一种基于行为大数据的统计学人格计算方法与流程
本发明涉及大数据处理技术领域,具体涉及一种基于行为大数据的统计学人格计算方法。
背景技术:
目前在高校内甚至在社会上,对人格计算的主流和广泛使用的方法还是自陈量表,所谓自陈量表,是指根据需要测量的人格特征编写与之对应的项目,然后要求被试者根据自己的实际情况或感受来评价其与项目描述的符合程度,从而最终对用户的人格特征进行评定的方法,其中比较著名的就是基于“五因素人格模型”理论的大五人格问卷。
对于自陈量表方法进行人格计算的价值,是不能否认的,然而由于自陈量表需要用户填写,不仅需要耗费大量的人力、物力,也难以有效实现针对大规模用户的实时测量,而且用户在接受调查的过程中存在着主观因素或有意回避真实的情况,导致人格计算结果的误差大,同时也会由于问题设置的比较多,也会引起用户的厌烦。
此外,随着互联网技术和计算机技术的发展,虽然很多专家和研究者已经通过使用网络上外显的行为数据进行人格计算的研究,其中包括对网络社交文本分析进行人格计算、对新闻评论分析进行人格计算、对微博用户的行为数据分析进行人格计算等,并且也取得了显著的研究成果,但是这些研究大多限制于单一的数据种类,例如只对社交类网站公开的网络数据进行研究,缺乏将高校中产生的社会活动外显行为数据及网络外显行为数据应用于人格计算的研究,同时这些研究是面向社会采集的、网站上公开的网络数据,移植到空间相对狭小的高校后很难采集到大量的符合上述研究要求的学生的网络数据,因此在高校中并不能发挥已有研究的优势之处。
技术实现要素:
本发明的目的在于提供一种基于行为大数据的统计学人格计算方法,其能够及时地、客观地反映学生的人格和人格的变化情况,提高了高校人格测量的客观性和准确性。
为实现上述目的,本发明采用以下技术方案:
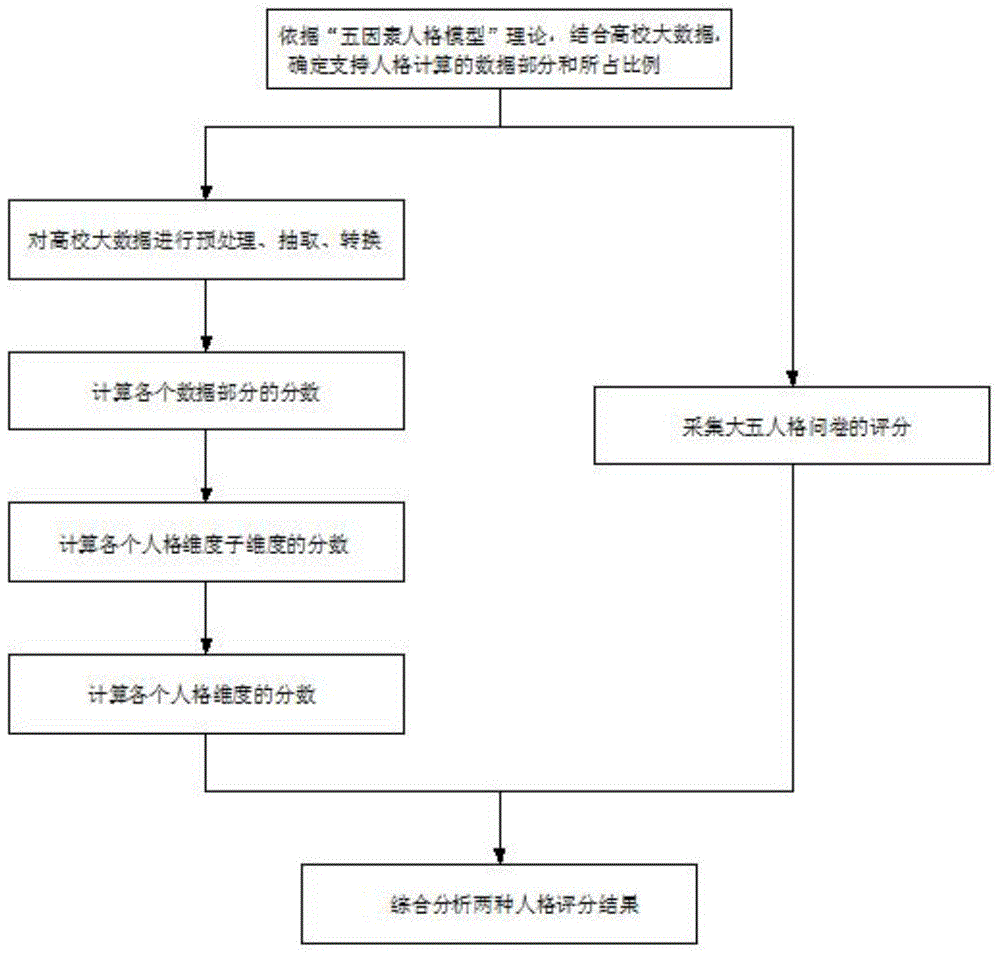
一种基于行为大数据的统计学人格计算方法,包括以下步骤:
s1、根据“五因素人格模型”理论,并结合高校积累的行为大数据,确定能够支持计算五个人格维度的人格子维度、各人格子维度分数的比例、支持人格子维度计算的数据部分及各个数据部分的分数的比例;
s2、对高校大数据进行预处理、抽取、转换操作,得到s1中确定的数据部分;
s3、计算各个数据部分的分数;
s4、根据s1中确定的人格子维度与数据部分的对应关系以及s3中数据部分的分数数据,计算各人格子维度的评分;
s5、根据s1中确定的五个人格维度与人格子维度的对应关系以及s4中各人格子维度的分数,计算五个人格维度的评分;
s6、采集大五人格问卷的评分;
s7、综合分析上述两种人格评分的结果,得出结论。
进一步地,s2步骤具体为:
s21、根据s1中确定的数据部分,爬取高校大数据中用户浏览的网页文本内容,使用分词工具并根据sc-liwc心理学词典,统计sc-liwc中的语言情感特征出现的次数及占总次数的比例,作为浏览网页文本内容的特征向量;
s22、根据s1中确定的数据部分,通过高校大数据中监控系统的人脸识别数据,获取识别到的人脸图像,再通过人脸表情识别程序分析并得到人脸图像中的表情数据;
s23、去除s21和s22中包含的非学生用户数据、空数据及错误数据;
