基于深度递归非负矩阵分解的音频场景分类方法及系统与流程
1.本发明涉及音频分类领域,具体涉及基于深度递归非负矩阵分解(nonnegative matrix factorization,nmf)的音频场景分类方法及系统。
背景技术:
2.音频作为多媒体信息的重要组成部分,对其分析、检索和使用已成为日常生活中不可避免的问题。如何对海量音频信息进行高效管理、分析和利用已然成为音频信号处理领域一个极富挑战的问题。音频场景分类是对音频的初步分析,是音频高效管理和充分使用的前提。它关注如何让计算机能够分辨场景中的各种声音,识别特定场景中的基本声学要素,并能根据这些要素对新场景归类。
3.传统的音频分类系统主要分为两步操作:首先,利用变换从待分析信号中提取出频谱、基频、音色、共振峰等声学特征;其次,高斯混合模型(gmm)、隐马尔可夫模型(hmm)或支持向量机(svm)被用作后端分类器完成对信号的归类。
4.近年来,随着深度学习的发展,人们开始研究大数据驱动的音频场景分类算法。一种直接的方法就是用深度神经网络(dnn)替换gmm作为后端分类器。由于dnn 能够通过改变隐含层数量增加模型复杂度,并通过层次化结构实现特征的多次变换, dnn通常表现出比传统分类器更好的性能。另一种方式则采用卷积神经网络(cnn) 作为前端特征提取器,后端则采用dnn或者cnn作为分类器。全网络结构允许模型进行联合训练,从而进一步提升系统性能。
5.基于dnn的音频场景分类算法充分利用了网络的强大建模能力,但是dnn的不可解释性极大地增加了其优化和训练过程的复杂性。与之相反,由于nmf是基于一组统计模型,因而它易于扩展,如稀疏性正则、卷积化等。但是,nmf在测试阶段需要解迭代优化问题,这会增加推理所需时间。
技术实现要素:
6.本发明的目的在于克服上述缺陷,在借鉴深度递归神经网络结构的基础上,将 nmf的迭代优化计算利用网络进行展开(unfolding)。由于采用深度递归结构的nmf 能够利用反向传播算法进行高效计算,从而提高了nmf在测试/训练阶段的计算速度,使得nmf能够利用海量数据进行训练。另外,相较于dnn,nmf能够给建模提供更好的解释性。结果表明,在少量训练数据的情况下,深度递归nmf比dnn 具有更好的泛化能力;而在大数据情况下,性能于dnn相当。
7.为实现上述目的,本发明提出了一种基于深度递归非负矩阵分解的音频场景分类方法,该方法包括:
8.将待分类的音频信号按照贝叶斯信息准则进行音频场景切分;
9.将切分后的每一段音频划分为多个块,每个块包括多个音频帧;以块为单位分别输入多个预先训练好的深度递归nmf网络,得到每块音频在不同子空间中的展开特征;将不
同子空间中的展开特征拼接为一个长特征向量,输入支持向量机,获得每块音频的类别判别结果;
10.计算该段音频所有块的类别判别结果的均值,由此得到该段音频的所属类别。
11.作为上述方法的一种改进,所述深度递归nmf网络为一个改进的堆叠rnn,包括k个处理层,每个处理层包括t个处理单元;对应处理每个块中的t个音频帧: x1,x2,
…
,x
t
;
12.其中网络的第k层的第i个处理单元的输出为:
[0013][0014][0015]
是一个n维的行向量
[0016][0017][0018]
其中,1≤i≤t;w
(k)
表示第k层对应的字典,是w
(k)
的转置,i为单位矩阵,α
(k)
是第k层对应的非负权重,b=λ/α
(k)
为截断门限,λ是一个控制网络输出特征稀疏性的参数;当k=1时,
[0019][0020]
其中,表示权重系数;
[0021]
第k个处理层的每个单元的输入为则所述展开特征为第k层输出组成的向量:
[0022][0023]
作为上述方法的一种改进,所述方法还包括对深度递归nmf网络进行训练的步骤,具体包括:
[0024]
基于各类干净音频信号和稀疏nmf,利用乘积更新准则训练得到相应干净音频字典w
(clean)
;
[0025]
利用实际带噪数据,训练字典w=[w
(clean)
,w
