一种基于RDMA网络的分布式训练系统及高效训练方法与流程
一种基于rdma网络的分布式训练系统及高效训练方法
技术领域
[0001]
本发明涉及分布式机器学习领域;具体地,涉及一种基于rdma网络的分布式训练系统及高效训练方法。
背景技术:
[0002]
机器学习,特别是深度学习,在人工智能驱动服务中获得了广泛的成功。随着模型越来越复杂,其训练的计算成本越来越高。若要实现高效及时的训练,则需发掘分布式系统并行计算的优势。业内领军企业如微软、facebook和google等已经开始尝试在成百上千的服务器组成的生产集群上运行分布式机器学习训练任务。
[0003]
然而,一个具备实用意义的用于分布式训练的物理集群,其从构建部署到运行维护,都是极为专业且复杂甚至是繁琐的工作。将容器云技术应用到分布式机器学习领域,无疑可大大简化其构建部署运维工作的难度。
[0004]
容器云技术不仅能够实现容器集群的快速部署,同时它也是一种轻量化的解决方案,且能够有效整合和管理着裸机资源。以kubernetes平台运行分布式机器学习训练任务为例,kubernetes不仅为打包应用提供一致的方法,保证应用在不同设备上运行的一致性,为应用的运行环境提供资源隔离,同时其对硬件底层的复杂性和节点管理进行了抽象,并且支持gpu的调度。
[0005]
但是,无论是以若干主机服务器搭建的用于训练的物理集群,还是在容器云平台部署的训练集群,计算节点间的数据传输通常是以基于tcp/ip协议(也是目前广域网和局域网通用的网络协议)网络通信实现的。上述网络通信过程需要操作系统和协议栈的介入,但随着训练集越来越大,在参数交换(parameter exchange)过程中将不可避免占用大量的cpu资源,造成较大网络延时,严重制约训练效率。
[0006]
远程直接内存访问技术,即rdma(remote direct memory access)技术,则是一种直接内存访问技术;它将数据直接从一台计算机的内存传输到另一台计算机,无需双方操作系统的介入。因此,相较于上述基于通用的tcp/ip协议的常规网络,rdma网络通信可以避免网络传输过程中大量的cpu资源占用,同时也减小了网络延时。那么,为分布式训练任务搭建/部署具有rdma网络的训练集群,并在训练过程中为训练数据(例如参数交换过程中的数据通信)提供rdma网络通信,显然是一种突破参数交互网络通信瓶颈、提高分布式训练效率的有效途径。
[0007]
在分布式训练过程中,通常是以环境配置参数来保障被分配到各计算节点的子任务间的依赖关系和控制子任务间的数据一致性的。具体而言,一般地,每个子任务对应的环境配置参数将包括全部子任务以及当前子任务的一些信息(如子任务编号、网络连接参数等)。在现实的部署及训练过程中,除利用环境配置参数调度分布式任务到训练集群(即将各个子任务分配到训练集群各计算节点)外,还包括在训练过程中通过环境配置参数中的网络连接参数实现运行在不同计算节点的训练应用程序间的数据通信。
[0008]
因此,在实践中,以在具有rdma网络的物理集群部署分布式训练任务为例,为实现
rdma网络环境下的高效分布式训练,一般是先行获取训练集群各计算节点的rdma网络ip,手动/利用脚本生成包括rdma网络ip(作为网络连接参数)的环境配置参数,进而实现任务被调度到训练集群后的高效分布式训练。
[0009]
然而,在容器云平台上部署分布式训练,往往被认为是能够更高效地利用平台资源。为更好地利用资源,在容器云平台部署训练任务时,通常是:先将训练任务分解为若干个子任务,并为之生成环境配置参数,然后才为子任务创建对应的容器/容器组(容器/容器组是指容器集群在编排管理时最小单位;其中,容器即在容器环境下运行独立应用的容器;容器组,是指在容器环境下运行独立应用的“逻辑主机”,运行着一个或者多个紧密耦合的应用容器,如kubernetes平台的pod)。分布式训练启动后,运行在各计算节点的子任务训练应用程序间则是通过连接访问服务经由常规网络(即基于tcp/ip的网络,一般作为多网络集群的默认网络)实现通信的。而这种通信机制恰是需要系统内核介入的。而rdma网络实现高效通信的关键则是不依赖系统内核介入。因此,即使当分布式训练任务被调度到具有rdma网络的多网络容器训练集群,在分布式训练启动后,运行在集群各计算节点(即用于训练的容器/容器组)的训练应用程序也是无法发现和有效地使用rdma网络,进而也就仍无法突破通信瓶颈,实现高效训练的。
