一种基于BERT与LSTM、CNN融合的中文情感分析方法与流程
本发明涉及信息处理技术,尤其涉及一种基于bert与lstm、cnn融合的中文情感分析方法。
背景技术:
近年来,随着网络技术的快速发展,许多消费者开始在网络上发表自己对某一事物的看法和评论,自然语言处理技术应运而生,情感分析一类的任务比如商品评价正负面分析,敏感内容分析,用户感兴趣内容分析、甚至安全领域的异常访问日志分析等等实际上都可以用文本分类的方式去做,本质上来讲就是一个文本输出一个多个对应的标签。因此如何快速并准确的从海量信息中分析用户看法及情感成为当前信息技术领域的一个重要研究课题,在现实生活中具有很重要的理论意义和实际应用价值。
对于企业产品来说,通过将用户的评论数据进行分析,同时将其中的情感信息提取出来,可以最大化的了解到用户们对于产品的满意程度,对于产品的改进以及产品价值的提升具有很好的参考价值。同样的,在评定电影的好坏程度、某酒店服务情况,美团中商家的口碑,情感分析技术也具有十分重要的现实意义。
不管是文本分类、命名体识别、语义分析还是情感分析,都需要进行文本的预处理。传统的文本预处理过程一般包含文本预训练、分词,生成向量词典、生成词索引等过程,过程繁琐,模型实现功能少,这样会导致文本分析准确率下降以及花费时间更长。而且一般将预训练语言表示应用于下游任务有两种策略:基于特征和微调。基于特征的方法,如elmo,主要是以特定于任务的体系结构为主;基于微调的方法,如openaigpt,引入特定的任务参数,然后通过简单的微调预训练参数来训练文本特征。两者均是使用单向的语言模型来完成任务。
目前情感分析的粒度较大,一般指对整个句子或是文本进行分析判断,这样容易忽视文本和句子中更细粒度的信息,丢失很多有价值的信息,不能准确的判断文本含义。传统的对文本进行标记一般是人工,这样耗费大量的时间和人力资源,这样的方法影响后续的训练效果,大大降低情感分类的准确性。而且相较于之前提出的特征融合方法,分类结果均没有本发明中在加入bert模型后准确率高。
技术实现要素:
在下文中给出了关于本发明的简要概述,以便提供关于本发明的某些方面的基本理解。应当理解,这个概述并不是关于本发明的穷举性概述。它并不意图确定本发明的关键或重要部分,也不意图限定本发明的范围。其目的仅仅是以简化的形式给出某些概念,以此作为稍后论述的更详细描述的前序。
鉴于此,本发明提供了基,以至少解决现有技术中存在的问题。
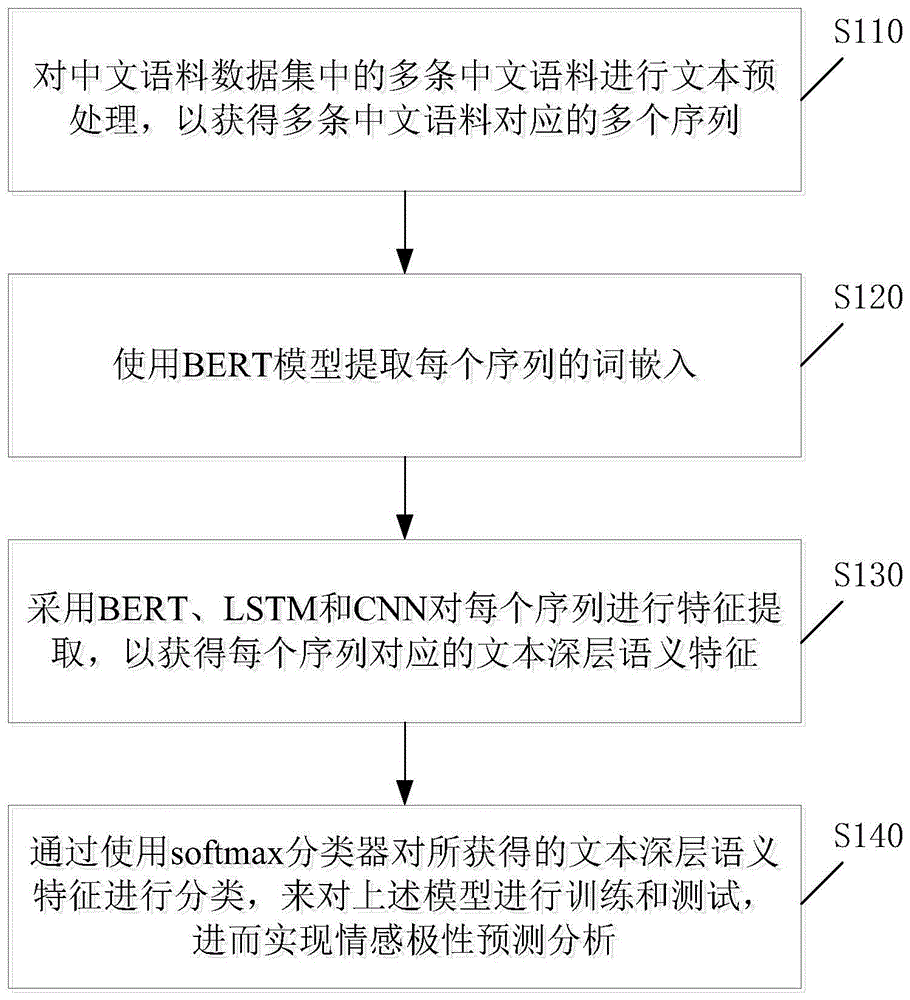
本发明的一方面提供了一种基于bert与lstm、cnn融合的中文情感分析方法,包括:对中文语料数据集中的多条中文语料进行文本预处理,以获得所述多条中文语料对应的多个序列;使用bert模型提取每个序列的词嵌入;采用bert、lstm和cnn对每个序列进行特征提取,以获得每个序列对应的文本深层语义特征;通过使用softmax分类器对所获得的文本深层语义特征进行分类,来对模型进行训练和测试,进而实现情感极性预测分析。
进一步地,所述对中文语料数据集中的多条中文语料进行文本预处理的步骤包括:针对所述中文语料数据集中的每条中文语料,将该条中文语料中的文本字符化,其中,在获得的该条中文语料对应的序列中,用cls作为该序列的第一个标记,通过sep对该序列进行分割。
进一步地,在所述对中文语料数据集中的多条中文语料进行文本预处理的步骤中,通过所述文本字符化使得文本中的句子切分为多个字。
