一种面向联盟链的分片内数据组织管理方法与流程
本发明属于区块链技术领域,涉及到分片内数据的组织管理,具体是一种面向联盟链的分片内数据组织管理方法及分片增加方法。
背景技术:
区块链是一种由互不信任的多方维护的不可篡改的分布式账本,除了具有分布式的特点,同时也支持拜占庭容错。但区块链系统在计算和存储方面的可扩展性较弱,使其不能满足企业级的需求,大大限制了区块链的发展。
分片技术被认为是提高区块链可扩展性的解决方法。在基于帐户模型的区块链中,分片技术主要通过将账户数据划分成几个部分,每个部分称为一个分片,每个分片单独执行,从而提高系统吞吐量。分片划分之后,划分到每个分片中的状态数据目前主要通过默克尔树或其变体结合键值对数据库进行管理,比如mpt树结合基于lsm树的键值对数据库。但是,这些结构因为是在键值存储上实现的,会出现明显的读放大情况。
在增加分片时,会出现数据的重划分过程,在数据迁移同步的过程中,系统无法对外提供服务,会出现系统服务短暂停机的情况,降低了系统的可用性。
作为分片内账户状态数据组织的数据结构,首先要可以作为分片内账户状态的索引结构、生成分片内账户状态的摘要、支持账户状态数据的历史版本溯源,同时还应该满足:保证分片之间的负载均衡、分片划分时快速的数据迁移、数据迁移过程中提供不停机的服务。在现有技术中,账户状态数据组织结构一般被组织为默克尔树或其变体的形式,比如mpt、mbt、默克尔b+树等。但现有的这些技术都不能满足以上这些需求。
默克尔桶树(mbt)。mbt由两部分组成:哈希表和默克尔树。哈希表由一系列桶组成,每个桶包含许多账户状态(每个桶内账户是有序的)。桶的哈希值是上层默克尔树的叶子节点,默克尔树的哈希根是所有状态的摘要。由于mbt是一棵大小固定的树,因此它的高度是一定的,并且从根节点到桶的路径上的节点,可以作为账户状态的完整性证明。但是,mbt无法为单独的账户状态提供完整性证明(因为一个桶里面有一批账户状态数据)。
默克尔帕特里夏树(mpt)是由帕特里夏树(patriciatrie)和默克尔树的混合物。该结构除了可以计算摘要外,还可以作为账户状态的索引,并提供完整性证明。此外,mpt通过在每个块上构建全局账户状态的快照来存储账户状态数据的所有版本。但是,mpt不是一棵平衡的树,它的高度可能会随着帐户数量的增长而快速增加,这会导致整体性能下降。同时mpt的结构是在键值存储区上实现的,具有明显的读放大的情况。
默克尔b+树,作为一种具有出色的i/o性能的平衡结构,可以处理提供完整性证明的可验证查询。但是,默克尔b+树不支持数据的多版本溯源。因此,上述结构都存在一些缺陷。
技术实现要素:
针对上面这些结构的存在的这些缺陷,本发明在分片中设计一种用于数据管理的聚集默克尔b+树(amb-tree),如图12所示,聚集默克尔b+树具有出色的读写性能,并可以生成全局账户状态数据的摘要以及提供查询的完整性证明;每个分片内包含多个互相之间账户地址不连续的子分片,增加分片时,每个分片切分其聚集默克尔b+树,仅需切分其中一个子分片,减少了分片增加时数据的迁移量,同时这种方法保证在进行分片划分时分片之间的负载均衡;聚集默克尔b+树支持快速重建,并且每个分片可以在数据同步(迁移)期间服务不停机。
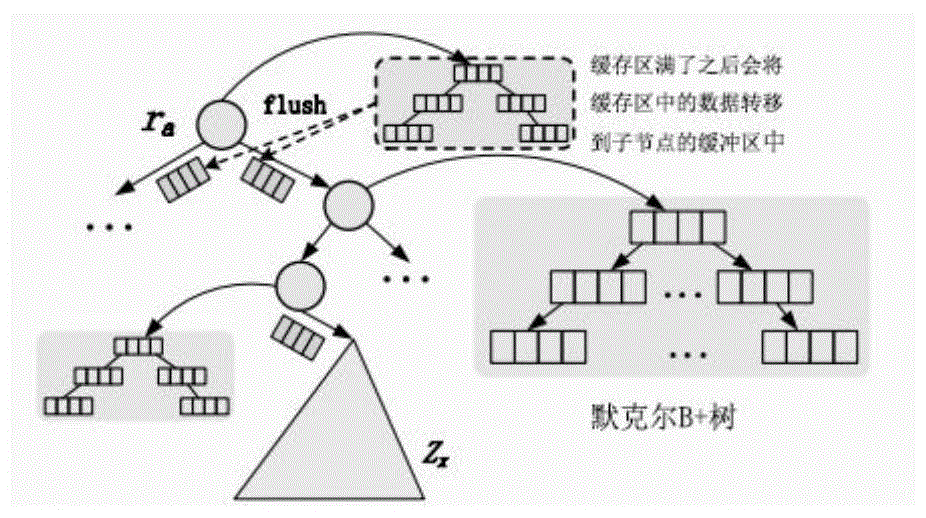
本发明对聚集默克尔b+树又做了一些改进(amb*-tree),本发明将amb-tree的聚集层默克尔树中每个节点设置一个固定大小的缓存区,对数据的更新操作可以先写入缓存区,每个缓存区通过默克尔b+树进行管理。具体细节为:当有对状态数据的更新操作时,将更新操作写入根节点的缓冲区中,当根节点的缓冲区满了之后,将缓冲区的数据切分,切分之后写入子节点的缓冲区中,以此类推,缓冲数据会到达相应的叶子节点,最终将叶子节点内的数据写入索引层中。每个节点的缓冲区通过默克尔b+树进行组织管理,所有的默克尔b+树在主存中维护,当需要查找数据时,首先到缓存区中查找数据;需要对分片进行重新划分时,缓存区中若存在一些对分片中的账户的更新操作,首先需要将这些数据执行写回操作,写回之后执行分片划分操作。通过这种优化手段,大大提高了写的效率,同时根据数据访问的局部性,这种优化手段也提高了读的效率。如图1所示。
