一种基于改进粒子群的气体浓度的预测方法及装置与流程
本申请涉及电力技术领域,特别涉及一种基于改进粒子群的气体浓度的预测方法及装置。
背景技术:
变压器是电力系统中最为核心的设备,变压器的工作状态决定着配电网的工作状态。因此监测变压器的工作状态,是运维人员的一项重要工作。
变压器工作过程中会有少量的气体溶解入变压器的绝缘油中,而绝缘油中溶解的气体浓度可以体现变压器的工作状态。运维人员根据目前绝缘油中溶解的气体浓度,可以预测未来一段时间内气体的浓度,进而监测变压器的工作状态。而目前方法中预测绝缘油中溶解气体浓度的方法中使用的预测模型,大多根据经验确定,导致预测模型的精确度偏低。
基于此,目前亟需一种基于改进粒子群的气体浓度的预测方法,用于解决现有技术中预测绝缘油中溶解的气体的浓度的过程中,使用的预测模型的精确度偏低的问题。
技术实现要素:
本申请提供了一种基于改进粒子群的气体浓度的预测方法及装置,可用于解决在现有技术中预测绝缘油中溶解的气体的浓度的过程中,使用的预测模型的精确度偏低的问题。
第一方面,本申请提供了一种基于改进粒子群的气体浓度的预测方法,所述方法包括:
获取待预测变压器的绝缘油中,任意一种待预测气体的多个历史时刻对应的历史浓度组;所述历史浓度组包括多个历史浓度;一个历史浓度对一个历史时刻;
对所述历史浓度组进行归一化处理,得到归一化后的历史浓度组;
将归一化后的历史浓度组输入气体预测模型中,得到预测气体浓度组;所述气体预测模型包括归一化后的历史浓度组与预测气体浓度组的对应关系;所述气体预测模型基于长短期记忆网络预测模型建立,并基于改进粒子群的方法优化;所述预测气体浓度组包括多个预测气体浓度。
结合第一方面,在第一方面的一种可实现方式中,所述气体预测模型采用以下方法训练:
获取样本变压器的绝缘油中,任意一种待预测气体的p个样本浓度构成的样本浓度组;所述p个样本浓度对应p个时刻;
对所述样本浓度组进行归一化处理,得到归一化后的样本浓度组;
将所述归一化后的样本浓度组划分为输入样本浓度组和输出样本浓度组;所述输入样本浓度组由n个归一化后的样本浓度构成;所述输出样本浓度组由m个归一化后的样本浓度构成;p=m+n,且n个归一化后的样本浓度中任意一个归一化后的样本浓度对应的时刻,早于m个归一化后的样本浓度中任意一个归一化后的样本浓度对应的时刻;
将所述输入样本浓度组作为输入,将所述输出样本浓度组作为输出,训练得到所述气体预测模型。
结合第一方面,在第一方面的一种可实现方式中,将所述输入样本浓度组作为输入,将所述输出样本浓度组作为输出,训练得到所述气体预测模型,包括:
随机初始化长短期记忆网络预测模型的神经元个数以及长短期记忆网络预测模型的学习率;
多次迭代更新神经元个数的速度、神经元个数的位置、学习率的速度以及学习率的位置,改变所述长短期记忆网络预测模型的神经元个数以及所述长短期记忆网络预测模型的学习率,得到多个训练好的长短期记忆网络预测模型;
将所述输入样本浓度组输入多个训练好的长短期记忆网络预测模型中,得到多个样本预测浓度组;
从多个样本预测浓度组中确定出与所述输出样本浓度组最接近的最佳样本预测浓度组;
将与所述最佳样本预测浓度组对应的训练好的长短期记忆网络预测模型,确定为所述气体预测模型。
结合第一方面,在第一方面的一种可实现方式中,所述归一化后的历史浓度组采用以下方法确定:
其中,x*为所述归一化后的历史浓度组中任意一个归一化后的历史浓度;x为所述历史浓度组中任意一个历史浓度;xmin为所述历史浓度组中的最小历史浓度;xmax为所述历史浓度组中的最大历史浓度。
结合第一方面,在第一方面的一种可实现方式中,待预测气体包括:
氢气、甲烷、乙烷、乙烯、乙炔、一氧化碳以及二氧化碳。
第二方面,本申请提供了一种基于改进粒子群的气体浓度的预测装置,所述装置包括:
获取模块,用于获取待预测变压器的绝缘油中,任意一种待预测气体的多个历史时刻对应的历史浓度组;所述历史浓度组包括多个历史浓度;一个历史浓度对一个历史时刻;
归一化模块,用于对所述历史浓度组进行归一化处理,得到归一化后的历史浓度组;
