一种智能车站反刷票方法和反刷票系统与流程
本发明涉及智能交通领域,更具体地,涉及一种智能车站反刷票方法和反刷票系统。
背景技术:
随着信息技术不断发展,互联网技术和物联网技术为人们的生活带来了极大的便利。其中,高铁、普通列车的购票方式也主要从线下改成线上。但购票方式网络化也带来黄牛等违倒卖车票的行为大量出现,黄牛凭借优于普通用户的购票技术条件,大量抢票囤票,影响了广大普通用户的出行。现有技术主要是候补购票以及对高频次发起购票请求的ip进行针对性封禁两个手段。
2018年年底上线的候补购票能很大程度上缓解黄牛刷票的问题。但是仍旧无法解决第一批次放票以及黄牛自身也利用大量用户账号也进行候补购票的问题。特别的,部分用户刷票速度过快,但是非团伙刷票行为,单纯只是购买自身出行需要的车票,这种情况下单纯依靠封禁请求频率过高的ip,可能导致错误封禁该非黄牛用户的ip。
技术实现要素:
本发明为克服上述现有技术所述的反刷票技术仍旧无法解决第一批次放票以及黄牛自身也利用大量用户账号也进行候补购票的问题的缺陷,提供一种智能车站反刷票方法和反刷票系统。
所述智能车站反刷票方法包括以下步骤:
s1:将历史购票数据集存入大数据计算分析系统的hive数据仓库中,并进行数据预处理,得到下一步算法需要的各个指标点;
s2:使用k-means算法进行按账号作为用户唯一标识进行用户画像构建并存储;
s3:构建模糊神经网络模型,使用历史数据结合用户画像生成训练集,并由专家统计分析给出算法所需隶属函数,进而训练模糊神经网络模型;
s4:采用经过训练的模糊神经网络,对实时购票请求进行分析处理,得到的结果反馈给下游业务系统;业务系统接收分析处理结果,根据惩罚规则进行放行或惩罚。
优选地,s1包括以下步骤:
s1.1:在大数据计算分析系统的hive中建立购票请求数据表和用户账号数据表;并将往年历史数据导入两张表中;
s1.2:根据请求多种原始购票和账号数据统计出以下的数据指标:
"user_id":"用户账号",
"t_idser":"身份证号码",
"t_most_type":"成功订单座位类型总数的有座与无座次数差值",
"user_prefer_src":"常用乘车的出发站点",
"user_prefer_des":"最多次数乘车的目的地站点",
"user_gps":"设备定位地址(如果购票方式是通过手机)",
"ip_location":"发出请求的ip归属地(默认为unknow)",
"req_density":"每秒请求次数",
"check_time_avg":"平均请求时间间隔",
"user_address":"推测居住地"。
s1.3:根据s1.2的统计结果统计出以下的数据指标:
"user_id":"用户账号",
"t_idser":"身份证号码",
"user_gps_count":"手机购票次数",
"check_time_avg":"平均请求时间间隔",
"t_most_type":"成功订单座位中的有座票与无座票次数差值",
"user_address_req_ratio":"于推测居住地发起购票次数于与总购票次数比值"。
s1.3得到的数据将用于k-means算法的输入数据集。
优选地,推测居住地的推测方法为:
若存在移动设备定位地址则使用最多次相同定位地址为准,若不存在则使用user_prefer_src的所在城市作为推测居住地"。
优选地,步骤s2中通过大数据计算平台中的flink计算引擎利用k-means算法进行用户画像的构建,最终得到的用户画像。用户画像包含多个指标数据,最关键的指标是系统处理用户购票请求的优先度,优先度为1-5,数字越高表示越优先处理,s2包括以下步骤:
s2.1:构建系统处理用户购票请求的优先度规则,优先度为1-5,数字越高表示越优先处理:
手机购票次数越多的用户,优先度增加;
ip或账号的单个时间内请求次数也就是频率越大,优先度降低;
购票ip归属地长期非账户推测居住地,优先度降低;
t_most_type的值高于所有用户的平均水平,优先度越高。
s2.2:s1.3的数据中,user_id和t_idser只是标识数据所属于哪个用户,不参与相似度计算。通过对user_id和t_idser两个指标以外的指标进行归一化,然后根据s2.1的优先度规则给出五个初始训练样本,从上到下对应优先级5至1:
(x1,y1,1.00,0.00,1.00,1.00,5),
(x2,y2,0.80,0.25,0.80,0.80,4),
(x3,y3,0.50,0.50,0.50,0.50,3),
(x4,y4,0.25,0.80,0.25,0.25,2),
(x5,y5,0.00,1.00,0.00,0.00,1)
其中,上述五个样本的格式为:(user_id,t_idser,user_gps_count_normal,check_time_avg_normal,user_address_req_ratio_normal,t_most_type_normal,pri_label);
pri_label为优先级标签,后缀为_normal的表示原字段值归一化后的结果
x1-x5,y1-y5分别表示不同的user_id,t_idser;
s2.3:根据s2.2给出的五个自定义样本点作为簇中心,从上到下分别为μ1,μ2,μ3,μ4,μ5,将s1.3中所描述的预处理后的用户购票;
使用s2.2给出的五个自定义样本点为中心,使用kmeans算法将历史数据集中的所有数据聚集成为5类优先级数据(也可理解为分成5类优先级)。比如a数据聚集在给出μ1样本点周围,而μ1样本点数属于优先级5级的数据,那么a会被认为属于5级优先级数据。
历史数据集作为输入;每条数据称为一个样本xm,m∈[1,n],n表示数据总数;按照以下过程进行计算:
(1)计算每个样本xm与各“簇中心”向量的欧式距离,根据距离最近的“簇中心”向量确定xm的簇标记:
γm=argmin||xm-μi||2,i=1,2,…5
其中argmin是使目标函数取最小值时的变量值。
(2)更新各个簇中心:
其中ni表示为属于簇i的样本总数;
(3)判断簇标签是否达到收敛精度,若达到,则输出各簇中心;若未达到,则返回步骤(2);直到簇标签达到预设的收敛精度为止;
s2.4:通过flink计算引擎得出的处理优先度,还需在计算中关联s1所述历史数据中每个账号本身的其他数据,由于通过s2.3用用户数据计算出了每个用户的请求处理优先级顺序,但是用户画像除了优先级外还需要别的更丰富的特征,所有需要以用户id(user_id)为分辨标识,将刚算好的优先级和之前s1.2中的部分特征组合一起,成为多个特征的用户画像数据。从而每个用户id都有自己的画像数据。也称为关联某数据。
,才是完整的用户画像数据,完整数据格式为:
"user_id":"用户账号","t_idser":"身份证号码",
"user_prefer_src":常用的乘车出发站点,
"user_prefer_des":"常用的乘车目的地站点,
"user_address":"推测居住地,
"pri_label":"请求的处理优先级";
上述格式的数据直接存储至redis数据库中,在售票期间供实时计算过程使用。
优选地,s3需要构建并训练模糊神经网络,并使用flink计算引擎的利用训练后的算法模型实时辨识购票请求是否属于黄牛的异常购票行为,并将识别后的结果发送给下游业务系统,s3包括以下步骤:
s3.1:提出购票期间的异常购票行为识别根据:
(1)同一ip或者账号请求频率大于正常行为数据集得到的均值;
(2)同一ip或者账号购票请求包含不同乘车人数量大于正常平均值;
(3)同一ip或者账号以大于正常平均值的次数购买自身画像定义常来往车站之外的车站车票的次数;
(4)s2.4中获得的处理优先级,缺失则默认为(3);
以上包含的正常行为平均值数据在进行历史数据分析时一并计算得出并存入数据库用于下一步训练模型和实时计算中使用。
s3.2:建立并训练模糊神经网络模块模型,内容包括:
s3.3:利用训练后的模型完成计算任务;
1)将经过训练的模型文件,存储到大数据计算分析系统中等待调用;
2)实时购票数据进入运行中的计算分析系统进行计算;
3)将输出的y值交给下游业务系统。
其中,y值是用户实时购票请求数据所展现的特征,表示跟黄牛刷票行为的特征的相似度是多少,为0.0到1.0中间的一个数。
优选地,s3.2包括以下步骤:
s3.2.1:确定数据来源:
实时计算中,将实时请求数据提取后将进行计算,并不断累积同账号的购买行为参数。实时的用户请求数据结合s2.4存至redis的用户画像数据,得到的计算样本将是4个维度的向量,在训练模型时使用历史请求数据一样可以获得以下指标参数:
"req_frequence":"100ms内请求频率","t_user_count":"包含不同乘车人数量",
"t_station_count":"购买常来往车站之外的次数,
"pri_label":"请求的处理优先级"。
s3.2.2:建立模糊神经网络模型:
1)输入层:将4个维度的向量中内个维度的值用xm表示,即向量(x1,x2,x3,x4)为的模糊神经网络的输入;
2)模糊化层:每个特征,即xm的隶属函数由专家根据不同历史数据集统计分析给出,根据函数定义域划分为若干个函数分支,每个分支对应模糊化层的一个节点;
例如(x1,x2,x3,x4)对应的八组隶属函数分别有3、5、3、5个分支,其中μ1i(x1),i=1,2,3;μ2i(x2),i=1,2,3,4,5;…;μ4i(x4),i=1,2,3,4,5;其中,μ1i(x1),i表示。
故模糊化层一共10个节点;并且每个节点根据本身代表的隶属函数与上一层中跟这个隶属函数对应的特征输入节点相连;即模糊化层输出为:
4)与层:与层的节点数量为模糊规则数,模糊化层中共四组节点,四个组中分别选出一个与其他组选出的一个节点连接,所以与层一共有3*5*3*5=225个节点;每个节点的输出为上一层输入到这个节点的所有信号的乘积,即
5)或层:节点数按照输出变量模糊度划分的个数确定,输出变量为当前数据属于刷票行为数据的可能性,所以或层有1个节点,每个节点与上一层为全互连,连接权值为
6)反模糊化层:反模糊化层输出1个结果,也就是有1个节点,节点的输出就是上一层所有节点的乘积再乘以上层节点到本层节点的权值
数值y即当前样本属于黄牛刷票行为的可能性,是一个0到1之间的小数。
s3.2.3:训练模糊神经模型得到经过训练的模糊神经网络;
优选地,s3.2.3中训练模糊神经模型使用的激活函数是relu函数(线性整流函数),其表达式为y=max(x,0),具体训练过程为:
s3.2.3.1:训练数据分为两类,正常和异常购票行为;将输出y定为其中一种;
s3.2.3.2:选择样本集合的一个样本(x,label),x为数据,label为x所属类别;
s3.2.3.3:将样本送入模糊神经网络,计算模糊神经网络的实际输出y;
s3.2.3.4:计算损失函数