基于以上,本发明提出了一种面向联盟链的分片内数据组织管理方法:在分片内数据组织管理中,将分片内数据分三层管理,聚集层生成分片内所有账户状态数据的摘要,索引层负责对分片内账户状态数据的索引,数据层管理账户状态的历史数据。聚集默克尔b+树支持生成完整性证明,支持数据的多版本溯源,同时可以降低现有技术中存在的读放大情况;每生成一个区块,就对新生成的聚集默克尔b+树生成快照。当对聚集默克尔b+树进行更新时,依据之前生成的快照对外提供服务。具体包括以下步骤:
步骤1:利用聚集默克尔b+树组织管理分片内账户地址状态;所述默克尔b+树包括索引层、聚集层、数据层;具体包括以下子步骤:
步骤1-1:每个分片负责全部地址空间的一部分地址空间,为了保证分片之间的负载均衡和增加分片时尽可能少的数据迁移,每个分片又分为多个子分片,子分片内部的地址空间是连续的,子分片之间的地址空间是不连续的,每个子分片中的账户状态用默克尔b+树组织管理,该树作为该子分片内账户状态的索引,此部分作为聚集默克尔b+树的索引层;
步骤1-2:将分片内所有子分片的默克尔b+树的根节点作为叶子节点,通过默克尔树生成分片内所有账户状态的摘要,此部分作为聚集默克尔b+树的聚集层;
步骤1-3:利用可验证只可添加跳表管理单个账户状态的全部历史数据,导致账户状态改变的交易所在区块的区块号作为账户状态的一个版本;为每个账户状态历史版本维护多层链接,链接通过哈希指针指向之前的版本,第0层链接全部版本数据,第0层链表中每隔2n个的版本依次链接成为第n层的链表,此部分作为聚集默克尔b+树的数据层。
步骤2:针对所述聚集默克尔b+树,完成带完整性证明的状态查询操作和数据多版本溯源;具体包括以下子步骤:
步骤2-1:在所述索引层,将从默克尔b+树顶端出发到满足查找条件的叶子节点的路径上每个节点保存的哈希指针作为所述索引层的完整性证明;所述具体查找办法为从包含查找键的子分片的根节点出发,查找包含查找键的子节点,依次逐层查询,直到叶子节点,查找路径上的所有的节点对应的哈希值即为索引层的完整性证明;
步骤2-2:在所述聚集层,将从聚集层根节点出发到指向满足查找条件的子分片的叶子节点的路径上的所有节点的兄弟节点作为所述聚集层的完整性证明;所述查找办法为:从查找键所在的子分片的根节点(该根节点在聚集层作为叶子节点)出发,查找其对应的兄弟节点,之后再查找其父节点的兄弟节点,以此类推,直到根节点,查找到的所有从叶子节点到根节点这条路径上的所有兄弟节点即为聚集层的完整性证明;
步骤2-3:在所述数据层,查找指定的账户状态版本时,给定一个账户和区块号,则应返回小于该区块号的最大的状态版本对应的数据;所述查找方法是:针对指定的账户,从当前状态版本出发,查找所有版本号大于等于所给区块号的版本,若其中最小的版本等于所给区块号,则此最小的版本即为所求版本;若最小的版本大于所给区块号,则依照上述步骤递归查询,其中递归查找结束的条件是:区块号位于两个相邻的版本号之间;递归过程中访问到的所有状态版本为数据层的完整性证明。
步骤3:针对聚集默克尔b+树的更新操作;具体包括以下子步骤:
步骤3-1:每产生一个区块,会对新的聚集默克尔b+树生成快照,在执行下一个区块里面的交易时,状态数据未更新完成,依据在上一个区块中生成的快照对外提供服务。将聚集默克尔b+树中所有需要更新的脏节点复制并将索引层和聚集层进行更新;
步骤3-2:在新的区块到来之后,执行区块里面的交易时,会涉及对状态数据的更新,从而会涉及聚集默克尔b+树的更新,将聚集默克尔b+树中需要更新的节点进行复制并对其进行更新,当分片内的节点对该区块达成共识之后,将更新的节点写回到聚集默克尔b+树中。
基于以上,本发明提出了一种分片增加时服务不停机的分片增加办法,其中涉及串行增加和并行增加两个部分。在串行化分片增加方案中,首先获取现有分片的一些信息,随机生成多个哈希键,对包含这些哈希键的分片进行划分,将新划分出来的数据同步到新分片中,新分片对这些数据进行组织整理,构建相应的数据结构;新分片未完成数据同步时,而新分片内的节点对某一交易达成了共识,在执行这一交易时,需要访问或更新还未同步的数据时,新分片内的节点向原数据所在分片请求相关数据来执行交易,并将请求回来的数据构建本地的数据管理的数据结构;并行增加过程中,会出现新生成的分片a尚未完成数据同步时,另一个新分片b就要对a分片进行切分操作的情况,针对这种情况,a分片首先向原数据所在分片请求相关数据来执行分片切分操作,并将切分的情况发送给b分片,a分片和b分片依据切分的情况,通过向原数据所在分片请求数据响应数据查询和数据更新请求。具体技术方案包括以下步骤:
步骤1:串行化增加分片:
步骤1-1:获取所有现有的分片信息(每个分片负责的部分账户空间等);
步骤1-2:随机生成多个哈希键(数目与子区域的数目相同),查找包含该哈希键的分片,利用该哈希键对包含此哈希键的分片子区域进行切分;
步骤1-3:数据划分之后不立即将数据同步到新分片中,而是当分片内的节点空闲时,开始同步数据;
步骤1-4:数据同步完成之后,利用默克尔b+树管理每个子区域的数据,利用默克尔树生成分片数据的摘要(将所有子区域数据通过默克尔树聚集生成摘要),新分片根据自身的数据对外提供服务。
其中,分片子区域内默克尔b+树切分方法:
步骤1-2-1:给定一棵默克尔b+树,和特定的哈希键。从根节点到叶子节点向下遍历,将当前所处节点包含哈希键的子节点进行切分,生成两棵子树。
步骤1-2-2:将两棵子树进行调整,去除无效节点,将其调整为满足要求的子树;
步骤1-2-3:调整之后,根据相应的映射规则,将切分之后的两棵子树分别替换原有分片的数据或同步到新分片中。
步骤2:并行化增加分片:
步骤2-1:并行化增加分片时会出现一个新产生的分片s1还未来得及从其他分片同步回数据时,另一个新的分片s2就需要对分片s1进行切分的情况。针对这种情况,处理步骤如下:当最新产生的分片s2需要对之前新产生的但还未同步数据的分片s1进行切分时,分片s1会首先向现在数据所处的分片请求必要的数据并将依据分片s2的分片请求对数据进行切分,切分之后将相关信息通知给分片s2,分片s1和分片s2各自从现在数据所在分片请求同步数据。
步骤3:分片增加(数据同步)过程中服务不停机的查询处理
步骤3-1:新分片未完成数据同步时,若新分片内的节点对某一交易达成了共识,在执行这一交易时,需要访问还未同步的数据时,新分片内的节点向原数据所在分片请求相关数据来执行交易,并将请求回来的数据构建本地的数据管理的数据结构;
步骤3-2:新分片未完成数据同步时,当需要执行数据更新请求时,新分片内的节点向原数据所在分片请求相关的数据,并在本地执行数据更新操作,当需要插入新数据时,可能需要调整本地的数据组织结构,同样从原分片同步一些必要的信息;
步骤3-3:若新分片未收到数据查询或数据更新请求,新分片内的节点开始同步数据。
本发明的有益效果包括:
在分片内中设计一种新颖的数据结构,即用于分片内数据管理的聚集默克尔b+树,该结构不仅支持完整性证明和多版本数据溯源,同时可以降低现有技术存在的读放大情况。每生成一个区块,就对新生成的聚集默克尔b+树生成快照,当对聚集默克尔b+树进行更新时,依据之前生成的快照对外提供服务,可以持续对外提供服务。本发明在分片增加过程中利用惰性同步方式保证系统服务不阻塞,克服了数据服务短时间不可用的问题。
附图说明
图1是amb*-tree示意图。
图2是get()函数对从0.1m(1m=1,000,000)到1.5m的账户数量的状态数据操作的延迟。
图3是put()函数对从0.1m到1.5m的账户数量的状态数据操作的延迟。
图4是在具有约0.1m账户历史状态版本的数据集上,对4种数据组织管理结构的hist()操作的延迟进行了比较。
图5是所有数据组织管理结构在不同账户数量情况下的系统吞吐量。
图6是所有数据组织管理结构在读写比分别为1:1和1:3情况下的总延迟。
图7是在不同的数据同步量情况下,不同数据组织管理结构的同步时间。
图8是3种数据组织管理结构在执行的区块数从1到8000不等的情况下,基于opr()函数实现的切分的延迟。
图9是不同数据组织管理结构增加一个分片的时间开销比较。
图10是在数据量约为2gb时,所有数据组织管理结构添加单个分片时的系统吞吐量。
图11是在数据量约为2gb时,所有数据组织管理结构添加两个分片时的系统吞吐量。
图12是本发明涉及的面向联盟链分片内数据组织管理方法架构示意图;
图13是生成聚集层对应的完整性证明过程。
图14是生成索引层对应的完整性证明过程。
图15是数据层通过跳表链接账户的历史状态数据。
图16是对聚集默克尔b+树生成快照和对聚集默克尔b+树进行更新操作。
图17是分片串行增加办法的伪代码说明。
图18-1至图18-4是利用一个哈希键对分片内子区域默克尔b+树进行切分操作。
图19是分片增加数据未完成同步时数据执行请求过程。
图20是并行增加分片时远程状态数据请求过程。
具体实施方式
