基于卷积-门控循环神经网络的水泥回转窑电耗预测方法与流程
本发明涉及水泥回转窑电耗预测技术领域,尤其是基于卷积-门控循环神经网络的水泥回转窑电耗预测方法。
背景技术:
水泥工业是我国经济发展、生产建设和人民生活不可或缺的原材料工业,水泥烧成过程是水泥生产的重要过程,而电耗量是衡量水泥烧成过程能耗的重要参数,对电耗量进行精准预测,可以为水泥烧成过程调度的优化和综合能耗的降低提供依据,所以水泥烧成过程中电耗量预测具有重要的意义。
水泥烧成过程具有复杂性、随机性和动态时滞性等特点,难以使用传统数学方法建立一个精确的水泥能耗预测模型。针对上述问题,一些学者采用了不同的算法来研究用电量预测模型:
aranda等人采用多元非线性回归算法对电耗进行预测,此方法用于研究水泥生产过程中的非线性问题,难以解决时滞问题;zhao等使用卷积和长短时记忆网络建立风电功率预测;cui等基于支持向量机建立水泥工厂电耗预测模型,但没有解决变量之间的耦合问题。
上述研究由于自身局限性难以解决时变时延和变量间的耦合问题,因此本专利申请提出了一种基于cnn-gru的水泥回转窑电耗预测方法。
技术实现要素:
本发明需要解决的技术问题是提供一种基于卷积-门控循环神经网络的水泥回转窑电耗预测方法,解决了水泥烧成复杂工况多变量、强耦合、难以建立机理模型的特点,又解决了变量数据与电耗之间存在的时变时延问题。
为解决上述技术问题,本发明所采用的技术方案是:
一种基于门控循环神经网络的水泥回转窑电耗预测方法,包括以下步骤:
步骤1:分析整个水泥烧成的生产工艺,选取与电耗相关的10个输入变量,将变量数据进行归一化处理,考虑水泥生产过程的时延和变量之间的耦合,将归一化后的变量数据以横向为变量,竖向为时间顺序的方式排列;每一段时间的数据设置为一组作为二维卷积的输入;
步骤2:对步骤1中整理后的数据进行二维卷积及最大池化运算,将经过二维卷积和最大池化运算后的数据按照时间顺序将其重构为时序序列;
步骤3:将步骤2中得到的部分组时序序列作为门控循环神经网络模型的输入,数据在门控循环神经网络模型的内部门控单元中进行数据信息传播,门控循环神经网络模型通过更新门和重置门来控制信息的保留和丢失,前一时刻的留存信息和当前时刻的信息共同决定当前的输出;使用反向传播算法计算误差,更新权值和偏置,得到训练好的门控循环神经网络模型;
步骤4:将步骤2中得到的其他组时序序列输入到训练好的门控循环神经网络模型,进行水泥回转窑电耗的预测。
本发明技术方案的进一步改进在于:步骤1中,所述10个输入变量分别为:喂料量反馈、窑电流平均值、ep风机转速、高温风机转速、分解炉喂煤量、窑头煤、二次风温、窑尾温度、分解炉出口温度、一级筒出口温度。
本发明技术方案的进一步改进在于:步骤2中,所述二维卷积及最大池化运算包括:
(1)二维卷积运算时使用3x3大小的卷积核以平移方式对输入数据进行卷积运算,得到特征矩阵,将卷积核设定为若干个,从而提取输入数据的不同特征信息,得到多个特征矩阵;
(2)对得到的多个特征矩阵进行池化,使用最大池化方式对数据进行处理。
