一种基于DBA-DTW-KNN的机械通气人机不同步快速识别方法与流程
本发明涉及一种机械通气人机不同步快速识别方法,首先使用基于dba和dtw实现数据集压缩,再基于knn的分类思想对机械通气中病人的无效吸气努力进行识别,进而可以评估呼吸机参数设置的合理性,为调整呼吸机参数设置相关领域提供辅助教学。
背景技术:
在重症监护室(intensivecareunit,icu)中,机械通气(mechanicalventilation,mv)是急性呼吸衰竭患者的重要生命支持手段。但是当患者的呼吸需求与呼吸机设置参数不匹配时,就会造成人机不同步,将会导致一系列不良的临床结果。常见的人机不同步类型包括无效吸气努力、双触发、周期过短、周期过长等。本发明主要针对无效吸气努力(ineffectiveinspiratoryeffortduringexpiration,iee)这一类型进行识别。无效吸气努力指的是患者在吸气努力后未触发呼吸机进行送气,在呼吸波形上主要表现为呼气相流速中有突起的同时伴随压力波形有凹陷。
早期最常用的人机不同步识别方式是依据肉眼在床边观察和评估呼吸机波形,这需要花费大量的医护人员资源。另外有文献报道可以通过基于规则的方法实现iee的识别,即在流速呼气相寻找极大值,然后在极大值到呼气结束点之间寻找最小值,计算极大值和最小值之间的差值,并设定阈值,当差值大于阈值时,认为该次呼吸是无效吸气努力;随机森林(randomforest,rf)以及自适应增强(adaboost)作为机器学习领域比较常见两种方法,被广泛使用于各个领域。因此,近年有学者提出使用随机森林以及自适应增强学习方法实现iee识别。但是,上述方法在iee识别上均存在较大局限性:基于规则的iee识别方法对于阈值的选取比较敏感,并且需要精准地检测呼气开始点;基于rf以及adaboost的iee识别方法在提取特征时,也涉及到呼气点的检测,同时对于各个特征的计算也十分麻烦。因此,需要设计一种更加简便的机械通气人机不同步的自动识别方法。
技术实现要素:
为了克服呼气开始点的精准检测比较困难、阈值设置不确定以及knn分类耗时等问题,本发明提出了一种基于dba-dtw-knn的机械通气人机不同步识别方法。
本发明解决其技术问题所采用的技术方案是:
一种基于dba-dtw-knn的机械通气人机不同步快速识别方法,该方法为:实时读取呼吸波形数据组成测试序列ql=(q1,q2,...,qp),并对呼吸波形数据进行标准化处理;然后计算测试序列ql与训练集c=(c1,c2,...,ce)中所有序列的dtw距离。采用dtw计算相似性距离,再结合knn分类思想,根据设定的k值对测试序列样本ql进行分类,k为正整数。其中,训练集c=(c1,c2,...,ce)的构建包括以下步骤:
a获取预标注的呼吸波形数据作为原始训练数据集s=(s1,s2,...,sm),其中,m表示原始训练数据集中序列的数量。
b对原始训练数据集中所有序列样本进行预处理。先对所有标注的呼吸序列样本分别做z-score标准化,将序列sm=(s1,s2,...,sn),m∈(1,2,...,m)标准化变换成
其中,μ为序列平均值,σ为序列标准差,m表示序列的序号,i表示采样点的序号。
c将经过预处理之后的原始训练数据集数据进行压缩。压缩步骤如下所示:
c1首先构建模板库
c2从经过预处理之后的原始训练数据集中选取一条非初始模板序列
c3将步骤c2计算得到的最小的平均dtw距离mean_dm与设置的阈值ε比较,当mean_dm≤ε时,将序列
c4重复执行步骤c2-c3直至原始训练数据集遍历完毕。
c5对模板库
