一种基于信息资源库的政务用户画像构建方法及其系统与流程
本发明属于数据处理、可视化技术领域,尤其涉及一种基于信息资源库的政务用户画像构建方法及其系统。
背景技术:
在互联网大数据时代,网络信息高度冗杂,尤其是在各类事务相互交叉关联、重复使用度高的政府领域,更需要对数据有极高的专业处理能力,对政务数据进行全面的挖掘和分析,实现信息的精准采集和推送,降低不断重复提交的政务手续,实现政府网站千人千网、专人专网的精准定位。
目前,现有的画像构建方法是采集用户行为数据,去除冗余数据,对清洗后数据进行分析处理和特征提取,形成用户标签并生成用户画像,以实现精准营销。但是,这种技术方案也存在不足,其只能解决传统领域中数据规模不大、容易采集和存储的资源,而对于政府领域,由于横向跨部门、纵向分级的管理结构,各部门、各层级系统间的数据多是相互独立的,并且存储形式分散无序,无法实现完整采集,统一有序的管理,进而对用户特征无法全面提取和有效描述,也就无法进行精准推送,这个是当前急需解决的问题。
技术实现要素:
为了解决现有技术对政务数据采集不完整导致画像描述不准确无法实现精确推送的问题,本发明提供一种基于信息资源库的政务用户画像构建方法及其系统,通过构建分类科学、集中规范、共享共用的信息资源库,按照“先入库,后使用”原则,对来自平台上各政府网站的信息资源以及对接应用系统数据库中的资源进行统一管理,实现统一采集、统一分类、统一元数据、统一数据格式、统一调用、统一监管,并运用压缩算法优化采集性能,通过模板自动切片智能提取特征标签,运用聚类算法自动关联标签构建用户分析模型,进而生成用户画像,最后将业务数据与用户画像相匹配,实现精准推荐,为实现政府网站的千人千网、专人专网的精准推送奠定基础。
本发明提供的一种基于信息资源库的政务用户画像构建方法,具体实现步骤是:
系统汇聚原始资源,判断不同存储介质特性,构建多源计算模型;判断原始资源数据类型、大小和使用频率,自动匹配合适的压缩算法并切片;动态收集网络速度、网络质量、后台服务器处理任务量级和处理能力等参数,自适应调整传输切片大小;运用数字指纹算法为每个切片生成一个数字指纹,比对数字指纹后将有效切片与多源计算模型进行匹配,统一编码、自动寻址存储到无限数据列表中;分析列表中的数字指纹特征,智能抽取特征输出特定标签;运用聚类算法自动关联特定标签,构建用户分析模型并进行机器训练和加权计算,根据权重生成用户画像;运用推荐算法对用户画像进行评分,根据得分实现多终端精准推送。
进一步地,原始资源来源可包括:区县信息资源库、数据库、文件系统、视频库、图片库、正风行风热线、政务信息公开、政务资料库等。
进一步地,多终端可以包括:网站发布系统、两微一端系统、政务服务门户、数据开发平台等。
进一步地,用户画像包括:法人用户画像、自然人用户画像。
进一步地,系统根据原始资源种类不同自动匹配合适的压缩算法,比如:图片优先使用rle压缩算法,音视频优先使用rice压缩算法,文本及其他类型使用deflate压缩算法,小文本优先选择snappy压缩算法。
进一步地,存储介质的种类包括:分布式文件系统、分布式缓存系统、非关系型数据库和关系型数据库等。
进一步地,针对网页元数据,运用dom节点剪枝算法分类网页模板,针对分类的网页模板运用视觉模型算法构造视觉模型和视觉模型链,分析视觉模型的结构化特征并通过模型抽取网页数据进而输出特定标签。
进一步地,推荐算法可包括:基于协同过滤的推荐算法、基于关联规则的推荐算法和基于内容的推荐算法等。
另外,本发明还提供一种可构建政务用户画像的信息资源库系统,该系统包括以下模块:
数据采集模块:运用采集工具从互联网、移动互联网多渠道多终端采集原始资源;
