一种提高人脸识别准确性的二次识别方法与流程
本发明涉及人脸图像识别技术领域,特别涉及一种提高人脸识别准确性的二次识别方法。
背景技术:
随着科技的不断发展,特别是计算机视觉技术的发展,人脸识别技术广泛应用于信息安全、电子认证等各个领域,图像特征提取方法具有良好的识别性能。人脸识别是指基于已知的人脸样本库,利用图像处理和/或模式识别技术从静态或者动态场景中,识别一个或多个人脸的技术。但是目前的人脸识别上技术具有提取处理较差、识别不够准确的问题,特别是人脸识别中相近似的不同人脸识别方法仍存在识别效率较低的问题。
技术实现要素:
为了解决上述现有技术中存在的问题,本发明的目的在于:对面部局部特征进行再次的比较,提高识别准确性。
本发明提供一种提高人脸识别准确性的二次识别方法,包括以下步骤:
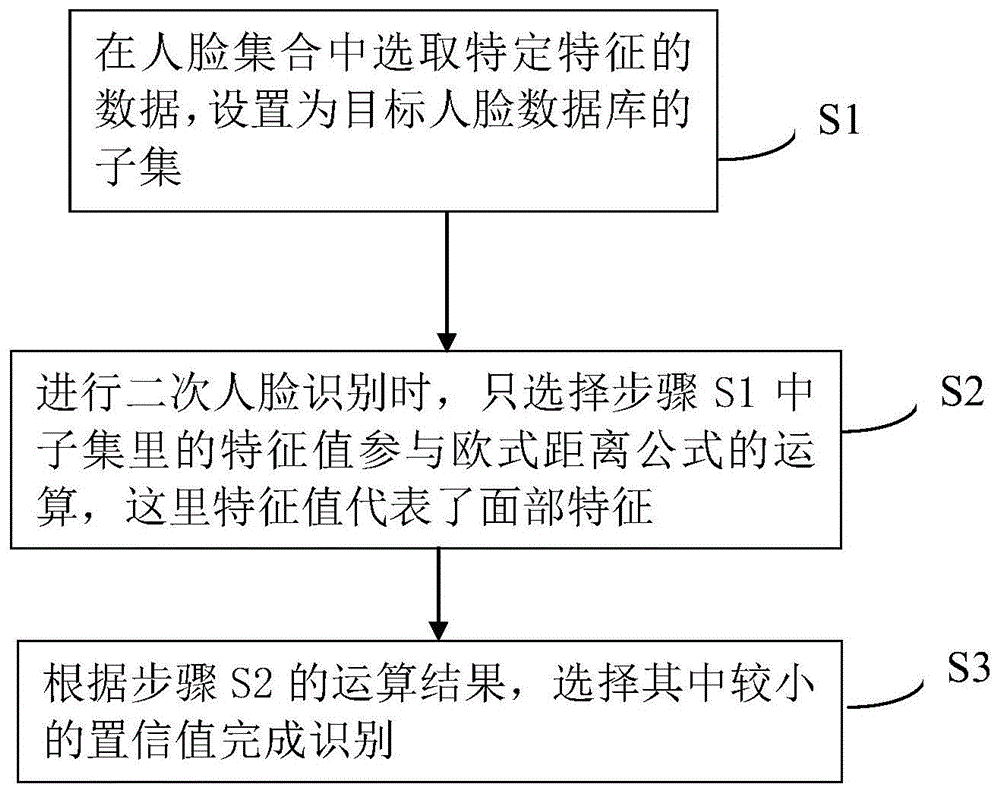
s1,在人脸集合中选取特定特征的数据,设置为目标人脸数据库的子集;s2,进行二次人脸识别时,只选择步骤s1中子集里的特征值参与欧式距离公式的运算;
s3,根据步骤s2的运算结果,选择其中较小的置信值完成识别。
所述的欧式距离公式为:
两个n维向量a(x11,x12,…,x1n)与b(x21,x22,…,x2n)间的欧氏距离:
当所述的欧式距离公式的结果数值越小,说明比较的这两张图的局部越接近;这里特征值代表了面部特征。
所述的特定特征是人脸的某一局部特征。
所述的特定特征的数据是长相近似的两人的人脸局部特征中差异大的特征值。
所述的人脸局部特征包括眼睛、眉毛、嘴巴、鼻子、耳朵。
步骤s3中所述的完成识别是根据运算结果中较小的置信值决定识别出来的是哪个人。
本申请的优势在于:当我们经过一次识别,无法准确的区别近似的两个人时,需要进行二次识别,只需针对人脸部分的特征进行再比较,便能够准确的区分具体是谁。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,并不构成对本发明的限定。
图1是本发明的方法的流程框图示意图。
具体实施方式
目前人脸识别技术领域的术语包括:
1、人脸检测:将一张图片输入到一个检测器中,将人脸的眼睛、鼻子、嘴和人脸外接矩形的坐标信息提取出来,如果没有人脸,不会输出任何信息。
2、人脸识别库:是用来训练人脸识别模型的一种样本库。在不会产生混淆的情况下,可以简称为样本库。
3、人脸识别模型:通过使用人脸识别库来训练,可以得到人脸识别模型。使用人脸识别模型,可以对人脸提取人脸的特征值。
4、人脸的特征值:是一张人脸图片,通过人脸识别模型处理后生成的一维数据,这个数据称为该人脸的特征值。同一人的不同人脸图片,特征值间的空间距离很小。
本申请是个基于一种面部特征点估计(facelandmarkestimation)的方法的改进方法。这个方法由瓦希德·卡奇米(vahidkazemi)和约瑟菲娜·沙利文(josephinesullivan)在2014年发明的方法。
面部特征点估计方法是基于面部的68个关键点(或特征点landmark)进行计算,得出128个测量值,这128个测量值可以代表面部特征,我们也把它称为特征值。我们为不同的脸图生成对应的特征值,然后我们比较两张脸的办法是计算它们特征值的欧式距离(置信值)。
