基于自适应卡尔曼滤波的LSTM-IDM跟驰特性融合方法、存储介质及设备与流程
本发明涉及智能汽车驾驶技术领域,具体涉及一种基于自适应卡尔曼滤波的lstm-idm跟驰特性融合方法、存储介质及设备。
背景技术:
随着汽车智能驾驶技术的发展,各种辅助驾驶系统已被广泛的使用在量产车上。如车辆自适应巡航系统(acc)等,而车辆跟驰行为是车辆日常行驶过程中最普遍的一环。目前的acc系统才用的跟驰模型从车辆动力学出发,良好的保持了车辆之间的跟车间距,但忽视了驾驶员的驾驶习惯和驾驶风格问题,无法满足驾驶员的驾驶偏好(如舒适性、动力性等)。
跟驰模型可分为理论驱动模型和数据驱动模型。理论驱动车辆跟驰模型是指基于车辆跟驰理论和车辆动力学,运用数理统计和微积分等传统数学方法建立的模型。所建立的模型中的参数具有明确物理意义,符合车辆物理特性。理论驱动模型在当前的车辆跟驰模型研究中居主导地位,并相对成熟,在许多软硬件中已经有了实际的运用。这类模型主要应用于交通流理论与控制领域,表征的是一般驾驶行为特性,通常不适合于车辆的动力学或智能辅助驾驶控制。而实际车辆行驶环境中,对于个体车辆的跟驰模型,虽然可以基于实际行驶数据对理论驱动模型的参数(例如期望速度,期望跟驰距离等)进行标定,但由于这些模型描述的是大多数驾驶行为特性,去除了驾驶员的一些个性,在表征驾驶员个体的微观驾驶行为特性时存在较大的误差。
数据驱动跟驰模型指的是近年来利用机器学习和人工智能等技术对车辆跟驰行为进行描述的方法,已成为当前车辆跟驰理论研究的热点。数据驱动车辆跟驰模型不依赖于车辆动力学等先验知识,建模相对容易,且模型结构可以依据训练时所用的样本做出改变,适用范围更广,模型精度高。但是,数据驱动模型也存在一些不足之处。首先,模型的准确度依赖于数据训练集的数量和质量。理论上,当有足够的样本数据时,所建立的模型能够获得极高的精确度,然而实际中可获得的样本数据数量和质量通常具有很大的局限性。对于一个复杂的神经网络结构,有限的样本容易是模型进入过拟合状态,失去泛化能力;反之,基于大数据的模型训练比较耗时且数据质量难以保证。此外,数据驱动模型可解释性差,可能输出不符合车辆物理特性的数据(例如:过大的加/减速度,超出限速范围等)。
技术实现要素:
为了解决上述的问题,本发明提出一种基于自适应卡尔曼融合驾驶员模型的跟车方法及系统。本发明同时引入数据驱动模型和理论驱动模型,进行互补。其中数据驱动模型选用lstm(longshort-termmemory,长短时记忆网络),理论驱动模型选用idm(theintelligentdrivermodel,智能驾驶员模型),通过大量稳态跟车数据对模型进行训练,建立了非线性输入输出模型。同时能够在线修正模型参数,融合后的模型既能有较高的准确性,又能体现驾驶员风格,符合车辆动力学特性。模型输出的加速度可用于对人-车驾驶系统舒适性、经济性、安全性进行评价,可用于自动驾驶直线跟车的自动控制,亦可用于智能辅助驾驶开发。
一种基于自适应卡尔曼滤波的lstm-idm跟驰特性融合方法,包括