数据处理和存储模块:判断原始资源的数据类型、大小和使用频率,自动匹配合适的压缩算法并切片;动态收集网络速度、网络质量、服务器处理任务量级和处理能力等参数,自适应调整传输切片大小;运用数字指纹算法为每个切片生成一个数字指纹,比对数字指纹后将有效切片与多源计算模型进行匹配,统一编码、自动寻址并存储到标签语料库中;
模型构建和训练模块:判断各种存储介质的特性,构建多源计算模型;从标签语料库中提取特征并输出特定标签,运用聚类算法自动关联特定标签,构建用户分析模型并进行机器训练;
画像构建模块:通过用户分析模型对特定标签进行加权计算,根据权重生成用户画像,并存储到用户画像库中;
接口管理模块:对采集源、推送终端的接口进行管理;
推荐模块:运用推荐算法对用户画像进行评分,根据得分向多终端进行推送。
进一步地,数据处理和存储模块包括压缩子模块、指纹生成子模块、标签语料库和用户画像库。
进一步地,模型构建和训练模块包括智能提取子模块、模型构建和训练器。
进一步地,画像构建模块包括标签计算子模块、画像生成子模块。
进一步地,采集工具包括:etl工具和web数据采集工具,不同的采集工具适用于不同的信息源。etl工具多用于处理关系型数据库系统、xml文件和json文件的采集;web数据采集工具多用于处理web应用系统。
本发明提供的一种基于信息资源库的政务用户画像构建的方法及其系统,相比于现有技术具有以下优点:
本发明作为政务信息的汇聚管理平台,能够有效汇聚用户在政府网站上操作产生的所有信息,比如注册的用户基本信息,访问政府网站的浏览轨迹信息,在政府网站中的留言、投诉、来信、建议等信息,通过政府网站办理企业及个人服务事项的行为信息和过程记录等。通过对这些信息的智能分析梳理,构建法人/自然人政务用户画像,为实现政府网站的千人千网、专人专网的精准推送奠定基础。
附图说明
图1为实施例一提供的一种基于信息资源库的政务用户画像构建方法的流程示意图。
图2为实施例二提供的一种基于政务用户画像的信息资源库系统的结构示意图。
具体实施方式
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可以找说明书的内容予以实施,并且为了让本发明的上述和其他目的、特征和有点能够更明显易懂,以下为本发明的具体实施方式。
实施例一
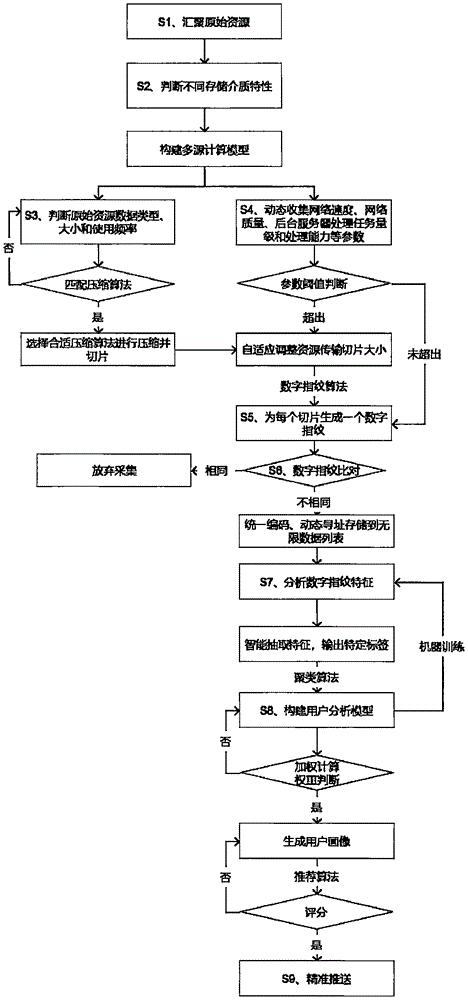
参见图1,为本实施例提供的一种基于信息资源库的政务用户画像构建方法,所举实例只用于解释本发明,并非用于限定本发明的范围。该方法具体包括以下步骤:
s1、系统汇聚原始资源;
s2、判断各个存储介质的特性,构建多源计算模型;
s3、判断原始资源的数据类型、大小和使用频率,为原始资源自动匹配合适的压缩算法并切片;
s4、动态收集网络速度、网络质量、服务器处理任务量级和处理能力等参数并判断,超出指定阈值时自适应调整传输切片大小;
s5、运用数字指纹算法为每个切片生成一个数字指纹;
s6、比对数字指纹,指纹不同时将有效切片与多源计算模型匹配进行统一编码和自动寻址,并存储到无限数据列表中,否则放弃采集;
s7、分析列表中的数字指纹特征,智能抽取特征输出特定标签;
s8、运用聚类算法自动关联特定标签并构建用户分析模型,对用户分析模型进行机器训练和加权计算,判断标签权重生成用户画像;
s9、运用推荐算法对用户画像进行评分,根据分数进行多终端精准推送。
其中,s1还包括以下步骤:
s1.1、分布式搜索引擎对采集源分区域设立检索服务器;
s1.2、经url地址重写将动态网页标准化为静态网页;
s1.3、网页模板引擎访问静态网页,从页面中分离出动态数据保存到缓存系统中,ssi直译服务器对静态网页做动态数据更新;
s1.4、运用文本挖掘算法对缓存中数据进行汇聚。