s24、对经过s23预处理后的数据,根据s1数据部分的要求,对象上按用户、时间上按学期和周进行汇总,并对按周汇总的数据进行量化处理。
进一步地,s24步骤中,按周汇总数据的计算方式为:
汇总:
对按周汇总数据中规律性的行为通过标准差的方式进行量化处理,量化的计算方式如下:
标准差:
再通过求比例对汇总数据进行归一化处理,最终得到归一化后的数据(data_norm),计算方式如下:
归一化:
其中:
i为从上到下的第i个人格维度;
xi为第i个人格维度一周的汇总数据;
x为第i个人格维度一周的汇总数据result_data或量化后的数据s;
x*为第i个人格维度一周数据归一化后的数据(data_norm)。
进一步地,s3步骤包括:
s31、以5分制计算每个学生各数据部分的评分,并给出置信值brief_data,置信值的计算方式如下;
其中:
cur_data为当前学生的一个数据部分的量化值;
max_data该数据部分的最大量化值;
s32、根据s2处理后的每个数据部分,计算每个数据部分的全校平均值data_norm_avg;
s33、将每个数据部分的全校平均值扩大倍数α,并根据平均值和扩大倍数α得到评分的标准分数线;
s34、根据标准分数线,结合s2中处理后的数据部分,对每个学生的每个数据部分进行计算评分,评分的计算方式如下:
其中:α1<α2,初始α1=1,α2=2。
进一步地,s4步骤中,人格子维度的评分计算公式如下:
其中:
i表示表2从上到下的第i个人格维度;
j表示第j个人格维度的第j个人格子维度;
k表示第k个人格维度的第k个数据部分;
n表示第i个人格维度的第j个人格子维度包含数据种类数;
p_son_scorei,j表示第i个人格子维度的第j个人格子维度的分数;
p_son_data_ratioi,j,k表示第i个人格子维度的第j个人格子维度的指标的第k个数据部分的比率;
p_son_data_scorei,j,k表示第i个人格子维度的第j个人格子维度的指标的第k个数据部分的分数,其计算方式参见公式(5)。
进一步地,s4步骤中,根据s31中支持数据部分的置信值,计算平均置信值或加权置信值之和作为人格子维度的置信值brief_p_son,计算方式如下:
或
其中:
m表示每个人格子维度的数据种类数;
brief_datak表示第k个数据部分的置信值,其计算方式见公式(4);
p_son_data_ratiok表示权重,即数据部分在当前人格维度所占比例。
进一步地,s5步骤中,五个人格维度的评分计算公式如下:
其中:
i表示表2从上到下的第i个人格维度;
j表示第i个人格维度的第j个人格子维度;
m表示第i个人格维度包含子维度的个数;
p_scorei代表第i个人格维度的分数;
p_son_ratioi,j表示第i个人格子维度的第j个人格子维度的指标;
p_son_scorei,j表示第i个人格子维度的第j个人格子维度的分数,其计算方式参见公式(7)。
进一步地,s5步骤中,根据人格子维度的置信值brief_p_son,计算平均置信值或加权置信值之和,作为人格维度的置信值brief_p,计算方式如下:
或
其中:
n表示每个人格维度的人格子维度个数;
brief_p_sonj表示第j个人格子维度的置信值;
p_son_ratioj表示权重,即数据部分在当前人格维度所占的比例。
