一种注意力机制下基于特征表征的点击率预估模型的制作方法
1.本发明属于数据挖掘技术领域,具体为一种端到端点击预测技术,利用深度学习模型自动完成特征表征进而预测点击率的模型。
背景技术:
2.点击率预估作为直接影响用户平台体验和广告营收的关键技术,一直是业界最核心的研究课题之一。目前国内外的研究工作主要在特征表征层面,现有方法主要分为机器学习点击率模型和深度学习点击率模型两类。
3.早期阶段,工业界受限于计算力、在线学习和模型部署,主要是通过搭建轻量级机器学习模型,最经典模型当属逻辑回归模型(logistic regression)。lr以其数学含义好、可解释性强和便于工程化部署等优点迅速成为业界ctr预估主流模型。2010年brendan mcmahan等提出针对lr的在线学习算法ftrl(follow the regularized leader),进一步促进了lr在工业界的应用,但lr模型本质是线性模型,模型学习能力有限,其预测效果通常取决于数据科学家的特征工程能力。因此,业界开始探索使用二项式模型(polynomial regression)构造二阶组合特征,利用特征两两交叉进行显式特征组合,其暴力交叉方式一定程度上解决了特征组合问题,但其只能学习到训练数据集中出现的共现性特征,难以在推荐、广告等大规模稀疏数据场景下泛化出未共现的组合特征。为了解决二项式模型的缺陷,2010年德国康斯坦茨大学的steffen rendle等提出了fm(factorization machine),开始为每个特征学习一个隐权重向量(latent vector),使用隐向量內积作为特征交叉权重,较好地解决了稀疏特征场景下的特征组合问题,此外通过变换目标函数形式的方法,使fm训练复杂度进一步降低,因此fm在2012到2014年前后逐渐成为业界ctr模型的重要选择。2015年,基于fm提出的ffm(field-aware factorization machine)在多项ctr预估比赛中一举夺魁,并随后被criteo、美团等公司开始应用在推荐、广告场景。相比fm模型,ffm模型主要引入了“域”的概念,在做特征交叉时,每个特征选择与组合特征域对应的隐向量做内积运算得到交叉特征的权重,使模型的表达能力更强,但受限于ffm空间复杂度较高及只能进行二阶特征交叉等限制,其在工业界并未得到广泛使用。此外,2014年xinran he等提出了基于gbdt(gradient boost decision tree)+lr组合模型的解决方案,用于处理高维特征组合和筛选问题,其利用gbdt自动进行特征筛选和组合,利用独特编码对叶子节点进行编码,再把该编码特征作为lr模型输入完成ctr预估,开启了利用模型进行高阶特征构造、筛选的先河,较为高效的解决了过去非常棘手的特征组合和筛选问题,极大地推进了特征工程模型化这一重要趋势。
4.在此期间,研究人员发现高阶组合特征更容易挖掘出个性化需求,实现“千人千面”推送效果,受限于稀疏特征急剧增多,高阶组合特征业务逻辑难以理解等原因,传统的人工特征工程在挖掘高阶组合特征方面难以为继,人们开始尝试延续模型提取特征的优势,完成大数据场景下用户的个性化推送。伴随着深度学习在计算机视觉、自然语言处理领域大放异彩,人们开始尝试利用神经网络自动进行特征表征,进而取代手工特征工程完成
点击率预估。
5.2016年,深度学习开始被大规模应用于点击率预估,微软ying shan等提出deep crossing串行网络结构,其涵盖了ctr预估神经网络模型的经典要素,即通过加入嵌入层将稀疏特征转化为低维稠密特征,用堆叠层将分段的特征向量进行拼接,再通过多层神经网络完成特征的组合、转换,最终通过sigmoid激活函数完成ctr预估,并正式将残差网络结构引入点击率预估模型,用于加强模型高阶特征提取能力。同年,上海交通大学张伟楠等提出fnn,在之前deep crossing网络结构的基础上,使用fm的隐层向量作为用户和物料的嵌入,从而避免了完全从随机状态训练嵌入矩阵,大大降低了模型的训练时间和嵌入层的不稳定性。使用预训练的方法完成网络嵌入层训练,无疑是降低深度学习模型复杂度和训练不稳定性的有效工程经验。然而,传统的dnn直接利用多层全连接层完成特征交叉组合,对点击率预估场景缺乏特征组合的“针对性”,因此,yanru qu等提出pnn(product-based neural network),在嵌入层和全连接层之间加入product layer,旨在不同特征域之间进行特征组合,增强模型表征不同数据模式的能力。
