一种基于改进YOLOv3模型的深度估计方法与流程
本发明涉及智能体自主导航和环境感知领域,特别涉及一种基于改进yolov3模型的深度估计方法。
背景技术:
智能体为实现安全可靠的自主导航需要具备完善的环境感知功能,环境感知中需要对智能体周围环境的各类目标进行准确识别和深度估计。基于机器视觉的环境感知最早使用人为设计的浅层目标特征,如sift特征、hog特征、局部二值特征等,由于现实环境复杂多变且光照强度不均匀等,此类特征的检测效果不够稳定。将此类特征点代表环境目标进行深度估计,在立体目标上缺乏表达性且估计误差很大。当前智能体环境感知任务中,通常将目标检测和深度估计作为两个独立的部分来处理,两部分之间处理的信息不能共享,很大程度上造成了计算资源的浪费。
随着人工智能的发展,智能体逐渐应用深度卷积神经网络来完成环境感知任务。相比于人为设计特征的感知方式,深度卷积神经网络对环境特征的感知更加丰富和多层次,且能够通过从大规模数据集中不断学习当前任务的特征表达,从而获得更优的感知效果。因此研究基于深度卷积神经网络的深度估计方法,以实现目标检测和深度估计端到端处理,具有重要的现实意义。
技术实现要素:
发明目的:针对上述现有技术,提出基于深度卷积神经网络的目标深度估计方法,实现目标检测和深度估计的有效融合和端到端处理,并通过改进原有模型提高深度估计的整体精度,为智能体自主导航和环境感知提供基础。
技术方案:一种基于改进yolov3模型的深度估计方法,首先采用改进yolov3模型对左右视图分别进行目标检测;然后根据目标检测信息进行左右视图间的目标匹配;最后基于目标匹配结果完成对各类目标的深度估计。
进一步的,一种基于改进yolov3模型的深度估计方法包括如下具体步骤:
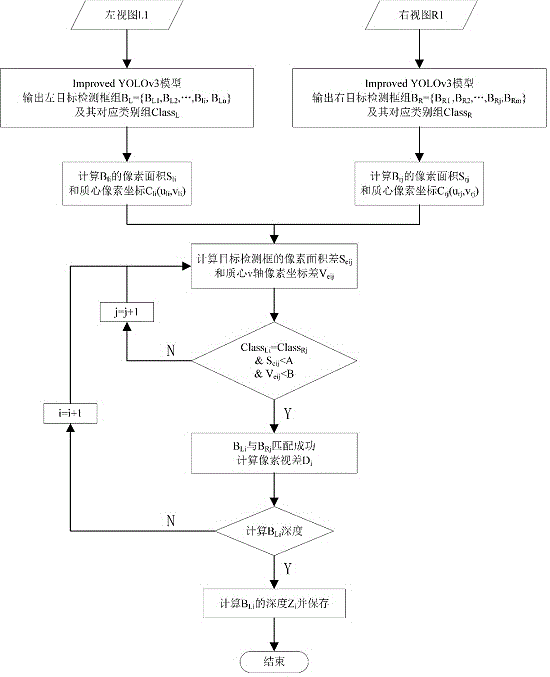
步骤1),采用改进yolov3模型对左右视图分别进行目标检测,包括如下具体步骤:
a),对原始yolov3模型的损失函数进行改进并针对性训练,其中x误差项正向赋值,其余项固定赋值,损失函数如式(1)所示:
式中,k为输入层网格数;m为单个网格预测的锚框数;
b),用改进的模型yolov3对左右视图分别进行目标检测,输出左右视图的目标检测框组bl={bl1,bl2,…,bli,bln}、br={br1,br2,…,brj,brm}和对应类别组classl、classr,并由式(2)得到左右视图中目标检测框的像素面积sli、srj和质心坐标cli(uli,vli)、crj(urj,vrj):
式中,xl1、yl1和xr1、yr1分别是左右视图中目标检测框左上顶点的像素坐标,xl2、yl2和xr2、yr2分别是左右视图中目标检测框右下顶点的像素坐标;
步骤2),根据目标检测信息进行左右视图间的目标匹配,包括如下具体步骤:
a),计算左右视图中任意两目标检测框的像素面积差seij和质心v轴像素坐标差veij,如式(3)所示:
b),对上述任意两目标检测框进行目标匹配,若满足条件则匹配成功,不满足条件则遍历至下一组重新进行目标匹配,匹配成功条件如式(4)所示:
式中,a、b为像素阈值;
步骤3),基于目标匹配结果完成对各类目标的深度估计,包括如下具体步骤:
a),对匹配成功的目标检测框组进行像素视差计算,然后将像素视差转换成视差,过程如式(5)所示:
式中di为像素视差;di为视差;xli、xrj分别是左右质心在物理成像平面坐标系下的横坐标;α为成像平面坐标系与像素坐标系的横轴缩放比例系数;
