一种大气监测系统中数据异常的修正方法与流程
本发明属于大气环境监测技术,具体涉及一种大气监测系统中数据异常的修正方法。
背景技术:
随着社会经济的发展和进步,环境保护问题逐渐引起了人们的重视,为了提升环境保护工作的科学性,环境监测已经成为环境保护工作的重要工具,为环境保护工作作出了重要的贡献。但在当前我国环境监测工作中,难以避免出现异常数据的情况,这些数据的存在对提升环境监测工作的质量造成了一定的阻碍。在环境监测中主要存在三种异常数据,分别是离群数据、不合理数据、跳跃性较大的数据。
自动大气监测装置主要会用到传感器作为监测和数据传输的媒介,随着无线传感器网络被越来越多的部署到实际环境中,其以数据为中心的特点就日益凸显。无线传感器网络需要从部署环境中获取数据,从中发现有价值的信息,这是其应用能否成功的关建。因此需要重点关注和解决的问题是怎样设计有效的异常检测机制,用来从数据中寻找各类异常信息或发现各种异常状况。
在现有的传感器网络数据异常修正方法中,基于统计的修正方法难以适应传感器网络部署环境的变化存在误报率高的问题,基于距离的修正方法往往需要融入其他修正方法中来提升检测效果,基于数据挖掘、机器学习技术的修正方法通常需要大量的数据,并且对检测设备的计算、存储等性能要求较高,不适宜部署在能力受限的传感器节点上。目前,在无线传感器网络中应用的异常检测方案有集中式的,但是集中式的异常检测存在时效性差、数据瓶颈、设备资源浪费等问题,而在分布式的异常检测方案中,将复杂的检测算法嵌入传感器网络中的各个设备中又会给整个系统带来沉重的计算和通信开销。
技术实现要素:
发明目的:针对上述现有技术中环境监测系统的采集数据错误率比较高和整个通信系统开销较大的问题,本发明提供一种大气监测系统中异常数据的修正方法。
技术方案:一种大气监测系统中数据异常的修正方法,所述方法基于信息熵的异常检测算法和基于k-means聚类的异常检测算法,包括如下步骤:
(1)采集空气质量监测数据,并对待监测的数据提取特征数据;
(2)对于需要通过多个维度的数据对传感器数据进行异常检测,需要对不同属性的数据规范化,利用最小-最大规范化对特征数据进行预处理,计算特征数据的信息熵;
(3)获取该节点的历史数据,按第一级基于信息熵的异常检测算法计算出传感器节点的异常概率,当节点的异常概率高于阈值时,执行第二级基于k-means的异常检测算法,获取该节点相近节点的特征向量,对该节点和相近节点进行聚类分簇,在分簇结果之上计算该节点特征向量与所在聚类中心之间的距离,若距离小于距离阈值,则认为对应的传感器节点没有异常,若距离大于当前的距离阈值,则判定该数据对象为异常数据;
(4)剔除异常数据,通过分段线性插值、临近点插值、三次样条函数插值以及三次多项式方法对空缺进行插值补充数据,获取大气监测系统的准确数据。
进一步的,步骤(2)所述的最小-最大规范化为将大气监测系统中该传感器节点采集的原始数据的基础上,线性变换原始数据,属性x的最大值为maxx和最小值为minx,将数据集中某属性x的值x映射到区间[min′x,max′x]中的x',则最小-最大规范化通过下式计算:
通过最小-最大规范化,可以保持原始数据值之间的大小关系。
更进一步的,所述方法对温度和气压的异常数据检测,还包括监测传感器输过程中产生的传输异常数据检测,所述温度和气压的异常数据检测通过t检验法和t分布理论来计算差异发生的概率,比较两个平均数的差异;所述的传输异常数据检测基于信息熵和k-means的分级式异常检测算法对时间、空间相关性进行检测。
所述温度和气压的异常数据检测计算过程如下:
(101)获取观测数据为x1,x2,……,xn,其中标记xmax或xmin为可疑值xm,当统计量大于临界值时判断为异常值,表达式如下:
ym>yp(n)
式中ym是统计量,yp(n)是临界值;
设t检验的统计量为tm,临界值为tp(n),下标p是百分数,由下式决定:
剔除异常值一般取α=0.01,故一般p=0.99或p=0.995;
(102)计算统计量表达式中的样本均值
不包括可疑值xm的样本均值
t检验法的临界值为:
式中tp(n-2)是自由度为(n-2)的t分布的p分位数;
(103)计算不包括可疑值xm的统计量,计算公式如下:
(104)对于计算出的异常数据,通过插值法进行修改,将异常数据剔除,使用分段线性插值、临近点插值、三次样条函数插值以及三次多项式方法对空缺进行插值,补充监测数据。
所述方法对于单传感器下的数据信息熵的异常检测计算步骤如下:
(201)滑动窗口
构建滑动窗口,滑动窗口模型通过使用长度w(w>0)的滑动窗口将传感器数据流切分成窗口内数据与窗口外数据,窗口内包含w个采样数据;当窗口滑动时,上一采样时刻tbefore的数据退出窗口,而下一采样时刻tnext的数据进入窗口;
假设w1、w2为两个相邻窗口,窗口滑动距离为1,则其移动前的数据序列x1(t)可表示为:
x1(t)=[x(t-w*δt),…,x(t-δt),x(t)]
滑动窗口移动后的数据序列x2(t)可表示为:
x2(t)=[x(t-(w-1)*δt),...,x(t),x(t+δt)]
其中tbefore的数据为x(t-w*δt),tnext的数据为x(t+δt);
(202)数据距离
对于数据对象x1(t)和x2(t),其距离表示为:
对于数据序列的信息熵h1(t)和h2(t),其距离表示为:
d(h1(t),h2(t))=h1(t)-h2(t)
(203)进行k-means异常检验
先对数据进行规范化处理,然后使用k-means聚类算法对传感器网络的数据对象进行聚类分簇,最终确定聚类中心的位置和分组的结果,最后通过计算待测数据对象与各聚类中心之间的最短距离并与异常距离阈值比较大小来确定待测传感器节点是否出现异常,其中数据对象之间的距离通过欧几里得距离公式计算。
有益效果:与现有技术相比,本发明所述方法经过信息熵异常检验和k-means异常检验两道步骤,不仅减少了传感器网络正常状态下运行的资源消耗,而且降低了整体的性能消耗,提高了检测的效率;另一方面,本发明还适用于对于传感器采集数据组的异常检测和对于大气监测系统在数据传输过程中的异常检测,提高监测数据准确性的同时提高监测系统的监测能力。
附图说明