6.2016年,谷歌heng-tze cheng等提出了wide&deep并行网络结构,把单输入层的wide部分和经过多层感知机的deep部分进行拼接传给输出层。利用wide部分实现模型的“记忆性”(memorization),deep部分实现模型的“泛化性”(generalization),其中dnn挖掘隐式高阶特征组合,lr连接wide部分和deep部分形成统一的ctr模型。wide&deep建立了一种基于深度学习的点击率预估并行框架,但仍未摆脱需要借助人工特征工程的限制。针对wide部分表现不足等缺陷,2017年,华为huifeng guo等提出了deepfm,在延续了wide&deep并行网络结构的基础上,使用fm替换原来的wide部分,加强了浅层网络的特征组合能力,同时摆脱了点击率预估深度模型对人工特征工程的依赖。同年,ruoxi wang等提出deep&cross network(dcn),开始使用cross网络替换了原来的wide部分,实现bit级别显式特征交互,进一步细化了wide部分的特征交叉粒度。xiangnan he等提出nfm(neural factorization machines)对deep部分进行改进,引入了bi-interaction pooling层替换fm进行特征交叉,进一步加强了deep层的特征组合能力。2018年阿里巴巴guorui zhou等提出了基于注意力机制的深度学习网络din(deep interest network),从用户行为序列中提取实时兴趣特征,进一步完善了用户侧特征表征。同年,jianxun lian等提出xdeepfm并行网路结构,建模vector级别显式特征交互,其wide部分采用cin(compressed interaction network)来加强模型的显式特征组合能力,取得了一定效果。随后,2019年guorui zhou等提出dien(deep interest evolution network),在din的基础上开始引入序列模型augru,将不同时间的用户兴趣串联起来,形成兴趣进化的链条,最后将当前时刻的“兴趣向量”输入上层的多层感知机,与其他特征联立完成点击率预估,取得了较好效果。
7.综上,目前的深度学习模型仍然无法做到利用神经网络取代手动特征工程进行特征提取、特征组合和特征筛选。进一步的就无法在利用神经网络取代手动特征工程的前提下,准确的对特征变化趋势进行预估,也就无法自动方式获取准确的点击率预估。
技术实现要素:
8.为解决上述问题,提供一种注意力机制下基于特征表征的点击率预估模型。本发明采用了如下技术方案:
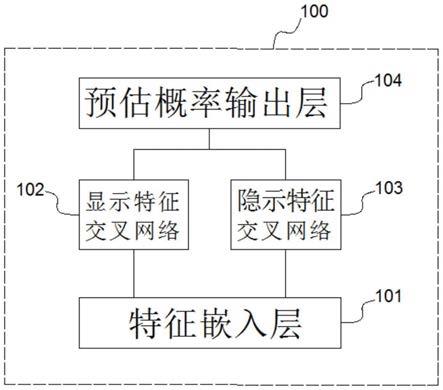
9.本发明的一种注意力机制下基于特征表征的点击率预估模型包括:特征嵌入层、显式特征交叉网络、隐式特征交叉网络以及预估概率输出层。特征嵌入层,将连续型特征和离散型特征进行矢量化处理后堆叠嵌入处理形成堆叠特征;显式特征交叉网络,通过将堆叠特征输入到注意力交叉网络进行显式特征组合,形成显式输出矢量;隐式特征交叉网络,通过将堆叠特征输入到多层感知机进行隐式特征组合,形成隐式输出矢量;预估概率输出层,将显式输出矢量和隐式输出矢量组合形成高阶非线性的组合特征,同时将该组合特征传递给sigmoid激活函数进行点击率预测,得到点击率;其中,注意力交叉网络包括:交叉层,通过交叉算法对堆叠特征进行处理并生成多维矢量;以及注意力层,通过全连接神经网络对多维矢量进行处理并生成注意力得分,并对注意力得分进行规范化处理生成特征系数,进一步基于特征系数通过输出计算式生成显式输出矢量。