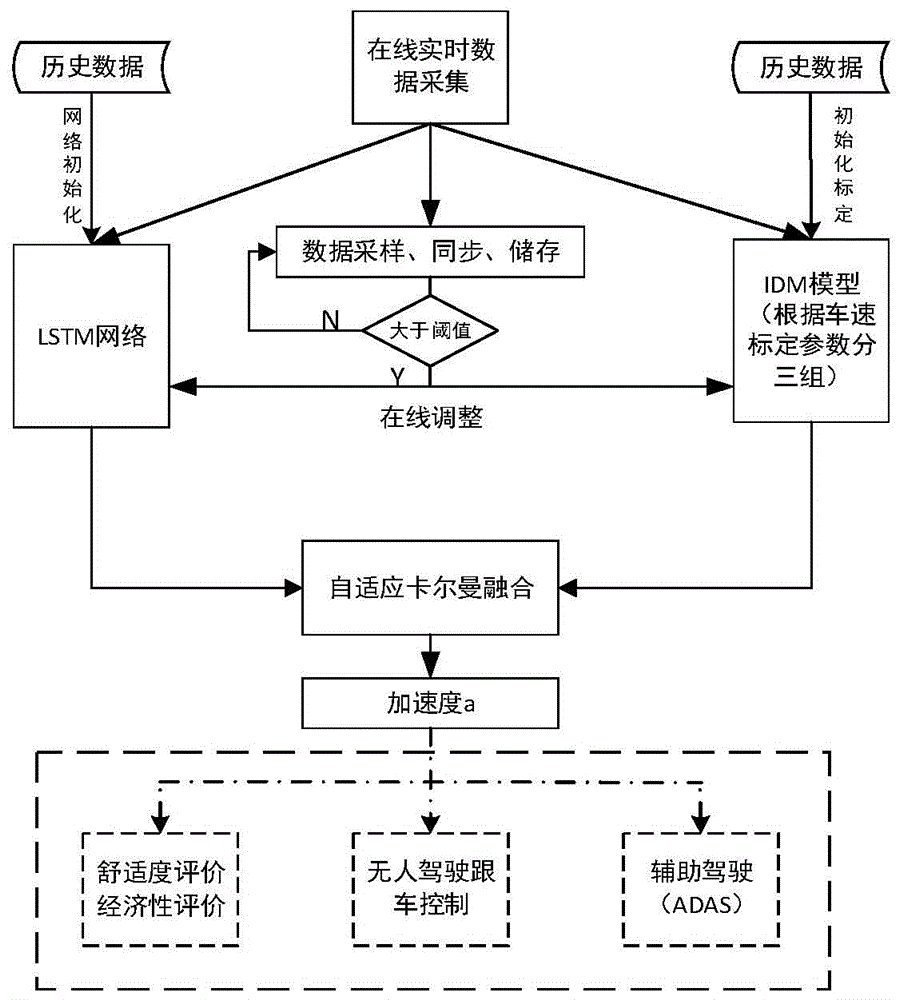
针对单个驾驶员建立lstm模型,所述lstm模型的输入为自车速度、相对速度和相对距离,输出为第一自车加速度;利用所述单个驾驶员的历史数据分批次对所述lstm模型进行训练;利用所述单个驾驶员的历史数据对idm模型进行基于遗传算法的参数标定,得到第二自车加速度;采集当前车辆实时行驶数据,分别传送到所述lstm模型和所述idm模型;当采集的数据数量达到预定的阈值时,对所述lstm模型和所述idm模型的参数进行更新;构建卡尔曼状态方程和量测方程,将所述第一自车加速度和所述第二自车加速度作为输入,得到融合后的加速度值。
进一步,所述lstm模型包括一个输入层、五个隐藏层和一个输出层,各层之间各设有一个dropout层。
进一步,所述隐藏层的层数分别是60、100、300、200、100。
进一步,所述idm模型为
式中,aα为后车加速度,vα为后车速度,
进一步,当前车辆实时行驶数据被传送到idm模型后进行如下处理:所述idm模型根据车速划分得到多种行车工况,选择实时车速对应的行车工况的标定值。
本发明另一方面提供一种存储介质,包括存储在该存储介质中的程序,在所述程序运行时控制所述存储介质所在的设备执行上述技术方案中任一项所述的基于自适应卡尔曼滤波的lstm-idm跟驰特性融合方法。
本发明还提供一种基于自适应卡尔曼滤波的lstm-idm跟驰特性融合设备,包括处理器,所述处理器用于运行程序,所述程序运行时执行上述技术方案中任一项所述的基于自适应卡尔曼滤波的lstm-idm跟驰特性融合方法。
本发明可以适用于绝大多数行车特性的建模,将驾驶员历史驾驶数据和传感器采集到的环境数据作为输入,建立非线性输出关系,输出的加速度用于描述当前人车系统的跟驰特性,该特性可用于对驾驶行为的评价、无人驾驶车辆跟驰控制参考以及车辆的智能辅助驾驶控制,如智能能量管理与控制等。前者lstm循环神经网络模型为数据驱动模型,不依赖先验的车辆动力学知识、模型精度高、泛化能力强。后者idm模型为理论驱动模型,采用数理统计和微积分等传统数学方法建立而成,其中的参数具有明确物理意义,符合车辆物理特性。采用自适应卡尔曼滤波器对两者进行融合,既提高了数据驱动模型输出的物理特性合理性,又改善了理论驱动模型的精度及可泛化能力。
附图说明
构成本发明的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的限定。在附图中,
图1为本发明一实施例基于自适应卡尔曼滤波的lstm-idm跟驰特性融合方法流程图;
图2为lstm网络cell结构图;
图3为图1实施例中lstm网络结构图;
图4为自适应卡尔曼融合过程图;
图5为仿真程序流程图;
图6为仿真结果路径轨迹与实际轨迹对比;