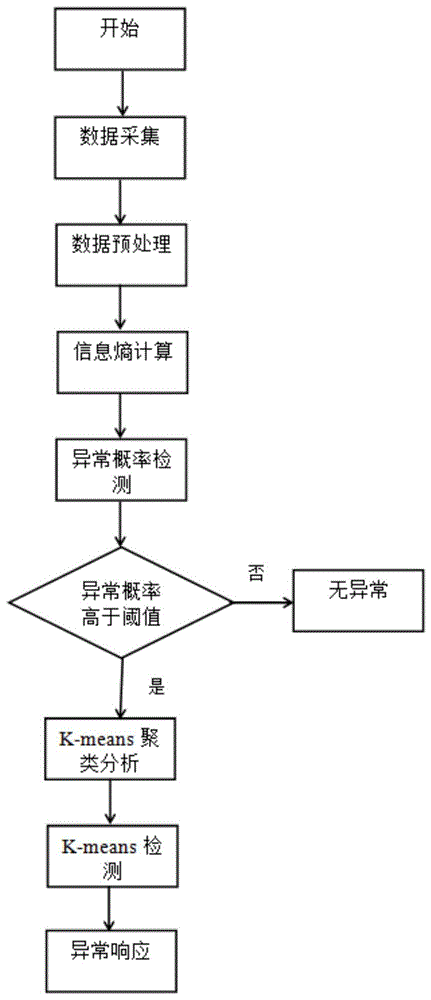
图1是本发明所述方法的流程示意图。
具体实施方式
为了详细说明本发明所公开的技术方案,下面结合说明书附图和具体实施例做进一步的阐述。
对于气象数据、环境数据的监测系统所获取的数据,一般存在如下几个方面特征:
(1)离群数据主要是指实际的监测数据和全部监测数据的平均值产生较大偏差的情况,这样的数据不能够正确反馈环境污染的程度以及污染的实际情况,所以在环境监测工作中被判定为异常数据。在当前环境监测工作中,对于离群数据主要是通过数据分析和人工方式来对离群数据进行判别,再对其进行数据初步核实或是补充监测等措施进行处置,至于离群数据是否属于无效的异常数据,就需要通过进一步的分析和判定,避免出现真实数据被删除的情况。
(2)不合理数据主要是指环境监测的数据出现不符合日常监测逻辑的情况,比如说在进行污染源监督性监测中,得到的监测数据呈现出污染物进出口倒置的情况,这往往说明监测设施运作不正常或者是监测人员在进行监测操作时可能发生了不合理的操作行为,致使最终的数据受到影响。
(3)跳跃性较大的数据是将监测数据与同一对象的历史监测数据相比较而言的,指监测对象的监测数据与其较长期的监测历史数据发生较大偏差的情况。在监测对象的状态相对稳定,这种数据的出现往往表明监测工作本身出现了一定的问题,尤其还要仔细核实监测对象的状态是否发生了潜在的,不明显的改变。在环境监测阶段,监测者找到异常信息时,要立刻分析其产生的原因,从客观与主观因素着手,综合监测环节的工况条件、外界环境和监测者的监测行为等展开详细分析。在处理异常信息时,不得采用忽视和任意剔除的方法进行片面处理,其要在找出原因的前提下,对异常信息展开全面分析和科学处置。
本发明所提供的是一种大气监测系统中异常数据的修正方法,如图1所示,通过算法先采集传感器网络中的数据,并从采集数据中提取出所需的特征数据,然后利用最小-最大规范化方法对特征数据进行预处理,之后结合本节点的历史数据按第-级基于信息熵的异常检测算法计算出传感器节点的异常概率,当节点的异常概率高于阈值时,执行第二级基于k-means的异常检测算法,获取该节点相近节点的特征向量,对该节点和相近节点进行聚类分簇,在分簇结果之上计算该节点特征向量与所在聚类中心之间的距离,若距离小于距离阈值,则认为对应的传感器节点没有异常,若距离大于当前的距离阈值,则认为该数据对象出现异常,对应传感器节点发生异常事件或恶意攻击。
具体实施如下:
首先进行基于信息熵的异常检验:首先获取数据流一段时间内的数据序列,然后对数据序列进行计算得到滑动窗口信息熵序列,再分别计算出滑动窗口内数据异常概率和信息熵异常概率,最后通过综合计算异常概率判断数据流是否发生异常。
伴随着采集时间t的不断变化,传感器节点采集到的数据也在不断变化。通常情况下,采集时间t处的数据同其历史数据及后继数据具有时间相关性,并且数据采集周期的选择对这种相关性有极大的影响。对于单传感器数据流而言,假设数据采集的时间间隔为δt,则该传感器数据流的时间序列可表示为如下:
x(t)=[...,x(t-δt),x(t),x(t+δt),...]