b),使用上述得到的视差对目标进行深度估计,过程如式(6)所示:
式中zi为目标深度;b为双目相机基线;fx为相机内参数矩阵中的标量;
进一步的,当进行步骤2)时,将左视图中目标检测框bl1同右视图中目标检测框组br进行遍历匹配,若某一对目标检测框满足式(4)要求,则目标匹配成功,并将右视图中该匹配成功的目标检测框移除目标检测框组br,且不再进行目标检测框bl1对应的后续框组遍历匹配,转而进行目标检测框bl2对应的框组遍历匹配,如此循环直至结束。
有益效果:本发明所提出的一种基于改进yolov3模型的深度估计方法,将基于深度卷积神经网络的目标检测信息用于深度估计,实现目标检测和深度估计的端到端处理;在对原始yolov3模型的改进过程中,结合深度估计的几何原理修改模型的损失函数并针对性训练,重点增强模型对左右视图中目标u轴坐标变化的敏感程度,从而实现改进模型对深度估计精度的控制。使用本发明所提出的方法,可极大地节省智能体环境感知的计算资源;同时,相较应用于原始模型,目标的深度估计精度得到了显著提升。
附图说明
图1深度估计方法流程图;
图2深度估计方法各步骤示意图;
图3双目相机深度估计模型;
图4像素视差计算模型;
图5改进yolov3模型训练的损失变化;
图6改进yolov3模型测试效果;
图7所提方法与原始模型的深度估计精度对比;
具体实施方式
下面结合附图和具体实施方式,进一步阐明本发明,应理解下述具体实施方式仅用于说明本发明而不用于限制本发明的范围。
一种基于改进yolov3模型的深度估计方法,使用基于深度卷积神经网络的目标检测和双目相机深度估计模型相结合的策略对目标进行深度估计,针对深度估计任务在原始yolov3模型的基础上进行了相关改进,将部分目标检测信息用于深度估计,实现对目标类别、定位和深度估计信息的全部输出;包括如下具体步骤:
步骤1),采用改进yolov3模型对左右视图分别进行目标检测,包括如下具体步骤:
a),对原始yolov3模型的损失函数进行改进并针对性训练,其中x误差项正向赋值,其余项固定赋值,损失函数如式(1)所示:
式中,k为输入层网格数;m为单个网格预测的锚框数;
b),用改进的模型yolov3对左右视图分别进行目标检测,输出左右视图的目标检测框组bl={bl1,bl2,…,bli,bln}、br={br1,br2,…,brj,brm}和对应类别组classl、classr,并由式(2)得到左右视图中目标检测框的像素面积sli、srj和质心坐标cli(uli,vli)、crj(urj,vrj):
式中,xl1、yl1和xr1、yr1分别是左右视图中目标检测框左上顶点的像素坐标,xl2、yl2和xr2、yr2分别是左右视图中目标检测框右下顶点的像素坐标;
步骤2),根据目标检测信息进行左右视图间的目标匹配,包括如下具体步骤:
a),计算左右视图中任意两目标检测框的像素面积差seij和质心v轴像素坐标差veij,如式(3)所示:
b),对上述任意两目标检测框进行目标匹配,若满足条件则匹配成功,不满足条件则遍历至下一组重新进行目标匹配,匹配成功条件如式(4)所示:
式中,a、b为像素阈值;
进一步的,当进行步骤2)时,将左视图中目标检测框bl1同右视图中目标检测框组br进行遍历匹配,若某一对目标检测框满足式(4)要求,则目标匹配成功,并将右视图中该匹配成功的目标检测框移除目标检测框组br,且不再进行目标检测框bl1对应的后续框组遍历匹配,转而进行目标检测框bl2对应的框组遍历匹配,如此循环直至结束。