进一步地,s6步骤包括:
s61、进行大五人格问卷分数的采集,分数为百分制;
s62、将大五人格问卷百分制的分数(score_hundred)转换成5分制分数(score_five),使其与通过行为大数据得到的分数采用的分数制相同,转换方式如下:
进一步地,s7步骤包括:
s71、选择置信值比较大的用户的人格计算结果,通过直方图检验每个人格维度的分布情况,从而选择合适的相关系数,并使用pearson相关系数分析两种人格评分结果的相关性,计算方式如下:
s72、计算的相关系数大于0.6属于强相关,可以不进行参数调整,依据行为数据得到的分数作为人格分数;若相关系数低于0.6需进行参数α1、α2调整,以增大相关性,直到强相关,所有数据部分调整完毕后,选择其中相关度最强的作为最终模型;
s73、将两种评分结果进行权重求和,计算方式如下:
p_score=brief_p*p_score+(1-brief_p)*p_quest_score(12)
其中:
p_quest_score是问卷的相同人格维度的分数。
采用上述技术方案后,本发明与背景技术相比,具有如下优点:
本发明根据高校积累的行为大数据,结合大五人格理论,通过统计学工具对学生的人格进行计算,从而能够及时地、客观地反映学生的人格和人格的变化情况,提高了高校人格测量的客观性和准确性。
附图说明
图1为本发明的流程框图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
实施例
参考图1所示,本发明公开了一种基于行为大数据的统计学人格计算方法,包括以下步骤:
s1、根据“五因素人格模型”理论,并结合高校积累的行为大数据,确定能够支持计算五个人格维度的人格子维度、各人格子维度分数的比例、支持人格子维度计算的数据部分及各个数据部分的分数的比例。
“五因素人格模型”理论,也叫做大五人格理论,该理论从五个维度来描述个体的人格:神经质(neuroticism)、外向性(extraversion)、开放性(openness)、宜人性(agreeableness)与尽责性(conscientiousness),“五因素人格模型”见表1。
表1“五因素人格模型”结构
行为大数据,即高校中积累的网络外显行为数据和社会活动外显行为数据,包括校园一卡通中的消费数据、教务系统的成绩数据、上课出勤数据、参加社团和社团活动数据、借阅书籍数据、监控系统的人脸识别数据、人脸表情识别数据、网络日志数据、浏览网页的语言情感特征数据、大五人格问卷的结果数据等,其中人脸表情识别数据和浏览网页的语言情感特征数据需要依据监控系统的人脸识别数据和网络日志数据来获取。
五个人格维度的人格子维度、各人格子维度分数的比例、支持人格子维度计算的数据部分及各个数据部分的分数的比例见表2,表2中,数据部分按照与人格子维度的相关性进行匹配;各个比例按与其上一级的相关程度及数据量的大小设置;表格中无特别说明就是正相关。
表2“五因素人格模型”比例划分
s2、对高校大数据进行预处理、抽取、转换操作,得到s1中确定的数据部分,s2步骤具体为:
