一种用于神经网络模型推理跨平台的部署方法及架构与流程
本发明涉及人工智能技术,特别涉及一种用于神经网络模型推理跨平台的部署方法及架构。
背景技术:
随着人工智能技术的发展,神经网络的应用也越来越广泛。为了支持神经网络的应用,各大厂商都在生产可以运行神经网络的芯片,特别是运行深度神经网络的芯片,诸如中央处理器(cpu,centralprocessingunit)、图形处理器(gpu,graphicsprocessingunit)、神经网络训练的处理器(tpu,tensorprocessingunit)、机器学习处理器(mlu,machinelearningunit)或arm处理器等。在这里,深度神经网络为有很多隐藏层的神经网络,又被称为深度前馈网络(dfn)或多层感知机(mlp)。
当一芯片支持的平台要运行神经网络时,则在所述平台上部署具有该神经网络模型推理,将数据输入到该神经网络模型推理中执行即可实现。神经网络模型推理仅针对一芯片支持的平台,对于异构芯片支持的平台,则由于所采用的处理器架构不同及所采用的神经网络模型的类型不同等原因,而导致了神经网络模型推理无法跨平台实现。即使是实现同一任务的神经网络模型推理,也有差异,无法跨平台实现,需要单独部署,使得神经网络在异构平台上的部署不方便,给神经网络的广泛应用带来障碍。
技术实现要素:
有鉴于此,本发明实施例提供了一种用于神经网络模型推理跨平台的部署方法,该方法能够跨异构平台部署神经网络模型推理。
本发明实施还提供一种用于神经网络模型推理跨平台的部署架构,该架构能够跨异构平台部署神经网络模型推理。
本发明实施例是这样实现的:
一种用于神经网络模型推理跨平台的部署方法,所述方法包括:
对数据进行统一处理;
基于所加载的神经网络模型,确定神经网络模型推理,将统一处理后的数据输入到所述神经网络模型推理中;
根据神经网络模型推理,调用神经网络模型推理中的适用于平台的至少一个算子后,执行;
输出得到神经网络模型推理的解析结果。
较佳地,所述对数据进行统一处理包括:
识别所述数据的数据类型;
为所述数据设置对应数据类型的数据类型标识。
较佳地,所述根据神经网络模型推理,调用神经网络模型推理中的适用于平台的对应算子包括:
识别神经网络模型推理中包括至少一个推理节点,每个推理节点具有一个待处理算子;
针对每一个待处理算子,访问设置的算子库,从所述算子库中提取待处理算子对应的,适用于平台的算子。
较佳地,所述识别神经网络模型推理中包括至少一个推理节点,每个推理节点具有一个待处理算子还包括:
识别神经网络模型推理中包括至少一个推理节点,每个推理节点具有的一个待处理算子,与所述神经网络模型推理中的其他推理节点所具有的待处理算子相同或不同;
针对每一个待处理算子,访问设置的算子库,从所述算子库中提取待处理算子对应的,适用于平台的算子还包括:
针对当前待处理算子,当与所述神经网络模型推理中的其他推理节点所具有的待处理算子相同时,从所述算子库中提取相同待处理算子对应的,适用于平台的算子。
较佳地,所述在访问设置的算子库,从所述算子库中提取待处理算子对应的,适用于平台的算子之前,还包括:
获取待处理算子对应的,适用于平台的算子中的平台通用子算子;
设置待处理算子对应的,适用于平台的算子中的平台适配子算子;
将所获取的平台通用子算子与平台适配子算子结合,形成待处理算子对应的,适用于平台的算子;
