一种基于迁移学习的实体关系联合抽取方法与流程
本发明涉及自然语言处理技术领域,具体来说,涉及一种基于迁移学习的实体关系联合抽取方法。
背景技术:
实体及其关系的抽取方法主要分为串联抽取方法及联合抽取方法。其中,联合抽取方法能够整合实体及其关系之间的信息。随着深度学习在nlp任务上的成功,神经网络也广泛应用到实体、关系事实的提取。2016年“基于lstm的序列和树结构端到端关系提取”(计算语言学协会第54届年会论文集)为减少人工抽取特征工作,提出基于神经网络的端到端模型,但因在模型实现过程分开抽取实体及其关系而导致信息冗余。“基于全局优化的端到端神经关系提取”(2017年自然语言处理经验方法会议论文集,1730-1740页)采用端到端的模型将关系抽取问题转化为了表格填充问题。
但目前大多数关系抽取的标注数据不稳定,有标注的数据通用性比较低,使用场景也经常更新。迁移学习能够让模型在大量通用数据上进行预训练,再将预训练的模型迁移到具体的下游任务中,从而加快并优化模型的学习效率。如google提出的bert,先利用大规模无监督数据预训练神经网络模型,再用目标数据对模型进行微调,以适应当前任务,在中文数据方面,基于迁移学习对实体-关系联合抽取的研究还很匮乏。
技术实现要素:
针对相关技术中的上述技术问题,本发明提出一种基于迁移学习的实体关系联合抽取方法,能够克服现有技术的上述不足。
为实现上述技术目的,本发明的技术方案是这样实现的:
一种基于迁移学习的实体关系联合抽取方法,该实体关系联合抽取方法,包括以下步骤:
将百度公开的基于schema的中文信息抽取数据集作为数据源;
对输入句子先进行预处理;
使用bert预训练模型,将tokenembedding、segmentembedding和positionembedding三种向量合并组成embedding层作为bert的输入;
将embedding层的向量输入到编码器中,得到编码序列;
将字向量传入全连接的dense层和sigmoid激活函数,得到主实体的编码向量;
对于得到的主实体集合,随机采样一个主实体,获得其编码向量;
将主实体的编码向量再传到全联接的dense网络,对于每一种关系类型都构建两个客实体的首尾向量,预测出客实体和关系类型,与主实体结合,最终得到三元组;
使用precision,recall以及f1值来作为模型预测结果的评价标准。
进一步地,所述基于schema的中文信息抽取数据集包含20万条标注数据及50种关系类型。
进一步地,所述主实体的编码由首尾两个向量构成,首尾两个向量分别标记主实体的首尾位置。
进一步地,所述编码器为双向transformer编码器。
进一步地,对输入句子预处理的具体步骤为:将句子按照字符分隔开后,在句子首尾分别加上cls和sep标记,将空格类字符用unused1表示,非空格类字符用unk表示。
本发明的有益效果:通过将迁移学习应用在中文文本的实体-关系联合抽取问题中,提出了一个新的端到端的神经网络模型,使用bert模型作为编码器;设计了一种新型解码结构解决了三元组提取中多个主实体对应多个客实体的问题;能够直接对三元组进行建模,从非结构化文本中提取出三元组信息,显著地提高了关系抽取的效率和准确率;能够应用于海量中文文本的知识自动化抽取,为中文知识图谱自动化构建提供基础。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