s21、根据s1中确定的数据部分,通过高校大数据中的网络日志数据包含的url,使用爬取技术爬取用户浏览的网页文本内容,并将一天的文本汇集成一个大的文本,使用jieba分词工具并根据sc-liwc心理学词典,统计sc-liwc中的语言情感特征出现的次数及占总次数的比例,作为浏览网页文本内容的特征向量;
s22、根据s1中确定的数据部分,通过高校大数据中监控系统的人脸识别数据,获取识别到的人脸图像,再通过人脸表情识别程序分析并得到人脸图像中的表情数据,其中表情被分为7种:愤怒(anger)、厌恶(disgust)、高兴(happy)、恐惧(fear)、伤心(sad)、中立(neutral)、吃惊(surprise);
s23、去除s21和s22中包含的非学生用户数据、空数据及错误数据;
s24、对经过s23预处理后的数据,根据s1数据部分的要求,对象上按用户、时间上按学期(成绩、参加社团和志愿者活动数等)和周(淋浴、餐饮、表情数据、考勤等)进行汇总,并对按周汇总的数据进行量化处理,以方便后期分数的计算。
进一步地,s24步骤中,按周汇总数据的计算方式为:
汇总:
对按周汇总数据中规律性的行为(主要是淋浴、餐饮等)通过标准差的方式进行量化处理,量化的计算方式如下:
标准差:
再通过求比例对汇总数据进行归一化处理,最终得到归一化后的数据(data_norm),计算方式如下:
归一化:
其中:
i为从上到下的第i个人格维度;
xi为第i个人格维度一周的汇总数据;
x为第i个人格维度一周的汇总数据result_data或量化后的数据s;
x*为第i个人格维度一周数据归一化后的数据(data_norm)。
s3、计算各个数据部分的分数,s3步骤包括:
s31、以5分制计算每个学生各数据部分的评分,并给出置信值brief_data,置信值的计算方式如下;
其中:
cur_data为当前学生的一个数据部分的量化值;
max_data该数据部分的最大量化值;
由于每个用户的数据量不一,数据量少和数据量多以s24中的统计方式可能得到相同的结果,因此必须根据数据量建立置信值(brief_data),每个数据部分最多数据量的置信值为1。
s32、根据s2处理后的每个数据部分,计算每个数据部分的全校平均值data_norm_avg;
s33、将每个数据部分的全校平均值扩大倍数α,并根据平均值和扩大倍数α得到评分的标准分数线(α需要根据计算结果的准确性进行调整);
s34、根据标准分数线,结合s2中处理后的数据部分,对每个学生的每个数据部分进行计算评分,评分的计算方式如下:
其中:α1<α2,初始α1=1,α2=2。
由于高校是一个相对封闭的区域,并且高校之间也会因为地理位置的差异数据之间也存在着比较大的差异,同时每个高校也有自己的独特情况,确定一个适应全部高校评分的标准是比较困难的。为了能够支持每个高校的独特情况,一个高校每个数据部分的平均值就比较有意义了,即可以把每个平均值扩大适合的倍数,作为评分的标准。
s4、根据s1中确定的人格子维度与数据部分的对应关系以及s3中数据部分的分数数据,计算各人格子维度的评分;
进一步地,s4步骤中,人格子维度的评分计算公式如下:
其中:
i表示表2从上到下的第i个人格维度;
j表示第j个人格维度的第j个人格子维度;
k表示第k个人格维度的第k个数据部分;
n表示第i个人格维度的第j个人格子维度包含数据种类数;
p_son_scorei,j表示第i个人格子维度的第j个人格子维度的分数;