将待处理算子对应的,适用于平台的算子存储到设置的算子库中。
一种用于神经网络模型推理跨平台的部署架构,包括:数据接口模块、推理模块及输出解析模块,其中,
所述数据接口模块,用于对数据进行统一处理后,输入到所述推理模块确定的神经网络模型推理中;
所述推理模块,用于基于所加载的神经网络模型,确定神经网络模型推理;根据神经网络模型推理,调用神经网络模型推理中的适用于平台的至少一个算子后,执行;
所述输出解析模块,用于输出得到的神经网络模型推理的解析结果。
较佳地,所述数据接口模块中具有至少一个不同的数据类型子接口模块,用于识别所述数据的数据类型,为所述数据设置对应数据类型的数据类型标识。
较佳地,所述推理模块,包括公共接口及算子库,其中,
所述公共接口,用于识别神经网络模型推理中包括至少一个推理节点,每个推理节点具有一个待处理算子;针对每一个待处理算子,访问所述算子库,从所述算子库中提取待处理算子对应的,适用于平台的算子,执行;
所述算子库,用于存储至少一个适用于平台的算子,接受所述公共接口的访问后,将待处理算子对应的,适用于平台的算子,提供给所述公共接口。
较佳地,所述公共接口,还用于识别神经网络模型推理中包括至少一个推理节点,每个推理节点具有的一个待处理算子,与所述神经网络模型推理中的其他推理节点所具有的待处理算子相同或不同;
所述公开接口,还用于针对当前待处理算子,当与所述神经网络模型推理中的其他推理节点所具有的待处理算子相同时,从所述算子库中提取相同待处理算子对应的,适用于平台的算子。
所述算子库,还用于获取待处理算子对应的,适用于平台的算子中的平台通用子算子;设置待处理算子对应的,适用于平台的算子中的平台适配子算子;将所获取的平台通用子算子与平台适配子算子结合,形成待处理算子对应的,适用于平台的算子;将待处理算子对应的,适用于平台的算子进行存储。
如上所见,本发明实施例提供的部署方法中,首先对数据进行统一处理;然后基于所加载的神经网络模型,确定神经网络模型推理,将统一处理后的数据输入到所述神经网络模型推理中;再次,根据神经网络模型推理,调用神经网络模型推理中的适用于平台的至少一个算子后,执行;最后,输出得到神经网络模型推理的解析结果。因此,本发明实施例在平台部署神经网络模型推理时,对神经网络模型推理进行了算子碎片化处理,而并不是直接将完整的神经网络模型推理进行部署,由于针对不同平台的神经网络模型推理中的相同算子可以被灵活使用,甚至是复用,所以实现了跨异构平台部署神经网络模型推理。
附图说明
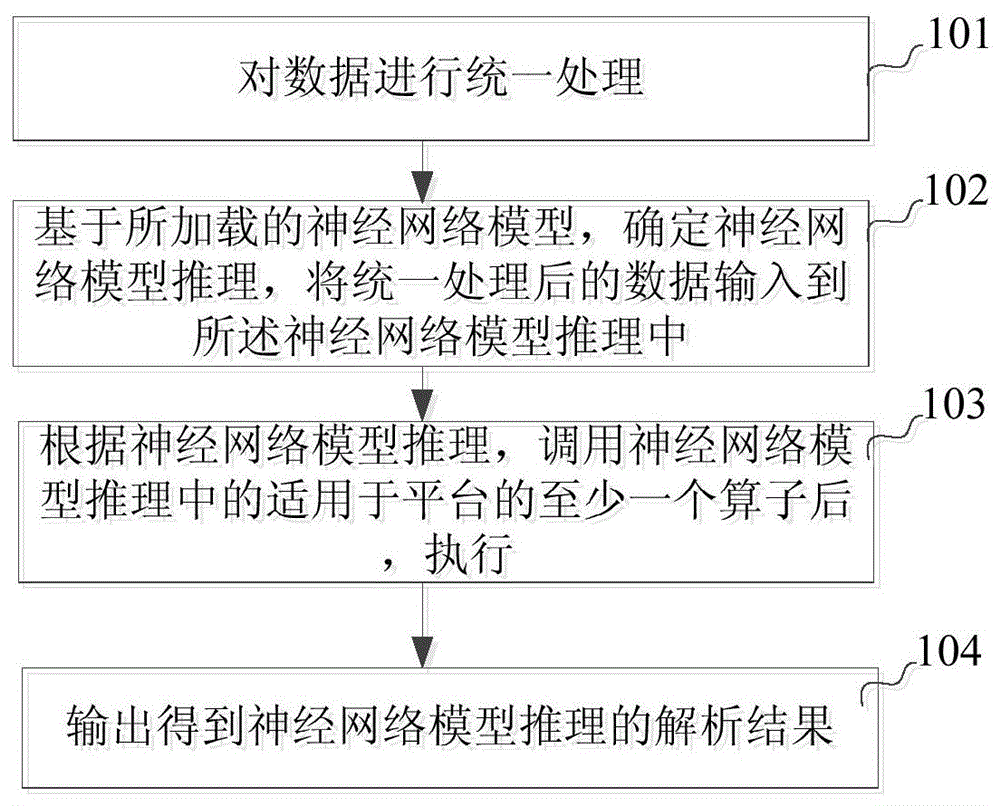
图1为本发明实施例提供的一种用于神经网络模型推理跨平台的部署方法流程图;
图2为本发明实施例提供的一种用于神经网络模型推理跨平台的部署架构示意图;
图3为本发明实施例提供的神经网络模型的跨平台封装方法流程图;
图4为本发明实施例提供的神经网络模型的跨平台封装过程示意图;
图5为本发明实施例提供的用于神经网络模型推理跨平台的部署方法的具体示意图;
图6为本发明实施例提供的用于神经网络模型推理跨平台的部署方法的具体例子过程示意图;
图7为本发明实施例提供的统计当前场景下带口罩的男女比例任务的实现流程图;
图8为本发明实施例提供的采用针对不同平台加载不同的神经网络模型推理实现任务的过程示意图;
