一种基于python脚本的分布式大数据清洗方法与流程
本发明涉及数据清洗领域,具体涉及一种基于python脚本的分布式大数据清洗方法。
背景技术:
数据清洗是指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等,与问卷审核不同,录入后的数据清理一般是由计算机而不是人工完成。
现有的分布式大数据清洗方法,清洗能力较为有限,不能够针对大量的数据进行清洗,且现有的清洗方法基本都是采用sql清洗规则,清洗规则较少,导致清洗效果较为一般,此外传统的清洗数据的方法清洗算力不足,因此,如何将打造一种基于python脚本的分布式大数据清洗方法成为一个亟待解决的问题。
技术实现要素:
本发明所要解决的技术问题在于:现有的分布式大数据清洗方法,清洗能力较为有限,不能够针对大量的数据进行清洗,且现有的清洗方法基本都是采用sql清洗规则,清洗规则较少,导致清洗效果较为一般,此外传统的清洗数据的方法清洗算力不足。
本发明是通过以下技术方案解决上述技术问题的,一种基于python脚本的分布式大数据清洗方法,该方法包括如下步骤:
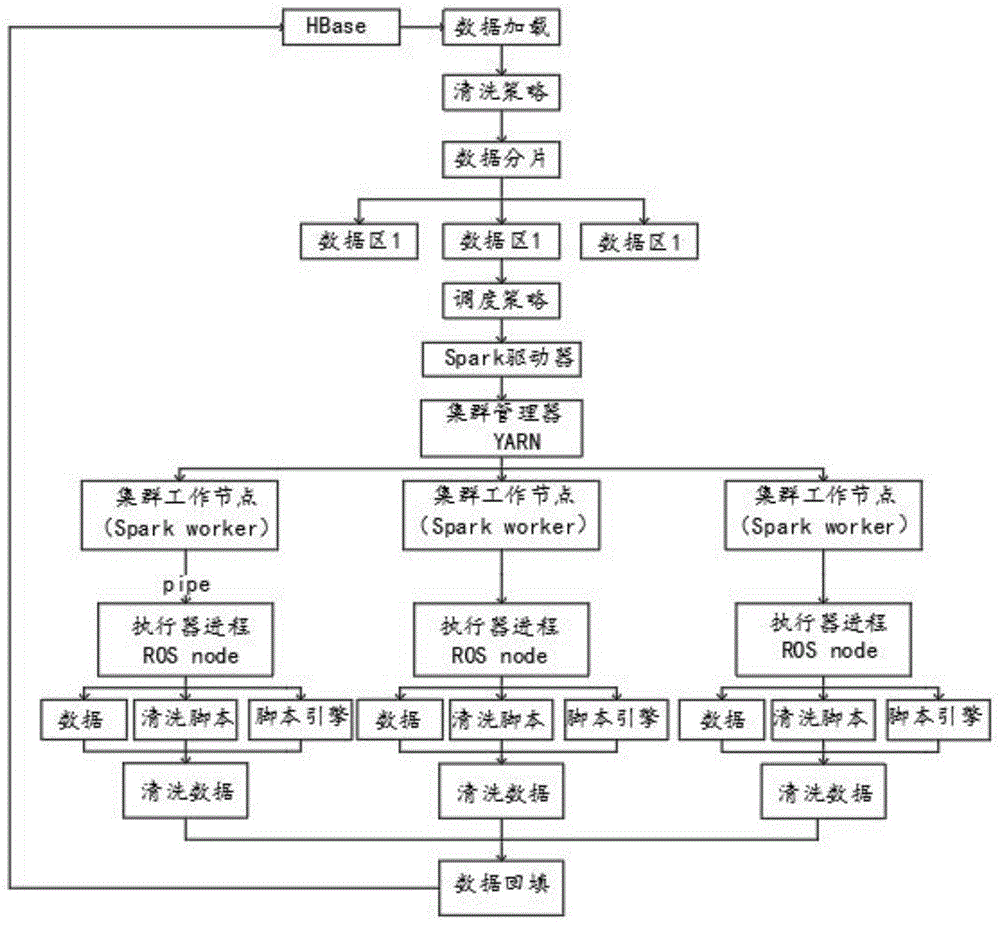
步骤一:首先对待清洗的数据的加载,再对加载后的待清洗的数据进行分片操作;
步骤二:对待清洗的数据进行分布式调度以及执行操作;
步骤三:对待清洗的数据进行请求以及对清洗结果进行回填;
其中,步骤一具体分为如下步骤:
s1:数据加载,首先从hbase列存数据库加载所需要进行清洗的数据;
s2:制定清洗策略,设置数据清洗策略;
s3:根据s2制定的清洗策略,对所有待清洗的数据进行分片,并记录各个分片的信息;
步骤二具体分为如下步骤:
a1:调度策略,根据步骤一s2中制定的清洗策略,实现清洗任务的调度策略;
a2:加载脚本,根据步骤一s2中制定的清洗策略,加载python清洗脚本;
a3:根据a1中的调度策略,生成调度任务,将调度任务绑定python脚本引擎,并绑定清洗脚本;
步骤三具体分为如下步骤:
y1:执行任务,根据步骤二a1中的调度策略,执行待清洗数据分布式调度任务;
y2:数据清洗,步骤a1中每个调度任务工作节点的执行器,通过绑定的python脚本引擎执行数据清洗脚本;
y3:结果回填,将所清洗的数据的清洗结果,回填到hbase列存数据库的数据清洗目标表。
优选的,s2中数据清洗策略包括清洗规则、清洗方法和对数据计算划分,将待清洗数据划分为n个任务,数据分片数量设为n,数据记录值设为c,每个数据切面为数据记录c除以数据分片k,k=c/n。
优选的,在步骤a1中安装数据分片k,生成对应的k个计算任务,分布式计算引擎会分派计算任务到集群工作节点(sparkworker),将节点数设为l,则每个节点分配t=k/l个调度任务。
优选的,步骤a3绑定清洗脚本后生成根据每个调度任务生成对应的算子,算子加载到加载到执行器进程(rosnode)。
优选的,hbase列存数据库包括内置分区单元,其中,内置分区单元将hbase列存数据库分为区间c和区间d,步骤y3所清洗的数据的清洗结果会回填到区间c中,未清洗的数据均储存在区间d中。
优选的,步骤a1中调度策略制定后,由spark驱动器进行调度策略的驱动,由集群集群管理器yarn对所有的集群工作节点进行统一管理。
本发明相比现有技术具有以下优点:本发明基于大数据技术门,采用hbase列存数据库作为清洗数据的数据储存,进而可以解决海量数据清洗的问题,采用python脚本引擎对清洗数据进行清理,解决了传统的采用sql数据库清洗时,清洗规则较少,以及jar包清洗静态编码的问题,通过制定清洗策略对清洗规则、清洗方法和对数据计算划分进行限定,实现了多规则清洗数据的效果,提高数据清洗结果的准确性,通过采用集群管理器对集群工作节点进行分布式管理,采用spark分布式计算引擎,从而可以对待清洗的数据进行分区清洗,解决了传统的撒数据清洗方法清洗能力不足的问题。