图7为仿真过程中参数变化与实际参数变化对比图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本实施例提供了一种基于自适应卡尔曼滤波的lstm-idm融合跟驰模型建模方法。相对于单一模型,融合跟驰模型具有更高的精度,相对理论模型更能凸显驾驶员个性,同时,改善了传统数据模型为提高模型泛化能力,无法对极值情况(例如,加速度、速度为零时的稳定状态)做到完全拟合的不足;固由融合模型建立起来的跟驰建模方法及系统针对上述几点也有极大改善。模型最终输出的加速度可用于对人-车驾驶系统舒适性、经济性、安全性进行评价,可用于自动驾驶直线跟车的自动控制,亦可用于智能辅助驾驶开发。
基于自适应卡尔曼滤波的lstm-idm跟驰特性融合方法包括以下几个步骤:
训练数据的获取。采集单个驾驶员在沿全程路线行驶过程中的速度和车辆间距信息。数据采集系统包括:车载激光测距仪、激光扫描雷达、obd-can采集器、gps和电脑。其中车载激光测距仪用来测量试验车与前车的距离,obd-can信号采集器用来采集车辆速度等车辆行驶数据,gps用以提供规划路径、交通及位置信息,电脑用于存储和同步采集的数据。跟驰过程的判定采用5s车头时距。如果与前车间距离小于以当前车速行驶5秒的距离则判定车辆处于跟驰状态,否则在数据处理过程中将其剔除。
采用最大最小标准化对数据进行归一化处理,以提升模型训练过程中梯度下降求最优解的速度,归一化方法,见下式,
yi=(xi-xmin)/(xmax-xmin)
其中,xi为各个特征数列,yi为与之对应的归一化后的数列。
lstm网络模型的建立。lstm网络内部结构包括cell单元和遗忘门、输入门、输出门3个门空单元,如图2。通过这个结构完成了旧信息的筛选和新信息合并输出,解决了rnn梯度消失的问题。lstm模型的输入为自车速度、相对速度和相对距离,输出为第一自车加速度。
遗忘门:决定从细胞状态中丢弃的信息。
ft=σ(wf·[ht-1,xt]+bf)
ht-1表示的是上一个cell的输出,xt表示的是当前细胞的输入,wf为权重系数矩阵,bf为偏置系数矩阵。σ表示sigmoid函数
输入门:决定新的信息加入到细胞状态中。
ct为0-1之间的一个数字表示当前的细胞状态。1表示“完全保留”,0表示“完全舍弃”。
输出门:确定输出值。
ot=σ(wo·[ht-1,xt]+bo)
ht=ot*tanh(ct)
其中:
ot为输出前的中间变量,ht为当前细胞输出。
在本实施例中采用的网络结构如图3所示,其中各lstm层隐藏层数分别为60,100,300,200,100,历史时间间隔长度设置为10步,每步时间间隔为1s,故lstm网络能够运用过去10秒内的信息进行训练当前时间的输出值。测试表明,考虑10秒的历史数据输入是最佳选择,过短的时间间隔会影响模型精度,增加时长也不会提升精度,反而会增加训练消耗时间。另外采用分批输入的方式进行数据训练,每批数量为32,学习率为0.001,输入层激活函数为sigmoid函数,输出层激活函数为tanh函数,损失函数为mse,优化算法为adam。为防止过拟合,设置了dropout=0.1。