一种面向稀疏数据的个性化情感分析方法与装置与流程
本发明涉及在数据稀疏的情况下利用用户文本数据对文本进行情感分析,属于机器学习技术领域。
背景技术:
用户生成文本情感分析旨在根据用户撰写的文本(如一条twitter或一条购物评论),计算得到一个相应的情感打分(如满意度)。传统的情感分析方法认为文本和情感打分之间的映射对所有的用户来说是相同的,即不区分用户之间的个体差异性。但是,这样的假设不符合实际情况。因为由于用户教育背景、社会经历等不同,他们情感表达方式也会有一定的区别,所以针对用户个性化情感分析十分有必要。而现有的一些个性化情感分析方法通常使用一个固定维度的用户向量来表示每个用户,用户向量通常是随机初始化然后由网络自己学习得到,这种用户表示方式对数据和网络的依赖性很强。根据网络统计结果显示,twitter的大部分用户是很少发twitter,而将近80%的twitter是由10%的活跃用户发出。这意味着在现实生活中,常常存在用户数据稀疏的情况,所以解决数据稀疏环境下的个性化情感分析问题有着十分重要的社会意义。
技术实现要素:
发明目的:为了克服现有技术中存在的不足,本发明提供了一种面向稀疏数据的个性化情感分析方法与装置,能够处理当前个性化情感分析中的数据稀疏问题。
技术方案:为实现上述目的,本发明所述的一种面向稀疏数据的个性化情感分析方法,包括如下步骤:
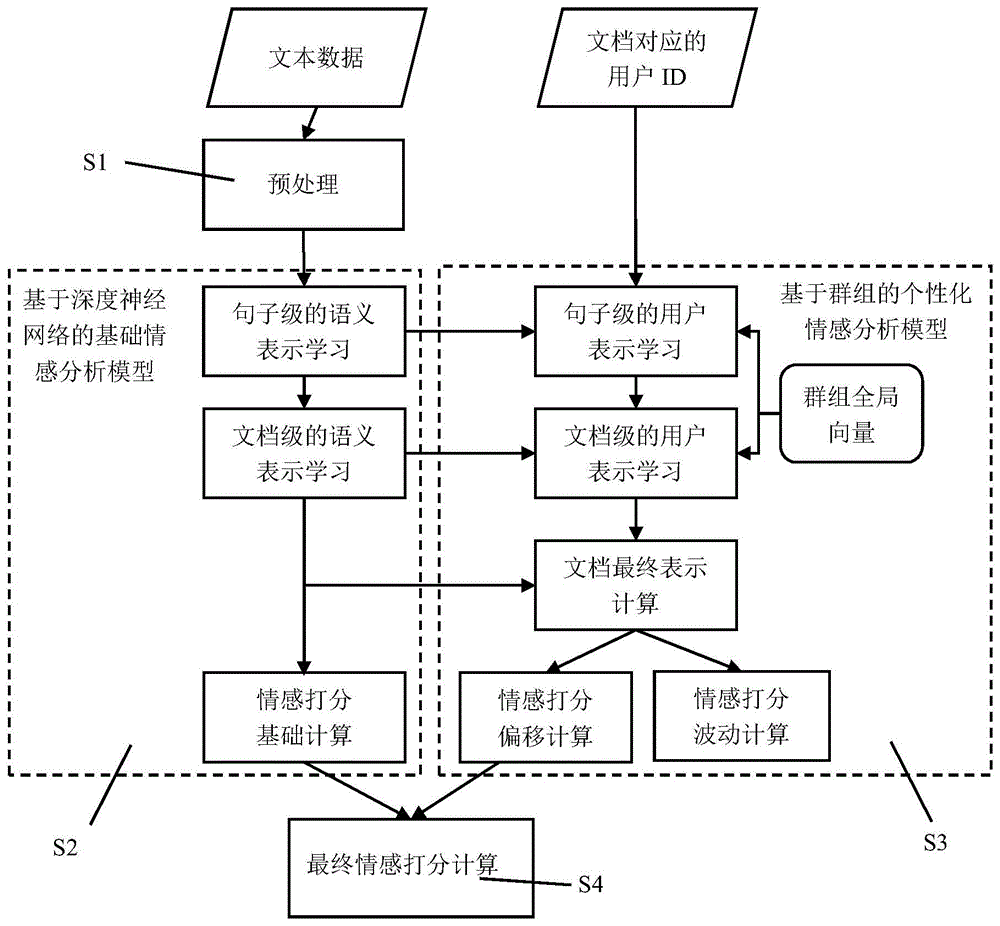
(1)对文档进行预处理;
(2)使用基于深度神经网络的基础情感分析模型,以文档的单词作为输入,通过句子级的语义表示学习和文档级的语义表示学习分别计算得到文档中每个句子的语义表示和文档的语义表示,并将文档的语义表示映射得到的数值作为情感打分基础;
(3)使用基于群组的个性化情感分析模型,以基于深度神经网络的基础情感分析模型得到的文档的语义表示、用户向量和全局群组向量作为输入,通过句子级的用户表示学习和文档级的用户表示学习分别计算得到文档中每个句子的用户表示和文档的用户表示,并将文档的用户表示和基于深度神经网络的基础情感分析模型得到的语义表示表示级联起来作为文档最终表示,并将文档的最终表示映射到两个数值分别作为情感打分偏移和波动;情感打分偏移用于最终的打分计算,情感打分波动用于网络的优化;
(4)将情感打分基础和情感打分偏移相加得到最终的情感打分。
进一步地,所述步骤(1)中的文档预处理包括:对文档进行分词,过滤掉文档中的停用词和所处理的数据集中仅出现一次的词。
进一步地,所述步骤(2)中的使用基于深度神经网络的基础情感分析模型计算情感打分基础包括:
(2.1)针对句子中的每个单词,先映射为一个预先训练好的词向量,然后利用双向长短记忆网络bi-lstm对句子中的每个词进行编码得到每个词的对应的隐状态;使用注意力机制计算每个词的权重;最后对每个词加权求和,得到每个句子的语义表示;
(2.2)是针对文档中的每个句子,以句子的语义表示作为输入,利用bi-lstm对文档中的每个句子进行编码得到每个句子的对应的隐状态;使用注意力机制计算每个句子的权重;最后对每个句子加权求和,得到文档的语义表示;
(2.3)使用一个多层感知器对文档级的语义表示映射到一个数值,即情感打分基础。
进一步地,所述步骤(3)中的使用基于群组的个性化情感分析模型计算情感打分偏移和波动包括:
(3.1)以bi-lstm中的每个词的隐状态、群组全局向量和文档对应的用户向量为基础,计算得到每个词的用户隐状态;使用注意力机制计算每个词对应的用户隐状态的权重;最后对每个词对应的用户隐状态加权求和,得到句子的用户表示;
