一种手写文档文本的检测识别方法与流程
本发明涉及深度学习技术领域,特别涉及一种手写文档文本的检测识别方法。
背景技术:
二十世纪末,首次提出了自然场景中复杂彩色图像中文本块位置检测的问题。由于解决该问题具有很大的经济和文化效益,因此该问题很快成为计算机视觉和文档分析领域的热点。在上述问题提出后的几十年间,各种不同的文本检测识别方法被提出。
对于文本检测而言,目前主要有如下几种方法:
1、基于能力最小化方法,其大部分方法都是基于条件随机场和马尔可夫随机场的,把文本行的检测问题看作是能量最小化问题,以解决文本行之间的干扰;
2、基于连通域的方法,其核心思想是找出小的部分组成大的部分,然后通过分类器去掉非文字部分,最终从图像中抽取文字并结合成文字区域,基于连通域的方法最具有代表性的是最大稳定极值区域(mser)和笔划宽度转换(swt);
3、基于深度学习的方法,利用卷积神经网络从图像中提取高维特征,实现文本检测识别。
对于文本识别,目前主要有如下几种方法:
1、基于字符的方法,该方法执行字符级的文本识别,成功识别字符可以使得自底向上的文本识别更容易实现;
2、基于词组的方法,将文本识别视作单词识别;
3、基于序列的方法,将文本识别问题转化成序列识别问题,文本通过字符序列表示,利用卷积循环神经网络处理任意长度序列。
自然场景下手写文档中的文本检测识别与传统ocr识别不同。与ocr相比,自然场景下手写文档中的文本检测识别存在着非常多的挑战:
其一是场景复杂性,噪音、变形、不统一照明、局部遮挡、文字和背景的混淆等都会影响检测识别效果;
其二是文字多样性,颜色、大小、方向、字体、语言、文字部分残缺等也会影响检测识别效果。
该问题的解决有着巨大的文化经济效益,比如可以帮助视觉障碍人群阅读文档、实现实时拍照翻译等。但是由于自然场景下拍摄的手写文档图片中具有很多的干扰因素,传统的文本检测识别方法并不能很好的应用到自然场景。基于此,本发明提出了一种手写文档文本的检测识别方法。
技术实现要素:
本发明为了弥补现有技术的缺陷,提供了一种简单高效的手写文档文本的检测识别方法。
本发明是通过如下技术方案实现的:
一种手写文档文本的检测识别方法,其特征在于:包括文本行定位和文本行检测两部分;
文本行定位网络使用变形的vgg-11,对一张图片经过网络训练,回归得到(x0,y0)坐标、尺度s0、旋转度θ0以及文本行出现的可能性p0,从而在图片上找到文本行可能的开始位置;
文本行检测网络增量地沿着文本行前向传播,通过文本行定位网络得到的文本行开始位置和旋转角度(xi,yi,θi),重新采样获得一个查看窗口,输入到cnn网络回归得到下一个位置的(xi+1,yi+1,θi+1),一直重复此过程直到达到图片边缘,最终产生归一化的文本行图片,输入到文本行识别网络,文本行识别网络识别文本行图片并输出识别结果。
输入到所述文本行定位网络前,先对数据集进行处理,输出所有的文本行图片,同时输出json标注信息,包括图像路径、每一行文本的区域坐标、每一行中每一个字所在区域的坐标以及每一行文本的文字内容。
所述文本行定位网络的处理方法,包括以下几个步骤:
s1.读取图像标签json文件,遍历json文件,剔除标注错误的部分;
s2.将输入图像resize到512像素宽,并且在整张图片上采样256*256个图像patch,允许每个patch使用该图像patch边缘的平均颜色填充扩展到图像外部;
s3.将每一个16*16的输入图像块输入到变形的vgg-11网络进行训练,经过网络训练回归得到(x0,y0)坐标、尺度s0、旋转度θ0以及文本行出现的可能性p0;
s4.经过训练后,使得p0=1,(x0,y0)坐标、尺度s0和旋转度θ0等于0;
s5.使用文本行定位模块确定图片中文本行开始位置之后,文本行检测网络沿着文本行的路径增量逐步前进,确定出完成的文本行区域。
所述变形的vgg-11网络删除了经典的vgg-11网络中的全连接层以及最后一个池化层,其所有卷积层都是同样大小的卷积核,尺寸为3*3,步长stride为1,填充padding为1。