进一步地,所述步骤a中,呼吸波形数据先由5名资历较低的医生进行第一轮的预标注,后由2名资历较高医生对第一轮的标注结果进行审核,以确保标注结果的准确性,然后提取所有无效吸气努力波形,并随机挑选相同数目的非无效吸气努力波形构成实验数据集。
进一步地,所述dtw距离通过如下公式计算:
其中,x,y表示两条不同的序列样本,x,y分别表示来自x,y序列的采样点,下标i,j表示采样点序号,d(xi,yj)=(xi-yj)2。d(i,j)表示最小累加距离;最终,由以下公式计算两序列的dtw距离,即dtw(x,y)。
进一步地,采用dba算法压缩的具体步骤为:
s1从目标模板集tk(tk,1,tk,2,...,tk,h)中随机挑选一条初始序列tk,j作为平均序列,其中k为模板集序号,k∈(1,2,...,e),j∈(1,2,...,h)表示该模板集中序列的序号;
s2有序选取目标模板集tk(tk,1,tk,2,...,tk,h)里面的序列tk,i(非初始序列tk,j),i≠j,i∈(1,2,...,h),基于动态规划的思想,将tk,i与tk,j对齐;
s3重复步骤s2直至目标模板集tk(tk,1,tk,2,...,tk,h)遍历完成;
s4计算对齐之后的所有序列的平均序列mean_tk;
s5若
s6当执行次数超过设定阈值δ时,将最后一次获得的mean_tk替代目标模板集中的所有序列。δ为任意整数。
本发明的有益效果主要表现在:利用基于dba-dtw-knn方法对呼吸波形进行相似度计算,成功克服了呼气开始点的精准检测比较困难、阈值设置不确定以及knn分类耗时的问题,为实现自动化快速识别人机不同步提供了基础。
附图说明
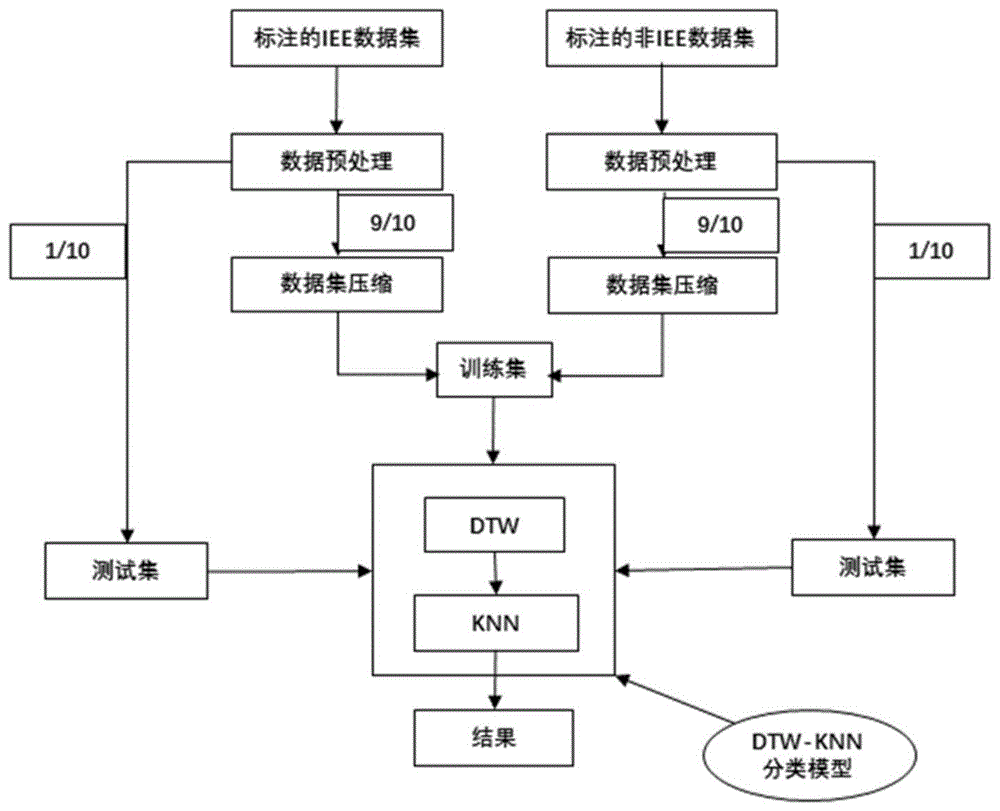
图1为本发明的流程示意图。
图2(a)为对原始波形进行预处理之后的示意图,(b)为序列经过dtw对齐之后的示意图。
图3为数据集压缩流程图。
图4为knn分类示意图,图中,三角形和方形表示已知的不同类别,圆形表示待分类。
图5为本发明方法不同生成模板阈值ε条件下的训练集生成时间图。
图6为本发明方法不同生成模板阈值ε条件下最优k值的测试时间图。
图7为标准dtw_knn方法不同k值条件下的测试时间图。
图8为本发明方法不同生成模板阈值ε条件下最优k值的准确率图。
图9为标准dtw_knn方法不同k值条件下的准确率图。
图10为本发明方法不同生成模板阈值ε条件下最优k值的f1得分图。
图11为标准dtw_knn方法不同k值条件下的f1得分图。
具体实施方式
下面结合附图对本发明作进一步描述。
本发明提供了一种基于dba-dtw-knn的机械通气人机不同步快速识别方法,其特征在于,该方法为:实时读取呼吸波形数据组成测试序列ql=(q1,q2,...,qp),并对呼吸波形数据进行标准化处理;然后计算测试序列ql与训练集c=(c1,c2,...,ce)里面的所有序列的dtw距离。采用dtw计算相似性距离,再结合knn分类思想,根据设定的k值对测试序列样本ql进行分类。其中,训练集c=(c1,c2,...,ce)通过预标注的呼吸波形数据压缩后获得。其中,k值为正整数。
优选地,用于构建训练集的采集的呼吸波形数据先由5名资历较低的医生进行第一轮的预标注,后由2名资历较高医生对第一轮的标注结果进行审核,以确保标注结果的准确性,然后提取所有无效吸气努力波形,并随机挑选相同数目的非无效吸气努力波形,从而对数据集进行了样本均衡。本实施方式中,在临床采集了17位病人共12305次呼吸,其中4689次无效吸气努力呼吸波形,7616次非无效吸气努力呼吸波形。
