本发明涉及计算机应用技术领域,具体涉及一种基于关系型数据库的信用评价算法。
背景技术:
随着互联网的快速发展及云计算、大数据、移动互联网、物联网等技术的日渐成熟,政府机关、金融机构、互联网公司、公共服务行业等都积累了丰富的数据资源,这些数据资源在大数据环境下才能得到充分利用,挖掘出这些数据与信用的关联关系,可以促进对征信数据进行更加充分的利用。
现阶段基于大数据支持的信用评价算法,如阿里芝麻信用、京东白条信用等,其研发和维护成本较高,不太适合小型项目或者人员体系的算法评测,对于数据量较小、不足以支撑大数据运算的信用评价情况不适用。
技术实现要素:
本发明的技术任务是提供一种基于关系型数据库的信用评价算法,可在小型关系体系中计算出基于需求定制的评价结果,信用评价过程支持配置,易用性高,评分速度和效率大幅提高。
本发明解决其技术问题所采用的技术方案是:
一种基于关系型数据库的信用评价算法,该算法通过在数据库中实现基于存储过程定义的算法方法,实现对基础数据的整理和体系人员的信用评价,基于存储过程的编译规则,针对不同的关系型数据库进行差异化实现,可以满足mysql,oracle等多种数据库进行算法实现;实现方式如下:
将一系列的业务指标项依据不同的预处理规则进行加工整理;
再根据不同的指标项的处理算法整合出相关具体指标的得分情况;
然后依据每个指标所属维度的计分方式与规则进行分数整合,整理出最终的信用评价得分,实现对主体的信用考核。
存储过程是在大型数据库系统中,一组为了完成特定功能的sql语句集,存储在数据库中,经过第一次编译后调用不需要再次编译,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。存储过程是数据库中的一个重要对象。
本算法基于基础数据的自定义基础整理,以及相关算法的自定义配置,可在小型关系体系中计算出基于需求定制的评价结果,实现信用评价的过程配置。
优选的,该算法的底层指标项为数据整合,通过将一组数据进行预处理加工,整合出满足评分要求的结果集存入指标项结果表中。
底层指标项的数据整合方式为:解析“指标项.1”→计算原值→加载评分标准→得出分值;由“指标项.1”进而解析“指标项.2”→计算原值→加载评分标准→得出分值;直至“指标项.n”→计算原值→加载评分标准→得出分值;并返回得分情况。
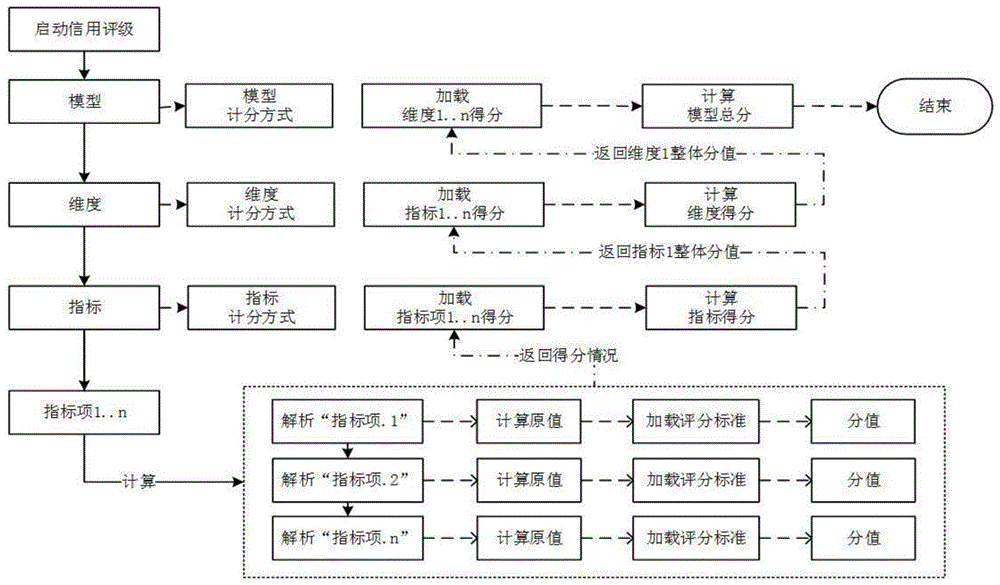
启动信用评级→模型→维度→指标→指标项1...n,定义模型计分方式、维度计分方式和指标计分方式;
底层指标项数据整合→指标加载指标项1...n得分→计算指标得分→返回指标1整体分值→维度加载指标1...n得分→计算维度得分→返回维度1整体分值→模型加载维度1...n得分→计算模型总分→信用评级结束。
优选的,将加工规则的处理sql语言存入指标项规则表,主算法过程在进行评分算法之前预先加工指标项,以满足易用性。
优选的,每个指标项对应评分卡,算法在对指标项进行评分时,会依据每个指标项对应的评分卡中记录的评分依据进行评分,为满足不同用户的需求,将算法规则进行定义加工,通过拼接的形式选择,评分过程通过读取评分卡的对应指标,进行评分语句拼接。
具体的,使用casewhen语句实现算法自定义配置。
优选的,评分卡配置时,预先配置评分卡规则,通过在算法过程中不同的if语句中的判断条件,根据算法的形式否决式或阶梯式的算法定义,最后将分数插入统一的结果表。
具体的,所述否决式算法为if...else;所述阶梯式算法为if...elseif...else。
优选的,评分卡配置完成后,主算法调取指标评分算法和维度评分算法进行整理加权,计算出最后的信用评价总分,加权过程算法读取预先配置好的加权规则,通过数据库中的聚合函数实现不同的积分规则,如求和函数sum、求均值avg等。
优选的,算法维度计算规则支持无限迭代,通过判断当前模型的最高级别判断出要循环的次数。
具体的,定义维度为末尾维度来标识算法是否完成,通过读取算法的等级来进行维度层次迭代,将分数插入统一的结果表中,最后进行数据加权汇总。
通过对分数的最终评分实现限制,可以针对部分模型触发条件后的直接定级。
本发明的一种基于关系型数据库的信用评价算法与现有技术相比,具有以下有益效果:
本算法通过在数据库中实现一组基于存储过程定义的算法方法,实现对基础数据的整理和体系人员的信用评价,算法过程相对较为简单,适合当数据量不足以支撑大数据运算时的信用评价的首要选择。