在lstm网络中,将最近的几个时间段内的观测到的跟车速度、相对速度、前后车车距作为输入,网络输出为该时刻的加速度值。所用lstm网络是一个针对单个驾驶员预训练过的模型,具有一般驾驶员的驾驶行为特征,并非空白模型。当有新的驾驶员时,随机时间采集跟车样本,当达到一定的数量后进行对网络权重和偏置进行修正,以促使网络能体现该驾驶员的驾驶风格。所述的修正方法并不是实时在线完成的,而是样本采集到一定数量,进行数据处理(数据筛选,异常值处理)后才会进行的在线修正,以减少功耗以及异常值引起的误差。
idm模型的标定。运用采集到的历史数据进行基于遗传算法的参数标定,优化目标为均方根误差值最小。idm模型如下式:
式中:aα为后车加速度,vα为后车速度,
式中:lα表示车长,只与车型相关。
根据idm的模型原理和车辆在数据采集过程中的特性,选取有效数据用遗传算法进行标定,目标函数为mse值,所标定结果参数有为期望速度为
lstm模型和idm模型输出融合。建立卡尔曼状态方程和测量方程如下。
xk=axk-1+wk-1
yk=cxk+vk-1
其中y=[xidm-xlstm]t,x=[δx]t,a=diag(1),c=diag(1)。w和v均属于高斯噪声。xidm为idm模型输出,xlstm为lstm模型输出。融合过程见图4。
为了全面准确地评估本实施例所提出方法的性能,进行了基于实际数据的仿真实验。仿真验证以lstm-idm融合模型为研究对象,取数据验证集中某一时刻作为轨迹起点(路径0m初始点),该时刻前后车的状态参数(相对速度,相对距离,速度)作为初始值。通过计算得到前车的速度,位移随时间变化的曲线作为仿真的环境参数(已知参数)。lstm模型中的输入需要10s时间间隔的历史数据。选用从静止启动的一个直线跟驰过程。10s间隔的初始数据为时间长度为10s的时间轴0s时的状态值。根据当前时刻的状态计算出加速度,更新下一时刻状态,不断迭代计算。实验流程图如图5所示。
由结果图6,图7可知在前车加减速过程中,模型发挥调节作用,抑制误差增大,逐步将车距控制在一定范围内,尤其在后车车速和相对速度控制上有较好的鲁棒性。整个仿真过程,融合模型有很好的跟随特性,还原了跟驰轨迹,加减速度都在合理范围内,没有出现(超车等)与原有轨迹不符的行为。随着车速的增加,两车之间的车距随之增加,这一现象也符合正常的驾驶行为。
本实施例还提供一种存储介质,包括存储在该存储介质中的程序,在所述程序运行时控制所述存储介质所在的设备执行上述技术方案中任一项所述的基于自适应卡尔曼滤波的lstm-idm跟驰特性融合方法。
本实施例还提供一种基于自适应卡尔曼滤波的lstm-idm跟驰特性融合设备,包括处理器,所述处理器用于运行程序,所述程序运行时执行上述技术方案中任一项所述的基于自适应卡尔曼滤波的lstm-idm跟驰特性融合方法。
本发明方案所公开的技术手段不仅限于上述实施方式所公开的技术手段,还包括由以上技术特征任意组合所组成的技术方案。
- 还没有人留言评论。精彩留言会获得点赞!