处理模块,用于将归一化后的历史浓度组输入气体预测模型中,得到预测气体浓度组;所述气体预测模型包括归一化后的历史浓度组与预测气体浓度组的对应关系;所述气体预测模型基于长短期记忆网络预测模型建立,并基于改进粒子群的方法优化;所述预测气体浓度组包括多个预测气体浓度。
结合第二方面,在第二方面的一种可实现方式中,所述气体预测模型采用以下方法训练:
获取样本变压器的绝缘油中,任意一种待预测气体的p个样本浓度构成的样本浓度组;所述p个样本浓度对应p个时刻;
对所述样本浓度组进行归一化处理,得到归一化后的样本浓度组;
将所述归一化后的样本浓度组划分为输入样本浓度组和输出样本浓度组;所述输入样本浓度组由n个归一化后的样本浓度构成;所述输出样本浓度组由m个归一化后的样本浓度构成;p=m+n,且n个归一化后的样本浓度中任意一个归一化后的样本浓度对应的时刻,早于m个归一化后的样本浓度中任意一个归一化后的样本浓度对应的时刻;
将所述输入样本浓度组作为输入,将所述输出样本浓度组作为输出,训练得到所述气体预测模型。
结合第二方面,在第二方面的一种可实现方式中,将所述输入样本浓度组作为输入,将所述输出样本浓度组作为输出,训练得到所述气体预测模型,包括:
随机初始化长短期记忆网络预测模型的神经元个数以及长短期记忆网络预测模型的学习率;
多次迭代更新神经元个数的速度、神经元个数的位置、学习率的速度以及学习率的位置,改变所述长短期记忆网络预测模型的神经元个数以及所述长短期记忆网络预测模型的学习率,得到多个训练好的长短期记忆网络预测模型;
将所述输入样本浓度组输入多个训练好的长短期记忆网络预测模型中,得到多个样本预测浓度组;
从多个样本预测浓度组中确定出与所述输出样本浓度组最接近的最佳样本预测浓度组;
将与所述最佳样本预测浓度组对应的训练好的长短期记忆网络预测模型,确定为所述气体预测模型。
结合第二方面,在第二方面的一种可实现方式中,所述归一化后的历史浓度组采用以下方法确定:
其中,x*为所述归一化后的历史浓度组中任意一个归一化后的历史浓度;x为所述历史浓度组中任意一个历史浓度;xmin为所述历史浓度组中的最小历史浓度;xmax为所述历史浓度组中的最大历史浓度。
结合第二方面,在第二方面的一种可实现方式中,待预测气体包括:
氢气、甲烷、乙烷、乙烯、乙炔、一氧化碳以及二氧化碳。
本申请通过改进粒子群的方法确定气体预测模型的参数,能够提升气体预测模型的精确度,进而得到变压器在下一阶段的准确状态,使得运维人员能够及时监测变压器的是否发生故障。
附图说明
图1为本申请实施例提供的一种基于改进粒子群的气体浓度的预测方法的流程示意图;
图2为本申请实施例提供的一种气体预测模型的确定方法的流程示意图;
图3为本申请实施例提供的一种基于改进粒子群的气体浓度的预测装置的结构示意图。
具体实施方式
为使本申请的目的、技术方案和优点更加清楚,下面将结合附图对本申请实施方式作进一步地详细描述。
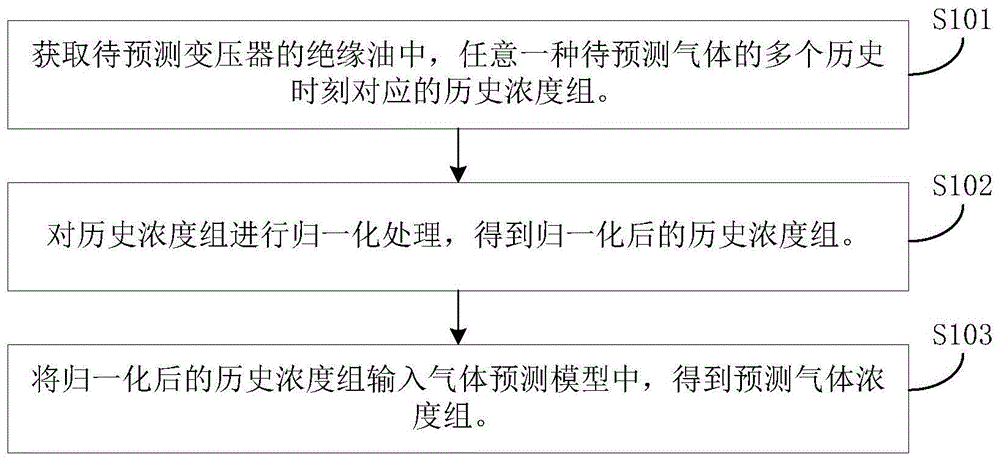
如图1所示,为本申请实施例提供的一种基于改进粒子群的气体浓度的预测方法的流程示意图。
步骤101,获取待预测变压器的绝缘油中,任意一种待预测气体的多个历史时刻对应的历史浓度组。
具体的,历史浓度组包括多个历史浓度;一个历史浓度对一个历史时刻
本申请实施例中,待预测气体包括氢气、甲烷、乙烷、乙烯、乙炔、一氧化碳以及二氧化碳。本申请实施例中,对任意一种气体浓度的预测方法都相同。
步骤102,对历史浓度组进行归一化处理,得到归一化后的历史浓度组。
与历史浓度组相对应,归一化后的历史浓度组由多个归一化后的历史浓度构成。
具体的,归一化后的历史浓度组采用以下方法确定:
公式(1)中,x*为归一化后的历史浓度组中任意一个归一化后的历史浓度;x为历史浓度组中任意一个历史浓度;xmin为历史浓度组中的最小历史浓度;xmax为历史浓度组中的最大历史浓度。
步骤103,将归一化后的历史浓度组输入气体预测模型中,得到预测气体浓度组。