图9为本发明实施例提供的部署到不同平台的具有跨平台功能的神经网络模型推理实现任务的过程示意图;
图10为现有技术提供的人体检测功能部分在一平台上采用神经网络模型推理的实现过程示意图;
图11为本发明实施例提供的人体检测功能部分在跨平台的神经网络模型推理的实现过程示意图;
图12为本发明实施例提供的算子库中的算子构成示意图;
图13为本发明实施例提供的神经网络模型推理的跨平台编译方法流程图;
图14为本发明实施例提供的跨平台编译及部署的过程流程图。
具体实施方式
为使本发明的目的、技术方案及优点更加清楚明白,以下参照附图并举实施例,对本发明进一步详细说明。
本发明实施例为了实现跨异构平台部署神经网络模型推理,采用了一种用于神经网络模型推理的部署方法:首先对数据进行统一处理;然后基于所加载的神经网络模型,确定神经网络模型推理,将统一处理后的数据输入到所述神经网络模型推理中;;再次,根据神经网络模型推理,调用神经网络模型推理中的适用于平台的至少一个算子后,执行;最后,输出得到神经网络模型推理的解析结果。
这样,本发明实施例在平台部署神经网络模型推理时,对神经网络模型推理进行了算子碎片化处理,而并不是直接将完整的神经网络模型推理进行部署,由于针对不同平台的神经网络模型推理中的相同算子可以被灵活使用,甚至是复用,所以节省了部署时间,且实现了神经网络模型推理跨平台的部署。
在本发明实施例中,将处理器架构不同的芯片支持的平台,简称为异构平台。更进一步地,一个平台还可以支持多个不同处理器架构,这里不限制。
在本发明实施例中,实现一任务的神经网络可以采用函数公式表示,比如表示为y=f(x),其中,函数f()就是神经网络模型,而f(x)的执行逻辑就是神经网络模型推理。对于异构平台,即使实现同一任务的神经网络,其得到的神经网络模型推理也是不同的。如果对于不同异构平台分别针对性部署不同的神经网络模型推理,则在部署上比较繁琐,且无法使得神经网络应用广泛。
因此,本发明实施例将要部署到异构平台上的神经网络模型推理进行算子碎片化,拆分为多个算子,这里的算子指的是神经网络模型中的每个神经推理节点的计算单元,比如在神经推理节点1进行卷积1计算的算子,在神经节点2进行卷积2计算的算子,在神经节点3进行池化计算的算子等等,当要执行神经网络模型推理时,则确定该神经网络模型推理所具有的多个待处理算子,从设置的算子库中调用这些待处理算子对应的,适用于平台的算子。
为了实现上述方案,本发明实施例提供的在异构平台上的神经网络模型推理的部署架构中,包括了公共接口及算子库,其中,公共接口具有该神经网络模型推理中的多个待处理算子,且可以调用算子库,获得这些待处理算子对应的,适用于平台的算子,而算子库中则具有可以应用于神经网络模型推理的,且适用于平台的算子,并接受公共接口的调用。
以下对本发明实施例进行详细说明。
图1为本发明实施例提供的一种用于神经网络模型推理跨平台的部署方法流程图,其具体步骤包括:
步骤101、对数据进行统一处理;
步骤102、基于所加载的神经网络模型,确定神经网络模型推理,将统一处理后的数据输入到所述神经网络模型推理中;
步骤103、根据神经网络模型推理,调用神经网络模型推理中的适用于平台的至少一个算子后,执行;
步骤104、输出得到神经网络模型推理的解析结果。
在该方法中,步骤101中的对数据进行统一处理过程,与步骤102中的确定神经网络模型推理的过程,在执行上的顺序可以同时进行,也可以先后进行,或者先执行确定神经网络模型过程,再执行数据统一处理过程,这里不限定。