附图说明
图1是本发明的流程图。
具体实施方式
下面对本发明的实施例作详细说明,本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
如图1所示,本实施例提供一种技术方案:一种基于python脚本的分布式大数据清洗方法,该方法包括如下步骤:
步骤一:首先对待清洗的数据的加载,再对加载后的待清洗的数据进行分片操作;
步骤二:对待清洗的数据进行分布式调度以及执行操作;
步骤三:对待清洗的数据进行请求以及对清洗结果进行回填;
其中,步骤一具体分为如下步骤:
s1:数据加载,首先从hbase列存数据库加载所需要进行清洗的数据;
s2:制定清洗策略,设置数据清洗策略;
s3:根据s2制定的清洗策略,对所有待清洗的数据进行分片,并记录各个分片的信息;
步骤二具体分为如下步骤:
a1:调度策略,根据步骤一s2中制定的清洗策略,实现清洗任务的调度策略;
a2:加载脚本,根据步骤一s2中制定的清洗策略,加载python清洗脚本;
a3:根据a1中的调度策略,生成调度任务,将调度任务绑定python脚本引擎,并绑定清洗脚本;
步骤三具体分为如下步骤:
y1:执行任务,根据步骤二a1中的调度策略,执行待清洗数据分布式调度任务;
y2:数据清洗,步骤a1中每个调度任务工作节点的执行器,通过绑定的python脚本引擎执行数据清洗脚本;
y3:结果回填,将所清洗的数据的清洗结果,回填到hbase列存数据库的数据清洗目标表。
s2中数据清洗策略包括清洗规则、清洗方法和对数据计算划分,将待清洗数据划分为n个任务,数据分片数量设为n,数据记录值设为c,每个数据切面为数据记录c除以数据分片k,k=c/n。
在步骤a1中安装数据分片k,生成对应的k个计算任务,分布式计算引擎会分派计算任务到集群工作节点(sparkworker),将节点数设为l,则每个节点分配t=k/l个调度任务。
步骤a3绑定清洗脚本后生成根据每个调度任务生成对应的算子,算子加载到加载到执行器进程(rosnode)。
hbase列存数据库包括内置分区单元,其中,内置分区单元将hbase列存数据库分为区间c和区间d,步骤y3所清洗的数据的清洗结果会回填到区间c中,未清洗的数据均储存在区间d中。
步骤a1中调度策略制定后,由spark驱动器进行调度策略的驱动,由集群集群管理器yarn对所有的集群工作节点进行统一管理。
本发明在使用时,具体包括如下步骤:
步骤一:首先对待清洗的数据的加载,再对加载后的待清洗的数据进行分片操作;
s1:数据加载,首先从hbase列存数据库加载所需要进行清洗的数据;
s2:制定清洗策略,设置数据清洗策略;
s3:根据s2制定的清洗策略,对所有待清洗的数据进行分片,并记录各个分片的信息;
步骤二:对待清洗的数据进行分布式调度以及执行操作;
a1:调度策略,根据步骤一s2中制定的清洗策略,实现清洗任务的调度策略;
a2:加载脚本,根据步骤一s2中制定的清洗策略,加载python清洗脚本;
a3:根据a1中的调度策略,生成调度任务,将调度任务绑定python脚本引擎,并绑定清洗脚本;
步骤三:对待清洗的数据进行请求以及对清洗结果进行回填;
y1:执行任务,根据步骤二a1中的调度策略,执行待清洗数据分布式调度任务;
y2:数据清洗,步骤a1中每个调度任务工作节点的执行器,通过绑定的python脚本引擎执行数据清洗脚本;
y3:结果回填,将所清洗的数据的清洗结果,回填到hbase列存数据库的数据清洗目标表,清洗完成。
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本发明的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!