所述步骤s4中,训练过程使用针对多框目标检测问题提出的损失函数,在最大概率预测的文本行开始位置和目标位置之间对齐,其损失函数如下所示:
其中,tm是目标位置,pn是sol出现的可能性,xnm是n个预测位置和m个目标位置之间的一个双向对齐矩阵,α是衡量位置loss和置信度loss之间相对重要性的参数,默认取0.01,ln是对卷积神经网络的初始预测结果(xn,yn,sn,θn)的代数变换,给定(l,p,t)计算使得l最小的xnm,ln的计算公式如下:
ln=(-sin(θn)sn+xn,-cos(θn)sn+yn,sin(θn)sn+xn,cos(θn)sn+yn)
所述文本行检测网络的处理方法,包括以下几个步骤:
s1.读取图像标签json文件,遍历json文件,剔除标注错误的部分;
s2.文本行检测网络递归增量运行,通过文本行定位网络得到的文本行开始位置和旋转角度(xi,yi,θi),重新采样获得一个查看窗口;
s3.输入到cnn网络回归得到下一个位置的(xi+1,yi+1,θi+1);
s4.重复上述步骤直到达到图片边缘,查看窗口的尺寸由文本行定位模块预测的尺度s0确定,且保持不变。
所述步骤s2中,重采样查看窗口的过程类似于空间变换网络,使用放射变换矩阵将图像坐标映射到查看图像坐标;
第一个查看窗口矩阵是w0=awsol,其中矩阵a是一个前向传播矩阵,负责为文本行检测网络提供上下文信息来使其正确定位文本行;
所述矩阵a与矩阵wsol的计算公式如下:
其中的参数是由文本行定位网络预测得到的;
根据wi矩阵提取一个32*32的查看窗口,然后文本行发现网络回归得到xi,yi以及θi,利用回归得到的xi,yi,θi以及预测矩阵pi计算下一个矩阵wi=piwi-1;
所述预测矩阵pi的计算公式如下:
为了定位文本行,把文本行视为一系列上下坐标点对pu,i和pl,i,坐标对通过预测窗口的上下中点来计算;
在卷积神经网络的训练过程中使用均方误差(meansquareerror)损失函数,计算公式如下:
文本检测网络在第一个目标位置处开始,即tu,0和tl,0,每4步重置相应的位置点,其目的是当文本行检测网络偏离手写文本行时,可以恢复正确的路径,而不会在训练过程中引入大量错误;
为了增强文本行检测网络的鲁棒性,在重置目标位置后,对目标位置随机施加δx,δy∈[-2,2]像素的平移变换以及δθ∈[-0.1,0.1]弧度的旋转变换。
所述文本行检测网络输出归一化的文本行图片,输入到文本行识别网络;文本行识别网络使用传统卷积神经网络以及双向循环神经网络,在框架的顶层使用ctc进行loss计算,对输入的不定长文本行图片进行识别,输出文本行识别结果。
本发明的有益效果是:该手写文档文本的检测识别方法,不仅能够克服自然场景下的干扰因素,准确的检测识别文本,还能够正确地沿着文本行的延展方向递归前进,最终检测出弯曲文本行。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
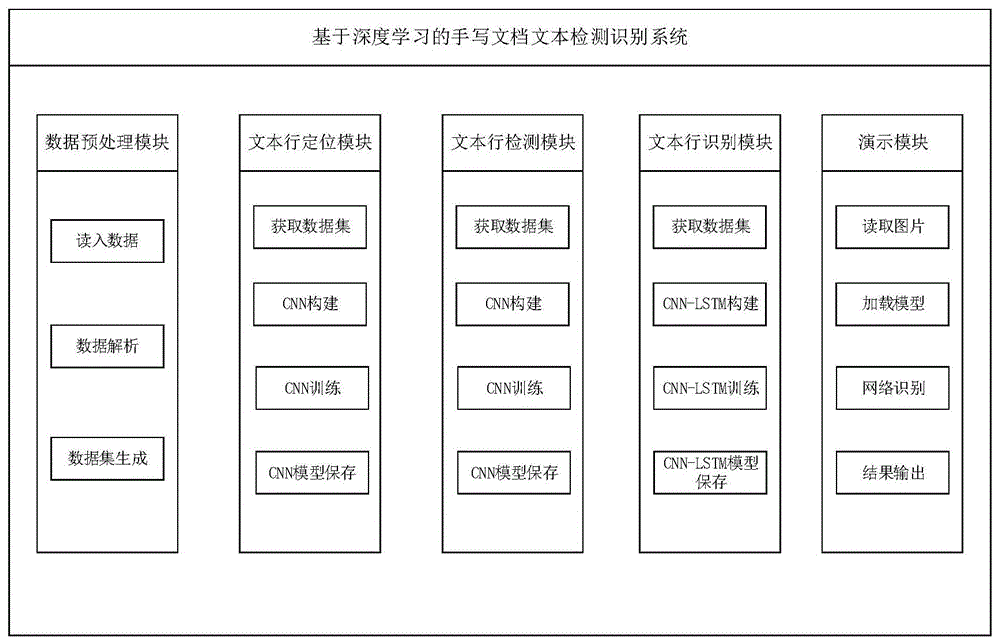
附图1为本发明手写文档文本的检测识别系统示意图。
具体实施方式
为了使本技术领域的人员更好的理解本发明中的技术方案,下面将结合本发明实施例,对本发明实施例中的技术方案进行清楚,完整的描述。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
该手写文档文本的检测识别方法,基于深度学习技术,包括文本行定位和文本行检测两部分;
文本行定位网络使用变形的vgg-11,对一张图片经过网络训练,回归得到(x0,y0)坐标、尺度s0、旋转度θ0以及文本行出现的可能性p0,从而在图片上找到文本行可能的开始位置;
文本行检测网络增量地沿着文本行前向传播,通过文本行定位网络得到的文本行开始位置和旋转角度(xi,yi,θi),重新采样获得一个查看窗口,输入到cnn网络回归得到下一个位置的(xi+1,yi+1,θi+1),一直重复此过程直到达到图片边缘,最终产生归一化的文本行图片,输入到文本行识别网络,文本行识别网络识别文本行图片并输出识别结果。
