一种自动化办公用服务交流机器人及其控制方法与流程
本发明涉及自动化办公领域,尤其涉及一种自动化办公用服务交流机器人和一种自动化办公用服务交流机器人的控制方法。
背景技术:
智能服务机器人是一种可以通过语言或显示屏与人交互,配合相关设备实现便捷需求的智能产品,在人机交互过程中,目前主要方式是预存检索模型,根据问题与检索模型的匹配度,输出机器人问题答案,但是计算机不能有效拆解人类的语言模式,因此不能理解查询意图,从而导致搜索出的信息不够准确。
针对上述问题,用户在搜索时可以加入高级语法进行操作,但高级语法输入复杂对用户要求高,使得用户体验度降低,并且待检索语句与事先设定的关键词匹配度不够。
申请号为201820061848.9的专利申请文件公开了一种办公服务机器人,涉及机器人技术领域,主要目的是实现人与机器人对接相关机密信息时的主人辨识和文件解密功能,但仍不能解决计算机不能有效拆解人类的语言模式,因此不能理解查询意图,从而导致搜索出的信息不够准确的问题。
申请号为201610619682.3的专利申请文件公开了一种智能办公机器人,能够规划出最佳行动路径、躲避障碍物,还能通过语音、电脑或者手机来操控它,即能够通过语音理解用户意图,但仍不能解决计算机不能有效拆解人类的语言模式,因此不能理解查询意图,从而导致搜索出的信息不够准确的问题。
技术实现要素:
本发明公开了一种自动化办公用服务交流机器人,具备蓝牙芯片能够将麦克风接收到的用户语音信息,通过蓝牙芯片传递到移动终端服务器,将待检索语句与预设模型进行匹配度运算。
本发明还公开了一种自动化办公用服务交流机器人控制方法,将检索语句拆分名词与实意动词,利用检索条数量、检索条权重、高频词组预设权重和关联词语预设权重构建神经网络模型,并提高待检索语句与预先设定匹配度的问题。
本发明提供的技术方案为:
一种自动化办公用服务交流机器人,包括:
壳体;
驱动装置,其设置在所述壳体底部,能够驱动所述壳体移动;
控制器,其设置在所述壳体内;
麦克风,其设置在所述壳体顶部,能够采集语音信息;
录音键;其设置在所述麦克风一端,所述录音键与所述麦克风的输入端相连,所述麦克风的输出端与所述控制器电连接;
蓝牙芯片,其设置在所述壳体内,并与所述控制器电连接,能够将麦克风获取的音频信号传送到移动终端服务器,且所述蓝牙芯片与移动终端武器无线连接。
一种自动化办公用服务交流机器人控制方法,包括如下步骤:
步骤一、在服务器预先存储检索信息,每个短句对应一个检索单位,对于任意一个检索单位均包括关联词语、高频词组和至少一个检索条,所述检索条由所述检索单位关联的的至少一个名词和实意动词组成,并且对全部检索条进行预设权重;
步骤二、将所述录音交互语语句进行滤噪并拆分名词与实意动词,并且将所述名词与所述实意动词扩展成为检索语句,并根据所述预设权重计算语句匹配相似度,根据存储的匹配相似度数值确定匹配的反馈语句;
如果不存在,则根据神经网络对话模型,给出针对用户发送的语句的答案;包括:
将所述检索条数量、检索条权重、高频词组预设权重和关联词语预设权重构建为神经网络模型,在所述第一神经网络中对用户发送语句进行解析,获得表示匹配语句的向量群;以及
将所述表示匹配语句的向量群作为反馈语句输出。
优选的是,所述录音交互语语句为所述名词和所述实意动词的逻辑组合;其中,所述逻辑组合包括:或、且、非逻辑关系。
优选的是,其特征在于,在所述步骤二,对所述检索语句进行相似度评价得到检索权重包括如下步骤:
根据所述名词查找所述名词所在领域,并且确定在所述领域内关键词;
将所述名词在所述领域内的领域密度、领域深度、与所述关键词的关系以及与所述关键词之间的联系强度,计算与所述关键词之间的词权;
根据所述词权,计算与所述关键词之间的检索距离;
根据所述检索距离,计算所述检索语句的相似度评分;
将所述检索语句的相似度评分作为所述检索权重。
优选的是,匹配时按所述预设权重大小依次进行匹配。
优选的是,所述第一神经网络计算过程包括:
步骤1、依次将参数检索条数量、检索条权重、高频词组预设权重和关联词语预设权重进行规格化;
步骤2、确定三层bp神经网络的输入层神经元向量x={x1,x2,x3,x4},其中,x1为检索条数量系数,x2为检索条权重系数,x3为高频词组预设权重系数、x4为关联词语预设权重系数;
步骤3、所述输入层向量映射到隐层,所述隐层向量y={y1,y2,…,ym},m为隐层节点个数;
步骤4、得到输出层神经元向量o={o1,o2,o3,o4};其中,o1为第一匹配词权重,o2为第二匹配词权重,o3为第三匹配词权重,o4为第四匹配词权重;
步骤5、控制器将第一匹配词、第二匹配词、第三匹配词和第四匹配词按照权重大小排列后作为匹配语句输出。
优选的是,所述隐层节点个数m满足:
优选的是,所述检索条数量yt,检索条权重yp、高频词组预设权重ys和关联词语预设权重sλ+1的规格化公式为:
其中,xj为输入层向量中的参数,xj分别为测量参数yt、yp、ys、sλ+1,j=1,2,3,4;xjmax和xjmin分别为相应测量参数中的最大值和最小值。
优选的是,第一匹配词、第二匹配词、第三匹配词和第四匹配词按照权重大小降序排列。
优选的是,所述隐层及所述输出层的激励函数均采用s型函数fj(x)=1/(1+e-x)。
本发明的有益效果
1、本发明公开了一种自动化办公用服务交流机器人,具备蓝牙芯片能够将麦克风接收到的用户语音信息,通过蓝牙芯片传递到移动终端服务器,将待检索语句与预设模型进行匹配度运算。
2、本发明将关键词进行匹配度计算的过程设定在限定的名词上,消除了借此、连词以及其他无实意的词对检索结果造成的干扰,减小检索负担,提高检索效率;
3、本发明通过神经网络模型运算检索的文本与预先设定文本的匹配度,提高了匹配效率以及增加结果的准确性;
4、本发明通过对预设多个检索条,分别进行匹配度的计算,提高了检索结果的全面性。
附图说明
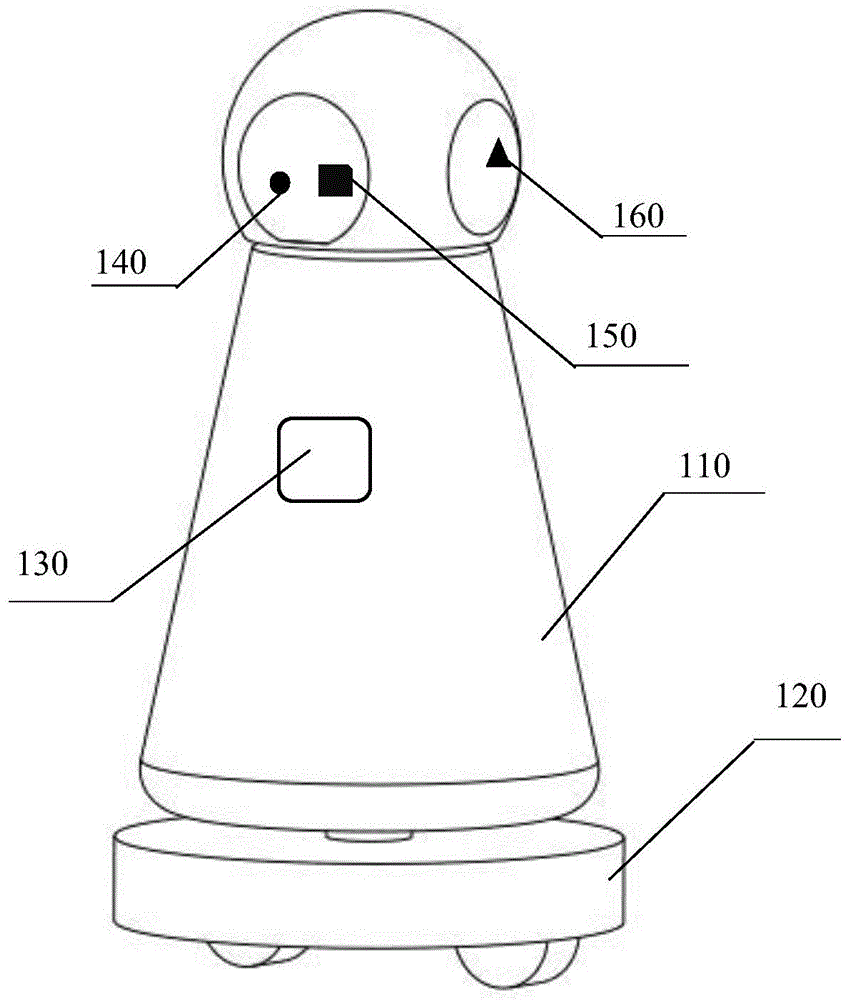
图1为本发明所述的自动化办公用服务交流机器人的结构示意图。
具体实施方式
下面结合附图对本发明做进一步的详细说明,以令本领域技术人员参照说明书文字能够据以实施
如图1所示,本发明提供的自动化办公用服务交流机器人,包括:壳体110、驱动装置120、控制器130、麦克风140、录音键150和蓝牙芯片160;
驱动装置120设置在壳体110底部,能够驱动壳体110移动;控制器130设置在所述壳体110内;麦克风140设置在壳体110顶部,能够采集语音信息;录音键150设置在麦克风140一端,录音键150与麦克风140的输入端相连,麦克风140的输出端与控制器130电连接;蓝牙芯片160设置在壳体110内,并与控制器130电连接,能够将麦克风获取的音频信号传送到移动终端服务器,且蓝牙芯片160与移动终端武器无线连接。自动化办公用服务交流机器人,具备蓝牙芯片能够将麦克风接收到的用户语音信息,通过蓝牙芯片传递到移动终端服务器,将待检索语句与预设模型进行匹配度运算。
