一种AI人工智能检测口气的数据模型的制作方法
本发明涉及检测口气技术领域,具体为一种ai人工智能检测口气的数据模型。
背景技术:
在现有技术中,当前智能手机,智能穿戴设备成为人们必备的通讯,娱乐,各种传感器检测的工具,极大地方便了我们的生活,拓延了我们的身体功能。当前mems传感器渐渐随着穿戴设备起来,可以使之前模拟电路或者功能单一的器件,具备更多功能。尤其是麦克风,当前集成了数字低功耗的唤醒机制,可以全天候开启,进行声纹识别以及时刻检测特定语句,进行执行相关指令,极大的提升了设备的智能性,以及应用场景。但人们经常用麦克风进行通话,是常用的语音输入入口,同时也是接触人体口气的最多时段。但是,目前检测人体口气的设备是独立的设备,因此,一般用户不会单独去买这样的设备。
技术实现要素:
本发明的目的在于提供一种ai人工智能检测口气的数据模型,具有数据准备模块、数据预处理模块、配置模型、训练模块和评估优化模块的方式,通过一次一次的迭代和对比来减少误差,提高模型的准确度的优点,解决了现有技术中的问题。
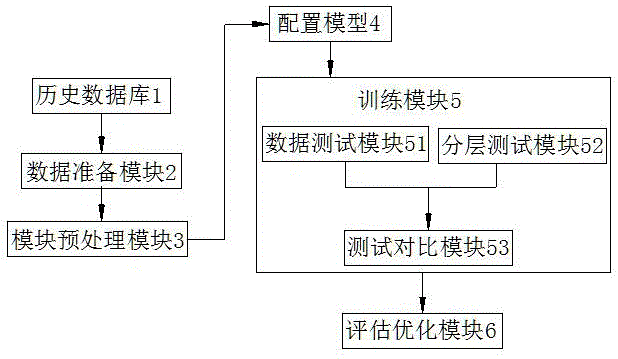
为实现上述目的,本发明提供如下技术方案:一种ai人工智能检测口气的数据模型,包括历史数据库,所述历史数据库的输出端连接数据准备模块,数据准备模块的输出端连接数据预处理模块,数据预处理模块的输出端连接配置模型,配置模型的输出端连接训练模块,训练模块的输出端连接评估优化模块;
所述的历史数据库在ai人工智能使用机器学习算法在大量的历史数据下进行训练,建立在过往数据所总结出的经验下建立的,所有的过往数据存储并记录在数据库中;
所述的数据准备模块从历史数据库中找到一定的规律并对未来做出的预测行,在历史数据库中抽取出来的特征;
所述的数据预处理模块预测一个口气的特征,就会从口气的数据中提取特征并查找对应的权重,根据这些特征的权重算出一个概率,收集了数据样本,做好了标签,并将数据均衡化和二值化处理;
所述的配置模型对口气数据的使用和处理,决定使用网络模型和结构来进行训练;
所述的训练模块训练结果和训练速度的两个关键指标,评价训练输出和测试输出的差距,并对两者产生的差距数值完成对比,输出对比值;
所述的评估优化模块训练结束后,使用口气数据划分里的测试集,通过一次一次的迭代和对比来减少误差,提高模型的准确度。
优选的,所述所述训练模块包括数据测试模块、分层测试模块和测试对比模块,数据测试模块的分层测试模块输出端连接测试对比模块。
优选的,所述分层测试模块将历史数据库引入到系统中,对数据进行清洗,拆分,将提取的样本放置到建立的不同模型中测试。
与现有技术相比,本发明的有益效果如下:
本ai人工智能检测口气的数据模型,在历史数据库中抽取出来的特征,有关的统计分析,根据分析结果确定利用分别预测影响口气指数指标的方法,然后再根据相关理论根据预测得到的各项口气体数据指标计算指数;对数据准备模块中提取的数据处理与分析,包括错误数据的删减、缺失数据的插值处理、插值处理数据的编码等相关数据计算;训练模块训练结果和训练速度的两个关键指标,评价训练输出和测试输出的差距,并对两者产生的差距数值完成对比,输出对比值,评估优化模块训练结束后,使用口气数据划分里的测试集,通过一次一次的迭代和对比来减少误差,提高模型的准确度。
附图说明
图1为本发明的整体模块图。
图中:1、历史数据库;2、数据准备模块;3、数据预处理模块;4、配置模型;5、训练模块;51、数据测试模块;52、分层测试模块;53、测试对比模块;6、评估优化模块。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1,一种ai人工智能检测口气的数据模型,包括历史数据库1,所述历史数据库1的输出端连接数据准备模块2,数据准备模块2的输出端连接数据预处理模块3,数据预处理模块3的输出端连接配置模型4,配置模型4的输出端连接训练模块5,训练模块5的输出端连接评估优化模块6。
历史数据库1在ai人工智能使用机器学习算法在大量的历史数据下进行训练,建立在过往数据所总结出的经验下建立的,所有的过往数据存储并记录在数据库中。
数据准备模块2从历史数据库1中找到一定的规律并对未来做出的预测行,在历史数据库1中抽取出来的特征,有关的统计分析,根据分析结果确定利用分别预测影响口气指数指标的方法,然后再根据相关理论根据预测得到的各项口气体数据指标计算指数。
数据预处理模块3预测一个口气的特征,就会从口气的数据中提取特征并查找对应的权重,根据这些特征的权重算出一个概率,收集了数据样本,做好了标签,并将数据均衡化和二值化处理,对数据准备模块2中提取的数据处理与分析,包括错误数据的删减、缺失数据的插值处理、插值处理数据的编码等相关数据计算。
配置模型4对口气数据的使用和处理,决定使用网络模型和结构来进行训练。
训练模块5训练结果和训练速度的两个关键指标,评价训练输出和测试输出的差距,并对两者产生的差距数值完成对比,输出对比值,训练模块5包括数据测试模块51、分层测试模块52和测试对比模块53,数据测试模块51的分层测试模块52输出端连接测试对比模块53,分层测试模块52将历史数据库1引入到系统中,对数据进行清洗,拆分,将提取的样本放置到建立的不同模型中测试。
评估优化模块6训练结束后,使用口气数据划分里的测试集,通过一次一次的迭代和对比来减少误差,提高模型的准确度。
选用400个病人的口气数据作为输入,将400个数据以20*20为数据片段进行随机打,然后按照3:7的比例划分训练数据与测试数据,将乱序之后的口气数据数据输入模型中,模型结果完成后,不断的调试模型数据完成模型建立。
综上所述:本ai人工智能检测口气的数据模型,在历史数据库1中抽取出来的特征,有关的统计分析,根据分析结果确定利用分别预测影响口气指数指标的方法,然后再根据相关理论根据预测得到的各项口气体数据指标计算指数;对数据准备模块2中提取的数据处理与分析,包括错误数据的删减、缺失数据的插值处理、插值处理数据的编码等相关数据计算;训练模块5训练结果和训练速度的两个关键指标,评价训练输出和测试输出的差距,并对两者产生的差距数值完成对比,输出对比值,评估优化模块6训练结束后,使用口气数据划分里的测试集,通过一次一次的迭代和对比来减少误差,提高模型的准确度。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!