在该方法中,由于针对不同平台,神经网络模型推理的部署架构是相同的,所以对于不同类型的数据,在输入到神经网络模型推理中进行执行时,需要进行统一处理,以使得神经网络模型推理能够识别该数据。具体地说,所述对数据进行统一处理包括:
识别所述数据的数据类型;
为所述数据设置对应数据类型的数据类型标识。
也就是说,需要识别到所述数据是适用于cpu处理、gpu处理、tpu处理、mlu处理或arm处理器处理,并在所述数据中增加对应的数据类型标识,以使得神经网络模型推理在执行时,根据数据类型标识确定要执行的数据。
在该方法中,对于不同平台,神经网络模型推理的实现是不同的,为了针对不同平台,使得神经网络模型推理的部署过程相同,所以将神经网络模型进行了算子碎片化。具体地说,所述根据神经网络模型推理,调用神经网络模型推理中的适用于平台的对应算子包括:识别神经网络模型推理中包括至少一个推理节点,每个推理节点具有一个待处理算子;针对每一个待处理算子,访问设置的算子库,从所述算子库中提取待处理算子对应的,适用于平台的算子。
在该方法中,所述识别神经网络模型推理中包括至少一个推理节点,每个推理节点具有一个待处理算子还包括:识别神经网络模型推理中包括至少一个推理节点,每个推理节点具有的一个待处理算子,与所述神经网络模型推理中的其他推理节点所具有的待处理算子相同或不同;针对每一个待处理算子,访问设置的算子库,从所述算子库中提取待处理算子对应的,适用于平台的算子还包括:针对当前待处理算子,当与所述神经网络模型推理中的其他推理节点所具有的待处理算子相同时,从所述算子库中提取相同待处理算子对应的,适用于平台的算子。也就是说,对于同一神经网络模型推理中,所调用的对应的,适用于平台的算子可以是重复的,比如,同一神经网络模型推理中,在不同推理节点中都要实现卷积的算子执行,在这种情况下,在算子库中,仅仅可以存储实现该卷积的一个算子,在调用时重复调用,节省了部署时间。
在该方法中,所述在访问设置的算子库,从所述算子库中提取待处理算子对应的,适用于平台的算子之前,还包括:获取待处理算子对应的,适用于平台的算子中的平台通用子算子;设置待处理算子对应的,适用于平台的算子中的平台适配子算子;
将所获取的平台通用子算子与平台适配子算子结合,形成待处理算子对应的,适用于平台的算子;将待处理算子对应的,适用于平台的算子存储到设置的算子库中。也就说,在设置算子时,所述算子中至少包括算子的平台通用子算子及算子的平台适配子算子,将两者结合形成了一个完整的算子。在这种情况下,对于不同平台的神经网络模型推理,其需要的至少一个算子中大部分是各个平台可以通用的,小部分是各个平台不通用的。所以在设置算子时,就可以直接获取算子的平台通用子算子,而对算子的平台适配子算子进行编写后,整合为一个完整的算子,节省了算子的设置时间。
图2为本发明实施例提供的一种用于神经网络模型推理跨平台的部署架构示意图,针对每个不同的平台,神经网络模型推理的部署架构都是相同的,具体包括:数据接口模块、推理模块及输出解析模块,其中,
所述数据接口模块,用于对数据进行统一处理后,输入到所述推理模块确定的神经网络模型推理中;
所述推理模块,用于基于所加载的神经网络模型,确定神经网络模型推理;根据神经网络模型推理,调用神经网络模型推理中的适用于平台的至少一个算子后,执行;