结合以下具体实施例和附图,对本方法进行详细的介绍。实施本方法的整体过程、条件、实验方法等,除以下专门提及的内容之外,均为本领域的公知常识,本发明没有对内容进行特别的限制。
本发明是以设计一种可扩展的分片内账户状态数据存储管理方法为目标,针对现有技术的缺失,提出一种面向联盟链的分片内数据组织管理方法。在分片内数据组织管理中,通过提出的聚集默克尔b+树进行管理,在聚集默克尔b+树中,将分片内数据分三层管理:聚集层,索引层和数据层。聚集层生成分片内所有账户状态数据的摘要,索引层负责对分片内账户状态数据的索引,数据层管理账户状态的历史数据。聚集默克尔b+树支持生成完整性证明,支持数据的多版本溯源,同时可以降低现有技术中存在的读放大情况;每生成一个区块,就对新生成的聚集默克尔b+树生成快照。当对聚集默克尔b+树进行更新时,依据之前生成的快照对外提供服务。
本发明提出了一种面向联盟链的分片内数据组织管理方法,该方法具体包括以下步骤:
步骤1:利用聚集默克尔b+树组织管理分片内账户地址状态:
步骤1-1:每个分片负责管理多个不同的子分片,每个子分片中的账户状态用默克尔b+树组织管理,该树作为该子分片内账户状态的索引,此部分作为聚集默克尔b+树的索引层;
步骤1-2:将每个子分片的默克尔b+树的根节点作为叶子节点,通过默克尔树生成分片内所有账户状态的摘要,此部分作为聚集默克尔b+树的聚集层;
步骤1-3:利用可验证只可添加跳表管理单个账户状态的全部历史数据。导致账户状态改变的交易所在区块的区块号作为账户状态的一个版本。为每个账户状态历史版本维护多层链接,链接通过哈希指针指向之前的版本,第0层链接全部版本数据,第0层链表中每隔2n个的版本依次链接成为第n层的链表,此部分作为聚集默克尔b+树的数据层;
步骤2:针对聚集默克尔b+树,完成带完整性证明的状态查询操作:
步骤2-1:在索引层,将从默克尔b+树顶端出发到满足查找条件的叶子节点的路径上每个节点保存的哈希指针作为索引层的完整性证明;所述具体查找办法为从包含查找键的子分片的根节点出发,查找包含查找键的子节点,依次逐层查询,直到叶子节点,查找路径上的所有的节点对应的哈希值即为索引层的完整性证明
步骤2-2:在聚集层,将从聚集层根节点出发到指向满足查找条件的子分片的叶子节点的路径上的所有节点的兄弟节点作为聚集层的完整性证明;所述查找办法为:从查找键所在的子分片的根节点出发,查找其对应的兄弟节点,所述根节点为索引层的根节点,索引层的根节点作为聚集层的叶子节点,之后再查找其父节点的兄弟节点,以此类推,直到根节点,查找到的所有从叶子节点到根节点这条路径上的所有兄弟节点即为聚集层的完整性证明。
步骤2-3:在数据层,查找指定的账户状态版本时,给定一个账户和区块号,则应返回小于该区块号的最大的状态版本对应的数据。查找方法是:针对指定的账户,从当前状态版本出发,查找所有版本号大于等于所给区块号的版本,若其中最小的版本等于所给区块号,则此最小的版本即为所求版本;若最小的版本大于所给区块号,则依照上述步骤递归查询,其中递归查找结束的条件是:区块号位于两个相邻的版本号之间。递归过程中访问到的所有状态版本为数据层的完整性证明。
步骤3:针对聚集默克尔b+树的更新操作:
步骤3-1:每生成一个区块,就对新生成的聚集默克尔b+树生成快照。当对聚集默克尔b+树进行更新时,依据之前生成的快照对外提供服务。
所述步骤3-1中,每产生一个区块,会对新的聚集默克尔b+树生成快照,在执行下一个区块里面的交易时,状态数据未更新完成,依据在上一个区块中生成的快照对外提供服务;将聚集默克尔b+树中所有需要更新的脏节点复制并将索引层和聚集层中进行更新。
步骤3-2:当对聚集默克尔b+树数据进行更新时,不立即执行写回操作,而是当分片里面验证者对新生成的聚集默克尔b+树达成共识时,执行写回操作。
所述步骤3-2中,在新的区块到来之后,执行区块里面的交易时,会涉及对状态数据的更新,从而会涉及聚集默克尔b+树的更新,将聚集默克尔b+树中需要更新的节点进行复制并对其进行更新,当分片内的节点对该区块达成共识之后,将更新的节点写回到聚集默克尔b+树中。