如图1流程图所示,一种基于dba-dtw-knn的机械通气人机不同步快速识别方法的训练集构建流程,包括如下步骤:
a提取所有无效吸气努力波形随机分为10等份,并随机挑选相同数目的非无效吸气努力波形组成组,从而对数据集进行了样本均衡。其中,9份为原始训练集s=(s1,s2,...,sm),1份为测试集q=(q1,q2,...,qr);
b对所有序列样本进行预处理。先对所有标注的呼吸序列样本分别做z-score标准化,以序列sm=(s1,s2,...,sn),m∈(1,2,...,m)转换为
其中,μ为序列平均值,σ为序列标准差,m表示序列的序号,i表示采样点的序号。
对序列进行z-score标准化是为了避免因基线水平不同而引发的问题。
c将经过预处理之后的原始训练集数据进行压缩。如图3所示,压缩步骤如下所示:
c1首先构建模板库
c2从经过预处理之后的原始训练数据集中选取一条序列
c3将最小的平均dtw距离mean_dm与设置阈值ε比较,当mean_dm≤ε时,将序列
c4重复执行步骤c2-c3直至训练数据集遍历完毕。
c5对模板库
d计算测试序列ql与训练集c=(c1,c2,...,ce)里面的所有序列的dtw距离。
e采用基于dtw的knn分类方法,其分类示意图如图4所示,根据设定的k值对测试序列样本ql进行分类。
具体地,dtw距离通过如下公式计算:以步骤d中dtw距离计算为例,选取测试集里面的一条测试序列样本ql=(q1,q2,...,qp),l=1,2,...,r,计算ql与训练集所有样本的dtw距离d=(d1,d2,...,de)。其中,对于两条不等长时间序列ql=(q1,q2,...,qp),l=1,2,...,r和ck(ck,1,ck,2,...,ck,r),k=1,2,...,e,dtw通过动态规划能够找到ql和ck之间的最佳规整路径,再通过以下公式得到最小累加距离d(i,j)。
其中,下标i,j表示采样点号,d(qi,ck,j)=(qi-ck,j)2。最终,可由以下公式(7)计算两序列的dtw距离,即dtw(ql,ck)。
上述方法中,dba算法的实现步骤为:
s1从目标模板集tk(tk,1,tk,2,...,tk,h)中随机挑选一条初始序列tk,j作为平均序列,其中k为模板集序号,k∈(1,2,...,e),j∈(1,2,...,h)表示是该模板集中序列的序号;
s2有序选取目标模板集tk(tk,1,tk,2,...,tk,h)里面的序列tk,i(非初始序列tk,j),i≠j,i∈(1,2,...,h),基于动态规划的思想,将tk,i与tk,j对齐;
s3重复步骤s2直至目标模板集tk(tk,1,tk,2,...,tk,h)遍历完成;
s4计算对齐之后的所有序列的平均序列mean_tk;
s5若
s6当执行次数超过设定阈值δ时,将最后一次获得的mean_tk替代目标模板集中的所有序列。其中,δ为任意整数,本实施例中,设定为δ=50。
另外,还可以通过设置不同阈值、构建多个训练集,采取预标记的测试集进行择优选取。本实施例中,设定k以2为步长,从1到15,阈值ε设置为以1为步长,从6到17,阈值λ设置为λ=15。
经测试集检测,本发明方法准确率以及f1得分与标准dtw_knn分类方法相当,但其训练集生成时间以及测试运行时间显著减少,为标准dtw_knn分类方法的测试时间的1/8-1/2,实验结果对比如图5-11所示。说明了该方法能够较为准确地快速判别机械通气人机不同步,可用于辅助教学。
通过dba-dtw-knn进行机械通气人机不同步的iee快速自动识别,解决了呼气开始点的精准检测困难、阈值设置不确定以及knn分类耗时的问题。
- 还没有人留言评论。精彩留言会获得点赞!