所述输出解析模块,用于输出得到的神经网络模型推理的解析结果。
在该部署架构中,所述数据接口模块中具有至少一个不同的数据类型子接口模块,用于识别所述数据的数据类型,为所述数据设置对应数据类型的数据类型标识。
在该部署架构中,所述推理模块,包括公共接口及算子库,其中,
所述公共接口,用于识别神经网络模型推理中包括至少一个推理节点,每个推理节点具有一个待处理算子;针对每一个待处理算子,访问所述算子库,从所述算子库中提取待处理算子对应的,适用于平台的算子,执行;
所述算子库,用于存储至少一个适用于平台的算子,接受所述公共接口的访问后,将待处理算子对应的,适用于平台的算子,提供给所述公共接口。
在该部署架构中,所述公共接口,还用于识别神经网络模型推理中包括至少一个推理节点,每个推理节点具有的一个待处理算子,与所述神经网络模型推理中的其他推理节点所具有的待处理算子相同或不同;
所述公开接口,还用于针对当前待处理算子,当与所述神经网络模型推理中的其他推理节点所具有的待处理算子相同时,从所述算子库中提取相同待处理算子对应的,适用于平台的算子。这样,所述神经网络模型推理中的推理节点具有的待处理算子中,有重复的待处理算子,可以节省部署时间。
在该部署架构中,所述算子库,还用于获取待处理算子对应的,适用于平台的算子中的平台通用子算子;设置待处理算子对应的,适用于平台的算子中的平台适配子算子;将所获取的平台通用子算子与平台适配子算子结合,形成待处理算子对应的,适用于平台的算子;将待处理算子对应的,适用于平台的算子进行存储。这样,所述算子中至少包括算子的平台通用子算子及算子的平台适配子算子,在设置算子时节省时间。
在本发明实施例中,在异构平台上部署神经网络模型推理时,需要获取神经网络模型,基于所获取的神经网络模型,确定所部署的神经网络模型推理。由于异构平台上所部署神经网络模型推理的架构相同,所以获取的神经网络模型的封装格式也需要统一。
图3为本发明实施例提供的神经网络模型的跨平台封装方法流程图,结合图4所示的神经网络模型的跨平台封装过程示意图进行说明,其具体步骤包括:
步骤301、将对应不同平台的神经网络模型转换为设定架构的前向模型;
在本步骤中,可以将采用pytorch生成的模型转换为caffe生成的caffemodel或onnx模型;
步骤302、通过设定的模型转化工具将前向模型转化为在任一平台运行的模型文件;
步骤303、将模型文件进行封装;
在本步骤中,封装主要是将模型文件加上设定的数据头,包装成统一格式。
步骤304、将封装后的模型文件进行加密后,封装为神经网络模型。
在图3所述的方法中,步骤301可以缺省,缺省的条件是步骤302中提供的转换工具可以直接将对应不同平台的神经网络模型,转换为在任一平台运行的模型文件。
为了方便调用封装后的神经网络模型,还设置模型封装接口(在图4中没有提及),,在本发明实施例的公共接口调用神经网络模型,形成神经网络模型推理时,可以通过设置的模型封装接口调用。在调用时,对神经网络模型进行解密,得到统一格式的神经网络模型文件。
在图3的步骤304中,对模型文件进行加密,保证了封装得到的神经网络模型的安全性,在后续调用时,进行解密调用即可。
