一种基于决策树模型的电力用能数据存储优化方法与流程
本发明涉及一种电力数据存储领域,尤其涉及一种基于决策树模型的电力用能数据存储优化方法。
背景技术:
随着大数据技术在用电采集系统中运用的不断成熟,越来越多的数业务迁移至用电采集大数据平台(以下简称:用采大数据平台),井喷式电力用能数据使采大数据平台的存储空间面临着存不足以及数据存储效率低下两大方面的问题。现有用采大数据平台的电力用能数据主要存至hbase中,为了解决用能数据存储问题,急需解决hbase存储优化。
现有的hbase存储优化主要有:一、按列、按区、按列、区混合等数据压缩策略只是应用于这些处理方法只适用于一次写入表hbase表,例如档案数据表;二、缓存加载方式及批量加载方式在一定程度上降低了hbasei/o开销,适用于对延时容忍较高的场景,例如异构数据迁移。对于高频采集、低实时性业务场景的数据,呈现出高频增长,延时容忍低等特点,已有的高效存储方法不能满足要求。
技术实现要素:
本发明要解决的技术问题和提出的技术任务是对现有技术方案进行完善与改进,提供一种基于决策树模型的电力用能数据存储优化方法,以达到弥补目前对于高频采集数据存储空间优化的不足,节省电力用能数据在大数据平台存储资源空间,提高hbase读写性能的目的。为此,本发明采取以下技术方案。
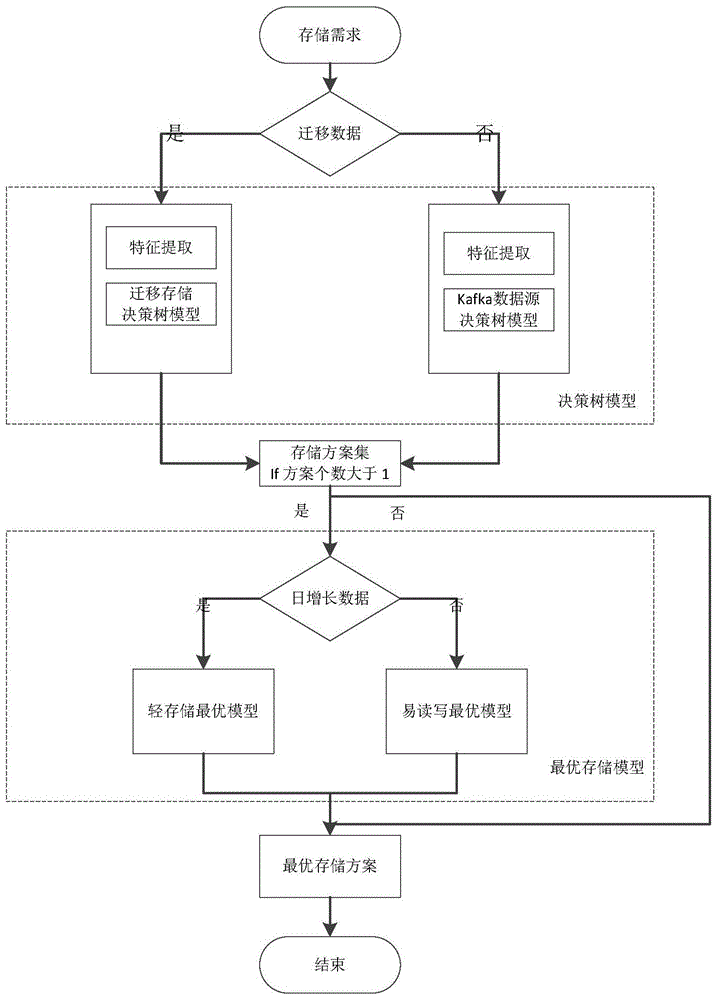
一种基于决策树模型的电力用能数据存储优化方法,包括以下步骤:
1)获取需存储的数据业务需求;
2)根据业务需求判断获取的数据是否为迁移数据,若是则进入步骤3);若否,则进入步骤4);
3)进行数据特征的提取,将特征属性输入迁移存储决策树模型中,获得存储方案;
4)进行数据特征的提取,将特征属性输入kafka数据源决策树模型中,获得存储方案;
5)根据步骤3)或步骤4)得到的存储方案集判断存储方案的个数是否大于1;若否,此方案为最优存储方案,否则进入下一步骤;
6)判断是否为日增长数据;若是则进入步骤7),若否则进入步骤8);
7)根据日增长数据,通过轻存储最优模型获得各存储方案的权重;
8)根据存储量,通过易操作最优模型获得各存储方案的权重;
9)结合步骤3)或步骤4)得到的存储方案集及步骤7)或步骤8)获得的各存储方案的权重,得到最优存储方案。
本技术方案采用多种格式的数据存储方式,根据不同的情况择优进行存储,弥补目前对于高频采集数据存储空间优化的不足,节省电力用能数据在大数据平台存储资源空间,提高hbase读写性;解决电力用能数据存储问题,为电力用能提供一个规范的hbase存储优化方法,具有易实现的、高效的特点,方便平台存储格式选择的规范化操作,便于后期平台存储资源的管理。
作为优选技术手段:迁移存储决策树模型、kafka数据源决策树模型均通过id3算法训练得出;id3算法将给定的样本计集合作为根结点,以信息增益率为标准确定最佳分组和最佳分割点;分别计算当前样本集合里的每个特征属性的信息增益,并从信息增益集合中选取信息增益最大的作为根结点,然后根据该属性值进行分支。
作为优选技术手段:id3算法步骤包括:
d)信息熵,假设数据集合为d,样本的个数为k,则数据集d的经验熵表示为:
其中ck是样本集合d中属于第k类的样本子集,|ck|表示该子集的元素个数,|d|表示元素集合的元素个数。
e)信息熵,某个特征a对于数据集d的经验条件熵h(d|a)为
其中,di表示d中特征a取第i个值的样本子集。
f)信息增益,信息增益的衡量标准,就是看特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要;
g(d,a)=h(d)-h(d|a)(3-3)。