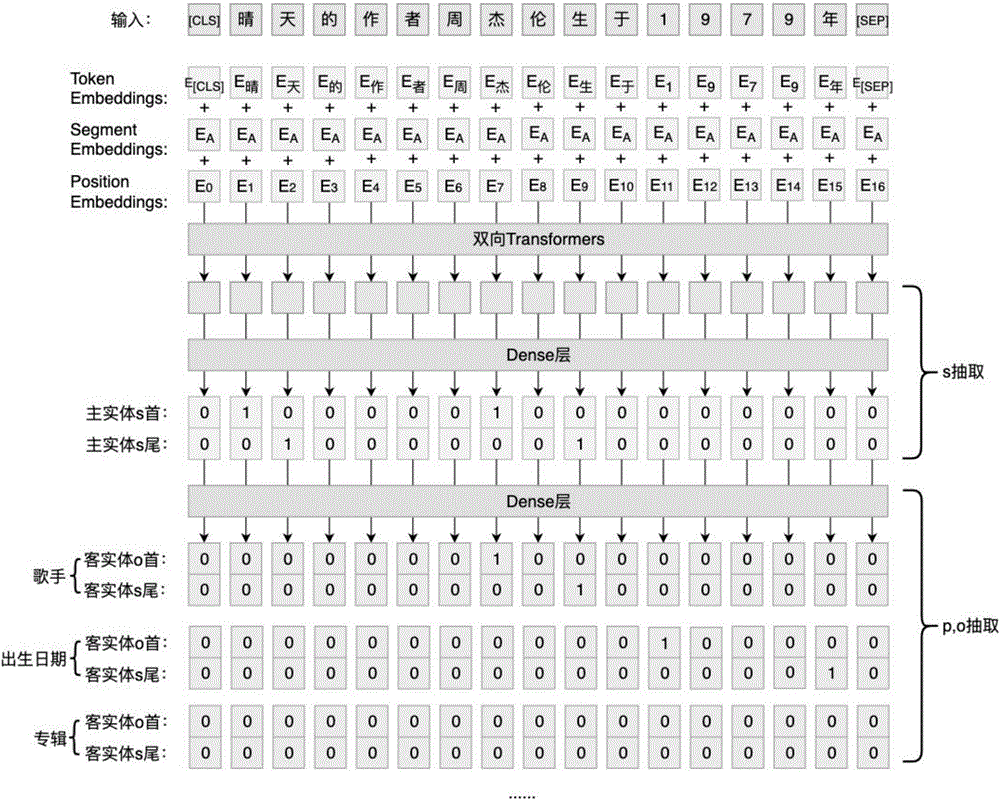
图1是根据本发明实施例所述的实体-关系联合抽取模型示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,根据本发明实施例所述的基于迁移学习的实体关系联合抽取方法将迁移学习应用在中文文本的实体-关系联合抽取问题中,提出了一个新的端到端的神经网络模型:
数据集以及标注方法
(1)数据源
数据源为百度公开的基于schema的中文信息抽取数据集,约有20万条标注数据,涵盖了50种关系。示例数据如下:
{
"text":"《离开》是由张宇谱曲,演唱",
"spo_list":[
["张宇","歌手","离开"],
["张宇","作曲","离开"]
]
}
text表示句子,spo_list表示句子中的三元组信息。其中s代表subject,即主实体;p代表predicate,即关系类型;o代表客实体,即object。
50种预定义的关系包括:
1."祖籍",2."父亲",3."总部地点",4."出生地",
5."目",6."面积",7."简称",8."上映时间",
9."妻子",10."所属专辑",11."注册资本",12."首都",
13."导演",14."字",15."身高",16."出品公司",
17."修业年限",18."出生日期",19."制片人",20."母亲",
21."编剧",22."国籍",23."海拔",24."连载网站",
25."丈夫",26."朝代",27."民族",28."号",
29."出版社",30."主持人",31."专业代码",32."歌手",
33."作词",34."主角",35."董事长",36."成立日期",
37."毕业院校",38."占地面积",39."官方语言",40."邮政编码",
41."人口数量",42."所在城市",43."作者",44."成立日期",
45."作曲",46."气候",47."嘉宾",48."主演",
49."改编自",50."创始人"。
(2)样本特点
1)大多数句子中标注的三元组是“一对多”的形式,即一个主实体对应多个客实体。例如“周杰伦的歌曲包括《稻香》和《晴天》”,那么预测的结果应该是“(周杰伦,歌手,《稻香》)”和“(周杰伦,歌手,《晴天》)”。
2)还有一些句子中存在“多个主实体,一个客实体”或者“多个主实体,多个客实体”的关系。例如“周杰伦和蔡依林合唱了歌曲《布拉格广场》”。那么预测的三元组是“(周杰伦,歌手,《布拉格广场》)”和“(蔡依林,歌手,《布拉格广场》)”。
3)同一对主实体和客实体也可能对应多种关系。例如“《晴天》的词曲作者都是周杰伦”。得到的结果是“(周杰伦,作词,《晴天》)”,“(周杰伦,作曲,《晴天》)”。
4)甚至主实体和客实体之间可能重合,例如“《富兰克林自传》由中央编译出版社出版”,抽取结果应该包括(“《富兰克林自传》,出版社,中央编译出版社”)以及(“《富兰克林自传》,作者,富兰克林”)