神经网络模型推理在不同平台的部署本发明实施例的核心,其通过公共接口调用封装好的神经网络模型,在平台上确定神经网络模型推理所包括的待处理算子;通过公共接口得到统一处理后的数据,依次输入到神经网络模型推理中的待处理算子中执行,在执行每个待处理算子时,从平台底层设置的算子库调用适用于平台的对应算子执行。实现了数据在不同平台上实现神经网络模型推理过程时的无感。
在平台部署的神经网络模型推理接收数据执行之前,对数据进行统一处理。特别地,当数据是基于gpu架构的平台的数据时,还可以对数据进行预处理,具体设置图像处理单元,对数据进行图像处理加速后,再设置对应的数据类型标识。在这里,可以通过通用并行计算架构(cuda)加速算子对数据进行图像处理加速。
图5为本发明实施例提供的用于神经网络模型推理跨平台的部署方法的具体示意图,结合图6所示的本发明实施例提供的用于神经网络模型推理跨平台的部署方法的具体例子过程示意图,进行详细说明:
步骤501、通过公共接口调用封装好的神经网络模型,在平台上确定神经网络模型推理所包括的待处理算子;
步骤502、接收到输入数据后,对数据进行统一处理,为数据设置对应的数据类型标识,提供给公共接口;
在本步骤中,输入数据可以是来自不同处理器架构的平台,可以是图片或视频等,根据输入数据的类型进行统一处理,比如当输入数据是基于gpu架构的平台的数据,对数据进行图像处理加速后,为数据设置对应的数据类型标识后,提供给公共接口;
步骤503、通过公共接口得到统一处理后的数据,依次输入到神经网络模型推理中的待处理算子中执行,在执行每个待处理算子时,从平台底层设置的算子库调用适用于平台的对应算子执行;
步骤504、执行完成后,对神经网络模型推理的结果进行输出。
举一个具体例子说明本发明实施例。
设置采用神经网络实现一个任务,比如任务为统计当前场景下带口罩的男女比例的任务,该任务可以被拆分为三个功能部分实现:人体检测功能部分、性别分类功能部分及计数功能部分实现,其中,将任务中的人体检测功能部分及性别分类功能部分采用神经网络模型推理实现,将任务中的计数功能部分由平台的应用层的逻辑运算功能实现。
图7为本发明实施例提供的统计当前场景下带口罩的男女比例任务的实现流程图,如图所示:
第一步骤、平台接收到输入数据,该数据为图像数据,对该数据进行统一处理后,输入到神经网络模型推理中;
第二步骤、神经网络模型推理得到统一处理后的数据,依次输入到神经网络模型推理中的待处理算子中执行,在执行每个待处理算子时,从平台底层设置的算子库调用适用于平台的对应算子执行,得到推理信息,所述推理信息包括某一人员的性别及是否带口罩的两个属性;
在本步骤中,该平台可以部署两个神经网络模型推理,一个是针对人体检测功能部分、另一个是性别分类功能部分的;
第三步骤,平台的应用层接收到推理信息,对带口罩的男性及带口罩的女性的推理信息进行计数后,计算得到带口罩的男女比例,作为输出信息进行输出。
在图7所述的过程中,任务中的人体检测部分及性别分类部分是由平台的硬核实现,而逻辑运算则在平台的应用层实现。
为了实现上述任务,如果采用针对不同平台加载不同的神经网络模型推理,如图8所示,图8为本发明实施例提供的采用针对不同平台加载不同的神经网络模型推理实现任务的过程示意图,则将任务拆分为多个功能部分,在第一平台采用第一神经网络模型推理实现任务中的主要功能部分,在第一平台的应用层完成任务中的简单功能部分;在第二平台采用第二神经网络模型推理实现任务中的主要功能部分,在第二平台的应用层完成任务中的简单功能部分。在这里,虽然第一神经网络模型推理和第二神经网络模型推理实现的是同一任务的主要功能部分,但是第一神经网络模型推理和第二神经网络模型推理是不相同的,无法在两个平台间移植,需要分别被部署。而第一平台的应用层和第二平台的应用层完成任务中的简单功能部分可以被复用。