s3.2.3.5:根据误差loss调整权重矩阵w;
s3.2.3.6:对每个样本重复上述过程,直到整个样本集的误差不超过规定范围,一般预测准确率达到93%以上。
优选地,s4包括以下步骤:
s4.1:提出以下惩罚处理规则:
将请求数据代入训练完毕的模糊神经网络模型进行计算,计算结果是一个概率值,表示此短时间内此账号购票行为是黄牛刷票的可能性,
设计算结果0.0-0.1,0.1-0.2,0.2-0.4,0.4-0.7,0.7-0.9,0.9-1.0分别表示当前购票行为数据是黄牛刷票的可能性为0到5级一共六种;
依次对应六种惩罚方式分别为:
0级放行,1级ip延后处理5%,2级ip延后处理10%,3级ip延后处理40%,4级ip延后处理90%,5级ip直接封禁。
s4.2:根据s4.1给出的惩罚等级进行惩罚处理;
根据s4.1给出的惩罚等级,如果是0级则直接正常处理,1级以上则根据不同等级对应的延后处理百分比,将当前需要惩罚的用户请求放到全量请求队列的前百分之多少进行排队等候或者直接封禁。
本发明中用户画像构建的整体流程,先用hive数据完成预处理,然后使用flink计算引擎基于kmeasn算法进行用户特征聚类得出优先度,最后flink将每个账号对应的用户购票请求处理优先度和预处理的数据中其他有代表性的用户特征参数,一并写入redis数据库。至此完成用户画像构建。
本发明基于kmeans算法实现用户行为特征分类。先提出关于优先度分级的四个规则。涉及使用手机购票次数、请求频率、请求的ip归属地、成功购票订单座位类型四个方面。然后进行用户画像的特征选择,包括常用的乘车出发站点、推测居住地等多个特征。给出五个对应优先级5至1的初始聚类中心。最后,根据给出的五个初始聚类中心作为簇中心,预处理后的用户购票历史数据集作为输入,按照kmeans算法通用的计算过程完成聚类任务。
此外,本发明还提出购票期间的异常购票行为识别根据,包括:同一账号或ip的请求频率、同一账号或ip下单不同乘车人的数量、同一账号或ip购买自身画像定义的常来往车站之外的其他车站车票次数。
本发明所述算法的输入参数选型、算法的输出。包括:
输入:实时的用户请求数据结合s2.4存至redis的用户画像数据,得到的计算样本将是4个维度的向量。
输出:一个概率值,表示短时间内此账号的综合购票行为是黄牛刷票的可能性。
本发明还提出根据模糊神经网络计算结果分出六种惩罚级别的办法。包括:模糊神经网络的计算结果0.0-0.1,0.1-0.2,0.2-0.4,0.4-0.7,0.7-0.9,0.9-1.0分别表示当前购票行为数据是黄牛刷票的可能性为0到5级一共六种。
然后指定各级别的惩罚方式,包括:0级放行,1级ip延后处理5%等。其中延后处理百分比是指将当前需要惩罚的用户请求放到全量请求队列的前百分之多少进行排队等候或者直接封禁。
本发明所述智能车站反刷票系统包括:数仓工具hive、数据库、计算引擎flink、历史数据行为分析模块、模糊神经网络算法模块、后台业务系统模块;
数据库存储历史数据;
数仓工具hive用来完成数据预处理;
计算引擎flink完成离线计算任务,也就是历史购票行为数据分析;
历史数据行为分析模块将经过预处理后的历史购票数据,利用k-means算法进行用户画像的构建,最终得到的用户画像;
模糊神经网络算法模块首先对模糊神经网络模型使用历史购票数据进行训练;购票请求经过使用flink计算引擎的计算分析,调用经过训练的模糊神经网络算法,结合账号对应的用户画像和本文将会介绍的三个规则辨识购票请求是否属于黄牛的异常购票行为,最后将识别后的结果发送给后台业务系统;