10.本发明提供的一种基于机器学习的临产宫缩判别系统还具有这样的技术特征,其中,矢量化处理为:对离散型特征进行独热编码转换,将编码后的离散型特征作为嵌入向量;对连续型特征进行依据数据分布特点的数据标准化,形成稠密特征;将嵌入向量和稠密特征进行堆叠嵌入处理作为堆叠特征,独热编码转化的矩阵计算公式为:
11.x
embed,i
=w
embed,i
x
i
#(1)
12.式中,x
embed,i
是嵌入向量,x
i
是第i类的二进制输入,而是将与网络中的其他参数一起进行优化的嵌入矩阵,而n
e
和n
v
分别是输入维度和嵌入矢量维度。
13.本发明提供的一种基于机器学习的临产宫缩判别系统还具有这样的技术特征,其中,交叉算法的计算公式为:
[0014][0015]
式中,是列向量,分别表示来自第l层和第l+1层交叉层输出;是第l层的权重和偏差,函数f表示各层特征矢量交叉公式。
[0016]
本发明提供的一种基于机器学习的临产宫缩判别系统还具有这样的技术特征,其中,其中,注意力层中的规范化处理的计算逻辑为:
[0017]
a
′1=h
t
relu(wx
i
+b)#(3)
[0018][0019]
式中,是模型参数,注意力分数通过softmax进行标准化。
[0020]
本发明提供的一种基于机器学习的临产宫缩判别系统还具有这样的技术特征,其中,注意力交叉网络的输出计算式为:
[0021][0022]
[0023]
式中,a
i
是注意力权重。
[0024]
本发明提供的一种基于机器学习的临产宫缩判别系统还具有这样的技术特征,其中,多层感知机的各层计算逻辑如下:
[0025]
h
l+1
=f(w
l
h
l
+b
l
)#(7)
[0026]
式中,h
l+1
表示隐藏层,f(
·
)是relu函数。
[0027]
本发明提供的一种基于机器学习的临产宫缩判别系统还具有这样的技术特征,其中,sigmoid激活函数的公式为:
[0028][0029]
式中,分别是显式特征交叉网络和多层感知机的输出,通过sigmoid函数得到最终的点击率预测值。
[0030]
本发明提供的一种基于机器学习的临产宫缩判别系统还具有这样的技术特征,其中,注意力机制下基于特征表征的点击率预估模型通过logloss损失函数对点击率进行误差反传,直至输出层输出的点击率收敛,完成注意力机制下基于特征表征的点击率预估模型的参数更新。
[0031]
本发明提供的一种基于机器学习的临产宫缩判别系统还具有这样的技术特征,其中,logloss损失函数的公式如下:
[0032][0033]
式中,p
i
为点击率预估模型的输出,y
i
为样本对应标签,n为训练样本数,λ则为l2正则项系数,通过logloss损失函数进行误差反传并基于此进行参数更新,直至收敛完成最终点击率模型训练。
[0034]
发明作用与效果
[0035]
根据本发明的一种注意力机制下基于特征表征的点击率预估模型,由于具有特征嵌入层,该特征嵌入层通过对连续型特征和离散型特征进行矢量化处理克服了独热编码处理后矢量维度过大的问题。同时还具有显式特征交叉网络,该显式特征交叉网络通过注意力交叉网络实现组合项的动态加权,更高效地利用了组合特征,并消除了冗余特征对点击率预测模型的影响。进一步的还具有隐式特征交叉网络,该隐式特征交叉网络通过运用多层感知机完成了高度非线性的交互特征的捕获,从而克服了模型的特征表达能力被参数规模限制的问题。最后本发明具有预估概率输出层,该预估概率输出层通过sigmoid激活函数进行基于显式特征交叉网络和隐式特征交叉网络的输出的点击率预估,使得到的预估数据更准确。进一步的该预估数据可作为数据精排环节应用于企业级推荐系统、搜索系统和在线广告系统等领域。