[0010]
此外,即便是在具有rdma网络的双网络物理集群部署分布式训练任务,也需手动/利用脚本生成特殊的环境配置参数(以rdma网络ip为网络连接参数的环境配置参数);而手动配置,难免不出错;而且也不适用于大规模集群部署。
技术实现要素:
[0011]
有鉴于此,本发明提供一种基于rdma网络的分布式训练系统及高效训练方法。
[0012]
一方面,本发明实施例提供一种基于rdma网络的分布式训练系统。
[0013]
上述的基于rdma网络的分布式训练系统,包括:
[0014]
网络环境重置单元和分布式训练执行单元;其中,
[0015]
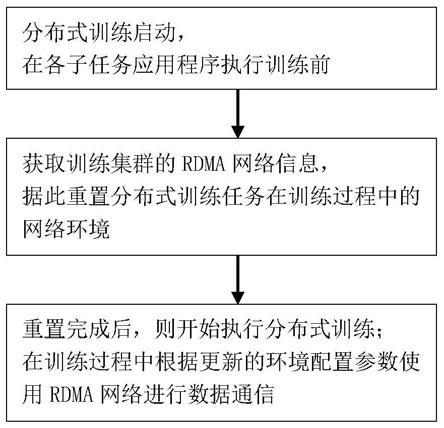
网络环境重置单元,用于在分布式训练启动后,即训练集群各计算节点分别启动对应子任务的训练应用程序后,且在各子任务应用程序执行训练前,重置分布式训练任务(即各子任务)在训练过程中的网络环境:
[0016]
即获取训练集群的rdma网络信息,并根据其更新分布式训练任务的环境配置参数;
[0017]
分布式训练执行单元,用于在重置完成后执行分布式训练,并在训练过程中根据更新的环境配置参数使用rdma网络进行数据通信。
[0018]
另一方面,本发明实施例提供一种高效的分布式训练方法,用于高效执行被调度到具有rdma网络的多网络训练集群上的分布式训练任务。
[0019]
上述的高效分布式训练方法,包括:
[0020]
当分布式训练任务被调度到具有rdma网络的训练集群,
[0021]
在分布式训练启动后,即训练集群各计算节点分别启动对应子任务的训练应用程序后,且在各子任务应用程序执行训练前,
[0022]
重置分布式训练任务(即各子任务)在训练过程中的网络环境:
[0023]
获取训练集群的rdma网络信息,即各计算节点的rdma网络信息;
[0024]
根据训练集群的rdma网络信息更新分布式训练任务的环境配置参数,实现分布式训练任务在训练过程中的网络环境重置;
[0025]
重置完成后,则开始执行分布式训练,即各子任务应用程序执行训练,并在训练过程中根据更新的环境配置参数使用rdma网络进行数据通信。
[0026]
上述实施例中的基于rdma网络的分布式训练系统、训练方法,在分布式训练任务被调度到具有rdma网络的训练集群后,通过为分布式任务重置其在训练过程中的网络环境,以及重置完成后的分布式训练过程中使用重置后的rdma网络进行通信,以克服现有技术部署分布式训练任务存在的通信瓶颈问题,进而提高分布式训练效率。
附图说明
[0027]
为更加清楚地说明本发明实施例或现有技术中的技术方案,下面将对本发明中一部分实施例或现有技术描述中涉及的附图做简单介绍。
[0028]
图1为基于本发明一些优选实施例提供的一种高效的分布式训练方法的流程示意图。
具体实施方式
[0029]
下面结合本发明实施例的附图,对本发明实施例中的技术方案进行清楚、完整地描述。显然,所描述的实施例仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在无需创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0030]
以下为本发明的一些优选实施例。这些优选实施例中的一些提供一种基于rdma网络的分布式训练系统。该系统包括:
[0031]
网络环境重置单元和分布式训练执行单元;其中,
[0032]
网络环境重置单元,用于在分布式训练启动后,即训练集群各计算节点分别启动对应子任务的训练应用程序后,且在各子任务应用程序执行训练前,重置分布式训练任务(即各子任务)在训练过程中的网络环境:
[0033]
即获取训练集群的rdma网络信息,并根据其更新分布式训练任务的环境配置参数;
[0034]
其中,获取训练集群rdma信息,即获取训练集群各计算节点及其rdma网络信息(这里可以是rdma网络ip);而获取训练集群的rdma网络信息的方式有很多种,其中的一些还与任务调度和集群网络ip分配机制有关。其中的一些实例,可以是获取资源调动平台的rdma网络ip分配表(通常是指集群部署过程中,分配rdma网络ip时记录生成的);另外也可以根据环境配置参数中的任务id(预先设定)或依靠zookeeper从各计算节点中确定一主节点来汇集训练集群的rdma网络ip;
[0035]