本发明是以设计一种服务不停机的分片增加方法为目标,针对现有技术的缺失,提出一种分片增加时服务不停机的分片增加办法,其中涉及串行增加和并行增加两个步骤。在串行化分片增加时,首先获取现有分片的一些信息,随机生成多个哈希键,对包含这些哈希键的分片进行划分,将新划分出来的数据同步到新分片中,新分片对这些数据进行组织整理,构建相应的数据结构;新分片未完成数据同步时,但新分片内的节点对某一交易达成了共识,在执行这一交易时,若需要访问或更新还未同步的数据,新分片内的节点向原数据所在分片请求相关数据来执行交易,并将请求回来的数据构建本地的数据管理的数据结构;并行增加分片过程中,会出现新生成的分片a尚未完成数据同步时,另一个新分片b就要对a分片进行切分操作的情况,针对这种情况,a分片首先向原数据所在分片请求相关数据来执行分片切分操作,并将切分的情况发送给b分片,a分片和b分片依据切分的情况,通过向原数据所在分片请求数据响应数据查询和数据更新请求。
本发明中,服务不停机的分片增加方法包括以下具体步骤:
步骤1:串行化增加分片;
步骤2:并行化增加分片;
步骤3:分片增加(数据同步)过程中服务不停机的查询处理;
所述步骤1具体包括:
步骤1-1:获取所有现有的分片信息(每个分片负责的账户地址空间等);
步骤1-2:随机生成多个(数目与子区域的数目相同)哈希键,查找包含该哈希键的分片,利用该哈希键对包含此哈希键的分片的子区域进行切分;
步骤1-3:数据划分之后不立即将数据同步到新分片中,而是当分片内的节点空闲时,开始同步数据;
步骤1-4:数据同步完成之后,利用默克尔b+树管理每个子区域的数据,利用默克尔树生成分片数据的摘要(将所有子区域数据通过默克尔树聚集生成摘要),新分片根据自身的数据对外提供服务。
所述步骤1-2包括:
步骤1-2-1:给定一棵子区域的默克尔b+树和生成的响应的哈希键。从根节点到叶子节点向下遍历,将当前所处节点包含哈希键的子节点进行切分,生成两棵子树;
步骤1-2-2:将两棵子树进行调整,去除无效节点,将其调整为满足要求的子树;
步骤1-2-3:调整之后,根据映射规则,具有较大的哈希的子树替代原树,较小的哈希子树划分到新生成的分片里面。
所述步骤1-4包括:
步骤1-4-1:获取每个子区域的默克尔b+树的根节点作为数据项;
步骤1-4-2:利用哈希函数将每个数据项生成哈希值;
步骤1-4-3:在生成的所有哈希值中,每两个哈希值拼接得到一个长字符串,再次利用哈希函数将长字符串生成哈希值,以此类推,直到最终得到一个哈希值,该哈希值作为所有数据项的摘要。
步骤2中,相比于串行化增加分片,并行化增加分片时会出现一个新产生的分片s1还未来得及从其他分片同步回数据时,另一个新的分片s2就需要对分片s1进行切分的情况。针对这种情况,处理步骤如下:当最新产生的分片s2需要对之前新产生的但还未同步数据的分片s1进行切分时,分片s1会首先依据分片s2的分片请求向现在数据所处的分片请求必要的数据并对数据进行切分,切分之后将相关信息通知给分片s2,分片s1和分片s2各自从现在数据所在分片请求同步数据。
步骤3具体包括:
步骤3-1:新分片未完成数据同步时,但新分片内的节点对某一交易达成了共识,在执行这一交易时,需要访问还未同步的数据时,新分片内的节点向原数据所在分片请求相关数据来执行交易,并将请求回来的数据构建本地的数据管理的数据结构;
步骤3-2:新分片未完成数据同步时,当需要执行数据更新请求时,新分片内的节点向原数据所在分片请求相关的数据,并在本地执行数据更新操作,当需要插入新数据时,可能需要调整本地的数据组织结构,同样从原分片同步一些必要的信息;
步骤3-3:若新分片未收到数据查询或数据更新请求,新分片内的节点开始同步数据。
实施例1
本实施例是在联盟链系统实施的一种分片内数据组织管理方法。
图12是分片内账户组织管理的数据结构聚集默克尔b+树,其中默克尔b+树用于管理子分片内的状态,然后聚集多个的子分片(每个子分片的账户状态数据组织成默克尔b+树),通过默克尔树计算分片中的所有状态摘要。同时,由可验证只可添加跳表支持多版本状态数据溯源和生成完整性证明。聚集默克尔b+树由三层组成:由默克尔树构成的聚集层,由默克尔b+树构成的索引层和由可验证跳表构成的数据层。
图13是生成聚集层对应的完整性证明过程,从聚集层根节点出发,到指向满足查找条件的子分片的叶子节点,路径上的所有节点的兄弟节点作为聚集层的完整性证明,节点3和节点4是数据2的完整性证明。
图14是生成索引层对应的完整性证明过程,从默克尔b+树顶端出发,到满足查找条件的叶子节点,路径上每个节点保存的哈希指针作为索引层的完整性证明,如图14所示,节点1、节点2、节点3对应的哈希值就是所需账户状态数据的完整性证明。