具体的,气体预测模型包括归一化后的历史浓度组与预测气体浓度组的对应关系。预测气体浓度组包括多个预测气体浓度。
本申请实施例中,气体预测模型基于长短期记忆网络预测模型建立,并基于改进粒子群的方法优化。
如图2所示,为本申请实施例提供的一种气体预测模型的确定方法的流程示意图。如图2所示,本申请实施例主要包括以下步骤:
步骤201,获取样本变压器的绝缘油中,任意一种待预测气体的p个样本浓度构成的样本浓度组。
其中,p个样本浓度对应p个时刻。
步骤202,对样本浓度组进行归一化处理,得到归一化后的样本浓度组。
步骤203,将归一化后的样本浓度组划分为输入样本浓度组和输出样本浓度组。
其中,输入样本浓度组由n个归一化后的样本浓度构成;输出样本浓度组由m个归一化后的样本浓度构成;p=m+n,且n个归一化后的样本浓度中任意一个归一化后的样本浓度对应的时刻,早于m个归一化后的样本浓度中任意一个归一化后的样本浓度对应的时刻。
步骤204,将输入样本浓度组作为输入,将输出样本浓度组作为输出,训练得到气体预测模型。
具体的,本申请实施例中,训练得到气体预测模型的具体如下:
首先,随机初始化长短期记忆网络预测模型的神经元个数以及长短期记忆网络预测模型的学习率。
然后,多次迭代更新神经元个数的速度、神经元个数的位置、学习率的速度以及学习率的位置,改变长短期记忆网络预测模型的神经元个数以及长短期记忆网络预测模型的学习率,得到多个训练好的长短期记忆网络预测模型。
具体的,本申请实施例中,将长短期记忆网络预测模型中的重要参数神经元以及学习率作为改进粒子群算法中的粒子。本申请实施例中,还需要设置的参数包括神经元个数的取值范围、神经元个数的搜索范围、学习的取值范围、学习率的搜索范围、最大迭代更新次数、种群数量、惯性权重最大值、惯性权重最小值、第一加速因子的初始值、第一加速因子的最终值、第二加速因子的初始值以及第二加速因子的最终值。
改进粒子群优化算法以局部和整体的角度来搜索粒子的运动状态。粒子的坐标变化取决于每次迭代时的搜索速度,而搜索速度又依赖于惯性权重、加速因子等参数。
每个例子的位置、速度、惯性权重和加速因子的计算公式如下所示:
公式(2)中,
公式(3)中,
ωk=ωmax-(ωmax-ωmin)(k/tmax)^2(4)
公式(4)中,k表示当前迭代次数;tmax表示最大迭代数;ωmax表示迭代惯性权重最大值;ωmin表示迭代惯性权重最小值;ωk表示第k次迭代时的惯性权重。
公式(5)中,c1,ini第一加速因子的初始值;c1,fin表示第一加速因子的最终值;k表示当前迭代次数;tmax表示最大迭代数;
公式(6)中,c2,ini第二加速因子的初始值;c2,fin表示第二加速因子的最终值;k表示当前迭代次数;tmax表示最大迭代数;
再然后,将n个归一化后的样本浓度组输入多个训练好的长短期记忆网络预测模型中,得到多个样本预测浓度组。
再然后,将输入样本浓度组输入多个训练好的长短期记忆网络预测模型中,得到多个样本预测浓度组。
再然后,从多个样本预测浓度组中确定出与输出样本浓度组最接近的最佳样本预测浓度组。
本申请实施例中,通过比较预测浓度组与输出样本浓度组的平均百分误差、预测浓度组与输出样本浓度组的根均方误差、预测浓度组与输出样本浓度组的预测精度以及预测浓度组与输出样本浓度组的决定系数,确定出最佳样本预测浓度组。
最后,将与最佳样本预测浓度组对应的训练好的长短期记忆网络预测模型,确定为气体预测模型。
本申请通过改进粒子群的方法确定气体预测模型的参数,能够提升气体预测模型的精确度,进而得到变压器在下一阶段的准确状态,使得运维人员能够及时监测变压器的是否发生故障。
下述为本申请装置实施例,可以用于执行本申请方法实施例。对于本申请装置实施例中未披露的细节,请参照本申请方法实施例。
图3示例性示出了本申请实施例提供的一种基于改进粒子群的气体浓度的预测装置的结构示意图。如图3所示,该装置具有实现上述基于改进粒子群的气体浓度的预测方法的功能,所述功能可以由硬件实现,也可以由硬件执行相应的软件实现。该装置可以包括:获取模块301、归一化模块302以及处理模块303。