本发明技术方案的进一步改进在于:由于水泥生产过程的复杂性,各输入变量之间存在耦合关系,使用二维卷积可以提取输入变量间的耦合特征,将输入变量数据以横向为变量,竖向为时间顺序的方式排列,每一段时间的数据设置为一组,使用3x3大小的卷积核对输入数据进行卷积运算,得到特征矩阵,表达公式如下所示:
其中,
本发明技术方案的进一步改进在于:步骤3中,门控循环神经网络模型具体的计算过程如下:
s1:更新门的计算
更新门决定前一时刻和当前时间的信息有多少需要继续进行传递,更新门的输出由前一时刻隐藏状态输出和当前时刻输入共同决定,计算公式如下:
zt=σ(wz·[ht-1,xt]+bz)(2)
上式(2)中,wz是更新门的权重矩阵,[ht-1,xt]表示将前一时刻隐含层状态ht-1和当前时刻输入xt连接成一个更长的向量,σ是sigmoid激活函数,bz为更新门偏置项;
s2:重置门的计算
重置门决定有多少之前时刻的信息需要进行遗忘,重置门的输出同样由前一时刻隐藏状态输出和当前时刻输入共同决定,计算公式如下:
rt=σ(wr·[ht-1,xt]+br)(3)
上式(3)中,wr是重置门的权重矩阵,[ht-1,xt]表示将前一时刻隐含层状态ht-1和当前时刻输入xt连接成一个更长的向量,σ是sigmoid激活函数,br为重置门偏置项;
s3:当前输入的单元状态计算
上式(4)中,wh是单元状态的权重矩阵,rt是重置门的输出,ht-1为前一时刻隐含层状态,xt为当前时刻的输入,tanh是双曲正切激活函数,bh为单元状态偏置项;
隐含层最终输出由上一时刻的单元状态、当前时刻候选单元状态和更新门输出共同决定:
上式(5)中,h为当前时刻隐含层输出,ht-1为前一时刻隐含层状态,zt为更新门的输出,
序列预测输出:
上式(6)中,
s4:采用反向传播反向计算每个神经元的误差和每个权重的梯度,更新权值
为了计算方便,权重矩阵wr、wz、wh拆分成wrh、wrx、wzh、wzx、whh、whx;定义损失函数:
上式(7)中,
s5:权重梯度的计算
wrh、wzh、whh各时刻的权重梯度为:
wrx、wzx、whx的权重梯度:
与权重对应的偏置br,bz,bh梯度为:
s6:进行权重的更新
η为模型的学习率,为了增加公式的适用性,对公式进行泛化,w表示网络中四个节点的权重,l代表四个节点的偏置项;
s7:至此,完成一次前向和反向传播,重复上述过程,每经过一个时间步,求得误差项,若误差项小于阈值,则进行权重矩阵w和偏置项b的更新,直到误差小于设定阈值完成训练。
由于采用了上述技术方案,本发明取得的技术进步是:
1、本发明根据水泥烧成过程经验选取与水泥电耗相关的10个变量,充分考虑输入数据的结构特征,使用二维卷积提取变量间的耦合特征,为了描述电耗序列的时序依从关系,将卷积提取特征后的数据作为门控循环神经网络的输入信息,计算得到电耗的预测结果;在模型的反向传播中,采用随机梯度下降算法,通过误差项的反向传播求得权重梯度,达到权重更新的目的,模型预测精度提升的同时,训练效率得到提高。
2、本发明建立的水泥回转窑烧成过程电耗预测模型,使用二维卷积提取数据信息特征,充分考虑到了各变量之间的耦合关系。