进一步地,其中每个序列为词向量序列,每个序列的第一个标记均为特殊分类符cls标记,句子之间的分割用sep进行标记,句子中替换的词汇用mask标记,其中,真实文本的每一个字对应1,补全符号对应0,其中cls和sep对应1。
进一步地,采用bert模型提取词嵌入,其中文本中各个字\词的原始词向量作为bert模型的输入,文本中各个字\词融合全文语义信息后的向量表示作为bert模型的输出。
进一步地,采用bert、lstm和cnn进行特征提取,提取文本深层语义特征。
进一步地,采用12层的注意力机制来提取更深层次的文本语义特征。
进一步地,所述cnn中的卷积层采用1维卷积,其中池化层采用最大池化。
进一步地,在通过lstm处理序列形式的文本数据时,产生序列化的输出数据,以将提取到的文本特征向量与cnn、bert中的数据拼接融合在一起,在经过全连接层后再进入分类器。
进一步地,在模型训练时,数据沿神经网络正向传播,所有网络在输出时进行多元特征的融合,反向传播时,通过对损失函数求偏导,进行参数更新;其中,反向传播采用的方法是adam优化算法,在进行模式测试时,利用训练时获得的模型和权重,测试数据沿神经网络正向传播至softmax分类器,进行情感极性分析。
本发明提供了一种基于bert与lstm、cnn融合的中文情感分析方法,该方法能够在使模型在训练过程中能够挖掘出更深层次的情感信息,相比于现有技术能够提高中文文本情感分析的准确率。
通过以下结合附图对本发明的最佳实施例的详细说明,本发明的这些以及其他优点将更加明显。
附图说明
本发明可以通过参考下文中结合附图所给出的描述而得到更好的理解,其中在所有附图中使用了相同或相似的附图标记来表示相同或者相似的部件。所述附图连同下面的详细说明一起包含在本说明书中并且形成本说明书的一部分,而且用来进一步举例说明本发明的优选实施例和解释本发明的原理和优点。其中:
图1是示出本发明的一种基于bert与lstm、cnn融合的中文情感分析方法的一种示例性流程的示意图;
图2为本发明的一个优选实施例中的模型整体结构示意图;
图3为本发明的一个优选实施例中的bert模型的内部结构示意图。
本领域技术人员应当理解,附图中的元件仅仅是为了简单和清楚起见而示出的,而且不一定是按比例绘制的。例如,附图中某些元件的尺寸可能相对于其他元件放大了,以便有助于提高对本发明实施例的理解。
具体实施方式
在下文中将结合附图对本发明的示范性实施例进行描述。为了清楚和简明起见,在说明书中并未描述实际实施方式的所有特征。然而,应该了解,在开发任何这种实际实施例的过程中必须做出很多特定于实施方式的决定,以便实现开发人员的具体目标,例如,符合与系统及业务相关的那些限制条件,并且这些限制条件可能会随着实施方式的不同而有所改变。此外,还应该了解,虽然开发工作有可能是非常复杂和费时的,但对得益于本发明内容的本领域技术人员来说,这种开发工作仅仅是例行的任务。
在此,还需要说明的一点是,为了避免因不必要的细节而模糊了本发明,在附图中仅仅示出了与根据本发明的方案密切相关的装置结构和/或处理步骤,而省略了与本发明关系不大的其他细节。
