一种基于文本分析的未知漏洞风险评估方法与流程
本发明涉及一种基于文本分析的未知漏洞风险评估方法,属于网络未知漏洞风险评估技术领域。
背景技术:
近年来,信息系统安全漏洞数量呈指数级增长,相对应的安全漏洞威胁评估系统可根据漏洞自身属性和威胁严重等级差异做出排序,从而优先处理破坏性较强的安全漏洞,把漏洞威胁可造成能的风险损失降到最低。
国内外安全专家学者从定性、定量以及定性与定量相结合的角度对系统安全漏洞风险评估方法都进行了探索研究。然而,目前还少有研究工作涉及到使用文本分析来评估漏洞的风险等级。
技术实现要素:
为了解决上述技术问题,本发明提供一种基于文本分析的未知漏洞风险评估方法,其具体技术方案如下:
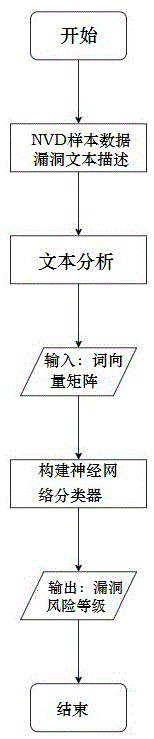
一种基于文本分析的未知漏洞风险评估方法,包括以下步骤:
步骤1:以美国国家漏洞数据库nationalvulnerabilitydatabase,nvd作为样本数据源,获取已有的漏洞文本描述;
步骤2:对样本漏洞文本描述进行文本分析,提取向量矩阵,具体为,
2.1,利用自然语言处理工具jieba对文本进行分词;
2.2,去除标点符号及停用词;
2.3,采用自然语言处理工具提取词干部分,去除无效的部分;
2.4,采用词频-逆向文件频率tf-idf(termfrequency-inversedocumentfrequency)方法建立关键词向量矩阵,具体为,
2.4.1,计算词频tf:
其中
2.4.2,计算逆向文件频率idf:
其中,
2.4.3:计算tf-idf:
2.4.4,将漏洞文本j的所有分词按照tf-idf值降序排列,提取排序靠前的分词作为漏洞文本j的类别关键词,其对应的tf-idf值构建词向量矩阵。;
步骤3:利用提取的向量矩阵及对应的cvss评分,建立分类模型;
步骤4:对任意一个未经评分的漏洞进行风险评估时,先进行步骤2,得到对应向量矩阵,然后将对应的向量矩阵输入到步骤3得到的分类模型中,得到漏洞风险等级。
进一步的,所述步骤3具体为:
3.1:构建text-cnn模型,使用步骤2.4中建立的词向量矩阵作为输入;
3.2:根据国际标准,将cvss评分划分为低危漏洞(0-3.9)、中危漏洞(4-6.9)、高危漏洞(7-10),标记对应的漏洞样本文本描述的危险等级,得到已标注样本集;
3.3:利用text-cnn模型对已标记样本集中的标记数据样本进行训练与学习,得到最终的分类模型,用以实现对未知漏洞风险的自动评估。
进一步的,所述步骤3.1中的text-cnn模型,包括输入层,卷积层,池化层和全连接层,具体为:
3.1.1:输入层:text-cnn的输入层是一个数字矩阵,即每个样本是一个矩阵,每行对应样本的一个分词,即词汇,每列表示一种不同的上下文或不同的漏洞文本,矩阵中的每个元素对应相关词和上下文的共现信息,通过神经网络的训练迭代更新分析样本数据集的长度来指定一个固定长度序列n,比n的短的样本序列需要填充(如以“0”填充),长度比n长的序列则需要截取至与n长度相同,通常是将多出的部分后面截掉,保留前面与序列n长度相同的部分,最终输入层输入的是文本序列中各词汇对应的分布式表示,得到一个的权重矩阵,其中n为此文本输入序列最大长度,k为词向量的维度;
3.1.2:卷积层:卷积层设计成三个不同大小的卷积核,卷积后生成特征图feature-map,然后进行边界填充padding,填充方式可采用same填充或valid填充形式;
3.1.3:池化层:在卷积层过程中由于使用了不同高度的卷积核,使得通过卷积层后得到的向量维度会不一致,所以在池化层中使用最大池化层方法(1-max-pooling)对每个特征向量池化成一个值,即抽取每个特征向量的最大值表示该特征,将这个最大值作为最重要的特征,对所有特征向量进行1-max-pooling之后,还需要将每个值拼接起来,得到池化层最终的特征,将步骤3.1.2中得到的结果,进行池化层,来缩小特征图,即从卷积层的feature-map中提取最大的值,并合并维度,最终提取出来,称为一个一维向量;
3.1.4:全连接层:用于对步骤3.1.1、3.1.2和3.1.3的特征做加权和,池化之后的一维向量通过全连接的方式接入一个softmax层进行分类,softmax公式为
在全连接层进行部分dropout,即在训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃,此处设置dropout=0.5,减少过拟合,最终输出的结果即是需要的准确分类,及对应的漏洞风险等级。