作为优选技术手段:迁移存储决策树模型、kafka数据源决策树模型输出的存储方案为protobuf、json、normal中的一个或多个。
作为优选技术手段:轻存储最优模型、易操作最优模型中的各存储方案的权重根据存储大小、读写性能计算获得。
作为优选技术手段:轻存储最优模型中存储不同范围的日增长量及与之对应的各存储方案的权重值,以根据实际的日增长量规模查询轻存储最优模型获得normal、json、protobuf三种存储格式的权重。
作为优选技术手段:易操作最优模型中存储不同范围的存储量及与之对应的各存储方案的权重值,以根据实际的存储量规模查询易操作最优模型获得normal、json、protobuf三种存储格式的权重。
作为优选技术手段:在步骤3)中,迁移数据是将关系型数据库中的档案表、结果表、统计表等数据同步到hbase中,此类数据结构固定,为结构化数据,结合业务场景和需求,决策树属性集合选用:{数据类型,字段嵌套,读表形式,是否过滤};其中
数据类型:是根据数据来源进行具体分类,分为档案数据、结构数据、统计数据;
字段嵌套:根据业务场景需求,存储是否是嵌套式;
读表形式:业务场景中与表的交互方式,分为全行扫描和部分字段读取;
是否过滤:业务场景中按条件与表的交互方式,分为是和否。
作为优选技术手段:在步骤4)中,kafka数据源决策模型数据来源是kafka,通常是通过前置机采集上送的数据,数据结构无规则,具有:结构化、半结构化、非结构化特征,选用的数据特征在异构数据迁移特征基础之上增加结构化数据特征,具体的特征包含:{数据类型,字段嵌套,数据结构,读表形式,是否过滤},其中:
数据类型:是根据数据来源进行具体分类,分为采集数据(前置机推送的采集数据)、异常日志、操作日志、原始报文;
字段嵌套:根据业务场景需求,存储是否是嵌套式;
数据结构:存储数据的结构,分为结构化、半结构化、非结构化;
读表形式:业务场景中与表的交互方式,分为全行扫描和部分字段读取;
是否过滤:业务场景中按条件与表的交互方式,分为是和否。
有益效果:
1、基于决策树模型的提出的优化方案,存储方式选择更加规范和科学,便于实现平台存储资源的管理,为后期存储选择提供参考依据。
2、引入轻量级存储方式,能够实现实时入库数据存储优化,解决了实时采集数据表不易操作,低延时入库需求的难题。
3、结合多存储格式的各自特点,根据业务场景和需求,制定三种数据格式存储方式,具有如下几个方面的优点:
(1)从业务场景和需求角度出发的定制的存储方式,不仅实现了合理规划平台存储空间利用率,还能满足后期业务场景需求;
(2)不同于传统的优化模型,需要对数据进行逐条或是逐批进行计算处理,合理的数据格式存储选取,降低了传统优化模型的时间成本和计算资源。
附图说明
图1是本发明的流程图。
图2、3是本发明的决策树图。
具体实施方式
以下结合说明书附图对本发明的技术方案做进一步的详细说明。
如图1所示,本发明包括以下步骤:
一种基于决策树模型的电力用能数据存储优化方法,包括以下步骤:
1)获取需存储的数据业务需求;
2)根据业务需求判断获取的数据是否为迁移数据,若是则进入步骤3);若否,则进入步骤4);
3)进行数据特征的提取,将特征属性输入迁移存储决策树模型中,获得存储方案;
4)进行数据特征的提取,将特征属性输入kafka数据源决策树模型中,获得存储方案;
5)根据步骤3)或步骤4)得到的存储方案集判断存储方案的个数是否大于1;若否,此方案为最优存储方案,否则进入下一步骤;
6)判断是否为日增长数据;若是则进入步骤7),若否则进入步骤8);
7)根据日增长数据,通过轻存储最优模型获得各存储方案的权重;
8)根据存储量,通过易操作最优模型获得各存储方案的权重;
9)结合步骤3)或步骤4)得到的存储方案集及步骤7)或步骤8)获得的各存储方案的权重,得到最优存储方案。