在这里,当任务为统计当前场景下带口罩的男女比例的任务时,任务中的主要功能部分包括:人体检测功能部分和性别分类功能部分;任务中的简单功能部分包括:计数功能部分。假设任务中的每个功能部分需要一周的开发时间设置在平台上,则将这个任务设置在第一平台上和第二平台上时需要五周的开发时间。
如果采用针对不同平台部署具有跨平台功能的神经网络模型推理实现任务时,如图9所示,图9为本发明实施例提供的部署到不同平台的具有跨平台功能的神经网络模型推理实现任务的过程示意图:在第一平台中部署具有跨平台功能的神经网络模型推理和在第二平台部署具有跨平台功能的神经网络模型推理,当第一平台执行任务时,将经过统一处理的数据提供给所部署的神经网络模型推理,由神经网络模型推理得到统一处理后的数据,依次输入到神经网络模型推理中的待处理算子中执行,在执行每个待处理算子时,通过公共接口从平台底层设置的算子库调用适用于平台的对应算子执行,实现任务中的主要功能部分后,在第一平台的应用层完成任务中的简单功能部分;在第二平台执行任务时,将经过统一处理后的数据提供给所部署的神经网络模型推理,由神经网络模型推理得到统一处理后的数据,依次输入到神经网络模型推理中的待处理算子中执行,在执行每个待处理算子时,通过公共接口从平台底层设置的算子库调用适用于平台的对应算子执行,实现任务中的主要功能部分后,在第二平台的应用层完成任务中的简单功能部分。在这里,第一平台上的神经网络模型推理和第二平台上的神经网络模型推理虽然不同,但是由于对神经网络模型推理在公共接口进行了算子碎片化,所以第一平台上的神经网络模型推理中的多个待处理算子,及第二平台上的神经网络模型推理中的多个待处理算子有可能有部分相同,因此可以被复用;对于第一平台上的神经网络模型推理中的多个待处理算子也可能相同,可以被复用;对于第二平台上的神经网络模型推理中的多个待处理算子也可能相同,可以被复用。第一平台的应用层和第二平台的应用层完成任务中的简单功能部分可以被复用。
采用图9所示的过程实现任务,当开发了第一平台上的神经网络模型推理后,就可以将第一平台上的神经网络模型推理中的,与第二平台上的神经网络模型推理中的相同待处理算子直接进行应用,所以这个任务实现设置在第一平台上和第二平台上时需要三周的开发时间,这相比于图8所述的过程减少了开发时间。
这里以两个异构平台举例说明开发时间的减少及开发工作量的减少,在实际生产过程中,可能会涉及到更多的平台,本发明实施例提供的方案在跨平台的实现上更具有明显的优势。更近一步地,当采用神经网络模型推理实现的任务比较复杂,具有超过两个功能部分时,工作量会更加减少及会更加节省开发时间。