而根据其更新分布式训练任务的环境配置参数,即训练集群rdma网络信息(即各计算节点的rdma网络ip)替换分布式训练任务环境配置参数中的默认网络连接参数;
[0036]
分布式训练执行单元,则用于在重置完成后执行分布式训练,而在这样的训练过程中,分布式训练任务,即各计算节点运行着的子任务训练应用程序,会根据各自更新的环境配置参数使用rdma网络进行数据通信。
[0037]
上述优先实施例中的一些提供的基于rdma网络的分布式训练系统中,其分布式训练任务部署在容器云平台,其计算节点非一般意义上的物理主机,而是容器/容器组这样的虚拟化计算机资源。
[0038]
上述优先实施例中的一些提供的基于rdma网络的分布式训练系统中,在训练集群的计算节点中,除在训练过程中用于数据并行计算的工作节点(worker)外,还包括参数服务器(parameter server)节点,用于负责维护全局共享的参数。
[0039]
图1则为本发明的另一些优选实施例提供的高效的分布式训练方法,用于高效执行被调度到具有rdma网络的多网络物理集群上的分布式训练任务。如图1所示,该方法包括:
[0040]
当分布式训练任务被调度到具有rdma网络的训练集群,
[0041]
在分布式训练启动后,即训练集群各计算节点分别启动对应子任务的训练应用程序后,且在各子任务应用程序执行训练前,
[0042]
重置分布式训练任务(即各子任务)在训练过程中的网络环境:
[0043]
获取训练集群的rdma网络信息,也就是训练集群各计算节点及其rdma网络信息(这里可以是rdma网络ip);以下为一些获取训练集群的rdma网络信息的方法,其中可以是获取资源调动平台的rdma网络ip分配表(通常是指集群部署过程中,分配rdma网络ip时记录生成的);也可以根据环境配置参数中的任务id(预先设定)或依靠zookeeper从各计算节点中确定一主节点来汇集训练集群的rdma网络ip;
[0044]
而根据其更新分布式训练任务的环境配置参数,即训练集群rdma网络信息(即各计算节点的rdma网络ip)替换分布式训练任务环境配置参数中的默认网络连接参数;
[0045]
而重置完成后,则开始执行分布式训练;即由各子任务应用程序执行训练,在这样的训练过程中分布式训练任务,即上述各子任务应用程序自然会根据更新的环境配置参数使用rdma网络进行数据通信。
[0046]
上述优先实施例中的一些提供的高效分布式训练方法,其分布式训练任务部署在容器云平台,其计算节点非一般意义上的物理主机,而是容器/容器组这样的虚拟化计算机资源。
[0047]
上述优先实施例中的一些提供的高效分布式训练方法,在训练集群的计算节点中,除在训练过程中用于数据并行计算的工作节点(worker)外,还包括参数服务器(parameter server)节点,用于负责维护全局共享的参数。
[0048]
而以下为基于本发明一优选实施例提供的高效分布式训练方法在kubernetes平台部署和执行分布式tensorflow任务的过程。其具体过程如下:
[0049]
当分布式tensorflow任务被调度到kubernetes平台上配置了常规网络和rdma网络的容器集群后,
[0050]
启动分布式tensorflow任务,容器集群的每个pod中起一个分布式tensorflow训练进程,用于执行调度到该pod的子任务;
[0051]
在各训练进程开始执行子任务训练前,
[0052]
重置各pod子任务在训练过程中的网络环境:
[0053]
运行在各pod的训练进程获取训练集群的rdma网络信息,即训练集群各pod及其被分配的(虚拟)rdma网卡ip;这里具体的实现为,选择一个pod获取训练集群各pod及其被分
配的(虚拟)rdma网卡ip,并通过常规网络同步给其他pod;
[0054]
并以rdma网卡ip替换tf_config中的默认网络连接参数——连接访问服务名称,重新生成tf_config替换原tf_config;
[0055]
更新完成后,,各pod即可开始执行tensorflow训练,进入构建图、数据并行计算阶段;在这之后的训练过程中,运行在各pod的tensorflow应用程序自然会根据更新的tf_config使用rdma网络进行数据通信。
[0056]
以上所述仅为本发明的具体实施方式,但本发明的保护范围并不局限于此。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1