一种基于元学习的主动采样方法与流程
本发明涉及一种基于元学习的主动采样方法;属于机器学习技术领域。
背景技术:
在大数据时代的背景下,我们能够轻易地获得大量的未标记数据集,而绝大部分机器学习模型,尤其是深度学习模型都需要大量的有标记样本进行训练。然而,获取有标记样本是十分困难且昂贵的,特别是在需要高度相关的专业知识背景的领域,例如医学图像领域。主动学习的概念正是针对上述问题而提出的,目的是挑选尽可能少的未标记样本进行标记,使得模型的性能达到一个令人满意的效果。
目前,大部分主动采样(al)策略都是针对不同的分类任务而设计相应的指标,在面对不同任务时,没有一种主动采样策略能够明显优于其他策略。因此,研究者提出了许多meta-al方法来自动选择最佳策略。但是它们需要对分类模型性能进行可靠的评估以此去选择最佳的策略,因为有标记的数据很少,这往往是不准确的。这些meta-al的方法也很难超越现有人为设计al策略的组合。鉴于上述原因,有必要对采样方法进行改进。
技术实现要素:
发明目的:为了克服现有技术中存在的不足,本发明的目的在于提供一种基于元学习的主动采样方法。
为实现上述目的,本发明采用的技术方案为:
一种基于元学习的主动采样方法,包括以下步骤:
(一)通过在大量已有标记的数据集上模拟进行主动学习的过程,根据meta特征设计规则,获取足够量的metadata数据;
(二)根据步骤(一)中获取的metadata数据训练meta回归模型m;
(三)在当前主动学习任务上,根据meta特征设计规则,计算每个未标记样本的meta特征;
(四)将(三)中meta数据输入至步骤(二)中meta回归模型m,选择输出值最大的未标记样本,向用户查询真实标记;
(五)根据得到的真实标记更新模型;
(六)返回步骤(三)或结束并输出分类模型c。
进一步的,所述步骤(一)在大量已有标记的数据集上获取metadata数据,具体方法为:
假设当前分类模型为c,当前考虑的未标记样本为x;设metadata数据集结构为[z,δp],其中z为设计的meta特征,δp为分类模型c在加入未标记样本x重新训练后,在测试集上性能前后变化值,其中meta特征z设计具体细节为:
1)关于数据集的传统的元特征(共19维)
a)简单的元特征
样本的数量及其对数,特征的数量及其对数,样本数与特征数之比及其对数,特征数与样本数之比及其对数;
b)统计特征
计算所有数值特征的峰度(kurtosis),取其最小值,最大值,均值,标准差;
计算所有数值特征的偏度(skewness),取其最小值,最大值,均值,标准差;
c)pca统计特征
利用主成分分析pca的方法,将主成分占比95%的每个成分所解释的方差量进行求和;利用pca将数据集降维至一维后,计算该特征值的峰度和偏度。
2)样本本身的信息(共35维)
a)数据集特征维度(属性维度);
b)已标记的数据集中正样本的比例,负样本的比例;
c)根据当前模型的预测值,计算未标记数据集中,模型预测为正样本的比例,负样本的比例;
d)在整个数据集(包含已标记和未标记)中进行聚类,获取10个聚类中心点ai,并按照每个中心点与x的距离从小到大排序记为aii=1,2,……10(这10个点的顺序是根据不同的x变化的)。计算x与上述10个代表性样本数据点的欧氏距离,并做归一化处理:
e)按照当前模型对已标记数据集的预测值进行排序,选出10等分点的数据bii=1,2,……10。计算x与上述10个代表性样本数据点的欧氏距离,并做归一化处理:
f)按照当前模型对未标记数据集的预测值进行排序,选出10等分点的数据cii=1,2,……10。计算x与上述10个代表性样本数据点的欧氏距离,并做归一化处理:
3)模型本身的信息(共180维)
a)在已标记数据上计算tp、fp、tn、fn的比例;
b)在已标记数据上按照当前模型对已标记数据集的预测值做归一化处理(在整个数据集上选出最小最大值进行归一化),并进行排序,选出10等分点的值记录;
c)计算2)中10个值(归一化后)的均值和方差;
d)在未标记数据上,根据当前模型的预测值,计算未标记数据集中,模型预测为正样本的比例,负样本的比例;
e)按照当前模型对未标记数据集的预测值做归一化处理(在整个数据集上选出最小最大值进行归一化),并进行排序,选出10等分点的值记录;
f)计算e)中10个值的均值和方差;
g)将在此轮之前的五轮主动学习过程中,上述a)到f)的特征全部用作本轮的特征。
4)模型在样本上预测的信息(共181维)
首先根据当前模型对整个数据集的预测值,做归一化处理;
a)记录c(x);
b)计算当前c(x)与a,b,c三组共30个样本预测值的差;
c)将在此轮之前的五轮主动学习过程中,上述1)到2)的特征全部用作本轮的特征(注意a、b、c三组样本都是本轮选出来的,而不是前5轮选出的)。
其中δp为分类模型c在加入未标记样本x重新训练后,在测试集上性能前后变化值。模型的性能在本文中选取为模型在测试集上的准确率,针对不同任务可以选择不同的评测标准。
进一步的所述步骤(三)在当前主动学习任务上,根据meta特征设计规则,计算每个未标记样本的meta特征,并在步骤(四)中利用步骤(二)中训练好的回归模型m输出值最大的未标记样本,具体方法为:
x*=argmaxx∈um(φ(x,c))
其中φ(x,c)是按照步骤(一)中设计的meta特征,根据当前模型c和未标记样本x计算出对应的meta特征,m是根据步骤(二)训练得到的回归模型,x*即为主动学习过程中被挑选出,给人类专家进行标注的未标记样本。
步骤(一)中,在已有标记数据集上获取metadata的步骤如下:
s11、从已有标记的数据集d={d1,…,dn}中挑选一个数据集d;
s12、将该数据集随机划分成训练集和测试集t;
s13、针对训练进一步划分成有标记样本集l和未标记样本集u,用于模拟主动学习的过程;
s14、依次随机地从u中选取5个样本加入至l,生成主动学习前五轮数据;
s15、根据当前有标记集l训练分类模型c,并在测试集t上获的性能评分p0;
s16、用生成metadata数据,从u中随机挑选一个样本x加入l中,重新训练模型c,然后根据当前分类模型c计算x的meta特征z=φ(x,c);
s17、将在x加入l中后重新训练的分类模型c在测试集t上获的性能评分p1,计算δp=p1-p0分类模型c性能变化值,生成metadata数据[z,δp];
s18、判断训练集划分成l和u的次数是否达到要求数量,若达到要求,跳至s19,否则转至步骤s13;
s19、判断训练集和测试集的划分次数是否达到要求数量,达到要求则结束,否则转至步骤s12。
优选地,为了保证分类模型测试性能的准确性,将测试集t占整个数据集的比例设置0.5。
有益效果:本发明的基于元学习的主动采样方法借鉴了metalearning的思想,通过之前得到的主动学任务的经验(metadata)用一个回归模型m去学习一个查询策略的指标,而不是人为设计一个指标。回归模型m的输入是根据我们设计的一些关于某个样本x和当前分类模型c的底层特征,这些设计的meta特征与数据集的特征空间和分类模型的形式无关,输出值是衡量x对于提升分类模型c的作用大小。并且,这些meta特征独立于数据集的特征空间和分类模型的形式,因此本发明的主动采样方法具有更好的泛化能力。
附图说明