获取模块301,用于获取待预测变压器的绝缘油中,任意一种待预测气体的多个历史时刻对应的历史浓度组。历史浓度组包括多个历史浓度。一个历史浓度对一个历史时刻。
归一化模块302,用于对历史浓度组进行归一化处理,得到归一化后的历史浓度组。
处理模块303,用于将归一化后的历史浓度组输入气体预测模型中,得到预测气体浓度组。气体预测模型包括归一化后的历史浓度组与预测气体浓度组的对应关系。气体预测模型基于长短期记忆网络预测模型建立,并基于改进粒子群的方法优化。预测气体浓度组包括多个预测气体浓度。
可行的,气体预测模型采用以下方法训练:
获取样本变压器的绝缘油中,任意一种待预测气体的p个样本浓度构成的样本浓度组。p个样本浓度对应p个时刻。
对样本浓度组进行归一化处理,得到归一化后的样本浓度组。
将归一化后的样本浓度组划分为输入样本浓度组和输出样本浓度组。输入样本浓度组由n个归一化后的样本浓度构成。输出样本浓度组由m个归一化后的样本浓度构成。p=m+n,且n个归一化后的样本浓度中任意一个归一化后的样本浓度对应的时刻,早于m个归一化后的样本浓度中任意一个归一化后的样本浓度对应的时刻。
将输入样本浓度组作为输入,将输出样本浓度组作为输出,训练得到气体预测模型。
可行的,将输入样本浓度组作为输入,将输出样本浓度组作为输出,训练得到气体预测模型,包括:
随机初始化长短期记忆网络预测模型的神经元个数以及长短期记忆网络预测模型的学习率。
多次迭代更新神经元个数的速度、神经元个数的位置、学习率的速度以及学习率的位置,改变长短期记忆网络预测模型的神经元个数以及长短期记忆网络预测模型的学习率,得到多个训练好的长短期记忆网络预测模型。
将输入样本浓度组输入多个训练好的长短期记忆网络预测模型中,得到多个样本预测浓度组。
从多个样本预测浓度组中确定出与输出样本浓度组最接近的最佳样本预测浓度组。
将与最佳样本预测浓度组对应的训练好的长短期记忆网络预测模型,确定为气体预测模型。
可行的,归一化后的历史浓度组采用以下方法确定:
其中,x*为归一化后的历史浓度组中任意一个归一化后的历史浓度;x为历史浓度组中任意一个历史浓度;xmin为历史浓度组中的最小历史浓度;xmax为历史浓度组中的最大历史浓度。
可行的,待预测气体包括:
氢气、甲烷、乙烷、乙烯、乙炔、一氧化碳以及二氧化碳。
本申请通过改进粒子群的方法确定气体预测模型的参数,能够提升气体预测模型的精确度,进而得到变压器在下一阶段的准确状态,使得运维人员能够及时监测变压器的是否发生故障。
本发明可用于众多通用或专用的计算系统环境或配置中。例如:个人计算机、服务器计算机、手持设备或便携式设备、平板型设备、多处理器系统、基于微处理器的系统、置顶盒、可编程的消费电子设备、网络pc、小型计算机、大型计算机、包括以上任何系统或设备的分布式计算环境等等。
本发明可以在由计算机执行的计算机可执行指令的一般上下文中描述,例如程序模块。一般地,程序模块包括执行特定任务或实现特定抽象数据类型的例程、程序、对象、组件、数据结构等等。也可以在分布式计算环境中实践本发明,在这些分布式计算环境中,由通过通信网络而被连接的远程处理设备来执行任务。在分布式计算环境中,程序模块可以位于包括存储设备在内的本地和远程计算机存储介质中。
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本发明的其它实施方案。本发明旨在涵盖本发明的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本发明的一般性原理并包括本发明未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本发明的真正范围和精神由下面的权利要求指出。
应当理解的是,本发明并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本发明的范围仅由所附的权利要求来限制。
- 还没有人留言评论。精彩留言会获得点赞!