后台业务系统根据模糊神经网络算法模块的识别结果进行相应的购票限制;分别为无需延后处理,延后处理5%、10%、40%、90%、ip直接封禁六个限制级别进行购票限制;惩罚百分比指的是将当前需要惩罚的用户请求放到全量请求队列的前百分之多少进行排队等候或者直接封禁。
本发明算法模型与整个系统的整合应用,先定义四个维度的输入数据格式,确定输出,根据经典的或专家给定的隶属度函数,完成模糊化层构建,后续按照模型自身规则完成与层、或层、反模糊化层的构建。然后使用历史购票数据进行模型训练,得到经过训练的模糊神经网络,最后将模型代码文件通过flink计算引擎实现工程应用,完成实时反刷票业务。
与现有技术相比,本发明技术方案的有益效果是:
(1).目前已有的系统直接对请求频率过高的ip进行封禁,本发明提出根据多个其他维度的判断依据,可以更准确地涵盖刷票行为的相关特征,使用模糊神经网络计算出属于黄牛行为的可能性,可以根据本发明提出的不同惩罚手段,避免了部分非黄牛用户某些特殊情况下被封禁ip的风险。
(2).此外,2018年底上线的候补购票能很大程度上缓解黄牛刷票的问题。但是仍旧无法解决第一批次放票以及黄牛自身利用大量用户账号也进行候补购票的问题。本发明通过历史数据分析的相关指标为依据,加上模糊神经网络模型,在购票期间对用户类别进行实时鉴定,可以有效解决上述问题。
(3)本发明使用模糊神经网络,其中的隶属函数可以根据历史数据分析统计,或者根据专家经验进行给出,可以很好地解决一些模糊的度量概念,比如购票请求频次过高,多少属于过高,频次属于高的范畴下是否有多个不同范围,这有利于对刷票行为严重性进行分辨,从而可以得到刷票行为的严重级别,针对性采取惩罚方式。
附图说明
图1为实施例1所述智能车站反刷票方法流程图;
图2为模糊神经网络架构图;
图3为实施例2所述智能车站反刷票系统示意图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
实施例1
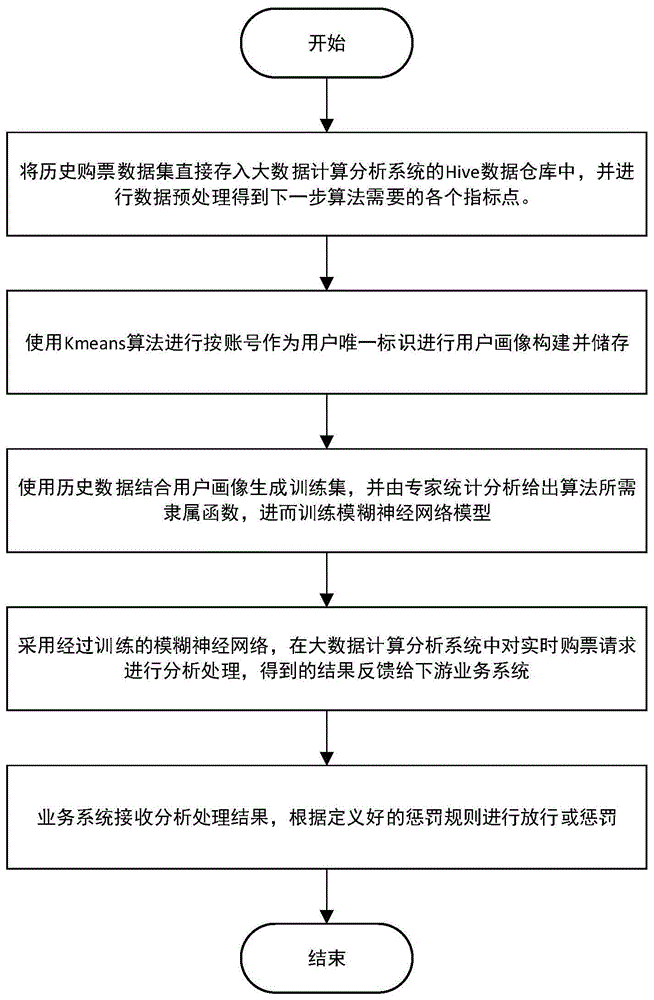
本实施例提供一种智能车站反刷票方法,如图1所示,所述方法包括以下步骤:
s1:将历史购票数据集存入大数据计算分析系统的hive数据仓库中,并进行数据预处理,得到下一步算法需要的各个指标点;
s2:使用k-means算法进行按账号作为用户唯一标识进行用户画像构建并存储;
s3:构建模糊神经网络模型,使用历史数据结合用户画像生成训练集,并由专家统计分析给出算法所需隶属函数,进而训练模糊神经网络模型;
s4:采用经过训练的模糊神经网络,对实时购票请求进行分析处理,得到的结果反馈给下游业务系统;业务系统接收分析处理结果,根据惩罚规则进行放行或惩罚。
下面结合图1对本实施例进行详细说明:
s1:将历史购票数据集存入大数据计算分析系统的hive数据仓库中,并进行数据预处理,得到下一步算法需要的各个指标点;
s1.1:在大数据计算分析系统的hive中建立购票请求数据表和用户账号数据表。并将往年历史数据导入两张表中。
s1.2:根据请求多种原始购票和账号数据统计出以下的数据指标:
"user_id":"用户账号",
"t_idser":"身份证号码",
"t_most_type":"成功订单座位类型总数的有座与无座次数差值",
"user_prefer_src":"常用乘车的出发站点",
"user_prefer_des":"最多次数乘车的目的地站点",
"user_gps":"设备定位地址(如果购票方式是通透手机)",
"ip_location":"发出请求的ip归属地(默认为unknow)",
"req_density":"每秒请求次数",