一种自动化办公用服务交流机器人控制方法,包括如下步骤:
步骤一、在服务器预先存储检索信息,每个短句对应一个检索单位,对于任意一个检索单位均包括关联词语、高频词组和至少一个检索条,检索条由所述检索单位关联的的至少一个名词和实意动词组成,并且对全部检索条进行预设权重;
步骤二、将录音交互语语句进行滤噪并拆分名词与实意动词,并且将所述名词与所述实意动词扩展成为检索语句,并根据预设权重计算语句匹配相似度,根据存储的匹配相似度数值确定匹配的反馈语句;
如果不存在,则根据神经网络对话模型,给出针对用户发送的语句的答案;包括:
将所述检索条数量、检索条权重、高频词组预设权重和关联词语预设权重构建为神经网络模型,在所述第一神经网络中对用户发送语句进行解析,获得表示匹配语句的向量群;以及
将表示匹配语句的向量群作为反馈语句输出。
作为一种优选,录音交互语语句为所述名词和所述实意动词的逻辑组合;其中,所述逻辑组合包括:或、且、非逻辑关系。
在另一实施例中,对检索语句进行相似度评价得到检索权重包括如下步骤:
根据所述名词查找所述名词所在领域,并且确定在所述领域内关键词;
将名词在领域内的领域密度、领域深度、与所述关键词的关系以及与所述关键词之间的联系强度,计算与所述关键词之间的词权:
其中,csd(i)为关键词之间的词权,x(i)为关键词联系强度,
根据所述词权,计算与所述关键词之间的检索距离;
其中,rms为关键词之间的检索距离。
根据所述检索距离,计算所述检索语句的相似度评分;
其中,skess为检索语句的相似度评分,将检索语句的相似度评分作为检索权重。
优选的是,匹配时按所述预设权重大小依次进行匹配。
优选的是,所述神经网络计算过程包括:
将参数检索条数量、检索条权重、高频词组预设权重和关联词语预设权重输入神经网络控制器,得到关于匹配词权重的向量群,包括:
建立bp神经网络模型。
bp模型上各层次的神经元之间形成全互连连接,各层次内的神经元之间没有连接,输入层神经元的输出与输入相同,即oi=xi。中间隐含层和输出层的神经元的操作特性为
opj=fj(netpj)
其中p表示当前的输入样本,ωji为从神经元i到神经元j的连接权值,opi为神经元j的当前输入,opj为其输出;fj为非线性可微非递减函数,一般取为s型函数,即fj(x)=1/(1+e-x)。
本发明采用的bp网络体系结构由三层组成,第一层为输入层,共n个节点,对应了表示设备工作状态的n个检测信号,这些信号参数由数据预处理模块给出;第二层为隐层,共m个节点,
该网络的数学模型为:
输入层向量:x=(x1,x2,…,xn)t
中间层向量:y=(y1,y2,…,ym)t
输出层向量:z=(z1,z2,…,zp)t
按照采样周期,本发明中,输入层节点数为n=4,输出层节点数为p=4,隐藏层节点数m由下式估算得出:
由于传感器获取的数据属于不同的物理量,其量纲各不相同。因此,在数据输入人工神经网络之前,需要将数据规格化为0-1之间的数。
检索条数量yt,检索条权重yp、高频词组预设权重ys和关联词语预设权重sλ+1的规格化公式为:
其中,xj为输入层向量中的参数,xj分别为测量参数yt、yp、ys、sλ+1,j=1,2,3,4;xjmax和xjmin分别为相应测量参数中的最大值和最小值,采用s型函数。
具体而言,对于检索条数量yt,进行规格化后,得到检索条数量系数x1:
其中,max(yt)和min(yt)分别为检索条数量的最大值和最小值。