本发明的实施例提供了一种基于bert与lstm、cnn融合的中文情感分析方法,所述中文情感分析方法包括:对中文语料数据集中的多条中文语料进行文本预处理,以获得所述多条中文语料对应的多个序列;使用bert模型提取每个序列的词嵌入;采用bert、lstm和cnn对每个序列进行特征提取,以获得每个序列对应的文本深层语义特征;通过使用softmax分类器对所获得的文本深层语义特征进行分类,来对所述模型进行训练和测试,进而实现情感极性预测分析。
图1示出了本发明的一种基于bert与lstm、cnn融合的中文情感分析方法的一个示例性处理的流程图。
如图1所示,该流程开始之后,执行步骤s110。
在步骤s110中,对中文语料数据集中的多条中文语料进行文本预处理,以获得多条中文语料对应的多个序列。其中,上述中文语料数据集包括有预先获得的多条中文语料。
作为一个示例,在步骤s110中,例如可以通过如处理来对中文语料数据集中的多条中文语料进行文本预处理:针对中文语料数据集中的每条中文语料,将该条中文语料中的文本字符化,其中,在获得的该条中文语料对应的序列中,用cls作为该序列的第一个标记,通过sep对该序列进行分割。
作为一个示例,在步骤s110中,在对中文语料数据集中的多条中文语料进行文本预处理的过程中,例如可以通过文本字符化使得文本中的句子切分为多个字。
其中,每个序列例如为词向量序列。
每个序列的第一个标记例如均为特殊分类符cls标记,句子之间(即两个序列之间)的分割用sep进行标记,句子中替换的词汇用mask标记,其中,真实文本的每一个字对应1,补全符号对应0,其中cls和sep对应1。
接着,在步骤s120中,使用bert模型提取每个序列的词嵌入。然后,执行步骤s130。
作为一个示例,在采用bert模型提取词嵌入时,例如可以将文本中各个字\词的原始词向量作为bert模型的输入,将文本中各个字\词融合全文语义信息后的向量表示作为bert模型的输出。
也就是说,本发明使用bert模型提取词嵌入,bert模型的主要输入是文本中各个字\词的原始词向量,可随机初始化,输出的是文本中各个字\词融合了全文语义信息后的向量表示,代替了之前常用word2vec算法进行预训练的过程,而且bert模型作为双向深层系统,能够捕捉到真正意义上的上下文信息。
在步骤s130中,采用bert、lstm和cnn对每个序列进行特征提取,以获得每个序列对应的文本深层语义特征。然后,执行步骤s140。
例如,在步骤s130中,可以采用bert、lstm和cnn进行特征提取来获得文本深层语义特征。
作为一个示例,可以采用12层的注意力机制来提取更深层次的文本语义特征。
需要说明的是,bert模型的核心模块是transformer,transformer的关键部分是attention机制,而且是多层注意力和位置嵌入,常用的bert模型是12层attention及24层的,本发明采用12层的attention机制来提取更深层次的文本语义特征。
其中,cnn中的卷积层例如可以采用1维卷积,其中池化层例如采用最大池化,来实现深层特征挖掘以及降维过程。
本发明加入lstm用来处理序列形式的文本数据,并产生序列化的输出数据,将提取到的文本特征向量与cnn、bert中的数据拼接融合在一起,然后在全连接后进入分类器。
这样,在步骤s140中,可以通过使用softmax分类器对所获得的文本深层语义特征进行分类,来对上述模型进行训练和测试,进而实现情感极性预测分析。
作为一个示例,在通过lstm处理序列形式的文本数据时,产生序列化的输出数据,以将提取到的文本特征向量与cnn、bert中的数据拼接融合在一起,在经过全连接层后再进入分类器。