其中,s1.1中“采集源”包括:网页采集、客户端埋点采集、app采集和外部接口采集。
其中,s2中“存储介质”包括:分布式文件系统、分布式缓存系统、非关系型数据库和关系型数据库等。
其中,s3还包括以下步骤:
s3.1、判断原始资源是否为图片,若是,使用rle压缩算法;
s3.2、否则,判断原始资源是否为音视频,若是,使用rice压缩算法;
s3.3、否则,判断原始资源是否为文本及其他类型,若是,使用deflate压缩算法;
s3.4、对压缩后资源进行切片。
其中,s3.3中所述“文本”为小文件时,使用snappy压缩算法。
其中,s3中所述“原始资源的数据类型”包括如下格式:
其中,s5中所述“数字指纹”是指每条元数据集的唯一编码;s7中所述“特定标签”是指元数据集;s8中所述“用户画像”是指对元数据集进行加权计算根据权重形成的标签集合。
其中,s7中所述“特定标签”由不同类型的元数据集构成,元数据集又由元数据组成,每条元数据集包含一个数字指纹,唯一对应一个特定标签,元数据集按照数据类型分为:
其中,s7还包括以下步骤:
s7.1、分析列表中的数字指纹特征;
s7.2、当为网页元数据,运用dom节点剪枝算法分类网页模板;
s7.3、针对分类的网页模板运用视觉模型算法构造视觉模型和视觉模型链;
s7.4、分析视觉模型的结构化特征;
s7.5、智能抽取特征输出特定标签。
其中,s7.5中所述“特定标签”根据输出顺序不同包括:事实标签、模型标签和预测标签。
其中,s8还包括以下步骤:
s8.1、运用聚类算法自动关联事实标签,构建用户分析模型;
s8.2、对用户分析模型进行机器训练,输出模型标签;
s8.3、运用预测算法对模型标签进行预判,输出预测标签;
s8.4、对预测标签进行加权计算,判断标签权重生成用户画像。
其中,s8.1中所述“事实标签”是指:在政务活动中产生的行为数据,比如:描述自然人a的每一条元数据集都可以看作是一个事实标签;s8.2中所述“模型标签”是指:将行为数据通过数字指纹进行关联汇聚而成的用户特征,比如:将描述自然人a的每一个事实标签进行聚类,生成模型标签,如下:
其中,s8.3中所述“预测标签”是指:根据行为数据对用户特征进行预判形成的预测特征,比如:通过对自然人a的行为数据对其爱好进行预测,生成预测标签,如下:
其中,s8.4中所述“用户画像”是指:对预测标签进行加权计算,权重越高越接近用户特征,进而生成用户画像,比如:通过对自然人a的行为数据进行分析,可以了解其关心政府发布的哪些政策,访问了哪些政府网站、办理了哪些政务服务事项,最近在网站搜索了哪些词汇,通过政府网站提交了哪些留言、投诉、建议或来信的信息,时间越近、行为次数越多的行为其权重越高,就越接近用户特征,进而构建出用户画像。
其中,s8中所述“加权计算”可通过tf-idf算法实现,具体是:
比重公式
其中,w(p,t)表示某标签t被用于标记用户p的次数,w(p,ti)表示用户p身上全部标签个数,tf(p,t)表示某标签t的标记次数在用户p所有标签中所占的比重;
稀缺程度公式
其中,w(pi,ti)表示全部用户的全部标签之和,w(pi,t)表示所有打某标签t的用户之和,idf(p,t)表示某标签t在全部标签中的出现几率;
权重公式tag_weight(p,t)=tf(p,t)*idf(p,t)
考虑到某标签t所处的业务场景、距今时间、用户p产生某标签t的行为次数等因素,用户标签权重公式如下:
用户标签权重=(行为类型权重*时间衰减)*(tag_weight(p,t)*行为次数)