图15是通过跳表管理账户历史状态数据,如图所示,当前状态数据版本号为8,当查找版本号为5的状态数据时,版本8链接的大于5的版本有版本6和版本7,选择版本号最小的版本6,版本6直接链接版本5,版本5即为所求。同时版本8,版本6作为版本5的完整性证明。
图16是对聚集默克尔b+树生成快照和对聚集默克尔b+树进行更新操作。在运行期间,系统必须基于最新提交的聚集默克尔b+树为其他人提供服务。为了避免阻塞交易的执行或客户的查询,本发明在每个块都生成了聚集默克尔b+树的快照。当更新聚集默克尔b+树时,将基于之前的聚集默克尔b+树来响应请求。在对聚集默克尔b+树上生成快照时,不是就地改写,而是将聚集默克尔b+树中所有需要更新的脏节点复制并在索引层和聚集层中进行更新,如图16所示。由于可验证跳表的只可添加属性,很容易将状态的新版本附加到聚集默克尔b+树中,而无需在数据级别修改快照。新版本状态包含一些指向其先前版本的正向链接。之后,重新计算聚集默克尔b+树的新摘要ra,以检查分片中节点之间的状态一致性。当分片中节点就新摘要ra达成一致时,开始基于新的聚集默克尔b+树进行服务。此外,当分片中节点没有对新区块达成共识时,使用快照进行回滚。
实施例2
本实施例是在联盟链系统实施的一种服务不停机分片增加方法。
图17是串行增加分片过程伪代码:首先新的分片通过sync()函数获取现有所有分片的信息(第2行到第4行):循环操作:将每个分片ci的数据同步到新分片cnew;之后新的分片基于现有分片的信息选择多个子区域(个数为分片内子分片的数量),每次选择的过程中,新分片首先利用splitkey()函数随机生成一个哈希键hks(第6行),并且在分片csi(包含哈希键hks的分片)中寻找包含该哈希键hks的子区域(子分片)zi(第7行)。之后新分片通过opr()函数用hks在区域zi上部署一个切分操作,生成两个子区域,opr()函数会返回将要划分到新分片中的子区域i’的数据的摘要(第8行)(原分片里的节点会对该摘要进行bls签名,保证原分片里的多数节点认可此摘要)。之后,新分片开始从原有分片同步回数据(第10行)。之后,新分片将同步回来的c个子区域的数据聚集(第11行),最后,新分片开始处理交易提供服务(第12行)。
图18-1至图18-4是利用一个哈希键对默克尔b+树进行切分操作:首先给定一棵默克尔b+树和一个特定的哈希键。从根节点到叶子节点向下遍历,将当前所处节点的包含给定哈希键的子节点进行切分,生成两棵子树,如图18-2所示。将两棵子树进行调整,去除无效节点,将其调整为满足要求的子树,如图18-3和18-4所示。具体如下:给定默克尔b+树被拆分为两个局部子树,如图18-2所示,节点<70>是根节点<30,90>的拆分子节点。然后将两个局部子树分别调整为有效的默克尔b+树,分别如图18-3和18-4所示,为了调整左树,首先从根<30,90>移除没有右子树的键90,并且根节点成为有效节点<30>。之后从节点<70>移除键70,然后将其与其左侧同级<10>合并到节点<10,30>中。此后,左局部子树成为有效的默克尔b+树。将右局部子树进行类似地调整处理。最后,右边的局部子树替换原始的默克尔b+树,重新计算本分片的摘要,而左边的局部树被转移到分片。
图19是分片增加过程中交易执行需要访问未同步数据的情况,当新分片尚未完成数据同步时,但新分片内的节点对某一交易达成了共识,在执行这一交易时,需要访问还未同步的数据时,新分片内的节点向原数据所在分片请求相关数据来执行交易,并将请求回来的数据构建本地的数据管理的数据结构。新分片未完成数据同步时,当需要执行数据更新请求时,新分片内的节点向原数据所在分片请求相关的数据,并在本地执行数据更新操作,当需要插入新数据时,可能需要调整本地的数据组织结构,同样从原分片同步一些必要的信息。新分片未收到数据查询或数据更新请求,新分片内的节点开始同步数据。
当多个分片同时加入系统时情况较逐一增加分片会更加复杂。具体来说,一个分片可以在另一个新分片中进行划分,而另一个新分片尚未完成数据同步。例如,一个新的分片cn2选择属于另一个新分片cn1的区域zx,并将其分为两个子区域zxl和zxr。但是,cn2无法同步来自cn1的所选区域zxl的数据,因为cn1尚未同步来自另一个分片cn0的区域zx中的所有状态。在这种情况下本方案的解决过程为:
1)新产生的分片cn2通过函数opr()在分片cn1中子区域zx上的哈希键hks上进行拆分操作。