输入到所述文本行定位网络前,先对数据集进行处理,输出所有的文本行图片,同时输出json标注信息,包括图像路径、每一行文本的区域坐标、每一行中每一个字所在区域的坐标以及每一行文本的文字内容。
所述文本行定位网络的处理方法,包括以下几个步骤:
s1.读取图像标签json文件,遍历json文件,剔除标注错误的部分;
s2.将输入图像resize到512像素宽,并且在整张图片上采样256*256个图像patch,允许每个patch使用该图像patch边缘的平均颜色填充扩展到图像外部;
s3.将每一个16*16的输入图像块输入到变形的vgg-11网络进行训练,经过网络训练回归得到(x0,y0)坐标、尺度s0、旋转度θ0以及文本行出现的可能性p0;
s4.经过训练后,使得p0=1,(x0,y0)坐标、尺度s0和旋转度θ0等于0;
s5.使用文本行定位模块确定图片中文本行开始位置之后,文本行检测网络沿着文本行的路径增量逐步前进,确定出完成的文本行区域。
所述变形的vgg-11网络删除了经典的vgg-11网络中的全连接层以及最后一个池化层,其所有卷积层都是同样大小的卷积核,尺寸为3*3,步长stride为1,填充padding为1。
所述步骤s4中,训练过程使用针对多框目标检测问题提出的损失函数,在最大概率预测的文本行开始位置和目标位置之间对齐,其损失函数如下所示:
其中,tm是目标位置,pn是sol出现的可能性,xnm是n个预测位置和m个目标位置之间的一个双向对齐矩阵,α是衡量位置loss和置信度loss之间相对重要性的参数,默认取0.01,ln是对卷积神经网络的初始预测结果(xn,yn,sn,θn)的代数变换,给定(l,p,t)计算使得l最小的xnm,ln的计算公式如下:
ln=(-sin(θn)sn+xn,-cos(θn)sn+yn,sin(θn)sn+xn,cos(θn)sn+yn)
所述文本行检测网络的处理方法,包括以下几个步骤:
s1.读取图像标签json文件,遍历json文件,剔除标注错误的部分;
s2.文本行检测网络递归增量运行,通过文本行定位网络得到的文本行开始位置和旋转角度(xi,yi,θi),重新采样获得一个查看窗口;
s3.输入到cnn网络回归得到下一个位置的(xi+1,yi+1,θi+1);
s4.重复上述步骤直到达到图片边缘,查看窗口的尺寸由文本行定位模块预测的尺度s0确定,且保持不变。
所述步骤s2中,重采样查看窗口的过程类似于空间变换网络,使用放射变换矩阵将图像坐标映射到查看图像坐标;
第一个查看窗口矩阵是w0=awsol,其中矩阵a是一个前向传播矩阵,负责为文本行检测网络提供上下文信息来使其正确定位文本行;
所述矩阵a与矩阵wsol的计算公式如下:
其中的参数是由文本行定位网络预测得到的;
根据wi矩阵提取一个32*32的查看窗口,然后文本行发现网络回归得到xi,yi以及θi,利用回归得到的xi,yi,θi以及预测矩阵pi计算下一个矩阵wi=piwi-1;
所述预测矩阵pi的计算公式如下:
为了定位文本行,把文本行视为一系列上下坐标点对pu,i和pl,i,坐标对通过预测窗口的上下中点来计算;
在卷积神经网络的训练过程中使用均方误差(meansquareerror)损失函数,计算公式如下:
文本检测网络在第一个目标位置处开始,即tu,0和tl,0,每4步重置相应的位置点,其目的是当文本行检测网络偏离手写文本行时,可以恢复正确的路径,而不会在训练过程中引入大量错误;
为了增强文本行检测网络的鲁棒性,在重置目标位置后,对目标位置随机施加δx,δy∈[-2,2]像素的平移变换以及δθ∈[-0.1,0.1]弧度的旋转变换。
所述文本行检测网络输出归一化的文本行图片,输入到文本行识别网络;文本行识别网络使用传统卷积神经网络以及双向循环神经网络,在框架的顶层使用ctc进行loss计算,对输入的不定长文本行图片进行识别,输出文本行识别结果。
以上所述的实施例,只是本发明具体实施方式的一种,本领域的技术人员在本发明技术方案范围内进行的通常变化和替换都应包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!