步骤3),基于目标匹配结果完成对各类目标的深度估计,包括如下具体步骤:
a),对匹配成功的目标检测框组进行像素视差计算,然后将像素视差转换成视差,过程如式(5)所示:
式中di为像素视差;di为视差;xli、xrj分别是左右质心在物理成像平面坐标系下的横坐标;α为成像平面坐标系与像素坐标系的横轴缩放比例系数;
b),使用上述得到的视差对目标进行深度估计,过程如式(6)所示:
式中zi为目标深度;b为双目相机基线;fx为相机内参数矩阵中的标量;
在本实施例中设定目标检测框的像素面积差seij阈值a为60、质心v轴像素坐标差seij阈值b为4。将原yolov3模型和改进yolov3模型分别部署至嵌入式终端并对智能体前方不同距离段上的目标进行深度估计。保持s1030-120型双目相机与目标图像的质心在同一水平面上,且双目相机左右光心的中点与图像质心的连线垂直于相机基线方向。对每类障碍物进行多组深度估计,获得目标的深度估计值,并将ut393a型测距仪的测量值(精度±1.5mm)作为距离真值进行误差分析。实施例中采用误差均值em和误差比均值erm作为深度估计精度的指标,其定义分别如下
公式(7)(8)中z是测距仪的深度测量真值,zi是深度估计值,n是某距离段上的测量次数,取值为3。
通过网络爬虫和相机抓图建立目标(人、拖拉机)数据集,包括训练集2000张和测试集400张。针对训练集,本实施例选用dellt7920型图形工作站(12g内存titanv型显卡)对原yolov3模型和改进yolov3模型分别进行相同的迭代训练,其中改进yolov3模型的训练损失函数如图5所示。针对测试集中的两类目标(人、拖拉机),对原yolov3模型和改进yolov3模型分别进行测试,其中改进yolov3模型的测试结果如图6所示(图a-拖拉机、图b-行人)。
图7是两类目标(图a-拖拉机、图b-行人)的深度估计测试结果,填充柱形和实折线分别表示目标在该距离段处应用改进yolov3模型后的深度估计误差均值em和误差比均值erm,未填充柱形和虚折线分别表示目标在该距离段处应用原yolov3模型后的深度估计em、erm。由ab两图可知,应用改进yolov3模型后的深度估计em、erm相对于原yolov3模型均有很大改善;随着检测目标体积增大,其深度估计em、erm均有变大的趋势,但检测目标与相机之间距离增长,其深度估计em、erm的变化无明显规律。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!
- 基于FPGA及改进Whitham模型的在线交通瓶颈预测控制方法
- 基于FPGA及改进Aw-Rascle模型的在线交通瓶颈预测控制方法
- 基于FPGA及改进Kerner-Konhauser模型的在线交通瓶颈预测控制方法
- 基于FPGA及改进Michalopoulos模型的在线交通瓶颈预测控制方法
- 基于FPGA及改进Zhang模型的在线交通瓶颈预测控制方法
- 基于fpga及改进吴正模型的在线交通瓶颈预测控制方法
- 基于FPGA及改进Ross模型的在线交通瓶颈预测控制方法
- 基于FPGA及改进Payne-Whitham模型的在线交通瓶颈预测控制方法
- 基于FPGA及改进Payne模型的在线交通瓶颈预测控制方法
- 基于FPGA及改进Phillips模型的在线交通瓶颈预测控制方法