2)在收到来自cn2的拆分操作请求后,cn1将子区域zx拆分为zxl和zxr,然后将zxl的根发送回去。为了拆分zx,分片cn1可以向分片cn0请求一些必要的默克尔b+树的节点,包含从zx的默克尔b+树的根ra到包含拆分的哈希密钥hks的叶子的路径,如图18-1至图18-4所示。
3)最后,cn1根据区域zxr重建其聚集默克尔b+树,并停止同步zxl的数据。当分片cn2收到zxl的根时,它开始直接同步来自分片cn0和cn1的zxl的数据。
并行增加分片时远程状态数据请求过程如图20所示。
实施例3(实验验证)
本实施例基于开源pbft系统的分片式区块链系统的原型,与amb-tree和amb*-tree树,分片增加协议集成在一起,并验证发明设计的有效性。分片内的共识算法采用hyperledgerfabric0.6共识模块中的pbft实现,并基于聚集默克尔b+树进行分片内数据组织管理。每个分片作为一个集群运行pbft算法进行共识,用基于两阶段提交的方式处理跨分片交易。智能合约的代码采用go语言。在网络层,分片中每个验证节点都与所有验证节点保持tcp连接,以便所有验证节点可以直接相互通信。哈希函数采用keccak-256算法,哈希值的长度为256位。聚集默克尔b+树用大约3000行c++代码实现。
在设计中本发明为应用程序(智能合约)提供了三个核心api,包括:put(key,val,blkno),get(key,[blkno])和hist(key,s,t):
put()用于将账户地址为key的val数据写入带有标签块号blkno作为版本的系统中;
get()返回块blkno处账户地址为key的状态值,默认情况下,返回最新的块中key的值;
hist()返回地址为key的账户的元组列表(val,blkno)。
分片增加过程中涉及的三个函数:
ruquest(rs,cr,args):分片cs中的节点rs向分片cr请求某些数据,其中args是请求的参数,返回的数据由cr分片的2f+1个(f是pbft中假设的恶意节点的数量,不超过节点数量的1/3)节点同意(通过bls签名实现);
sync(cs,cr,args):一个分片cs通过功能sync()同步另一个分片cr的数据,同时通过共识保证cs中的大多数节点获得相同的数据,sync()函数通过request()函数实现;
opr(cs,cr,args):分片cs通过函数opr()在分片cr上部署具体操作。opr()函数会被分片cs内多数节点调用。同时,函数opr()若需要将分片cr的多数节点同意的某些值返回给分片cs,将保证cs中的大多数节点都将接收到返回的数据。
评估基本读写操作的效率:图2至图4展示了基于4种结构的三个存储接口的数据访问延迟:amb-tree,amb*-tree,mpt和mbt。
图2和图3展示了get()和put()函数从0.1m(1m=1,000,000)到1.5m的账户数量的状态数据操作的延迟。事实证明,amb-tree和amb*-tree的性能明显优于mpt和mbt。例如,在账户地址数量为0.8m的情况下,mbt的get()和put()的等待时间分别超过4和8μs,比amb树的等待时间慢一个数量级,原因是因为其使用了基于lsm树的键值存储,例如mbt中的rocksdb或mpt中的leveldb,而amb-tree和amb*-tree由于其面向磁盘的设计和平衡的结构(索引层设计为默克尔b+树)而无需二次读写,因此对get()和put()表现良好。此外,因为对于amb-tree的优化,amb*-tree的表现比amb-tree更好。
图4是在具有约0.1m个账户历史状态版本的数据集上,对4种数据组织管理结构的hist()操作的延迟进行了比较。为了使mbt支持多版本,状态的版本号附加到其账户地址上来区分多个版本;通过在所有相关快照上查找每个版本来追溯mpt中账户状态的多个版本。结果如图4所示,amb-tree和amb*-tree获得较低的hist()查询延迟,因为它们可以批量的加载连续的版本(因为数据层设计为只可添加跳表的形式)。相反,针对hist()的mpt和mbt的延迟与版本数成正比,当跟踪30个版本时,mpt和mbt的延迟分别为42μs和155μs。
图5展示了所有数据组织管理结构在不同账户数量情况下的系统吞吐量。对于mpt和mbt,随着账户数量的增加,交易的执行开销逐渐成为瓶颈,基于mbt的系统的吞吐量约为2100,不到基于amb-tree和amb*-tree的吞吐量的三分之一。