当这个距离越小,说明这两张图越可能为同一个人。
这里特征值其实代表了面部特征,本发明旨在对面部局部特征进行再次的比较,提高识别准确性。
例如,一对双胞胎,他们只有右眼有细微的差别,其他特征都完全一样,因此我们采用原来的算法得出的这两人脸部比较的置信值已经很高,应用逻辑会把他们当做一个人。因此我们需要进行二次识别,只针对右眼这部分特征进行再比较,以便区分具体是谁。
一种提高人脸识别准确性的二次识别方法,包括以下步骤:
s1,在人脸集合中选取特定特征的数据,设置为目标人脸数据库的子集;
s2,进行二次人脸识别时,只选择步骤s1中子集里的特征值参与欧式距离公式的运算;
s3,根据步骤s2的运算结果,选择其中较小的置信值完成识别。
所述的欧式距离公式为:
两个n维向量a(x11,x12,…,x1n)与b(x21,x22,…,x2n)间的欧氏距离:
当所述的欧式距离公式的结果数值越小,说明比较的这两张图的局部越接近;这里特征值代表了面部特征。
所述的特定特征是人脸的某一局部特征。
所述的特定特征的数据是长相近似的两人的人脸局部特征中差异大的特征值。
所述的人脸局部特征包括眼睛、眉毛、嘴巴、鼻子、耳朵。
步骤s3中所述的完成识别是根据运算结果中较小的置信值决定识别出来的是哪个人。
本发明的原理是放大人脸的局部特征的效果,并在目标人脸集合的子集中做局部特征比较,从而更精确的区分是哪个人。这是一种识别识别的办法,例如两个人中眼睛、鼻子、嘴都很相像,但是可以通过差异最大的耳朵进行识别。
当然,本发明还可以包括进一步的识别,例如100个人中眼睛大的有10人,嘴巴大的有20人,既眼睛大又嘴巴大的有3人,如此筛选理论上只要次数足够多总能精确的筛选出正确的人。
本方法实现还涉及神经网络训练过程,具体过程如下。
1,假设我们的人脸数据库装了100个人的面部特征;
2,在一次识别过程中,我们用a图识别出这个100个人有两个人r1和r2都是非常匹配的,因此机器无法区分他们,这时通过人工参与,告诉机器正确答案,r1才是a图上的人;
3,机器这时会提交一个学习任务,在今后会不断的训练识别r1和r2;4,这个学习任务是这样进行的,他会定期拍3张照片,两张r1的不同的照片p1,p2,一张r2的照片p3;
5,经过多次重复的训练,找出p1与p2中差异比较小,而p1跟p3差异比较大的那些特征值,得到集合s1;
6,在之后的识别中,首先还是按原来的算法在100个人中识别出r1和r2,但现在仍然不知道到底是r1还是r2;
7,这时候启动二次识别算法,只用s1里面的特征值参与欧式距离的运算,根据运算结果中较小的置信值决定识别出来的是r1还是r2;
8,同理如果第一次识别找出来的人多于2个,我们仍然可以用以上办法二次识别,如果二次识别结果仍然大于等于2人的话,我们还可以进行三次识别。
本发明的创造性在于对原来算法的改进,做二次以上的比较,并且比较是基于原来算法的结果,并且比较是局部特征的比较而并非重复原来的算法,并且局部比较的特征选取采用了自动学习的训练机制,具有较高的科学性。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明实施例可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!