料库的建立遵循以下两个步骤:
步骤s11:语料采集;所述语料采集是基于python语言使用cookie信息,模拟浏览器访问的新浪微博自杀文本信息自动爬取方案,获取网站数据;所述自动爬取步骤包括使用requesst来模拟登陆、url构造、网页下载、网页解析以及网页内容导出;
步骤s12:语料预处理;所述语料预处理的步骤包括对语料采集的网页内容的无效数据进行过滤、繁体字的转换、文本分词、停用词去除以及文本数字化。
本实施例中,针对当前微博自杀语料库缺失问题,提出了一种基于python语言,使用cookie信息,模拟浏览器访问的新浪微博自杀文本信息自动爬取方案,使用该方案搭建的微博语料采集系统能够稳定的爬取新浪微博文本数据。其主要特点如下:
(1)可自主读取收集好的采集对象的微博id和所需爬取页数,符合本研究的需求;
(2)使用单线程低频率的爬取方式可有效避免反爬虫机制的检测;
(3)采用爬取微博移动端网页的策略,由于该网页结构简单,所以可最大限度提升爬取效率;
系统开发完成之后就将正式进入到微博语料的采集工作,最终,使用系统一共收集7817条微博语料,其中网络识别自杀死亡用户群体的语料共3827条,将它们定义为有自杀风险语料,网络识别未自杀死亡用户群体的语料共3990条,将它们定义为无自杀风险语料;随后通过一系列语料预处理操作,最终建立了自杀研究微博语料库。
如图2所示,所述步骤s2中,自杀微博语料识别模型分为四个层次,分别为词嵌入层、多路并行cnn层、bi-lstm层和全连接层,所述多路并行cnn层包括有卷积层和池化层。本实施例中,针对微博自杀文本特征较为稀疏的问题,并根据cnn和bi-lstm的特点,考虑将单行的cnn变为多个并行的cnn,且其中的卷积层使用多个不同尺寸的卷积核,这样可以分别提取文本数据中不同宽度视野下的局部特征,使获得的特征向量更全面,模型效果也会更好;同时为了进一步挖掘微博文本的深层上下文语义特征,考虑通过模型组合的方式将上述的多并行cnn和bi-lstm结合起来,这样既可以提取文本数据的各局部特征,又可提取出文本的上下文语义关联信息。
所述的词嵌入层将语料预处理的微博数字化文本序列中的每一个字词映射为一个具有固定长度且较短的连续实向量,每个词向量在该空间内的距离表示它们之间的相似度,所述的距离采用余弦距离公式计算得出,这样就保留了文本的语义特征。
首先输入得到的数字序列形式的微博文本语料,设模型的输入序列为xi=[i1,i2,i3,…,i70],ik∈n,且0≤ik≤|d|,d为语料库中所有不同词构成的词典,|d|表示词典中词的数目。在词嵌入层中存在一个权重矩阵t,它随机初始化后再通过训练不断更新,通过t能够将每个数字化的字词转换为其所对应的词向量:t[ik]=ek,其中ek代表得到的词向量;则词嵌入层的输出为e=[e1,e2,e3,…,e70],ek=t(ik)。
所述的多路并行cnn层通过多个卷积核尺寸不一的cnn并行组成,每个cnn通路由一个卷积层和一个池化层叠加组成;本层由多个卷积核尺寸不一的cnn并行组成,每个cnn通路由一个卷积层和一个池化层叠加组成,经过词嵌入层后,文本数据被表示成序列化的数据形式,所以此处均采用一维卷积的方式。
卷积层的作用是从词嵌入层的输出e中提取出序列的特征向量;卷积操作涉及一个过滤器wc∈rd×h,d表示字符向量的维度大小,h表示过滤器移动的窗口大小;一个过滤器卷积生成特征向量可通过公式计算:
c=f(conv(e*wc)+b)
其中,f表示非线性的激活函数,conv表示卷积过程,b表示的是偏置向量,c表示生成的特征向量,特别说明的是,在这里设置了多个并行的卷积层,并且每个卷积层的卷积核尺寸不同,通过设置不同的h来实现;然后需要将每一组特征向量输入池化层进行操作,池化层又叫采样层,其用以对数据进行降维,输出局部最优特征,减少模型复杂度;通常的做法是在卷积层提取出的局部特征上,在一个固定大小的区域上通过某种方法采样一个点,作为下一层网络的输入;这里使用的采样方法是最大池化,因为最大池化能够提取出最有效的特征信息,还能减少下一层的计算量。进行最大池化操作后生成的序列的特征向量见公式:xchar=[max{c1},max{c2},…,max{cx}]
这里最后还需要将多个通路的输出特征向量做拼接处理,如公式所示:
其中xnchar表示第n条cnn通路的输出特征向量,符号
所述bi-lstm层的输入为多路并行cnn的输出特征向量x,bi-lstm层通过组合两个方向相反的lstm即可实现bi-lstm层,所述两个方向相反的lstm分别记做前向lstm和后向lstm;
所述前向lstm的输出q表示如下:
q=[q1,q2,q3,…qn],qt∈q,t=1,2,3,…,n;
后向lstm的输出h表示如下:
h=[h1,h2,h3,…hn],ht∈h,t=1,2,3,…,n;
bi-lstm的输出y表示如下:
其中符号
所述全连接层用于生成更高阶的特征表示,使之更容易分离成我们想要区分的不同类;所述全连接层的输入为bi-lstm的输出向量y=[y1,y2,y3,…yn],采用反向传播算法对网络模型中的参数进行梯度更新。
所述步骤s3中,为了寻找最优自杀微博语料识别模型,设计nc-bilstm模型,分别做了1到5路并行cnn的模型训练,即并行路数n分别取值{1,2,3,…,5};试验采取了精准率、召回率和f测量值作为评价标准,
所述精准率计算公式如下:
pr=tp/(tp+fp);
所述召回率计算公式如下:
re=tp/(tp+fn);
所述f测量值计算公式如下:
f=2*(pr*re)/(pr+re);
其中tp表示无自杀风险文本预测为无自杀风险文本的数目,tn表示有自杀风险文本预测为有自杀风险文本的数目,fn表示无自杀风险样本预测为有自杀风险样本的数目,fp表示有自杀风险文本预测为无自杀风险文本的数目。表1所示是nc-bilstm模型各因素评价表:表1.nc-bilstm模型各因素评价表
从表中可得出3c-bilstm模型的精准率、召回率和f值均为最高,即当并行路数为3时模型效果最佳。
最佳自杀微博语料识别模型确定后,本文数据类别分为无自杀风险语料和有自杀风险语料两类,且特征差异较明显,使用sigmoid分类器输出自杀风险判定的结果,它可以将任意一个实数映射到[0,1]区间范围内,适合用来做二分类,而且其在特征差异比较大时效果比较好,输出表示如公式:
p(result|y,wx,bx)=sigmoidx(wx*y+bx)
其中,sigmoidx代表分类器,wx和bx为sigmoid分类器的参数,下标x代表迭代处于第x轮,result表示自杀风险识别的结果,result∈{有自杀风险,无自杀风险}。
以上所述之具体实施方式为本发明一种基于微博文本的自杀风险识别方法的较佳实施方式,并非以此限定本发明的具体实施范围,本发明的范围包括并不限于本具体实施方式,凡依照本发明之形状、结构所作的等效变化均在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!