即传感器数据流的时间序列具有无限延展性,但是传感器节点的存储空间和计算能力有限所以使用滑动窗口模型对数据流进行处理。
(1)滑动窗口
滑动窗口模型通过使用长度w(w>0)的滑动窗口将传感器数据流切分成窗口内数据与窗口外数据,窗口内包含w个采样数据。当窗口滑动时,上一采样时刻tbefore的数据退出窗口,而下一采样时刻tnext的数据进入窗口。假设w1、w2为两个相邻窗口,窗口滑动距离为1,则其移动前的数据序列x1(t)可表示为:
x1(t)=[x(t-w*δt),...,x(t-δt),x(t)]
滑动窗口移动后的数据序列x2(t)可表示为:
x2(t)=[x(t-(w-1)*δt),...,x(t),x(t+δt)]
其中tbefore的数据为x(t-w*δt),tnext的数据为x(t+δt)。
(2)数据距离
数据距离使用欧几里得距离定义,用于表示在n维空间中两个数据对象之间的真实距离,其可以作为数据对象相似程度的度量。通常距离越短相似度越高。
对于数据对象x1(t)和x2(t),其距离可表示为:
对于数据序列的信息熵h1(t)和h2(t),其距离可以表示为:
d(h1(t),h2(t))=h1(t)-h2(t)
然后进行k-means异常检验:先对数据进行规范化处理,然后使用k-means聚类算法对传感器网络的数据对象进行聚类分簇,最终确定聚类中心的位置和分组的结果,最后通过计算待测数据对象与各聚类中心之间的最短距离并与异常距离阈值比较大小来确定待测传感器节点是否出现异常。其中数据对象之间的距离通过欧几里得距离公式计算。
(a)对于简单的温度和气压数据的异常情况
由于温度和气压数据属于很少会出现突变情况的数据,所以对于温度和气压数据主要采用的是t检验法对所监测到的数据进行检测,t检验法用t分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显著。
已知正态样本的一组观测值x1,x2,......,xn,其中xm(xmax或xmin中之一)为可疑值,检验异常值的原理是:当它的统计量大于临界值时就判为异常值。写成通式就是:
ym>yp(n)
式中ym是统计量,yp(n)是临界值。y是可以替换的。设t检验的统计量为tm,临界值为tp(n)。下标p是百分数,由下式决定:
剔除异常值一般取α=0.01,故一般p=0.99或p=0.995。
统计量表达式中的样本均值
不包括可疑值xm的样本均值
t检验法的临界值为:
式中tp(n-2)是自由度为(n-2)的t分布的p分位数。具体数值可查询“t分布的分位数表”。
不包括可疑值xm的统计量计算公式为:
对于找出的异常数据,可以用插值的方法进行修改,将原本的错误数据剔除,使用分段线性插值,临近点插值,三次样条函数插值以及三次多项式方法对空缺进行插值,补充数据,得到完整且较为科学的数据。
(b)对于监测传感器传输过程中产生的异常数据
在无线传感器网络中,为了减小网络数量的传输量,降低网络的功耗,网络节点的感知数据会有网关节点汇集并传输给数据控制中心,网关节点完成数据融合操作。而在传感器网络中出现的异常数据指的是传感器网络在受到恶意的数据攻击时所反映出的多种网络数据的异常状态指标,数据类型的异常包括固定型异常和离散型异常。
正常情况下,传感器节点采集到的数据是随采样时间t变化的一簇变量,传感器节点采集到的数据值与前一段时间和后一段时间采集到的数据值具有一定的统计概率或函数关系,这--特性被称为传感器数据流的时间相关性。通常情况下,传感器节点采集到的数据所具有的时间相关性的明显程度与其所处的外界环境条件密切相关,当外界环境的变化在一定时间内连续时,传感器节点采集的温度、湿度、气压等自然数据也在这段时间内连续变化,这种连续变化的特点就是时间相关性。例如,对同一个传感器节点,任意一天的温度数据总是按照一定的物理规律缓慢地改变,一段时间内温度数据值的分布较为稳定,数据流信息熵也呈现出在一定范围内稳定变化的规律。
针对现有异常检测算法存在的问题,本文通过结合基于信息熵的异常检测算法和基于k-means聚类的异常检测算法两种算法,提出了一种基于信息熵和k-means的分级式异常检测算法。这种算法通过将这两种异常检测算法的优点结合起来,充分利用了传感器网络数据流的时间、空间相关性进行异常检测,且适用于无线传感器的组成结构和设备功能,可以灵活部署到传感器网络中。
通过上述方法对异常数据进行检测,当监测者发现异常数据时,可以立刻分析其产生的原因,从客观与主观因素着手,综合监测环节的工况条件、外界环境和监测者的监测行为等展开详细分析,具体到监测系统的各个节点传感器和所获取的数据源。在处理异常信息时,不得采用忽视和任意剔除的方法进行片面处理,在数据量较大的情况下,无论是按照科学评估剔除异常数据,还是重新监测都是工作量较大的行为,所以为了减少检测者的工作量,整合各种情况下的数据异常问题,本发明所提供的一种大气监测系统中数据异常的修正方法得到广泛的应用和具有良好的应用前景。
- 还没有人留言评论。精彩留言会获得点赞!