此外,根据本发明的实施例,在模型训练时,数据沿神经网络(即上述模型)正向传播,所有网络在输出时进行多元特征的融合,反向传播时,通过对损失函数求偏导,进行参数更新。
换句话说,在模型训练时,cnn通路的训练目标是权重wcnn和偏置bcnn;lstm通路的训练目标是权重wlstm和偏置blstm;bert通路的训练目标是wbert和偏置bbert。数据沿神经网络(即上述模型)正向传播,所有网络在输出时进行多元特征的融合。最终训练目标是:q={wcnn,wlstm,wbert,bcnn,blstm,bbert}。反向传播时,以损失函数loss求q求偏导,进行目标参数的更新。
其中,反向传播采用的方法是adam优化算法,在进行模式测试时,利用训练时获得的模型和权重,测试数据沿神经网络正向传播至softmax分类器,进行情感极性分析。
作为一个示例,通过采用经过预训练的bert模型避免分词、去停用词过程中所存在的误差对模型性能的影响;而且bert模型是双向的语言处理模型,比起常用的word2vec算法生成向量词典的预训练模型,bert模型能够捕捉到真正意义上的上下文信息,提高了情感分类的准确性。除此以外,bert模型可以同时输入字向量、文本向量和位置向量,这样能够将予以解禁的字/词在特征向量空间上的距离拉近,得到的语义信息更加准确。
例如,在本发明的实施例中,采用bert、lstm、cnn融合层来提取特征,比起常用的单层神经网络或是双层神经网络得到的数据更加准确,而且bert模型采用的是12层的attention机制,在进行特征提取时,挖掘到的数据更加全面详细。
以上均说明在情感分析过程中加入bert模型可以提高分析的准确率,能够得到更真实的数据结果,不管对于下面的特征提取和权重计算过程,还是最终的情感极性分类,都奠定了很好的基础,在很大程度上提升了情感分类的准确度。
在该实施例中,首先可以进行数据的采集和提取。
其中,本发明中的数据例如是从aichallenger中的细粒度用户评论情感分析中进行采集和提取的。
接着,对中文语料数据集进行文本预处理,将文本字符化,用cls作为每一个序列的第一个标记,sep将句子进行分割。
其中,在对中文文本语料进行预处理时,例如可以将文本字符化,使得文本中的句子切分为一个个字。其中每个词向量序列的第一个标记始终是特殊分类符cls标记,句子之间的分割用sep进行标记,句子中替换的词汇用mask标记,mask也是真实字符和补全字符标识符,真实文本的每一个字对应1,补全符号对应0,其中cls和sep对应的是1。例如:
[cls]博客是什么[sep]
11111110000000…
bert模型支持的序列长度是512个字符,上述例子中就是七个字符对应1,其他剩余为0。
接着,可以使用bert模型提取词嵌入。
其中,例如可以使用bert模型提取词嵌入,代替了之前常用word2vec算法进行预训练的过程,其中bert模型作为双向深层系统,能够捕捉到真正意义上的上下文信息。而且可以在不同的任务和模型中更新词向量,使词向量逐步地适应特定任务。
接着,可以采用bert、lstm(长短期记忆网络)和cnn(卷积神经网络)进行特征提取,提取文本深层语义特征。
