基于Faster-RCNN的自适应快速目标检测方法与流程
本发明属于计算机视觉和图像处理技术领域,特别是涉及一种基于faster-rcnn的自适应快速目标检测方法。
背景技术:
目标检测,也叫目标提取,是一种基于目标几何和统计特征的图像分割,它将目标的分割和识别合二为一,其准确性和实时性是整个系统的一项重要能力。目标检测是计算机视觉中一个重要问题,在行人跟踪、车牌识别、无人驾驶等领域都具有重要的研究价值。近年来,随着深度学习对图像分类准确度的大幅度提高,基于深度学习的目标检测算法逐渐成为主流。
自目标检测的概念提出以来,国内外学者针对这个问题进行了不懈探索。传统的目标检测算法,多是基于滑动窗口的框架或是根据特征点进行匹配。自2012年alexnet在当年度imagenet大规模视觉识别挑战赛中一举夺冠,且效果远超传统算法,将大众的视野重新带回到深度神经网络。2014年r-cnn的提出,使得基于cnn的目标检测算法逐渐成为主流。
技术实现要素:
为了解决上述问题,本发明的目的在于提供一种基于faster-rcnn的自适应快速目标检测方法。
为了达到上述目的,本发明提供的基于faster-rcnn的自适应快速目标检测方法包括按顺序进行的下列步骤:
(1)将原始图像输入底层特征提取网络中,经过若干次卷积得到特征图;
(2)将上述特征图输入到区域建议网络的卷积层中进行训练,通过预先设置的锚点,建立特征图到原始图像的映射,即特征图上某一像素点对应于原始图像中的k个候选区域;
(3)对上述所有候选区域进行重叠度的评分,然后自适应选取评分在300-2000名之间的候选区域并输入到区域建议网络的分类和回归层中进行训练,得到含有目标的候选区域;
(4)将上述含有目标的候选区域和特征图一起送入区域建议网络的最终分类回归层,采用roi池化操作来判断出该候选区域中的目标具体为哪一类目标,由此获得最终识别结果。
在步骤(1)中,所述的底层特征提取网络采用resnet58残差网络。
在步骤(2)中,所述的通过预先设置的锚点,建立特征图到原始图像的映射的方法是:通过预先设置的锚点,在此基础上生成若干个候选区域,特征图上的每一个像素点对应于原始图像中的某一个区域,然后对此区域进行调整,将该区域进行长宽比分别为1:1,1:2,2:1的三种设置,锚点的大小分别为大中小的三种不同设置,因此,特征图上每一个像素点对应于原始图像中的9个候选区域,即k等于9。
在步骤(3)中,所述的自适应选取评分在300-2000名之间的候选区域的方法是:每隔n次训练计算出回归损失的平均值total_loss,认为每隔n次训练,回归损失的平均值total_loss缩小一半和自增一倍为合理变化抖动区间,超过这个区间,认为需要反馈调节;当回归损失的平均值total_loss翻倍及其以上时,将候选区域的数量自增1+number_rate_up倍;当回归损失的平均值total_loss缩小一半及其更小时,适当减少候选区域的数量,将候选区域的数量变为1-number_rate_down倍,即让候选区域的数量在300-2000这个区间内自适应改变。
本发明提供的基于faster-rcnn的自适应快速目标检测方法具有如下优点:
1、将底层特征提取网络从vgg网络改变成残差网络,使网络深度更深更高,提取的特征自然更抽象更全面,并由原本的16层上升到50层,提高了目标检测的识别率。
2、提出一种具有区域数目调节层的快速目标检测方法对经典的区域建议网络进行改善。在训练时,引入区域数目调节层,实时判断当前训练效果,根据当前训练效果调节候选区域数量,训练结束时确定最佳候选区域数量。通过训练结果反馈调节,使候选区域的数量在300-2000之间动态变化,实验表明,相对于传统faster-rcnn网络,速率提升了18个百分点,识别率提高了3个百分点,对环境的适应性更强,因此有效减少了训练时间,并且识别率更高。
附图说明