图10为现有技术提供的人体检测功能部分在一平台上采用神经网络模型推理的实现过程示意图,图11为本发明实施例提供的人体检测功能部分在跨平台的神经网络模型推理的实现过程示意图。如图10所示,现有技术在一平台上实现人体检测功能部分时,是将神经网络模型推理的整体部署到平台时进行执行,所以在开发阶段及后续的部署阶段,都需要针对每个平台分别进行,繁琐且浪费时间。如图11所示,本发明实施例在一平台上实现人体检测功能部分时,是将神经网络模型推理以算子粒度进行拆分,提供公共接口及算子库的架构,其中,公共接口中部署神经网络模型推理中的待处理算子,算子库中部署神经网络模型推理要应用的适用于平台的算子,当执行时,基于各个待处理算子调用算子库中的对应的,适用于平台算子进行执行即可,这样,对于不同平台来说,其部署的神经网络模型中的部分算子可以被复用,简单实现且节省时间。
进一步地,对于算子库中的同一算子,其包括了算子的平台通用子算子及算子的平台适配子算子,对于不同平台,算子的平台通用子算子可以通用,在开发时可以跨平台移植,而对于算子的平台适配子算子则无法通用,在开发是时可以独立设置。如图所示,图12为本发明实施例提供的算子库中的算子构成示意图,其中,算子库在神经网络模型推理部署到某个平台上,可以针对平台分别部署,部署的算子不同;而对于所有平台的算子库来说,其在设置算子时,算子的平台通用子算子可以共用,而算子的平台适配子算子则进行设置,两者最终结合形成算子。算子库中的算子是通过公共接口进行调用的,其公共接口的调用逻辑是由神经网络模型推理中的各个推理节点所要执行的待处理算子确定的。
在本发明实施例中,当开发了跨平台的神经网络模型推理后,就进行编译,部署到平台上,图13为本发明实施例提供的神经网络模型推理的跨平台编译方法流程图,其具体步骤包括:
步骤1301、获取神经网络模型推理;
步骤1302、将神经网络模型推理,进行编译,部署到一平台上。
在该方法中,部署到一平台的神经网络模型推理的架构包括了公共接口及算子库,其中,对于不同平台上部署的神经网络模型推理,如果是实现同一任务,其公共接口中的神经网络推理是相同的,但是,其算子库中的算子有可能是不同的。
在该方法中,所述神经网络模型推理部署到一平台上,就是将上述架构的神经网络模型推理封装到平台上。
所述方法的编译环境包括跨平台的编译环境及异构平台所属芯片的硬件环境。按照13所述的方法,就可以将神经网络模型推理部署到平台上了。为了实现图13的过程,需要一个跨平台的编译环境及异构平台所属芯片的硬件环境,为的是可以将实现跨平台的神经网络模型推理部署到某一异构平台上。其中,实现跨平台的神经网络模型推理需要依赖跨平台的编译环境即可完成编译,而神经网络模型及模型封装接口需要依赖所加载平台所属芯片的硬件环境进行编译,从而可以将统一的神经网络模型封装到生产的某个异构平台所属的芯片中,也就是对于不同处理器架构的平台所属芯片都封装经过了统一处理的神经网络模型。
在这里,跨平台的编译环境,提供了跨平台的编译优化,包括了加载平台的高性能计算库,编译优化手段包括:在计算图层面进行与计算、算子融合及内存优化等。
图14为本发明实施例提供的跨平台编译及部署的过程流程图,如图所示:
第一步骤,获得多平台的获取神经网络模型推理;
第二步骤,将多平台的获取神经网络模型推理进行编译,生成可执行文件;
第三步骤,获得多平台的神经网络模型及模型封装接口;
在本步骤中,与第一步骤和第二步骤是并列步骤,并不需要在第一步骤和第二步骤后顺序执行;
第四步骤,将多平台的神经网络模型及模型封装接口封装到所生产的芯片上,将生成的可执行文件加载到所生成的芯片的平台上。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!