2、本发明建立的预测模型,充分考虑了变量数据的时序特性,而且解决了长短时记忆网络参数较多,内部计算复杂的问题,使用更新门和重置门控制时时序信息的传递状态,解决时延问题。
附图说明
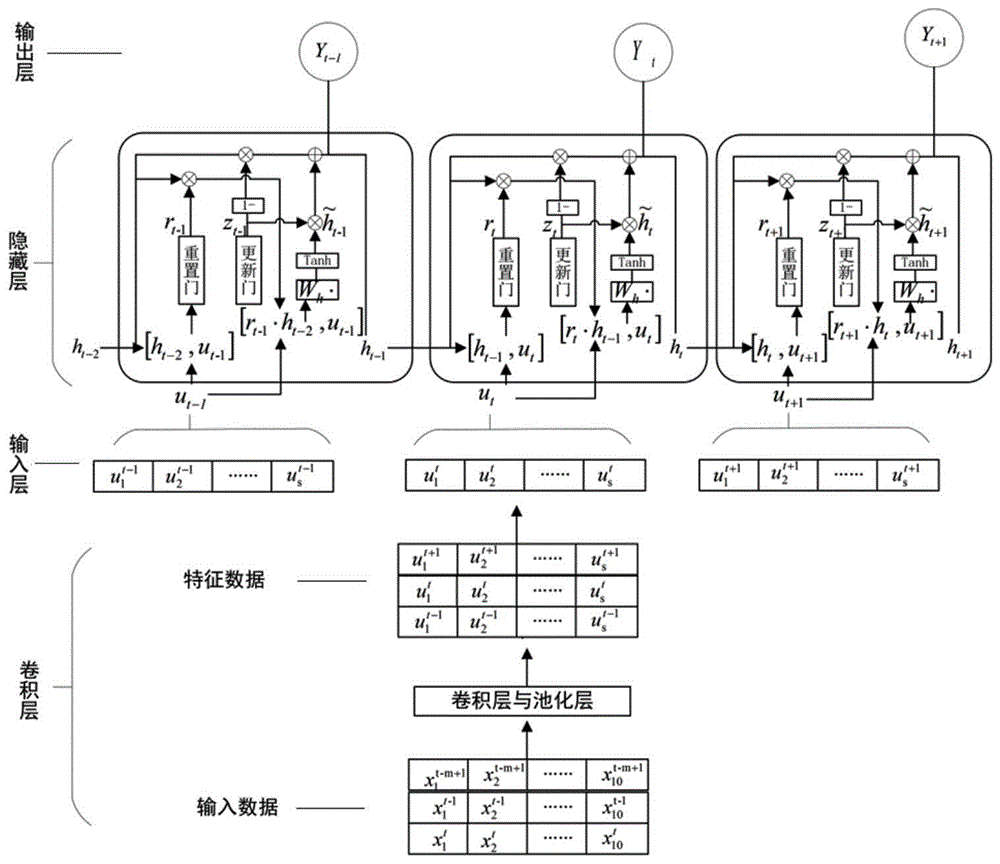
图1是本发明模型的结构图;
图2是本发明中二维卷积的特征提取图;
图3是本发明模型流程图。
具体实施方式
本发明是针对水泥烧成工艺流程的复杂性、随机性和动态时滞性等特点,难以用传统的数学方法建立精确的电耗预测模型,目前本技术领域现有的研究方法的自身局限性难以解决时变时延和变量间的耦合问题而研发的一种基于门控循环神经网络的水泥回转窑电耗预测方法。
下面结合附图及实施例对本发明做进一步详细说明:
如图1所示,一种基于门控循环神经网络的水泥回转窑电耗预测方法,包括以下步骤:
步骤1:分析整个水泥烧成的生产工艺,选取与电耗相关的10个输入变量,将变量数据进行归一化处理,考虑水泥生产过程的时延和变量之间的耦合,将归一化后的变量数据以横向为变量,竖向为时间顺序的方式排列;每一段时间的数据设置为一组作为二维卷积的输入;所述10个输入变量分别为:喂料量反馈、窑电流平均值、ep风机转速、高温风机转速、分解炉喂煤量、窑头煤、二次风温、窑尾温度、分解炉出口温度、一级筒出口温度。
步骤2:对步骤1中整理后的数据进行二维卷积及最大池化运算,将经过二维卷积和最大池化运算后的数据按照时间顺序将其重构为时序序列;所述二维卷积及最大池化运算包括:
(1)二维卷积运算时使用3x3大小的卷积核以平移方式对输入数据进行卷积运算,得到特征矩阵,将卷积核设定为若干个,从而提取输入数据的不同特征信息,得到多个特征矩阵;由于水泥生产过程的复杂性,各输入变量之间存在耦合关系,使用二维卷积可以提取输入变量间的耦合特征,将输入变量数据以横向为变量,竖向为时间顺序的方式排列,每一段时间的数据设置为一组,使用3x3大小的卷积核对输入数据进行卷积运算,得到特征矩阵,表达公式如下所示:
其中,
(2)对得到的多个特征矩阵进行池化,使用最大池化方式对数据进行处理。
步骤3:将步骤2中得到的部分组时序序列作为门控循环神经网络模型的输入,数据在门控循环神经网络模型的内部门控单元中进行数据信息传播,门控循环神经网络模型通过更新门和重置门来控制信息的保留和丢失,前一时刻的留存信息和当前时刻的信息共同决定当前的输出;使用反向传播算法计算误差,更新权值和偏置,得到训练好的门控循环神经网络模型;
门控循环神经网络模型具体的计算过程如下:
s1:更新门的计算
更新门决定前一时刻和当前时间的信息有多少需要继续进行传递,更新门的输出由前一时刻隐藏状态输出和当前时刻输入共同决定,计算公式如下:
zt=σ(wz·[ht-1,xt]+bz)(2)
上式(2)中,wz是更新门的权重矩阵,[ht-1,xt]表示将前一时刻隐含层状态ht-1和当前时刻输入xt连接成一个更长的向量,σ是sigmoid激活函数,bz为更新门偏置项;
s2:重置门的计算
重置门决定有多少之前时刻的信息需要进行遗忘,重置门的输出同样由前一时刻隐藏状态输出和当前时刻输入共同决定,计算公式如下:
rt=σ(wr·[ht-1,xt]+br)(3)