(3.2)以bi-lstm中的每个句子的隐状态、群组全局向量和句子用户表示为基础,计算得到每个句子的用户隐状态;使用注意力机制计算每个句子用户的隐状态的权重;最后对每个句子的用户隐状态加权求和,得到文档的用户表示;
(3.3)将文档的语义表示和用户表示级联起来作为文档最终表示;
(3.4)使用两个多层感知机分别将文档最终表示映射到两个数值,即情感打分偏移计算和情感打分波动。
进一步地,句子的用户表示为:
其中,
ek是第k个群组的全局向量,
进一步地,文档的用户表示为:
其中,
进一步地,使用联合损失来对网络进行优化,包括:对基于深度神经网络的基础情感分析模型使用均方误差损失;对基于群组的个性化情感分析模型使用高斯惩罚损失,以实现从损失函数中学习得到情感波动,并减小波动过大的样本对网络的影响;加入基于群组向量的惩罚项使得学习得到的群组向量具有判别性;加入网络参数的l2正则化项避免过拟合。
进一步地,网络的损失函数定义为:
其中,
λ‖θ‖2是网络参数的l2正则化项,t是样本数量,
基于相同的发明构思,本发明所述的一种面向稀疏数据的个性化情感分析装置,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述计算机程序被加载至处理器时实现所述的面向稀疏数据的个性化情感分析方法。
有益效果:本发明方法相较于现有的个性化情感分析的方法,可以有效地处理现实生活中是普遍存在的个性化情感分析中的用户数据稀疏的问题,通过将一个用户的情感打分建立成服从高斯分布,考虑了用户情感打分的偏移和波动,可以提高个性化情感分析性能。
附图说明
图1是本发明实施例中的方法流程图。
图2是本发明实施例中的用户编码器(u-encoder)的在句子级的用户表示学习中的计算示意图。
具体实施方式
下面结合附图和具体实施例,进一步阐明本发明,应理解这些实例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
问题可以描述如下:对于一篇文档及其用户u,个性化的情感分析任务就是预测文档对应的情感打分y(如满意度打分,比如1-5分,1分表示不满意,5分表示很满意)。根据观察,由于用户具有一个一般化的情感表达方式,所以可以得到一个情感打分基础yb,而用户又因为个体化差异,存在情感打分的偏差ys和波动σ2,所以可以将预测的情感打分建模成服从高斯分布的值
本发明实施例的一种面向稀疏数据的个性化情感分析方法,如图1所示,主要包括如下步骤:。
s1:文档预处理:对文档进行分词,去掉文档中的停用词和数据集中仅出现一次的词,得到处理后的文档d,其中d包括m个句子,每个句子ci包括ni个单词。
s2:使用一个基于深度神经网络的基础情感分析模型计算得到情感打分基础,具体包括如下步骤:
(1)句子级的语义表示学习。首先是针对句子中的每个单词,先映射为一个预先训练好的词向量,则一个句子可以表示为
然后将
由于每个词对句子的语义表示的贡献不同,所以使用了注意力机制使得句子中的重要的词具有更高的权重,计算方式如下:
其中
(2)文档级的语义表示学习。bi-lstm对文档中的每个句子表示进行编码得到每个句子的对应的隐状态:
然后将
由于不同的句子对文档最终语义表示的贡献不同,进一步使用注意力机制计算每个句子的权重,计算方式如下:
其中
(3)情感打分基础计算。使用一个多层感知器对文档级的语义表示映射到一个数值,