"check_time_avg":"平均请求时间间隔",
"user_address":"推测居住地,若存在移动设备定位地址则使用最多次相同定位地址为准,若不存在则使用user_prefer_src的所在城市作为推测居住地"。
s1.3:根据s1.2的计算结果统计出以下的数据指标:
"user_id":"用户账号",
"t_idser":"身份证号码",
"user_gps_count":"手机购票次数",
"check_time_avg":"平均请求时间间隔",
"t_most_type":"成功订单座位中的有座票与无座票次数差值",
"user_address_req_ratio":"于推测居住地发起购票次数于与总购票次数比值"。
本实施例s1.3得到的数据将用于下一步k-means算法的输入数据集。s1.3所提出的各种参数,是本实施例研究与设计的计算指标,并对其他模块的业务有重要作用。
s2:使用k-means算法进行按账号作为用户唯一标识进行用户画像构建并存储;
步骤s2中通过大数据计算平台中的flink计算引擎利用k-means算法进行用户画像的构建,最终得到的用户画像。用户画像包含多个指标数据,最关键的指标是系统处理用户购票请求的优先度,优先度为1-5,数字越高表示越优先处理,具体步骤包括:
s2.1:提出以下规则
手机购票次数越多的用户,优先度增加。
ip或账号的单个时间内请求次数也就是频率越大,优先度降低。
购票ip归属地长期非账户推测居住地,优先度降低。
t_most_type的值高于所有用户的平均水平,优先度越高。
s2.2:s1.3的数据中,user_id和t_idser只是标识数据所属于哪个用户,不参与相似度计算。通过对上述两个指标以外的指标进行归一化,然后根据s2.1规则给出五个初始训练样本,从上到下对应优先级5至1。
(x1,y1,1.00,0.00,1.00,1.00,5),
(x2,y2,0.80,0.25,0.80,0.80,4),
(x3,y3,0.50,0.50,0.50,0.50,3),
(x4,y4,0.25,0.80,0.25,0.25,2),
(x5,y5,0.00,1.00,0.00,0.00,1)
其中,上面五个样本的格式为:
(user_id,t_idser,user_gps_count_normal,check_time_avg_normal,user_address_req_ratio_normal,t_most_type_normal,pri_label)
pri_label为优先级标签,后缀为_normal的表示原字段值归一化后的结果;x1-x5,y1-y5分别表示不同的user_id,t_idser。
s2.3:根据s2.2给出的五个自定义样本点作为簇中心,从上到下为μ1,μ2,μ3,μ4,μ5,将s1.3中所描述的预处理后的用户购票;
历史数据集作为输入。每条数据称为一个样本xm,m∈[1,n],n表示数据总数。按照以下过程进行计算:
s2.3.1:计算每个样本xm与各“簇中心”向量的欧式距离,根据距离最近的“簇中心”向量确定xm的簇标记:γm=argmin||xm-μi||2,i=1,2,…5。
其中argmin是使目标函数取最小值时的变量值。
s2.3.2:更新各个簇中心。
s2.3.3:直到簇标签达到预设的收敛精度为止,否则重复s2.3.2-s2.3.3步的计算。
收敛精度可以多次训练选择最好的收敛精度,本实施例初次可以设置为精度为0.05。
s2.4:通过flink计算引擎得出的处理优先度,还需在计算中关联s1所述历史数据中每个账号本身的其他数据,才是完整的用户画像数据,完整数据格式为"user_id":"用户账号","t_idser":"身份证号码",