附图说明
[0036]
图1是本发明实施例中的注意力机制下基于特征表征的点击率预估模型的结构框图;
[0037]
图2是本发明实施例中特征嵌入层的工作流程图;
[0038]
图3是本发明实施例中注意力交叉网络的网络结构图;
[0039]
图4是本发明实施例中多层感知机的网络结构图;
[0040]
图5是本发明实施例中注意力机制下基于特征表征的点击率预估模型的训练过程流程图;以及
[0041]
图6是本发明实施例中的点击率预估模型的部署工作的流程图。
具体实施方式
[0042]
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,以下结合实施例及附图对本发明的一种注意力机制下基于特征表征的点击率预估模型作具体阐述。
[0043]
<实施例>
[0044]
图1是本发明实施例中的注意力机制下基于特征表征的点击率预估模型的结构框图。
[0045]
如图1所示,注意力机制下基于特征表征的点击率预估模型100包括:特征嵌入层101、显式特征交叉网络102、隐式特征交叉网络103以及预估概率输出层104。
[0046]
本实施例中通过对用户侧特征、广告侧特征和上下文特征进行采集,并将采集到的这些特征分为连续型特征和离散型特征两类,将这两类特征作为输入特征,同时整理形成训练数据集,进一步的通过该训练数据集完成对注意力机制下基于特征表征的点击率预估模型100的模型训练。此训练数据集由n个样本(x,y)组成,输入特征为连续型特征和离散型特征,目标是构建点击率预估模型y=model(x),x∈r∧n用于预测在指定上下文中用户u点击侯选物料v
t
的概率y,y∈[0,1]
[0047]
特征嵌入层101对接收到的输入特征进行矢量化处理,并将得到的嵌入向量和稠密特征进行堆叠,形成堆叠特征并输出。
[0048]
图2是本发明实施例中特征嵌入层的工作流程图。
[0049]
如图2所示,特征嵌入层101形成堆叠特征的步骤如下:
[0050]
步骤s1,对离散型特征进行独热编码转换,将编码后的离散型特征作为嵌入向量,然后进入步骤s2;
[0051]
步骤s2,对连续型特征,进行基于数据分布特点的数据标准化,形成稠密特征,然后进入步骤s3;
[0052]
步骤s3,将步骤s1形成的嵌入向量和步骤s2形成的稠密特征进行堆叠嵌入处理即将嵌入向量和稠密特征堆叠到一个向量中,并将该向量称为堆叠特征,然后进入结束状态。
[0053]
本实施例中,堆叠嵌入处理的矩阵计算公式为:
[0054]
x
embed,i
=w
embed,i
x
i
#(1)
[0055]
式中,x
embed,i
是嵌入向量,x
i
是第i类的二进制输入,而是将与网络中的其他参数一起进行优化的嵌入矩阵,而n
e
和n
v
分别是输入维度和嵌入矢量维度。
[0056]
显式特征交叉网络102接收特征嵌入层101形成的堆叠特征,并通过注意力交叉网络对堆叠特征进行交叉算法并生成多维矢量;
[0057]
图3是本发明实施例中注意力交叉网络的网络结构图。
[0058]
如图3中a图所示,注意力交叉网络包括:交叉层21以及注意力层22。
[0059]
如图3中b图所示,交叉层21中每一层的神经元数量都相同且等于输入向量x0的维度。
[0060]
本实施例中,交叉算法的计算公式为:
[0061][0062]
式中,是列向量,分别表示来自第l层和第l+1层交叉层输出;是第l层的权重和偏差,函数f表示各层特征矢量交叉公式。
[0063]
注意力层22通过全连接神经网络对多维矢量进行处理并生成注意力得分,并对注意得分进行规范化处理生成特征系数,并基于特征系数通过输出计算式生成显式输出矢量。
[0064]
本实施例中,全连接神经网络采用的是attention network,激活函数使用relu,网络大小用注意力因子表示。另外,注意力层22中的规范化处理的计算逻辑为:
[0065]
a
′
i
=h
t
relu(wx
i
+b)#(3)