本算法基于基础数据的自定义基础整理,以及相关算法的自定义配置,可以在小型关系体系中计算出基于需求定制的评价结果;同时,当数据结构发生改变和调整时,本算法无须开发人员支持,理解当前评信领域业务的任何业务人员都可以实现信用评价的过程配置,故本算法的易用性和可扩展性较高,评分速率和效率大幅提高。
附图说明
图1是本发明基于关系型数据库的信用评价算法的流程图;
图2是本发明实施例中指标项的加工规则示例图。
具体实施方式
下面结合具体实施例对本发明作进一步说明。
一种基于关系型数据库的信用评价算法,该算法通过在数据库中实现基于存储过程定义的算法方法,实现对基础数据的整理和体系人员的信用评价,基于存储过程的编译规则,针对不同的关系型数据库进行差异化实现,可以满足mysql,oracle等多种数据库进行算法实现。
存储过程是在大型数据库系统中,一组为了完成特定功能的sql语句集,存储在数据库中,经过第一次编译后调用不需要再次编译,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。存储过程是数据库中的一个重要对象。
信用评价是以一套相关指标体系为考量基础,通过对每个主体的一组业务数据进行评分的考核过程,实现对某一主体的信用考核,本算法的实现方式如下:
将一系列的业务指标项依据不同的预处理规则进行加工整理;
再根据不同的指标项的处理算法整合出相关具体指标的得分情况;
然后依据每个指标所属维度的计分方式与规则进行分数整合,整理出最终的信用评价得分,实现对主体的信用考核。
该算法的底层指标项为数据整合,通过将一组数据进行预处理加工,整合出满足评分要求的结果集存入指标项结果表中。为了满足易用性,将加工规则的处理sql语言存入指标项规则表,主算法过程在进行评分算法之前预先加工指标项。指标项的加工规则如图2所示。
每个指标项对应评分卡,算法在对指标项进行评分时,会依据每个指标项对应的评分卡中记录的评分依据进行评分,为满足不同用户的需求,将算法规则进行定义加工,通过拼接的形式选择,评分过程通过读取评分卡的对应指标,进行评分语句拼接,使用casewhen语句达到算法自定义配置效果。
评分卡配置时,预先配置评分卡规则,通过在算法过程中不同的if语句中的判断条件,根据算法的形式否决式或阶梯式的算法定义,最后将分数插入统一的结果表。
所述否决式算法为if...else;所述阶梯式算法为if...elseif...else。
底层指标项的数据整合方式为:解析“指标项.1”→计算原值→加载评分标准→得出分值;由“指标项.1”进而解析“指标项.2”→计算原值→加载评分标准→得出分值;直至“指标项.n”→计算原值→加载评分标准→得出分值;并返回得分情况。
如图1所示为本算法的流程示意图。
启动信用评级→模型→维度→指标→指标项1...n,定义模型计分方式、维度计分方式和指标计分方式;
底层指标项数据整合→指标加载指标项1...n得分→计算指标得分→返回指标1整体分值→维度加载指标1...n得分→计算维度得分→返回维度1整体分值→模型加载维度1...n得分→计算模型总分→信用评级结束。
评分卡配置完成后,主算法调取指标评分算法和维度评分算法进行整理加权,计算出最后的信用评价总分,加权过程算法读取预先配置好的加权规则,通过数据库中的聚合函数实现不同的积分规则,如求和函数sum、求均值avg等。
算法维度计算规则可以无限迭代,通过判断当前模型的最高级别判断出要循环的次数。定义维度为末尾维度来标识算法是否完成,通过读取算法的等级来进行维度层次迭代,将分数插入统一的结果表中,最后进行数据加权汇总。
通过对分数的最终评分实现限制,可以针对部分模型触发条件后的直接定级。
本算法基于基础数据的自定义基础整理,以及相关算法的自定义配置,可在小型关系体系中计算出基于需求定制的评价结果,当数据结构发生改变和调整时,本算法无须开发人员支持,理解当前评信领域业务的任何业务人员都可以实现信用评价的过程配置,算法过程相对简单,适合当数据量不足以支撑大数据运算时的信用评价。
通过上面具体实施方式,所述技术领域的技术人员可容易的实现本发明。但是应当理解,本发明并不限于上述的具体实施方式。在公开的实施方式的基础上,所述技术领域的技术人员可任意组合不同的技术特征,从而实现不同的技术方案。