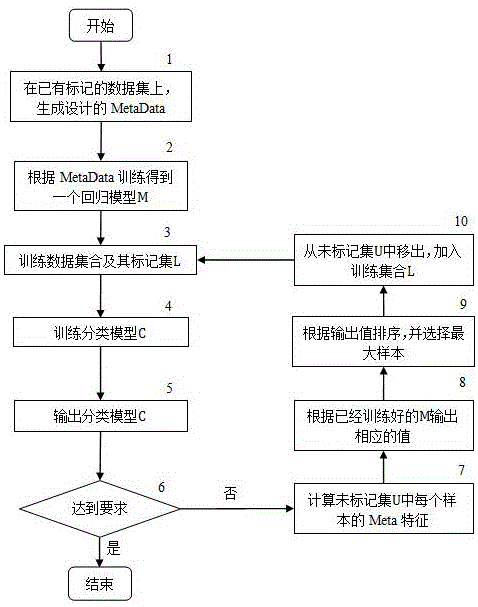
图1是以数据为驱动的元学习主动采样方法的工作流程图;
图2是在已有标记数据集上获取metadata的流程图。
具体实施方式
下面结合附图和具体实施例对本发明作具体的介绍。
参见图1,本实施例的采样方法具体流程如下:
首先,需要生成大量的metadata数据集。假设可以获取到大量已有标记的数据集d={d1,…,dn}。该步骤1中,对于d中的每个数据集,按照本方案设计的meta特征生成相对应的metadata数据集,具体过程参见图2。
接着,步骤2对于获得metadata数据集,利用sklearn机器学习工具包中的集成学习算法extratressregressor训练一个回归模型m。
然后,针对当前主动学习任务d*,假设共有n1个已标记样本,用l表示;另一部分是未经用户标注的,假设共有n2个未标记样本,用u表示。
最后,用已标记的数据l训练出初始模型c。
(1)如果模型达到要求,则结束训练。在这里,判断模型是否达到要求可以采用机器学习或模式识别教科书中常用的方法,比如迭代轮数达到用户指定的次数或是模型在测试集上性能表现达到要求。
(2)如果模型达不到要求,则根据当前分类模型c和本文设计的meta特征,对未标记样本集u中的每一个样本计算出对应的meta特征φ(x,c),其中x为未标记样本集中的样本,c是当前分类模型,φ是meta特征映射函数。通过已经训练好的回归模型m计算出预计模型性能变化值。选取能够使分类模型c性能提升最大的样本x*,公式表达为:x*=argmaxx∈um(φ(x,c))。然后将选取的x*交给用户进行标注,更新l和u,并返回步骤3。
图2所示为在已有标记数据集d上获取metadata的流程图:
首先,步骤11从已有标记的数据集d={d1,…,dn}中挑选一个数据集d,步骤12将该数据集随机划分成训练集和测试集t,其中为了保证分类模型测试性能的准确性,将测试集t占整个数据集的比例设置0.5。然后,步骤13针对训练进一步划分成有标记样本集l和未标记样本集u,用于模拟主动学习的过程。步骤14依次随机地从未标记样本集u中选取5个样本加入至l,生成主动学习前五轮数据。步骤15根据当前有标记集l训练分类模型c,并在测试集t上获得性能评分p0。步骤16用生成metadata数据,从u中随机挑选一个样本x加入l中,重新训练模型c,然后根据当前分类模型c计算x的meta特征z=φ(x,c)。步骤17,将在x加入l中后重新训练的分类模型c在测试集t上获得性能评分p1,计算δp=p1-p0分类模型c性能变化值,生成metadata数据[z,δp]。步骤18判断训练集划分成l和u的次数是否达到要求数量,若达到要求,则步骤19判断训练集和测试集的划分次数是否达到要求数量,否则转至步骤12;若没达到要求则转至步骤13。该数据处理过程的目的是为尽可能多的覆盖不同的主动学习情况,使得学得主动学习选择标准更具有泛化性能。
综上,本发明的基于元学习的主动采样方法借鉴了metalearning的思想,通过之前得到的主动学任务的经验(metadata)用一个回归模型m去学习一个查询策略的指标,而不是人为设计一个指标。回归模型m的输入是根据我们设计的一些关于某个样本x和当前分类模型c的底层特征,这些设计的meta特征与数据集的特征空间和分类模型的形式无关,输出值是衡量x对于提升分类模型c的作用大小。并且,这些meta特征独立于数据集的特征空间和分类模型的形式,因此本发明的基于元学习的主动采样方法具有更好的泛化能力。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!