本发明的有益效果是:
对于不存在于已有漏洞库中的漏洞,可以根据其漏洞文本描述,自动化评估出其风险等级,不再局限于漏洞库数据。
这种自动化的风险等级评估,有助于计算机用户根据漏洞描述来确定漏洞的严重性,为用户的处理排序提供依据。
此外,传统评分系统利用数学公式对漏洞的风险严重程度进行评分,而该方法相对传统方法而言,有着较高的自动化程度和简便性,并且准确性也较高,使其成为传统评分系统的一个有效替代方案。
附图说明
图1是本发明的流程框图。
具体实施方式
现在结合附图对本发明作进一步详细的说明。
如图1所示,本发明一种基于文本分析的未知漏洞风险评估方法,包括以下步骤:
步骤1:以美国国家漏洞数据库nationalvulnerabilitydatabase,nvd作为样本数据源,获取已有的漏洞文本描述;
步骤2:对样本漏洞文本描述进行文本分析,提取向量矩阵,具体为:
2.1:利用自然语言处理工具jieba对文本进行分词;
2.2:去除标点符号及停用词;
2.3:采用自然语言处理工具提取词干部分,去除无效的部分;
2.4:采用词频-逆向文件频率tf-idf(termfrequency-inversedocumentfrequency)方法建立关键词向量矩阵,具体为:
2.4.1:计算词频tf:
其中
2.4.2:计算逆向文件频率idf:
其中,
2.4.3:计算tf-idf:
2.4.4:将漏洞文本j的所有分词按照tf-idf值降序排列,提取排序靠前的分词作为漏洞文本j的类别关键词,其对应的tf-idf值构建词向量矩阵。
步骤3:利用提取的向量矩阵及对应的cvss评分,建立分类模型,具体为:
3.1:构建text-cnn模型,使用步骤2.4中建立的词向量矩阵作为输入,text-cnn模型包括输入层,卷积层,池化层和全连接层,具体为:
3.1.1:输入层:text-cnn的输入层是一个数字矩阵,即每个样本是一个矩阵,每行对应该文档的一个分词,即词汇,每列表示一种不同的上下文或不同的漏洞文本,矩阵中的每个元素对应相关词和上下文的共现信息,通过神经网络的训练迭代更新分析样本数据集的长度来指定一个固定长度序列n,比n的短的样本序列需要填充(如以“0”填充),长度比n长的序列则需要截取至与n长度相同,通常是将多出的部分后面截掉,保留前面与序列n长度相同的部分,最终输入层输入的是文本序列中各词汇对应的分布式表示,得到一个的权重矩阵,其中n为此文本输入序列最大长度,k为词向量的维度;;
3.1.2:卷积层:卷积层设计成三个不同大小的卷积核,卷积后生成特征图feature-map,然后进行边界填充padding,填充方式可采用same填充或valid填充形式;
3.1.3:池化层:在卷积层过程中由于使用了不同高度的卷积核,使得通过卷积层后得到的向量维度会不一致,所以在池化层中使用最大池化层方法(1-max-pooling)对每个特征向量池化成一个值,即抽取每个特征向量的最大值表示该特征,将这个最大值作为最重要的特征,对所有特征向量进行1-max-pooling之后,还需要将每个值拼接起来,得到池化层最终的特征,将步骤3.1.2中得到的结果,进行池化层,来缩小特征图,即从卷积层的feature-map中提取最大的值,并合并维度,最终提取出来,称为一个一维向量;
3.1.4:全连接层:用于对步骤3.1.1、3.1.2和3.1.3的特征做加权和,池化之后的一维向量通过全连接的方式接入一个softmax层进行分类,softmax公式为
3.2:根据国际标准,将cvss评分划分为低危漏洞(0-3.9)、中危漏洞(4-6.9)、高危漏洞(7-10),标记对应的漏洞样本文本描述的危险等级,得到已标注样本集;
3.3:利用text-cnn模型对已标记样本集中的标记数据样本进行训练与学习,得到最终的分类模型,用以实现对未知漏洞风险的自动评估。
步骤4:对任意一个未经评分的漏洞进行风险评估时,先进行步骤2,得到对应向量矩阵,然后将对应的向量矩阵输入到步骤3得到的分类模型中,得到漏洞风险等级。
以上述依据本发明的理想实施例为启示,通过上述的说明内容,相关工作人员完全可以在不偏离本项发明技术思想的范围内,进行多样的变更以及修改。本项发明的技术性范围并不局限于说明书上的内容,必须要根据权利要求范围来确定其技术性范围。
- 还没有人留言评论。精彩留言会获得点赞!