其中,可以采用bert、lstm和cnn进行特征提取,提取文本深层语义特征。其中本发明提出的bert模型的核心模块是transformer,transformer的关键部分是attention机制,常用的bert模型是12层attention及24层的,本发明采用12层的attention机制来提取更深层次的语义特征。本发明中cnn中的卷积层采用1维卷积,其中池化层采用最大池化,来实现深层特征挖掘以及降维过程。本发明加入lstm用来处理序列形式的文本数据,并产生序列化的输出数据,将提取到的文本特征向量与cnn、bert中的数据拼接融合在一起,然后在全连接后进入分类器。最后将bert与lstm、cnn中得到的数据特征进行同一维度上尺度的统一,可以避免数据信息的损失。
这样,可以通过使用softmax分类器进行分类,对模型进行训练和测试,进而实现情感极性预测分析。
其中,利用已经构建好的特征融合模型进行数据训练和测试,在进行模型训练时,各条神经网络的通路从嵌入层获取数据。其中bert模型的训练目标是网络参数权重wb及偏置bb,lstm的网络权重wl和偏置bl,cnn的网络权重wc和偏置bc。当数据沿神经网络正向传播时,所有通路的输出在bert模型中结合。最终的训练目标为£={wb,bb,wl,bl,wc,bc}。反向传播时,通过损失函数对£求偏导,进行目标参数的更新。本发明中反向传播采用的方法是adam优化算法。在进行模式测试时,利用训练时获得的模型和权重,测试数据沿神经网络正向传播至分类器。最终将得到的数据进行正向、负向、中性及未提及四类细粒度情感分类,实现情感极性分析。
本发明通过采用经过预训练的bert模型避免分词、去停用词过程中所存在的误差对模型性能的影响;而且bert模型用的是transformer,相比于常用的rnn更加高效、能捕捉更长距离的依赖;同时比起常用的word2vec算法生成向量词典的预训练模型,bert模型能够捕捉到真正意义上的上下文信息;除此以外,bert模型可以同时输入字向量、文本向量和位置向量,这样能够将予以解禁的字/词在特征向量空间上的距离拉近,得到的语义信息更加准确。本发明提出一种基于bert与lstm、cnn融合的中文情感分析方法,能够更加全面的挖掘深层次的语义特征,从而提高了情感分类结果的准确性。
下面描述本发明的一个优选实施例。
在该优选实施例中,如图2所示,首先对中文语料数据集进行文本预处理,将文本字符化,用cls作为每一个序列的第一个标记,sep将句子进行分割。
其中本发明所采用的中文语料集是从aichallenger中的细粒度用户评论情感分析这个数据库中进行采集和提取的。
本文的预处理过程主要完成了字符化过程,将文本切分成一个个字,然后用cls、sep进行标注,最终将处理好的数据传递到bert模型,为下一步过程做好准备工作。
然后使用bert模型提取词嵌入,数据集划分为训练集和测试集;
本发明加入bert模型,代替了之前常用word2vec算法进行预训练的过程,其中bert模型作为双向深层系统,能够捕捉到真正意义上的上下文信息。也不需要进行结巴分词和独自训练或者下载词向量,之后在词典中找到对应索引,完成向量化,为了便于神经网络的训练,向量数据形成一个嵌入矩阵,在bert模型的作用下完成词嵌入过程。而且可以在不同的任务和模型中更新词向量,使词向量逐步地适应特定任务。
接着采用bert、lstm(长短期记忆网络)和cnn(卷积神经网络)进行特征提取,提取文本深层语义特征;