(noise)
];其中,w
(noise)
为噪声字典;在采用稀疏nmf训练过程中,保持w
(clean)
不变,只更新w
(noise)
;w= [w
(1)
,w
(2)
,
…
,w
(k)
];
[0026]
利用获得的字典w和预先设定的非负权重α和初始化深度递归nmf网络;其中,是初始迭代点;α=[α
(1)
,α
(2)
,α
(k)
];
[0027]
为了训练深度递归nmf网络,解如下的优化问题:
[0028][0029]
其中,训练深度递归nmf参数θ包括:字典w,非负权重α和训练数据为 {x
i
,y
i
}
i=1:i
;i是音频训练样本总数,x
i
和y
i
分别表示第i个训练样本的网络输入及其期望输出;
是代价函数;是神经网络实际输出;θ是神经网络参数;
[0030]
代价函数选为:
[0031][0032]
其中,x
f,t
为输入信号x
t
的第f个频率点的频谱;y
f,t
是干净信号的第t帧,第f个频率点的频谱;m
t,f
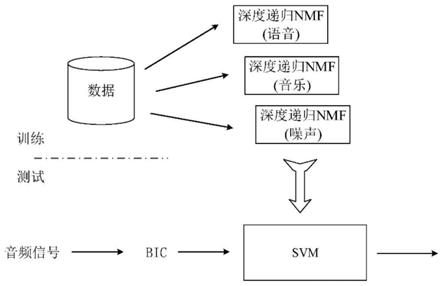
是取值范围在0和1之间的待估计掩码值,输入信号x中假定含有一定程度噪声干扰;y是干净信号。
[0033]
作为上述方法的一种改进,所述方法还包括:
[0034]
将非负权重α用新变量代替:
[0035][0036]
当求解出后,计算非负权重α:
[0037][0038]
其中,ε>0,exp(
·
)和ln(
·
)分别表示指数和对数运算;
[0039]
将字典w用新变量代替:
[0040][0041]
当求解出后,计算字典w:
[0042][0043]
其中,表示矩阵的第f行;exp(
·
)和ln(
·
)分别表示指数和对数运算。
[0044]
本发明还提供了一种基于深度递归非负矩阵分解的音频场景分类系统,所述系统包括:
[0045]
切分模块,用于将待分类的音频信号按照贝叶斯信息准则进行音频场景切分;
[0046]
音频块的类别判别模块,用于将切分后的每一段音频划分为多个块,每个块包括多个音频帧;以块为单位分别输入多个预先训练好的深度递归nmf网络,得到每块音频在不同子空间中的展开特征;将不同子空间中的展开特征拼接为一个长特征向量,输入支持向量机,获得每块音频的类别判别结果;
[0047]
音频段类别计算模块,用于计算该段音频所有块的类别判别结果的均值,由此得到该段音频的所属类别。
[0048]
作为上述系统的一种改进,所述深度递归nmf网络为一个改进的堆叠rnn,包括k个处理层,每个处理层包括t个处理单元;对应处理每个块中的t个音频帧: x1,x2,
…
,x
t
;
[0049]
其中网络的第k层的第i个处理单元的输出为:
[0050][0051][0052]
是一个n维的行向量
[0053][0054][0055]
其中,1≤i≤t;w
(k)
表示第k层对应的字典,是w
(k)
的转置,i为单位矩阵,α
(k)
是第k层对应的非负权重,b=λ/α
(k)
为截断门限,λ是一个控制网络输出特征稀疏性的参数;当k=1时,
[0056][0057]
其中,表示权重系数;
[0058]
第k个处理层的每个单元的输入为则所述展开特征为第k层输出组成的向量:
[0059][0060]
作为上述系统的一种改进,所述系统还包括深度递归nmf网络训练模块,用于对各类深度递归nmf网络进行训练;具体过程为:
[0061]
基于各类干净音频信号和稀疏nmf,利用乘积更新准则训练得到相应干净音频字典w
(clean)
;
[0062]
利用实际带噪数据,训练字典w=[w
(clean)
,w
(noise)
];其中,w
(noise)
为噪声字典;在采用稀疏nmf训练过程中,保持w
(clean)
不变,只更新w
(noise)
;w= [w
(1)
,w
(2)
,
…
,w
(k)
];
[0063]
利用获得的字典w和预先设定的非负权重α和初始化深度递归nmf网络;其中,是初始迭代点;α=[α
(1)