[0066][0067]
式中,是模型参数,注意力分数通过softmax进行标准化。将上式的结果作为特征系数,其中,注意力交叉网络的输出计算式为:
[0068][0069][0070]
式中,a
i
是注意力权重。
[0071]
隐式特征交叉网络103通过将堆叠特征输入到多层感知机进行隐式特征组合,形成隐式输出矢量。
[0072]
图4是本发明实施例中多层感知机的网络结构图。
[0073]
如图4所示,本实施例中多层感知机是一个全连接前馈神经网络,各层计算逻辑如下:
[0074]
h
l+1
=f(w1h
l
+b
l
)#(7)
[0075]
式中,h
l+1
表示隐藏层,f(
·
)是relu函数。
[0076]
预估概率输出层104将显式输出矢量和隐式输出矢量组合形成高阶非线性的组合特征,同时将该组合特征传递给sigmoid激活函数进行点击率预测,得到预估点击率。
[0077]
本实施例中,sigmoid激活函数的公式为:
[0078][0079]
式中,分别是显式特征交叉网络和多层感知机的输出,通过sigmoid函数得到最终的点击率预测值;
[0080]
获得点击率预测值后,注意力机制下基于特征表征的点击率预估模型100通过logloss损失函数对预估点击率进行误差反传,直至输出层输出的预估点击率收敛,完成注意力机制下基于特征表征的点击率预估模型的参数更新,进而完成了对注意力机制下基于特征表征的点击率预估模型100基于本实施例中的训练数据集的模型训练。
[0081]
本实施例中,logloss损失函数的公式如下:
[0082][0083]
式中,p
i
为点击率预估模型输出,y
i
为样本对应标签,n为训练样本数,λ则为l2正则项系数。
[0084]
图5是本发明实施例中注意力机制下基于特征表征的点击率预估模型的训练过程流程图。
[0085]
如图5所示,是本实施例中注意力机制下基于特征表征的点击率预估模型的训练过程为:
[0086]
步骤u1,构建数据集并将数据集中的数据特征分为连续型数据特征和离散型数据特征,然后进入步骤u2;
[0087]
步骤u2,构建特征嵌入层,将连续型特征和离散型特征进行矢量化处理后堆叠嵌入处理形成堆叠特征,然后进入步骤u3;
[0088]
步骤u3,构建显式特征交叉网络,通过将堆叠特征输入到注意力交叉网络进行显式特征组合,形成显式输出矢量,然后进入步骤u4;
[0089]
步骤u4,构建隐式特征交叉网络,通过将堆叠特征输入到多层感知机进行隐式特征组合,形成隐式输出矢量,然后进入步骤u5;
[0090]
步骤u5,构建预估概率输出层,将显式输出矢量和隐式输出矢量组合形成高阶非线性的组合特征,同时将该组合特征传递给sigmoid激活函数进行点击率预测,得到预估点击率,然后进入步骤u6;
[0091]
步骤u6,通过logloss损失函数对预估点击率进行误差反传,直至输出层输出的预估点击率收敛,完成注意力机制下基于特征表征的点击率预估模型的参数更新,进而完成模型训练,然后进入结束状态。
[0092]
本实施例中系统实现所用的编程环境是pycharm,python的版本是3.6。
[0093]
图6是本发明实施例中的点击率预估模型的部署工作的流程图。
[0094]
如图6所示,本实施例的注意力机制下基于特征表征的点击率预估模型训练完成后的具体工作步骤为:
[0095]
步骤t1,对现实业务场景进行原始数据采集,即通过前期数据埋点、后台日志提取和在线信息收集通过拼接汇总得到原始数据,然后进入步骤t2;
[0096]
步骤t2,对步骤t1收集到的原始数据进行预处理,形成整理数据,然后进入步骤t3;
[0097]
本实施例中预处理包括:对收集到的原始数据进行异常值处理、缺失值处理和噪声数据处理。
[0098]
步骤t3,将整理数据构造成点击率预估模型的训练数据集、测试数据集和验证数
据集,其比例分配需结合数据量和业务来定,然后进入步骤t4;
[0099]