本技术方案采用多种格式的数据存储方式,根据不同的情况择优进行存储,弥补目前对于高频采集数据存储空间优化的不足,节省电力用能数据在大数据平台存储资源空间,提高hbase读写性;解决电力用能数据存储问题,为电力用能提供一个规范的hbase存储优化方法,具有易实现的、高效的特点,方便平台存储格式选择的规范化操作,便于后期平台存储资源的管理。
为了简化决策树的模型,在本技术方案中,将决策树模型分为迁移存储决策树模型、kafka数据源决策树模型两种,迁移存储决策树模型、kafka数据源决策树模型均通过id3算法训练得出;id3算法将给定的样本计集合作为根结点,以信息增益率为标准确定最佳分组和最佳分割点;分别计算当前样本集合里的每个特征属性的信息增益,并从信息增益集合中选取信息增益最大的作为根结点,然后根据该属性值进行分支。
id3算法步骤包括:
g)信息熵,假设数据集合为d,样本的个数为k,则数据集d的经验熵表示为:
其中ck是样本集合d中属于第k类的样本子集,|ck|表示该子集的元素个数,|d|表示元素集合的元素个数。
h)信息熵,某个特征a对于数据集d的经验条件熵h(d|a)为
其中,di表示d中特征a取第i个值的样本子集。
i)信息增益,信息增益的衡量标准,就是看特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要;
g(d,a)=h(d)-h(d|a)(3-3)。
本技术方案集合normal、json、protobuf三种格式的优点,扬长避短;normal、json、protobuf三种格式在实际应用场景中都有着很强的适应性,当需求,环境等因素发生变化时,虽灵活度有差别但都可应对;此外,它们对操作数据而言是安全的。以下总结为,使用不同格式对业务处理的大致存储效率和它们彼此的特点与优劣,各存储的格式特点具体如下表所示:
三种数据格式性能对比
本技术方案充分利用了normal、json、protobuf三种格式的长处,对于日增长数据量很大的数据源,如:{采集数据,原始报文,操作日志,结果数据},这类数据对存储空间需求大,且对表操作频率不多,采用“轻存储,易操作”原则,这类数据存储的优先级可为:normal>json>protobuf;对于日增量不大的微增长数据源,如:{档案数据,统计数据,异常日志},这类数据对存储空间需求小,且对表操作频率高,灵活性要求高,采用“易操作,轻存储”原则,这类数据存储的优先级可为:protobuf>json>normal。
以下就具体实施例对部分内容说进一步的说明:
基于决策树模型的hbase存储优化方法,是将用电采集系统中多业务场景分类下,对数据存储和操作的不同需求进行划分,并且这些影响存储格式选择的属性集合,提取成特征集合,并且建立成对应的特征属性表,为后期平台的hbase存储提供参考依据。
1.1决策树模型建立
用采大数据平台的数据来源主要分为两类,一、通过前置机及日志等方式推送的kafka数据源采集数据;二、通过hive数据仓库、oracle/mysql数据库异构迁移数据。由于异构迁移数据是从关系型数据库中迁移而来,数据存储的结构相对稳定为结构化数据;而kafka数据源采集数据结构多样化,具有:结构化、半结构化、非结构化特征。基于以上三种存储格式的适应分析中,protobuf存储格式不适用于半结构化和非结构化数据。因此,为了简化决策树模型,本研究根据数据源不同,将决策树分为kafka数据源决策模型和异构数据源决策模型。
1.1.1kafka数据源决策模型
kafka数据源决策模型数据来源是kafka,通常是通过前置机采集上送的数据,数据结构无规则,具有:结构化、半结构化、非结构化特征,选用的数据特征在异构数据迁移特征基础之上增加结构化数据特征,具体的特征包含:{数据类型,字段嵌套,数据结构,读表形式,是否过滤},其中:
数据类型:是根据数据来源进行具体分类,分为采集数据(前置机推送的采集数据)、异常日志、操作日志、原始报文
字段嵌套:根据业务场景需求,存储是否是嵌套式
数据结构:存储数据的结构,分为结构化、半结构化、非结构化
读表形式:业务场景中与表的交互方式,分为全行扫描和部分字段读取
是否过滤:业务场景中按条件与表的交互方式,分为是和否
例如:现有业务,需要计算用采大数据平台的抄表采集成率。
分析过程:1、数据类型:用采大数据平台的数据是通过前置机获取的采集数据;
2、字段嵌套:存储不需嵌套;
3、数据结构:采集数据为前置机统一配置的模板,结构稳定为结构化数据;
4、读表形式:采集成功率为批量侧离线处理方式,需要全行读取;
5、是否过滤:采集成功率是计算实采点数/应采点数,取表方式无需过滤
6、存储格式:根据以上分析存储格式的适应性分析可知,存储格式选择为protobuf。
现将用采大数据平台kafka数据源决策树模型按照分析过程建立表1-1所示模型数据集合,为后期的决策数建立依据;
表1-1kafka数据源属性集合
根据表1-1所示kafka数据源属性集合,建立的决策树图如图2所示;
1.1.2迁移存储决策树模型
异构数据迁移通常是将关系型数据库中的档案表、结果表、统计表等数据同步到hbase中,此类数据结构固定,为结构化数据,结合业务场景和需求,决策树属性集合选用:{数据类型,字段嵌套,读表形式,是否过滤}。其中
数据类型:是根据数据来源进行具体分类,分为档案数据、结构数据、统计数据
字段嵌套:根据业务场景需求,存储是否是嵌套式
读表形式:业务场景中与表的交互方式,分为全行扫描和部分字段读取
是否过滤:业务场景中按条件与表的交互方式,分为是和否
例如:现有实时抄表异常清洗业务,需要读取上报表计表获取接线方式以此来判断计量异常。
分析过程:1、数据类型:用采大数据平台的数据是通过前置机获取的采集数据;
2、字段嵌套:存储不需嵌套;
3、数据结构:采集数据为前置机统一配置的模板,结构稳定为结构化数据;
4、读表形式:采集成功率为批量侧离线处理方式,需要全行读取;
5、是否过滤:采集成功率是计算实采点数/应采点数,取表方式无需过滤
6、存储格式:根据以上分析存储格式的适应性分析可知,存储格式选择为protobuf。
现将用采大数据平台迁移存储决策树模型按照分析过程建立表2-1所示模型数据集合,为后期的决策数建立依据;
表2-1异构数据源属性集合
根据表2-1所示kafka数据源属性集合,建立的决策树图如图3所示。
1.2最优化存储模型
实际应用中,应用场景及需求情况复杂通常会出现一表多需求的情况,多格式的存储结果。对于日增长数据量很大的数据源,如:{采集数据,原始报文,操作日志,结果数据},这类数据对存储空间需求大,且对表操作频率不多,采用“轻存储,易操作”原则;对于日增量不大的微增长数据源,如:{档案数据,统计数据,异常日志},这类数据对存储空间需求小,且对表操作频率高,灵活性要求高,采用“易操作,轻存储”原则。
对于增长频率规律的日增长数据,根据“轻存储,易操作”,以及增长量(增长记录数),定价的权重如下表所示:
日增长数据存储格式权重表
对于数据量增长无规律且增长量不大的数据,根据“易操作,轻存储”,以及存储量(记录数),定价的权重如下表所示:
微增长数据存储格式权重表
结合实际场景需求,对json、normal、protobuf分别赋予权重,当出现多格式存储时,按权重大小排序,以权重值最大的存储为准。
1.3模型验证
1.3.1迁移存储决策模型
异构数据迁移验证数据表计档案低压表迁移至hbase中,其数据量为5100w+记录。
a)验证方法