p_son_data_ratioi,j,k表示第i个人格子维度的第j个人格子维度的指标的第k个数据部分的比率;
p_son_data_scorei,j,k表示第i个人格子维度的第j个人格子维度的指标的第k个数据部分的分数,其计算方式参见公式(5)。
进一步地,s4步骤中,根据s31中支持数据部分的置信值,计算平均置信值或加权置信值之和作为人格子维度的置信值brief_p_son,计算方式如下:
或
其中:
m表示每个人格子维度的数据种类数;
brief_datak表示第k个数据部分的置信值,其计算方式见公式(4);
p_son_data_ratiok表示权重,即数据部分在当前人格维度所占比例。
进一步地,s5步骤中,五个人格维度的评分计算公式如下:
其中:
i表示表2从上到下的第i个人格维度;
j表示第i个人格维度的第j个人格子维度;
m表示第i个人格维度包含子维度的个数;
p_scorei代表第i个人格维度的分数;
p_son_ratioi,j表示第i个人格子维度的第j个人格子维度的指标;
p_son_scorei,j表示第i个人格子维度的第j个人格子维度的分数,其计算方式参见公式(7)。
s5、根据s1中确定的五个人格维度与人格子维度的对应关系以及s4中各人格子维度的分数,计算五个人格维度的评分;
进一步地,s5步骤中,根据人格子维度的置信值brief_p_son,计算平均置信值或加权置信值之和,作为人格维度的置信值brief_p,计算方式如下:
或
其中:
n表示每个人格维度的人格子维度个数;
brief_p_sonj表示第j个人格子维度的置信值;
p_son_ratioj表示权重,即数据部分在当前人格维度所占的比例。
s6、采集大五人格问卷的评分,s6步骤包括:
s61、进行大五人格问卷分数的采集,分数为百分制,采用与上述人格计算理论相同的大五人格问卷进行验证和辅助人格的测量,可以保证人格计算的准确性;
s62、将大五人格问卷百分制的分数(score_hundred)转换成5分制分数(score_five),使其与通过行为大数据得到的分数采用的分数制相同,以便综合分析获得的两种结果,转换方式如下:
s7、综合分析上述两种人格评分的结果,得出结论,s7步骤包括:
s71、选择置信值比较大的用户的人格计算结果,通过直方图检验每个人格维度的分布情况,从而选择合适的相关系数,并使用pearson相关系数分析两种人格评分结果的相关性,计算方式如下:
s72、计算的相关系数大于0.6属于强相关,可以不进行参数调整,依据行为数据得到的分数作为人格分数;若相关系数低于0.6需进行参数α1、α2调整,由于每个数据部分都存在自己的参数α1、α2,按数据部分的重要性(占比)顺序,依次调整它们的参数α1、α2,以增大相关性,直到强相关,所有数据部分调整完毕后,选择其中相关度最强的作为最终模型;
s73、将两种评分结果进行权重求和,计算方式如下:
p_score=brief_p*p_score+(1-brief_p)*p_quest_score(12)
其中:
p_quest_score是问卷的相同人格维度的分数。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!