,α
(2)
,α
(k)
];
[0064]
为了训练深度递归nmf网络,解如下的优化问题:
[0065][0066]
其中,训练深度递归nmf参数θ包括:字典w,非负权重α和训练数据为 {x
i
,y
i
}
i=1:i
;i是音频训练样本总数,x
i
和y
i
分别表示第i个训练样本的网络输入及其期望输出;是代价函数;是神经网络实际输出;θ是神经网络参数;
[0067]
代价函数选为:
[0068][0069]
其中,x
f,t
为输入信号x
t
的第f个频率点的频谱;y
f,t
是干净信号的第t帧,第f个频率点的频谱;m
t,f
是取值范围在0和1之间的待估计掩码值,输入信号x中假定含有一定程度噪声干扰;y是干净信号。
[0070]
本发明的优势在于:
[0071]
本发明的方法将深度nmf用于音频场景分类,通过探索相邻帧之间nmf系数的递归关系,降低模型复杂度,提高泛化能力。
附图说明
[0072]
图1为本发明的方法的流程图;
[0073]
图2为本发明的深度递归nmf网络的示意图;
[0074]
图3为本发明的深度递归nmf网络的第k层第t个单元的处理过程示意图;
[0075]
图4为现有技术的深度堆叠rnn的示意图;
[0076]
图5为图4的深度堆叠rnn的一个单元的处理过程的示意图。
具体实施方式
[0077]
下面结合附图和具体实施例对本发明的技术方案进行详细的说明。
[0078]
深度递归nmf借鉴了deep unfolding的思想:通过将统计模型的推理过程转换成深度网络结构,使得网络能够利用反向传播算法对进行有监督训练。
[0079]
假定输入信号幅度谱为f
×
t的矩阵x,nmf假设x能够被近似为其中,w(f
×
n维)和h(n
×
t维)均是非负矩阵;w是非负字典,h基的非负激活系数,f信号频点数,t信号帧数,n字典中的基数量。
[0080]
nmf对公式(1)进行优化,求得w和h。注意到,h通过1-范数操作被强制稀疏,以保证得到有意义的解。
[0081][0082]
公式(1)中,是贝塔-散度度量,β取为2:在半监督语音分离应用中,语音字典w
(clean)
首先从纯净信号中训练得到;接着通过在含噪数据上更新字典w=[w
(clean)
,w
(noise)
]的噪声对应部分和激活矩阵 h=[h
(clean)
,h
(noise)
],得到噪音字典w
(noise)
。在测试阶段,保持字典w不变,更新激活矩阵h,以使得(4)最小。此时,h可以理解为x在字典w所张成的空间中的投影;h
(v)
和h
(y)
分别为噪声和语音在空间w中的表示。
[0083]
为了加快模型收敛,nmf优化采用了一种改进的梯度下降算法:
[0084]
通常,公式(1)的求解通过乘积更新来完成。但是,乘积更新过程收敛缓慢,因此本发明采用迭代软门限方法(iterative soft-thresholding algorithm,ista)进行 nmf的优化。ista是改进的梯度下降法,它通常用于解如下优化问题:
[0085][0086]
其中,f是一个平滑函数,g是一个非平滑函数。ista以1/k的速度进行收敛,而梯度下降法以收敛,k表示迭代次数。
[0087]
表1给出了和时,ista算法的流程。其中, 1/α表示步长,表示应用公式(6)于向量b是一个实值门限。
[0088][0089]
表1:基本ista算法
[0090][0091]
在测试阶段,能够利用ista算法独立求解h的每一帧,则是h的第t帧。为了简化问题,k取为固定值。然而,对每一帧独立计算ista忽略了相邻帧之间的相关性。因此,采用递归形式的ista算法(见表2),使得第t帧的迭代初始值能够考虑前q帧的输出此处是现有算法的一个介绍,主要用于帮助理解递归ista算法。
[0092]
表2:递归ista算法
[0093][0094][0095]
如图1所示,本发明提出了一种基于深度递归非负矩阵分解(nonnegative matrix
ꢀꢀ