图6展示了所有数据组织管理结构在两个读写比分别为1:1和1:3情况下的总延迟。每笔交易都可能向系统写入新账户,因此账户的数量随交易的执行而增加。随着交易数量的增长,amb-tree和amb*-tree的延迟以很小的比例线性增加,mbt的性能最差,因为更新每个状态时,它都需要将加载桶中所有状态并重新插入。
分片增加协议性能分析:如图7至图11所示。
本发明将每个分片分为32个子分片,新分片使用函数sync()来同步每个子分片的数据(从其他分片新划分出来默克尔b+树),函数sync()涉及多轮request(),每轮请求一个子分片的默克尔b+树(序列化为2m网络包)。为对比清晰,在采用mpt和mbt方法对分片数据进行管理时,采用和聚集默克尔b+树相同的分片划分方法(一致性哈希算法)来划分账户地址空间,同样每个分片包含多个子分片,同样通过默克尔树(与聚集默克尔b+树中的聚集层相同)聚集多个子分片,不同点是每个子分片通过mpt或mbt进行管理。
图7展示了在不同的数据同步量情况下,不同数据组织管理结构的同步时间。amb-tree和amb*-tree的性能远超过mpt和mbt,这是因为聚集默克尔b+树索引层的默克尔b+树支持批量读取,而mpt和mbt基于键值存储,会有大量的随机读取操作,出现严重的读写放大的情况。
图8展示了3种数据组织管理结构在执行的区块数从1到8000不等的情况下,基于opr()函数实现的切分的延迟。因为mpt会在每个块都会生成全局状态的快照,所以切分mpt需要分割所有的快照,mpt的切分延迟也就随块数的增加而增加,8000个块时,mpt的延迟超过40毫秒;切分mbt的话需要将所有账户状态加载之后重新插入到两个新的mbt来实现切分操作,当账户数量为1.5m时,mbt的等待时间超过30s(时间过长,图中没有表示)。amb-tree和amb*-tree的延迟几乎不变,例如在27毫秒内进行拆分时需要0.4μs。
图9比较了不同数据组织管理结构增加一个分片的时间开销,mpt-线和mbt-线代表模分配方式划分账户地址空间下mpt和mbt的结果,因为模分配方式在分片增加或减少时需要对全局状态进行重新划分,会产生大量的数据迁移,增加分片的时间开销会很大。在amb-tree和amb*-tree中,因为每个分片又分为多个彼此之间账户地址不连续子分片,所以在分片增加时,对需要切分的分片,只会对其其中一个子分片进行切分,需要迁移的数据量不会很大,所以amb-tree和amb*-tree增加分片的延迟较小(约1.7s),同时受益于惰性同步,新分片加入之后可以即时提供服务,而无需等待数据完成同步。由于mpt和mbt新添加的分片首先需要同步账户状态数据,因此mpt和mbt比amb-tree花费更多的时间。随着数据集规模的扩大,mpt或mbt的延迟会迅速增长,因为几乎所有账户状态都重新映射到另一个分片,涉及大量数据的迁移。当数据大小为2gb时,mpt的新分片持续时间超过600s。
图10展示了在数据量约为2gb时,所有数据组织管理结构添加单个分片时的系统服务的吞吐量。对于每项测试,新分片在第3秒加入系统。在amb-tree和amb*-tree下,新分片很快就可以开始处理交易,而在mpt-和mbt-下,由于全局状态需要重新分配,整个系统的服务停止了500多秒。在mpt和mbt下,由于状态数据的同步,仅新分片的服务分别停止了150s和300s。随着时间的流逝,amb-tree和amb*-tree的吞吐量会相应增加,因为随着时间的增长,新分片同步回的数据越来越多,在本地就可以处理,而无需再远程请求数据。此外,由于在聚集层每个节点都缓存了最近更新的数据,索引层可减少写入开销并提高读取性能,因此amb*-tree的性能优于amb-tree。另外,mpt-的吞吐量比mpt的吞吐量高,这是因为在实验中模分配方式比一致性哈希空间划分更均匀,每个分片的负载更均衡。
图11显示了同时添加两个分片的结果,同时划分了两个区域。多个分片的添加与串行增加分片相比不会对吞吐量产生任何重大的副作用,此外,由于多了两个新分片,每个新分片需要同步的数据相对于增加一个分片会减少,因此同步时间缩短到大约6s。
本发明的保护内容不局限于以上实施例。在不背离发明构思的精神和范围下,本领域技术人员能够想到的变化和优点都被包括在本发明中,并且以所附的权利要求书为保护范围。
- 还没有人留言评论。精彩留言会获得点赞!