步骤t4,将各数据集输入点击率预估模型,得到预估点击率,然后进入步骤t5;
[0100]
步骤t5,结合预估点击率挖掘符合用户兴趣偏好的特征工程,此处不进行任何手动特征工程,然后进入步骤s6;
[0101]
步骤t6,依据离线数据集性能表现取出对应的最佳超参组合,然后进入步骤t7;
[0102]
步骤t7,通过人为设定的模型衡量指标(点击率预估场景常使用logloss和auc作为评估指标)评估点击预估模型的预测性能,然后进入步骤t8;
[0103]
步骤t8,由算法工程师对点击预估模型进行线上小流量测试,验证模型的在线效果,通过测试后方可进行模型部署上线,然后进入结束状态。
[0104]
本实施例中,t6中超参选择方法为网格搜索、随机搜索和贝叶斯搜索。
[0105]
在完成以上模型部署后,运用本发明的注意力机制下基于特征表征的点击率预估模型100(deep&attention cross network,dacn)进行了一系列实验,点击率预估模型100中注意力交叉网络(attention cross network,acn)在实现时所用的编程环境是pycharm,python的版本是3.6。实验的运行环境为core i7 cpu,32gb内存,linux操作系统。实验的数据集来自criteo lab的真实点击数据和movielens的电影影评数据。使用两个指标进行模型评估:auc和logloss,这两个指标从不同层面评估模型的表现。
[0106]
实验将实现显式和隐式相结合的新型特征交叉网络dacn(deep&attention cross network)即本发明的与lr(logistic regression),dnn,fm(factorization machines),wide&deep,dcn(deep&cross network)和deepfm进行对比。如上文,这些模型是目前主流且经过工业界验证的点击率预估模型。因dacn旨在通过模型提取特征组合,为控制变量,我们将不对原始特征进行任何人工特征工程。
[0107]
本文在tensorflow上实现dacn。对稠密型特征使用对数变换进行数据标准化;对类别型特征,将特征嵌入到长度为6
×
dimension
1/4
的稠密向量中;使用adam优化器,采用mini-batch随机梯度下降,其中batch大小设置为512,dnn网络设置batch normalization。对于对比模型,遵循pnn中针对fnn和pnn的参数设置。其中,dnn模块设置了dropout为0.5,网络结构设置为400-400-400,优化算法采用基于adam的mini-batch梯度下降,激活函数统一使用relu,fm的嵌入维度设置为10,模型其余部分设置与dacn一致。
[0108]
图7是本发明实施例中单模型表现对比结果的示意图。
[0109]
首先验证注意力机制下显式组合特征对整体模型预测性能的作用。其中,对比模型中,fm显式度量2阶特征交互,dnn建模隐式高阶特征交互,cross network建模显式高阶特征交互,而acn建模显式特征交互并自带特征筛选。其中,各单模型在两公开数据集表现如图7所示。
[0110]
实验表明,本发明所提acn始终优于其他对比模型。作为结论,一方面,对于实际的数据集,稀疏特征上的高阶交互是必要的,这一点从dnn,cross network和acn在上述两个数据集上均明显优于fm得到证明;另一方面,acn是最佳的个体模型,验证了acn在建模显式高阶特征交互方面的有效性。
[0111]
图8是本发明实施例中集成模型表现对比结果的示意图
[0112]
dacn将acn和dnn集成到端到端网络结构中。其中acn用于显式组合特征提取及筛选,dnn用于隐式组合特征提取,通过两者并行联立,以期最大程度地进行特征表征。比较了
dacn与目前主流点击率预估模型在两公开数据集上的表现,实验结果如图8所不。
[0113]