上式(3)中,wr是重置门的权重矩阵,[ht-1,xt]表示将前一时刻隐含层状态ht-1和当前时刻输入xt连接成一个更长的向量,σ是sigmoid激活函数,br为重置门偏置项;
s3:当前输入的单元状态计算
上式(4)中,wh是单元状态的权重矩阵,rt是重置门的输出,ht-1为前一时刻隐含层状态,xt为当前时刻的输入,tanh是双曲正切激活函数,bh为单元状态偏置项;
隐含层最终输出由上一时刻的单元状态、当前时刻候选单元状态和更新门输出共同决定:
上式(5)中,h为当前时刻隐含层输出,zt为更新门的输出,ht-1为前一时刻隐含层状态,
序列预测输出:
上式(6)中,
s4:采用反向传播反向计算每个神经元的误差和每个权重的梯度,更新权值
为了计算方便,权重矩阵wr、wz、wh拆分成wrh、wrx、wzh、wzx、whh、whx;定义损失函数:
上式(7)中,
s5:权重梯度的计算
wrh、wzh、whh各时刻的权重梯度为:
wrx、wzx、whx的权重梯度:
与权重对应的偏置br,bz,bh梯度为:
s6:进行权重的更新
η为模型的学习率,为了增加公式的适用性,对公式进行泛化,w表示网络中四个节点的权重,l代表四个节点的偏置项;
s7:至此,完成一次前向和反向传播,重复上述过程,每经过一个时间步,求得误差项,若误差项小于阈值,则进行权重矩阵w和偏置项b的更新,直到误差小于设定阈值完成训练。
步骤4:将步骤2中得到的其他组时序序列输入到训练好的门控循环神经网络模型,进行水泥回转窑电耗的预测。
具体的:
“卷积”英文缩写为cnn,门控循环神经网络英文缩写为gru。
一种基于门控循环神经网络的水泥回转窑电耗预测方法,首先从水泥烧成系统的数据库中选取与电耗相关的10个输入变量,使用二维卷积和最大池化对输入数据进行特征提取,将提取的特征数据分解重构后作为gru模型的输入,采用反向传播算法求取神经网络各节点的误差项,反复训练,获得训练好的模型。整体结构如图1所示,二维卷积的特征提取如图2所示,基于门控循环神经网络的水泥回转窑电耗预测模型流程如图3所示。
步骤1:分析整个水泥烧成的生产工艺,结合现场工程师的经验知识,选取了10种与电耗相关的过程参量作为输入变量,如图1中输入层所示,10输入变量分别为喂料量反馈x1、窑电流平均值x2、ep风机转速x3、高温风机转速x4、分解炉喂煤量x5、窑头煤x6、二次风温x7、窑尾温度x8、分解炉出口温度x9、一级筒出口温度x10。先对数据进行归一化处理,充分考虑水泥生产过程的时延和变量之间的耦合,将归一化后的变量数据以横向为变量,竖向为时间顺序的方式排列,每一段时间的数据设置为一组作为二维卷积的输入。
步骤2:对步骤1中整理后的数据进行二维卷积及最大池化运算,将经过卷积池化后的数据进行分解并重塑为顺序时间分量作为gru模型的输入。二维卷积的特征提取如图2所示,卷积层通过设定卷积核的大小和移动步长,以平移方式,对输入数据进行卷积运算,得到特征矩阵,公式如下所示:
其中,
步骤3:将步骤2中得到的其中一组时序序列作为gru模型的输入,数据在gru模型的内部门控单元中进行数据信息传播,使用反向传播算法计算误差梯度,更新权值和偏置,得到训练好的gru模型。gru模型具体的计算过程如下:
s1:更新门的计算
更新门来决定前一时刻和当前时间的信息有多少需要继续进行传递,更新门的输出由前一时刻隐藏状态输出和当前时刻输入共同决定,更新门的计算:
zt=σ(wz·[ht-1,xt]+bz)(2)
上式中,wz是更新门的权重矩阵,[ht-1,xt]表示将前一时刻隐含层状态ht-1和当前时刻输入xt连接成一个更长的向量,σ是sigmoid激活函数,bz为更新门偏置项。
s2:重置门的计算
重置门来决定有多少之前时刻的信息需要进行遗忘,重置门的输出同样由前一时刻隐藏状态输出和当前时刻输入共同决定,重置门的计算:
rt=σ(wr·[ht-1,xt]+br)(3)
上式中,wr是重置门的权重矩阵,[ht-1,xt]表示将前一时刻隐含层状态ht-1和当前时刻输入xt连接成一个更长的向量,σ是sigmoid激活函数,br为重置门偏置项。
s4:当前输入的单元状态计算
上式中,wh是单元状态的权重矩阵,rt是重置门的输出,ht-1为前一时刻隐含层状态,xt为当前时刻的输入,tanh是双曲正切激活函数,bh为单元状态偏置项。隐含层最终输出由上一时刻的单元状态、当前时刻候选单元状态和更新门输出共同决定:
上式中,h为当前时刻隐含层输出,zt为更新门的输出,
上式中,
s4:采用反向传播反向计算每个神经元的误差和每个权重的梯度,更新权值。
为了计算方便,权重矩阵wr、wz、wh拆分成wrh、wrx、wzh、wzx、whh、whx。定义损失函数:
上式中,
s5:权重梯度的计算
权重梯度的计算wrh、wzh、whh各时刻的权重梯度为:
wrx、wzx、whx的权重梯度:
与权重对应的偏置br,bz,bh梯度为:
s6:权重的更新
我们求出了各参数的梯度,下面进行权重的更新,η为模型的学习率,为了增加公式的适用性,对公式进行泛化,w表示网络中四个节点的权重,l代表四个节点的偏置项。
s7:至此,完成一次前向和反向传播,重复上述过程,每经过一个时间步,求得误差项,若误差项小于阈值,则进行权重矩阵w和偏置项b的更新,直到误差小于设定阈值完成训练。
步骤4:将处理后的水泥回转窑的过程变量数据输入到训练好的门控循环神经网络(gru)模型,实现水泥回转窑电耗的预测。
在本方法中,从水泥企业生产数据库中提取2000组数据,并按所述方法进行数据处理和模型训练。选取其中1600组作为训练数据,其余400组作为预测数据以验证模型有效性。
综上所述,本发明根据水泥烧成过程经验选取与水泥电耗相关的10个变量,充分考虑输入数据的结构特征,使用二维卷积提取变量间的耦合特征,为了描述电耗序列的时序依从关系,将卷积提取特征后的数据作为门控循环神经网络的输入信息,计算得到电耗的预测结果;在模型的反向传播中,采用随机梯度下降算法,通过误差项的反向传播求得权重梯度,达到权重更新的目的,模型预测精度提升的同时,训练效率得到提高。本发明既解决了水泥回转窑复杂工况多变量、强耦合,难以建立机理模型的特点,又解决了变量数据存在的时变实延问题,可以为水泥烧成过程的管理提供规划调度依据。
- 还没有人留言评论。精彩留言会获得点赞!