通过对样本特点的分析发现,无论是使用串联的关系抽取方法还是基于整体标注的联合抽取方法,都无法解决多个主实体对应多个客实体的情况。
为解决多个主实体对应多个客实体的情况,我们提出了一个新的实体-关系联合抽取方法:
知识抽取问题可以理解为输入一个句子,输出其中包含的所有三元组(s,p,o)信息,该方法先预测出主实体,然后将主实体传入,预测出客实体和关系类型,即:
上述模型可以预测“一对一”的三元组,为了处理多个主实体、多个客实体甚至多个关系类型的情况,还需要使用一种特殊的解码方式。一般的模型是对整个序列做两次softmax分别预测实体的首尾位置,而本方法采用的解码方式是对整个序列都用sigmoid,能够预测出多种主实体和客实体。
深度学习模型
现有的分词工具可能无法准确地识别出三元组的每个实体边界,为了避免边界切分错误,因此模型的输入是基于字符的。
1)在使用bert预训练模型时,需要对输入句子先进行预处理。将句子按照字符分隔开后,在首尾分别加上[cls]和[sep]标记。为了防止空格类字符被默认去掉,导致字符串长度改变,还需要将空格类字符用[unused1]表示,其他字符用[unk]表示。
2)将tokenembedding、segmentembedding和positionembeddings三种向量合并组成embedding层作为bert的输入。
3)将embedding层的向量输入到双向transformer编码器中,得到编码序列。
4)将字向量传入一个全连接的dense层和sigmoid激活函数。得到主实体s的编码,由首尾两个向量构成,分别标记主实体的首尾位置。
5)对于得到的主实体集合,随机采样一个主实体,获得其编码向量。
6)将主实体的编码向量再传到一个全联接的dense网络。对于每一种关系类型(共50种关系类型),都构建两个客实体的首尾向量,这样就同时预测出了客实体和关系类型。与主实体结合,最终得到了(s,p,o)三元组。
因为实体的首尾向量预测是两个二分类问题,因此在训练时,模型的损失函数是二分类的交叉熵损失函数。对于主实体s的预测是两个二分类问题,而对于关系类型p和客实体o的共同预测问题,则有num(p)*2=100个二分类问题。
在训练时学习率先经过一个warmup步骤,从零慢慢增加,再缓慢降下来,防止模型太过发散而不收敛。
评价标准
使用precision,recall以及f1值来作为模型预测结果的评价标准。与其他基于pipeline的经典方法相比,该方法不需要先识别出命名实体,就能直接获得三元组。因此在训练模型的时候,就无需利用实体类型的标签,在评估模型效果的时候也就不用考虑实体的类型。当三元组的关系类型和两个相应实体被正确预测时,就被认为是正确的预测结果。
综上所述,借助于本发明的上述技术方案,通过将迁移学习应用在中文文本的实体-关系联合抽取问题中,提出了一个新的端到端的神经网络模型,使用bert模型作为编码器;设计了一种新型解码结构解决了三元组提取中多个主实体对应多个客实体的问题;能够直接对三元组进行建模,从非结构化文本中提取出三元组信息,显著地提高了关系抽取的效率和准确率;能够应用于海量中文文本的知识自动化抽取,为中文知识图谱自动化构建提供基础。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!