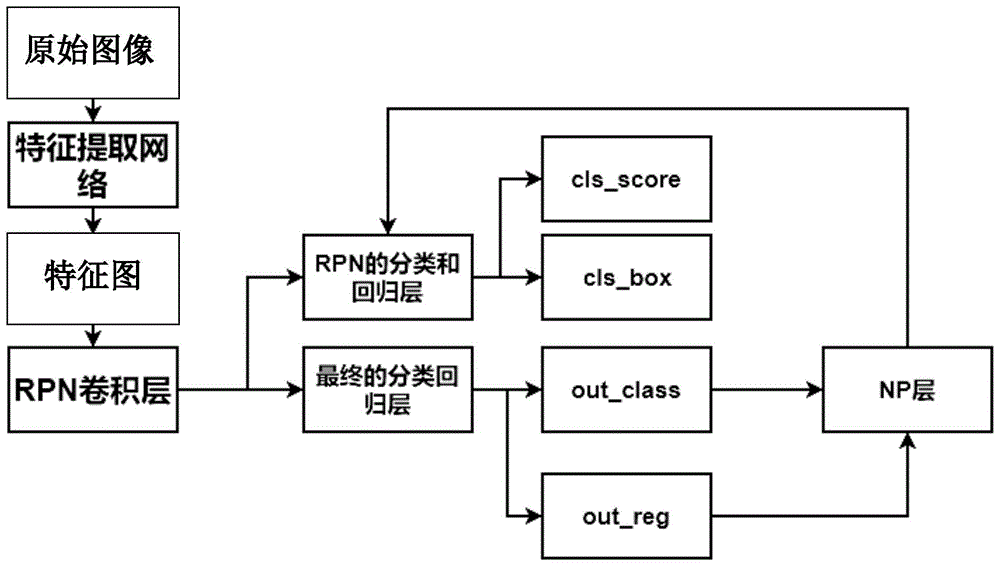
图1是本发明提供的基于faster-rcnn的自适应快速目标检测方法整体流程图;
图2是本发明中提供的基于faster-rcnn的自适应快速目标检测方法中所采用的底层特征提取网络框图;
图3是本发明提供的基于faster-rcnn的自适应快速目标检测方法提取的人脸感兴趣区域结果示意图。
具体实施方式
下面结合附图和具体实施例对本发明提供的基于faster-rcnn的自适应快速目标检测方法进行详细说明。
如图1所示,本发明提供的基于faster-rcnn的自适应快速目标检测方法包括按顺序进行的下列步骤:
(1)将voc2007数据集中的原始图像输入到如图2所示的作为底层特征提取网络的resnet58残差网络中,经过若干次卷积得到特征图;传统的做法是选取vgg16作为底层特征提取网络。由于随着网络层数的增加,训练结果收敛性越来越差,甚至导致网络层数越高,训练效果越差。为了解决网络的退化问题,本发明采用resnet58残差网络作为底层特征提取网络,使得底层特征提取网络的层数由16层变为58层,从而可以极大提升训练效果。底层特征提取网络的结构如表1所示。
(2)将上述特征图输入到区域建议网络(rpn)的卷积层中进行训练,通过预先设置的锚点,建立特征图到原始图像的映射,即特征图上某一像素点对应于原始图像中的k个候选区域;
faster-rcnn的核心思想是通过预先设置的锚点,在此基础上生成若干个候选区域,特征图上的每一个像素点对应于原始图像中的某一个区域,然后对此区域进行调整,在本发明中将该区域进行长宽比分别为1:1,1:2,2:1的三种设置,锚点的大小分别为大中小的三种不同设置,因此,特征图上每一个像素点对应于原始图像中的9个候选区域,即k等于9。原始图像中的候选区域数量为特征图中像素点数量的9倍,可以认为需要被检测的目标被所有候选区域穷尽。将这种特征图上设置好对应关系的像素点称为锚点。这些像素点类似于一个个船锚固定在海洋上,通过这些船锚按图索骥即可寻找到船只,即通过这些锚点来对应原始图像上的候选区域。
(3)对上述所有候选区域进行重叠度的评分,然后自适应选取评分在300-2000名之间的候选区域并输入到区域建议网络的分类和回归层中进行训练,得到含有目标的候选区域;
传统的做法是对所有候选区域进行重叠度的评分,重叠度和评分负相关。然后选取评分在前2000名的候选区域进行训练。由于步骤(2)中生成的候选区域数量太多,这样容易造成训练开销太大且消耗时间太多,因此本发明在此进行了优化,并在训练过程中引入了np(建设数量)层对训练结果进行反馈,以对候选区域的数量进行自适应调整,舍弃了大部分的候选区域,从而缩短了训练时间。自适应选取候选区域的方法是每隔n次训练计算出回归损失的平均值total_loss,认为每隔n次训练,回归损失的平均值total_loss缩小一半和自增一倍为合理变化抖动区间,超过这个区间,认为需要反馈调节;当回归损失的平均值total_loss翻倍及其以上时,将候选区域的数量自增1+number_rate_up倍;当回归损失的平均值total_loss缩小一半及其更小时,适当减少候选区域的数量,将候选区域的数量变为1-number_rate_down倍,即让候选区域的数量在300-2000这个区间内自适应改变,可使运算速率提高18%,本发明方法与其空白对照组的具体结果如表2所示。最终得到含有目标的候选区域。
(4)将上述含有目标的候选区域和特征图一起送入区域建议网络的最终分类回归层,采用roi(感兴趣区域)池化操作来判断出该候选区域中的目标具体为哪一类目标,由此获得最终识别结果。图3是本发明提供的基于faster-rcnn的自适应快速目标检测方法提取的人脸感兴趣区域结果示意图。
表1底层特征提取网络的结构
表2
- 还没有人留言评论。精彩留言会获得点赞!