factorization,nmf)的音频场景分类方法,该方法包括:
[0096]
步骤1)信号首先被贝叶斯信息准则(bic)进行音频场景切分;
[0097]
步骤2)对切分后的每一段音频,经过各个深度递归nmf网络进行相应特征提取;
[0098]
所述深度递归nmf网络的类型包括:语音、音乐、噪声、鸟鸣、流水声等。
[0099]
步骤3)将nmf网络输出系数的均值作为输入向量,用支持向量机(svm)对所属音频类别进行判断。
[0100]
深度递归nmf网络分为训练和测试两个阶段。在训练阶段,各类音频被分别用于递归nmf网络训练,得到针对特定音频的深度网络。在测试阶段,各音频网络被作为特征提取器,待检测音频分别通过各网络得到激活输出。输出的大小,反映了输入在音频网络空间中的表示情况,而重建误差反映了基对信号表示的质量,进而体现了输入音频属于该类别的概率。
[0101]
对于深度递归nmf,图2和图3给出了其展开后的网络结构。网络的递归形式,通过将t时刻之前的q个解的凸组合作为该时刻迭代初始值来体现。由于非负ista的非线性激活函数是relu,深度递归nmf网络可以通过将堆叠rnn进行修改后得到,
[0102]
改进主要体现在以下两部分。
[0103]
1、对每时刻t,输入直接连接到网络的每个节点;
[0104]
2、网络中的唯一时间递归存在于,将t时刻之前的q个顶层结点连接到t时刻的底层节点。为了对比,图4和图5给出一个典型的堆叠rnn的结构,其中网络的第k层为:
[0105][0106]
其中,σ
b
是激活函数;对于第一层,
[0107]
为了训练深度递归nmf网络,解如下的优化问题:
[0108][0109]
其中,训练数据{x
i
,y
i
}
i=1:i
;是训练代价函数;是神经网络输出;θ是神经网络权重。反向传播算法被用于网络训练。
[0110]
对于场景分类问题,神经网络尝试去重建输入信号x。为了增加网络的鲁棒性,借鉴语音分离中的掩码思想,代价函数选为:
[0111][0112]
其中,输入信号x中假定含有一定程度噪声干扰;y是干净信号;m是待估计的掩码。为了体现信号的在基空间的展开质量,网络输出一维表示重建误差的比例。
[0113]
由于深度递归nmf是一个优化问题,考虑使用稀疏nmf估计出迭代的初始值。整个训练过程如下:
[0114]
1、利用各类干净音频信号和稀疏nmf的乘积更新准则训练相应干净字典 w
(clean)
;
[0115]
2、利用实际带噪数据和稀疏nmf算法,训练字典w=[w
(clean)
,w
(noise
)]。训练过程中,保持w
(clean)
不变,只更新噪声字典w
(noise)
;
[0116]
3、初始化深度递归nmf:利用获得的字典w和ista所需的优化参数α和
[0117]
4、训练深度递归nmf参数利用方程(5)和(6)。
[0118]
当初始化网络后,ista算法中α须恰当选择,以使得k步迭代(此处迭代就是 nmf中的迭代次数,对应于深度递归nmf的层数)。具后,模型达到一个较好的性能。实验发现,当nmf中基向量的个数n=100时,α取为50;n=1000时,α取为400。为了保证权重α的非负性要求,算法没有直接优化α。引入新变量被初始化为ln( ε+α),则就是待优化的模型权重。同理,对于w,引入新变量令则算法优化归一化模型权重其中,ε是一个很小的正数,以保证对数运算正确;表示矩阵的第f行;exp(
·
)和ln(
·
)分别表示指数和对数运算。
[0119]
最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制。尽管参照实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,对本发明的技术方案进行修改或者等同替换,都不脱离本发明技术方案的精神和范围,其均应涵盖在本发明
的权利要求范围当中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1