结合strom实时抄表的实时交互、负荷清洗档案查询业务、前端页面实时展示业务等实时交互场景及各场景的属性如下所示:
b)验证结果
通过决策树模型,得到的存储结果集为场景一:normal;场景二:json;场景三:normal;属于一对多表的形式,将存储格式结果集最优化存储模型中,根据微增长数据源数据量5100w+条记录,选中权重集合ω’2,protobuf=0.2,json=0.3,normal=0.5,此时normal(0.5)>json(0.3),根据权重最大化选取原则,最优的存储格式为normal。
c)验证结论
通过最优存储优化方法模型在多业务场景需求下,最终表计档案低压表选择的存储格式是normal与轻量级存储格式json相比较,其在存储占用和读取效率如下表所示:
异构迁移表计档案低压测试结果表
从上表可知,通过最优化存储资源模型策略,在读取效率上normal优于json格式,满足“易操作,轻存储”原则。
1.3.2kafka数据源决策模型
kafka数据源通常是通过前置机采集上送的数据,数据结构无规则,具有:结构化、半结构化、非结构化特征,选用的数据特征在异构数据迁移特征基础之上增加结构化数据特征,具体的特征包含:{数据类型,字段嵌套,数据结构,读表形式,是否过滤}。
本研究若将kafka消息队列日增长量为5.3亿+条记录的高频负荷采集数据存储至hbase作为数据源验证基于决策模型的hbase存储资源最优化方法的可靠性。
a)验证方法
结合前端页面展示、采集成功计算、历史数据清洗补全等业务场景及各场景的属性如下所示:
b)验证结果
将场景输入决策树模型中,输入存储结果为场景一:json;场景二:json;场景三:normal;属于一对多表的形式,将存储格式结果集输入最优模型中,根据日增长数据量5.3亿+条记录,选中权重集合ω3,protobuf=0.5,json=0.3,normal=0.2,此时json(0.3)>normal(0.2),根据权重最大化选取原则,最优的存储格式为json。
c)验证结论
通过最优存储优化方法模型在多业务场景需求下,最终低压负荷数据选择的存储格式是json与传统的noraml相比较,其在存储占用和读取效率如下表所示:
低压负荷实时实时入库测试结果表
从上表可知,通过最优化存储资源模型策略,在对于日增长大的存储需求,选用json存储格式在读取效率及存储上明显优于normal格式,满足“轻存储,易操作”原则。
总结:本技术方案通过对用电信息采集系统多业务需求现状进行分析,对交互需求特征进行了提炼,并基于决策树模型的hbase存储资源优化的存储选择方法,提出电力用能数据基于hbase存储优化标准。电力用能数据基于hbase存储根据业务场景的存储格式的交叉性分为:单存储规范和多存储优化规范,其中:
单存储规范:是指根据交叉业务场景需求和数据规模,经过决策树分类算法的hbase存储格式是一致的,其最优化存储格式依照决策模型的存储格式定义。
多存储优化规范:是指交叉业务场景需求和数据规模,经过决策树分类算法的hbase存储格式不同出现一对多表的情况,此时需要根据存储最优化模型,进行进一步的优化选择。其选择的原则是根据存储格式权重最大化原则进行选取。
通过基于决策树模型的hbase存储最优化模型,合理的存储格式制定,将有助于更便捷为需求方提供交互服务,将节省大量电力用能数据的存储资源,提高用采大数据平台资源利用率,提高整个平台的读写效率。有助于为后期用采大数据平台的存储格规范选择上,提供标准化参考依据。
以上图1所示的一种基于决策树模型的电力用能数据存储优化方法是本发明的具体实施例,已经体现出本发明实质性特点和进步,可根据实际的使用需要,在本发明的启示下,对其进行形状、结构等方面的等同修改,均在本方案的保护范围之列。
- 还没有人留言评论。精彩留言会获得点赞!