从图8中容易得出,lr比所有其他模型都差,这表明基于因子分解的模型对于建模稀疏类交互特征至关重要;而wide&deep、dcn和deepfm则明显优于dnn,其结果表明dnn隐式特征提取能力比较受限,通常需要借助人工特征工程弥补特征组合能力不足的短板。其次,dacn相比于dcn指标提升明显。上文已从理论角度论证了dacn的优势,通过添加attention网络结构实现各指定阶组合特征筛选,提升重要组合特征权重,消除冗余特征影响。实验结果证明,该结构可较为有效地实现特征筛选,对整体模型表现具有较大提升。
[0114]
本发明所提的dacn在两个公开数据集上均实现了最佳性能,这表明将显式和隐式高阶特征联立,对原始特征表征更充分。同时,实验结果也验证了使用acn进行指定阶显式特征组合对最终模型表现具有很大提升,侧面验证了本发明所提dacn的合理性。
[0115]
图9是本发明实施例中网络参数数量对比结果的示意图
[0116]
考虑到acn引入的额外参数,在criteo数据集上对acn、crossnet及dnn进行了对比,比较各模型实现最佳对数损失阈值所需的最少参数数量,因为各模型嵌入矩阵参数数量相等,在参数数量计算中省略了嵌入层中的参数数量,实验结果如图9所示。
[0117]
从实验结果不难看出,本发明所提的acn和cross network的存储效率比dnn高出近一个数量级,主要原因是共有的特征交叉结构实现以线性空间复杂度完成指定阶特征交互。此外,acn与cross network参数量都属同一数量级,acn引入的attention网络只包含一个隐层,所需参数数量可近似忽略,但对模型点击率预测精度具有较大提升。从侧面验证了本发明所提acn结构在空间复杂度方面具有较大优势。
[0118]
实施例作用与效果
[0119]
根据本实施例提供一种注意力机制下基于特征表征的点击率预估模型,由于具有特征嵌入层,该特征嵌入层通过对连续型特征和离散型特征进行矢量化处理,进而克服了独热编码处理后矢量维度过大的问题。同时还具有显式特征交叉网络,该显式特征交叉网络通过注意力交叉网络实现组合项的动态加权,更高效地利用了组合特征,并消除了冗余特征对点击率预测模型的影响。进一步还具有隐式特征交叉网络,该隐式特征交叉网络通过运用多层感知机完成了高度非线性的交互特征的捕获,从而克服了模型的特征表达能力被参数规模限制的问题。最后由于具有预估概率输出层,该预估概率输出层通过sigmoid激活函数进行基于显式特征交叉网络和隐式特征交叉网络的输出的点击率预估,使得到的预估数据更准确。进一步的该预估数据可作为数据精排环节应用于企业级推荐系统、搜索系统和在线广告系统等领域。
[0120]
实施例中,由于在特征嵌入层中对离散型特征进行独热编码转换,将编码后的离散型特征作为嵌入向量和对连续型特征进行依据数据分布特点的数据标准化,形成稠密特征;上述两种低维稠密向量可以更有效保留原始语义信息。
[0121]
实施例中,交叉层中提出的交叉算法使得显式特征的组合更高效。
[0122]
实施例中,注意力层通过把不同的部分压缩在一起的时候,让不同部分的贡献程度不一样,进一步的让模型学习组合特征权重,从而实现特征自动提取。
[0123]
实施例中,显示特征交叉网络通过注意力交叉网络的机制实现组合项的动态加权,更高效地利用了组合特征,并消除了冗余特征对点击率预测模型的影响。
[0124]
实施例中,显式特征交叉网络和隐式特征交叉网络并行联立,进一步增强模型的
特征表征能力,提升点击率预估精度。
[0125]
实施例中,通过实验将本发明与目前主流且经过工业界验证的点击率预估模型分别进行单模型表现对比、集成模型表现对比以及网络参数数量对比,进一步验证了本发明的合理性以及本发明所提acn结构在空间复杂度方面具有较大优势。
[0126]
上述实施例仅用于举例说明本发明的具体实施方式,而本发明不限于上述实施例的描述范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1