即情感打分基础:
yb=mlp(rb)
s3:使用一个基于群组的个性化情感分析模型计算得到情感打分偏移和波动。假设共有k个组,每个组都有一个对应的全局向量ek,这个向量是随机初始化并且由网络自适应学习得到。具体包括如下步骤:
(1)句子级的用户表示学习。以每个词
然后,由于学习得到用户表示可能在数据稀疏的情况下不可靠,使用了基于群组表示门机制来对用户表示进行增强,具体计算方式如下:
其中
由于不同的词对句子的用户表示的贡献不同,进一步使用注意力机制计算每个词对应的用户隐状态的权重:
其中
(2)文档级的用户表示学习。以每个句子的隐状态
然后,由于学习得到用户表示可能在数据稀疏的情况下不可靠,使用了基于群组表示门机制来对用户表示进行增强,具体计算方式如下:
其中
由于不同的句子对文档的用户表示的贡献不同,进一步使用注意力机制计算每个句子对应的用户隐状态的权重:
其中
(3)情感打分偏移和波动计算。将文档的用户表示ru和基于深度神经网络的基础情感分析模型得到的语义表示rb级联起来的最终表示,使用两个多层感知机分别对文档级的最终表示进行映射:
ys=mlp([ru,rb])
σ2=mlp([ru,rb])
s4:结合情感打分基础yb、情感打分偏移ys和情感打分波动σ2,可以得到最终的预测结果
由于本发明可以被认为是多任务的结构,所以我们使用了联合损失来对网络进行优化。对于传统的一般化情感分析模型来说,我们使用了均方误差作为损失函数:
其中t是样本数量,
对于基于群组的个性化情感分析模型,我们使用高斯惩罚函数作为损失函数,包括两个部分:(1)基于情感波动的残差回归,以实现从损失函数中学习得到情感波动,并减小波动过大的样本对网络的影响;(2)一个情感波动的正则化项,以避免预测得到的情感波动过大。具体定义如下:
其中yt是第t个文档的基于群组的个性化情感分析模型输出最终情感打分,
另外,为了使得不同群组的全局向量具有一定的区分性,进一步引入了基于群组向量的惩罚项:
其中i是单位矩阵,e={e1,…,ek}是群组向量构成的矩阵,‖·‖f是矩阵的frobenius范数。
则网络的损失函数定义如下:
其中λ‖θ‖2是网络参数的l2正则化项。
本发明在实验过程中,实验参数设置如下:使用预训练好的glove作为词嵌入,词嵌入、用户和单词的隐状态维度均为300。dropout率为0.5,学习率为0.001,l2损失的权重为0.01。使用adam对网络进行优化,群组数目为6。在yelp2013的用户数据稀疏数据集上得到的rmse为0.7166,mae为0.5501,性能均优于现有的个性化情感分析方法。
本发明提出的一种面向稀疏数据的个性化情感分析方法与现有方法相比,考虑了个性化情感分析中的用户数据稀疏的问题,而这在现实生活中是普遍存在的,本方法通过将具有相似情感表达方式的用户分组,并且利用群组信息来进一步增强用户表示。同时,原有的方法通常将用户文本对应的情感打分考虑成一个单一的数值,而本方法将一个用户的情感打分建立成服从高斯分布,考虑了用户情感打分的偏移和波动,有利于提升个性化情感分析性能。
基于相同的发明构思,本发明实施例公开的一种面向稀疏数据的个性化情感分析装置,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,该计算机程序被加载至处理器时实现上述的面向稀疏数据的个性化情感分析方法。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!