同样的,检索条权重ys通过下式进行规格化,得到检索条权重系数x2:
其中,max(ys)和min(ys)分别为检索条权重的最大值和最小值。
高频词组预设权重yp进行规格化后,得到高频词组预设权重系数x3:
其中,max(yp)和min(yp)分别为高频词组预设权重的最大值和最小值。
关联词语预设权重sλ+1进行规格化后,得到关联词语预设权重系数x4:
其中,max(sλ+1)和min(sλ+1)分别为关联词语预设权重的最大值和最小值。
得到输出层神经元向量o={o1,o2,o3,o4};其中,其中,o1为第一匹配词权重,o2为第二匹配词权重,o3为第三匹配词权重,o4为第四匹配词权重;。
进行bp神经网络的训练。
建立好bp神经网络节点模型后,即可进行bp神经网络的训练。根据产品的经验数据获取训练的样本,并给定输入节点i和隐含层节点j之间的连接权值wij,隐层节点j和输出层节点k之间的连接权值wjk,隐层节点j的阈值θj,输出层节点k的阈值wij、wjk、θj、θk均为-1到1之间的随机数。
(1)训练方法
各子网采用单独训练的方法;训练时,首先要提供一组训练样本,其中的每一个样本由输入样本和理想输出对组成,当网络的所有实际输出与其理想输出一致时,表明训练结束;否则,通过修正权值,使网络的理想输出与实际输出一致;各子网训练时的输出样本如表1所示。
表1网络训练用的输出样本
(2)训练算法
bp网络采用误差反向传播(backwardpropagation)算法进行训练,其步骤可归纳如下:
第一步:选定一结构合理的网络,设置所有节点阈值和连接权值的初值。
第二步:对每个输入样本作如下计算:
(a)前向计算:对l层的j单元
式中,
若单元j的激活函数为sigmoid函数,则
且
若神经元j属于第一隐层(l=1),则有
若神经元j属于输出层(l=l),则有
(b)反向计算误差:
对于输出单元
对隐单元
(c)修正权值:
第三步:输入新的样本或新一周期样本,直到网络收敛,在训练时各周期中样本的输入顺序要重新随机排序。
bp算法采用梯度下降法求非线性函数极值,存在陷入局部极小以及收敛速度慢等问题。更为有效的一种算法是levenberg-marquardt优化算法,它使得网络学习时间更短,能有效地抑制网络陷于局部极小。其权值调整率选为
δω=(jtj+μi)-1jte
其中j为误差对权值微分的雅可比(jacobian)矩阵,i为输入向量,e为误差向量,变量μ是一个自适应调整的标量,用来确定学习是根据牛顿法还是梯度法来完成。
在系统设计时,系统模型是一个仅经过初始化了的网络,权值需要根据在使用过程中获得的数据样本进行学习调整,为此设计了系统的自学习功能。在指定了学习样本及数量的情况下,系统可以进行自学习,以不断完善网络性能。
第一匹配词、第二匹配词、第三匹配词和第四匹配词按照权重大小降序排列,并将对应匹配词输出。
本发明公开了一种自动化办公用服务交流机器人,具备蓝牙芯片能够将麦克风接收到的用户语音信息,通过蓝牙芯片传递到移动终端服务器,将待检索语句与预设模型进行匹配度运算。本发明将检索语句拆分名词与实意动词,利用检索条数量、检索条权重、高频词组预设权重和关联词语预设权重构建神经网络模型,并提高待检索语句与预先设定匹配度的问题。
尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节和这里示出与描述的图例。
- 还没有人留言评论。精彩留言会获得点赞!