本发明通过将bert、lstm和cnn进行特征融合能够更加全面的挖掘文本深层特征,在完成文本预处理及词嵌入过程后,将得到的数据经过bert、lstm和cnn融合层进行特征提取。本发明中bert层、lstm层及cnn层的输出数据都是一维的,这样做的目的是将bert与lstm、cnn中得到的数据特征进行同一维度上尺度的统一,可以避免数据信息的损失,使得最后融合生成的向量数据更加准确。
最后通过使用softmax分类器进行分类,对模型进行训练和测试,进而实现情感极性预测分析。
利用已经构建好的模型进行数据训练和测试,在进行模型训练时,主要是bert、lstm、cnn将经过预处理后的数据进行训练,然后从中提取各自的网络参数权重w及偏置b。同时在模型训练过程中需要通过正向传播和反向传播过程来实现对数据的传递和参数的更新,当进行正向传播时,bert、lstm、cnn中得到的数据最终传输到融合层进行处理。在反向传播时,主要是对损失函数£来求偏导,实现目标参数的更新。其中本发明中进行反向传播采用的方法是adam优化算法。在模型训练结束后,进行模型测试,将训练后得到的数据通过正向传播至softmax分类器。最终对得到的数据实现正向、负向、中性及未提及四类细粒度情感分类,实现情感极性分析。
如图3所示,公开了一种基于bert与lstm、cnn融合的中文情感分析方法,包括以下步骤:
bert模型对文本的处理主要是:首先输入文本,然后将文本用向量表示,之后进入multi-headself-attention(多头自注意力)结构,对数据进行处理和更新,最后输出文本。
比起attention(注意力)和self-attention(自注意力)机制,multi-headself-attention结构主要为了增强attention的多样性,通过利用不同的self-attention模块获得文本中每个字在不同语义空间下的增强语义向量,并将每个字的多个增强语义向量进行线性组合,从而获得一个最终的与原始字向量长度相同的增强语义向量。
这里给出一个例子来帮助理解multi-headself-attention。看下面这句话:“北京市长春市”,在不同语义场景下对这句话可以有不同的理解:“北京市/长春市”,或“北京市长/春市”。对于这句话中的“长”字,在前一种语义场景下需要和“春”字组合才能形成一个正确的语义单元;而在后一种语义场景下,它则需要和“市”字组合才能形成一个正确的语义单元。
而且,self-attention旨在用文本中的其它字来增强目标字的语义表示。在不同的语义场景下,attention所重点关注的字应有所不同。因此,multi-headself-attention可以理解为考虑多种语义场景下目标字与文本中其它字的语义向量的不同融合方式。可以看到,multi-headself-attention的输入和输出在形式上完全相同,输入为文本中各个字的原始向量表示,输出为各个字融合了全文语义信息后的增强向量表示。因此,bert模型对文本中每个字分别增强其语义向量表示具有重要意义,为后续情感分类的准确率有很大提升。
最后应说明的是:以上实施例仅用以示例性说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明及本发明带来的有益效果进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明权利要求的范围。
- 还没有人留言评论。精彩留言会获得点赞!