"user_prefer_src":常用的乘车出发站点,
"user_prefer_des":"常用的乘车目的地站点,
"user_address":"推测居住地,
"pri_label":"请求的处理优先级"。
这些格式的数据直接存储至redis数据库中。在售票期间供实时计算过程使用。
s3:构建模糊神经网络模型,使用历史数据结合用户画像生成训练集,并由专家统计分析给出算法所需隶属函数,进而训练模糊神经网络模型;
s3需要构建并训练模糊神经网络,并使用flink计算引擎的利用训练后的算法模型实时辨识购票请求是否属于黄牛的异常购票行为,并将识别后的结果发送给下游业务系统,具体步骤包括:
s3.1:提出以下三种购票期间的异常购票行为识别根据:
(1)同一ip或者账号请求频率大于正常行为数据集得到的均值。
(2)同一ip或者账号购票请求包含不同乘车人数量大于正常平均值。
(3)同一ip或者账号以大于正常平均值的次数购买自身画像定义常来往车站之外的车站车票的次数。
(4)s2.4中获得的处理优先级,缺失则默认为3。
以上包含的正常行为平均值数据在专人进行历史数据分析时一并计算得出并存入数据库用于下一步训练模型和实时计算中使用。
s3.2:建立并训练模糊神经网络模块模型,内容包括:
s3.2.1:确定数据来源:
实时计算中,将实时请求数据提取后将进行计算,并不断累积同账号的购买行为参数。实时的用户请求数据结合s2.4存至redis的用户画像数据,得到的计算样本将是4个维度的向量,在训练模型时使用历史请求数据一样可以获得以下指标参数:
"req_frequence":"100ms内请求频率","t_user_count":"包含不同乘车人数量",
"t_station_count":"购买常来往车站之外的次数,
"pri_label":"请求的处理优先级"。
s3.2.2:建立模型,如图2所示:
1)输入层:将4个维度的向量中内个维度的值用xm表示,即向量(x1,x2,x3,x4)为的模糊神经网络的输入;
2)模糊化层:每个特征即xm的隶属函数由专家根据不同历史数据集统计分析给出,根据函数定义域划分为若干个函数分支,每个分支对应模糊化层的一个节点。
例如(x1,x2,x3,x4)对应的八组隶属函数分别有3、5、3、5个分支,其中μ1i(x1),i=1,2,3;μ2i(x2),i=1,2,3,4,5;…;μ4i(x4),i=1,2,3,4,5
故模糊化层一共10个节点。并且每个节点根据本身代表的隶属函数与上一层中跟这个隶属函数对应的特征输入节点相连。即模糊化层输出为
4)与层:这层的节点数量为模糊规则数,模糊化层中共四组节点,四个组中分别选出一个与其他组选出的一个节点连接,所以与层一共有3*5*3*5=225个节点。每个节点的输出为上一层输入到这个节点的所有信号的乘积即:
5)或层:节点数按照输出变量模糊度划分的个数确定,本设计一共只会有一种输出,即是当前数据属于刷票行为数据的可能性,所以这一层有1个节点,每个节点与上一层为全互连,连接权值为
6)反模糊化层:本设计中在这一层输出1个结果,也就是有1个节点,节点的输出就是上一层所有节点的乘积再乘以上层节点到本层节点的权值
数值y即当前样本属于黄牛刷票行为的可能性,是一个0到1之间的小数。
如图2所示,本实施例以x1、x2、x3、x4对应的四组隶属函数分别有3、5、3、5个分支为例。
s3.2.3:训练模型得到经过训练的模糊神经网络
其中,使用的激活函数可以是relu函数(线性整流函数),其表达式为y=max(x,0)。具体训练过程为:
1)训练数据分为两类,正常和异常购票行为。将输出y定为其中一种;
2)选择样本集合的一个样本(x,label),x为数据,label为x所属类别;
3)样本送入网络,计算网络的实际输出y;
4)计算损失函数
5)根据误差loss调整权重矩阵w;
6)对每个样本重复上述过程,直到整个样本集的误差不超过规定范围(预测准确率93%以上)。
s3.3:训练后的模型完成计算任务
1)将经过训练的模型文件,存储到大数据计算分析系统中等待调用;
2)实时购票数据进入运行中的计算分析系统进行计算;
3)将输出的y值交给下游业务系统。
其中,y值是用户实时购票请求数据所展现的特征,表示跟黄牛刷票行为的特征的相似度是多少,为0.0到1.0中间的一个数。
s4:采用经过训练的模糊神经网络,对实时购票请求进行分析处理,得到的结果反馈给下游业务系统;业务系统接收分析处理结果,根据惩罚规则进行放行或惩罚。
此模块根据s3的识别结果进行相应的购票限制。一共有无需延后处理,延后处理5%、10%、40%、90%、ip直接封禁六个级别的处理控制。具体内容如下:
s4.1:提出以下惩罚处理规则:
将请求数据进行代入训练完毕的模糊神经网络模型进行计算,计算结果是一个概率值,表示此短时间内此账号购票行为是黄牛刷票的可能性,
计算结果0.0-0.1,0.1-0.2,0.2-0.4,0.4-0.7,0.7-0.9,0.9-1.0分别表示当前购票行为数据是黄牛刷票的可能性为0到5级一共六种。
惩罚方式分别为:
0级放行,1级ip延后处理5%,2级ip延后处理10%,3级ip延后处理40%,4级ip延后处理90%,5级ip直接封禁。
s4.2:惩罚处理
根据上一个步骤给出的惩罚等级,如果是0级则直接正常处理,1级以上则根据不同等级对应的延后处理百分比,将当前需要惩罚的用户请求放到全量请求队列的前百分之多少进行排队等候或者直接封禁。
实施例2
本实施例提供一种智能车站反刷票方法,应用于智能车站(高铁站或者火车站)下反刷票,使用车站票务系统历史数据,以及基于kmeans算法实现用户行为分类。运营期间产生实时的购票数据时,结合用户画像数据,经过大数据实时计算分析平台的模糊神经网络计算得出刷票请求是否属于刷票行为的结果,并交由下游业务系统决定是否需要惩罚以及如何惩罚。
如图3所示,本实施例所述系统包含数仓工具hive、数据库、计算引擎flink、历史数据行为分析模块、模糊神经网络算法模块、后台业务系统模块
数据库为所述系统提供历史数据;
hive完成数据预处理,提供算法需要的数据。
计算引擎flink完成离线计算任务,也就是历史购票行为数据分析。
历史数据行为分析模块将经过预处理后的历史购票数据,利用k-means算法进行用户画像的构建,最终得到的用户画像,供下游实时计算业务使用。
模糊神经网络算法模块首先对模糊神经网络模型使用历史购票数据进行训练。售票系统运营期间,购票请求会经过使用flink计算引擎的计算分析,调用经过训练的模糊神经网络算法,结合账号对应的用户画像和本文将会介绍的三个规则辨识购票请求是否属于黄牛的异常购票行为,最后将识别后的结果发送给下游业务系统。
后台业务系统根据模糊神经网络算法模块的识别结果进行相应的购票限制。一共有无需延后处理,延后处理5%、10%、40%、90%、ip直接封禁六个级别的处理控制。
惩罚百分比指的是将当前需要惩罚的用户请求放到全量请求队列的前百分之多少进行排队等候或者直接封禁。
附图中描述位置关系的用语仅用于示例性说明,不能理解为对本专利的限制;
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!