其中,行为类型权重表示用户浏览、搜索、收藏、访问、提交、投诉、建议等不同行为对用户而言有着不同的重要性,不同行为的权重也不相同;时间衰减表示某些行为受时间影响不断减弱,应乘以时间衰减函数;tag_weight(p,t)表示运用tf-idf算法计算用户身上每个标签的客观权重;行为次数表示用户产生每个标签的行为次数。
其中,s9中所述“精准推送”是指:与构成用户画像的标签进行匹配,匹配度越高,分值越高,近似度越大,进而实现精准推送,比如:自然人a最近在政府网站输入小升初,后台会判断该用户可能是一个孩子家长,孩子即将要升初中,那么本地所有小升初相关的政策、动态、活动等信息就会陆续推送给该用户;再比如:当政府网站和app发布新的信息时,先判断该信息对应的标签与哪些用户具有的标签相匹配,从而将信息精准的推送给匹配的用户,并且每个用户因为自身画像不同,收到的信息也不同,真正做到千人千网。
实施例二
参见图2,为本实施例提供的一种可构建政务用户画像的信息资源库系统,所举实例只用于解释本发明,并非用于限定本发明的范围。该系统具体包括以下模块:
数据采集模块:运用采集工具从互联网、移动互联网多渠道多终端采集原始资源;
数据处理和存储模块:判断原始资源的数据类型、大小和使用频率,为原始资源自动匹配合适的压缩算法并切片,动态收集网络速度、网络质量、服务器处理任务量级和处理能力参数并判断,超出指定阈值时自适应调整传输切片大小,运用数字指纹算法为每个切片生成一个数字指纹,比对数字指纹,指纹不同时将有效切片与多源计算模型匹配进行统一编码和自动寻址,并存储到标签语料库中;
模型构建和训练模块:判断各个存储介质的特性,构建多源计算模型,分析标签语料库中的数字指纹特征,智能抽取特征输出特定标签,运用聚类算法自动关联特定标签并构建用户分析模型,对用户分析模型进行机器训练;
画像构建模块:通过用户分析模型对特定标签进行加权计算,判断标签权重生成用户画像;
接口管理模块:对采集源、推送终端的接口进行管理;
推荐模块:运用推荐算法对用户画像进行评分,根据得分向多终端进行推送。
其中,该模型构建和训练模块进一步包括以下内容:
模型构建和训练器:判断各个存储介质的特性构建多源计算模型;从标签语料库中提取特征并输出特定标签,运用聚类算法自动关联特定标签构建用户分析模型,运用深度学习算法对用户分析模型进行机器训练;
智能提取子模块:针对网页元数据,分析存储的数字指纹特征,运用dom节点剪枝算法分类网页模板,针对分类的网页模板运用视觉模型算法构造视觉模型和视觉模型链,分析视觉模型的结构化特征并通过模型抽取网页数据进而输出特定标签;针对其他端数据,分析存储的数字指纹特征进而输出特定标签。
其中,该画像构建模块进一步包括以下内容:
标签计算子模块:通过用户分析模型对特定标签进行加权计算和权重判断;
画像生成子模块:根据权重生成用户画像,并存储到用户画像库中。
其中,该数据处理和存储模块进一步包括以下内容:
压缩子模块:判断原始资源的数据类型、大小和使用频率,自动匹配合适的压缩算法并切片;动态收集网络速度、网络质量、服务器处理任务量级和处理能力等参数,自适应调整传输切片大小;
指纹生成子模块:运用数字指纹算法为每个切片生成一个数字指纹,经数字指纹比对后将有效切片与多源计算模型匹配进行统一编码和自动寻址,并存储到标签语料库中;
标签语料库:存储输出的特定标签,包括事实标签、模型标签和预测标签,各个标签可由不同数据类型的元数据集构成,每条元数据集最多只能收录在一个标签下;
用户画像库:包括法人用户画像和自然人用户画像。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围不局限于此,任何熟悉本技术领域的技术人员在本发明的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!