[0001]
本发明涉及一种基于自我注意力机制的行为识别方法,属于人体动作识别领域。
背景技术:[0002]
动作识别通过提取连续视频帧的动作特征,实现动作分类分类任务,在实际中避免可能存在的危险行为的发生,实际应用场景广泛。
[0003]
现有的动作识别方法,均以3d卷积为基础,用于提取时间序列下的连续帧特征,提高算法对时间序列下图像特征的提取能力,增加动作识别精度。相对于2d卷积而言,3d卷积需要考虑时间轴特征,导致核参数大为增加。同时,3d作为一种新的计算方式,在不同深度学习框架下,对3d卷积的支持程度较差,影响了基于3d卷积的动作识别算法的实际应用性。
技术实现要素:[0004]
针对现有技术的缺陷,本发明提供一种基于自我注意力机制的行为识别算法,该方法使用自我注意力机制替代原用3d卷积操作,用于连续帧图像的时序特征提取,实现对于连续帧的动作检测及目标定位任务。
[0005]
为了解决所述技术问题,本发明采用的技术方案是:一种基于自我注意力机制的行为识别方法,包括以下步骤:
[0006]
s01)、连续帧图像读取:
[0007]
以关键帧为首帧图像,读取连续时间序列下的连续帧图像数据,并构建位置编码矩阵;
[0008]
位置编码矩阵是一个维度为[h,w]的全1矩阵,其中h、w表示读取图像的高度和宽度;
[0009]
s02)、基于2d卷积骨干网络进行图像特征提取:
[0010]
将读取的连续帧图像数据的每一帧输入2d卷积骨干网络,获取每一帧的图像特征,并将每一帧的特征图片进行拼接,从而获取连续帧特征图,关键帧图像为连续帧图像数据中的第一帧,则关键帧的特征图取连续帧特征图的第一帧,即key_frame=clip_frame[0],key_frame表示关键帧特征图,clip_frame表示连续帧特征图;
[0011]
s03)、位置编码:
[0012]
将步骤s01的位置编码矩阵按列方向进行逐列累加,获得矩阵x_embed;
[0013]
将步骤s01的位置编码矩阵按列方向进行逐列累加,获得矩阵y_embed;
[0014]
对矩阵x_embed、y_embed进行优化,获得优化后的结果pe
x_embed
,pe
y_embed
,将pe
x_embed
,pe
y_embed
按第3维度进行拼接,并进行维度顺序变换,获得最终的位置编码矩阵;
[0015]
由于关键帧数据与连续帧数据用在相同的图像处理过程,因此设定关键帧位置编码矩阵与连续帧位置编码矩阵相同,即key_mask=clip_mask,key_mask表示关键帧位置编码矩阵,clip_mask表示连续帧位置编码矩阵;
[0016]
s04)、关键帧图像目标位置预测:
[0017]
s41)、使用单层2d卷积网络对关键帧特征图进行通道压缩,使用线性连接层对关键帧位置编码矩阵进行宽高压缩,通道压缩后的关键帧特征图与宽高压缩后的关键帧位置编码矩阵具有相同的维度;
[0018]
s42)、将通道压缩后的关键帧特征图与宽高压缩后的关键帧位置编码矩阵输入关键帧图像目标预测模块,关键帧图像目标预测模块进行关键帧图像目标位置预测;
[0019]
s05)、连续帧动作预测:
[0020]
s51)、使用多层2d卷积网络对连续帧特征图进行通道压缩,使用线性连接层对连续帧位置编码矩阵进行宽高压缩,通道压缩后的连续帧特征图与宽高压缩后的连续帧位置编码矩阵具有相同的维度;
[0021]
s52)、将通道压缩后的连续帧特征图与宽高压缩后的连续帧位置编码矩阵输入连续帧图像动作类别检测模块,连续帧图像动作类别检测模块进行连接帧动作类别预测;
[0022]
步骤s04的关键帧图像目标预测模块与步骤s05的连续帧图像动作类别检测模块具有相同的结构,均包括编码模块和解码模块;
[0023]
编码模块包括m个串联的编码单元,每个编码单元包括1个多角度注意机制模块和1个数据处理模块,第一个编码单元的输入为通道压缩后的关键帧/连续帧特征图、宽高压缩后的关键帧/连续帧位置编码矩阵,后续编码单元的输入为前一个编码单元的输出;
[0024]
解码模块包括k个串联的解码单元和1个前置多角度注意机制模块,每个解码单元包括1个多角度注意机制模块和1个数据处理模块,前置多角度注意机制模块的输入为宽高压缩后的关键帧/连续帧位置编码矩阵、输出编码初始化值,第一个解码单元的输入为前置多角度注意机制模块的输出和编码模块的输出,后续解码单元的输入为前一个解码单元的输出;
[0025]
上述多角度注意机制模块采用多个平行注意层共同关注来自不同位置的不同表示空间的信息,即对其输入进行多角度注意机制处理,然后通过数据处理模块对多角度注意机制处理后的数据进行残余连接和归一化处理;
[0026]
最终解码器的输出即为预测的关键帧图像目标位置或连续帧图像动作类别。
[0027]
进一步的,多角度注意机制模块的计算过程为:
[0028]
a)、y
multihead
=multihead(q,k,v)=concat(head
1
,head
2
,
…
,head
h
)w
o
,
[0029]
其中,head
1
,head
2
,
…
head
h
为h个平行注意层,为可训练权重,d
model
表示位置编码矩阵的通道数,concat(
·
)表示拼接操作,q,k,v为输入数据,对于编码器中第一个编码单元,q和k相等,等于通道压缩后的帧特征图与宽高压缩后的位置编码矩阵的和,v等于通道压缩后的帧特征图,即
[0030]
q=k=key_frame_in+key_mask_in
[0031]
或者q=k=clip_frame_in+clip_mask_in,
[0032]
v=key_frame_in或者v=clip_frame_in,
[0033]
对于编码器的其他编码单元,q、k、v等于前一个编码单元的输出;
[0034]
对于编码器的前置多角度注意机制模块,q和k相等,等于输出编码初始化值与宽高压缩后的位置编码矩阵的和,v等于输出编码初始化值,即
[0035]
q=k=key_frame_c+key_mask_in,
[0036]
或者q=k=clip_frame_c+clip_mask_in,
[0037]
v=key_frame_c或者v=clip_frame_c,
[0038]
对于解码模块的第一个解码单元,q和k相等,等于编码模块的输出,v等于前置多角度注意机制模块的输出,对于解码模块的其他解码单元,q、k、v等于前一个解码单元的输出;
[0039]
其中,key_in表示通道压缩后的关键帧特征图,key_mask_in表示宽高压缩后的关键帧位置编码矩阵,clip_in表示通道压缩后的连续帧特征图,clip_mask_in表示宽高压缩后的连续帧位置编码矩阵,key_frame_c表示关键帧特征图的编码初始化值,clip_frame_c表示连续帧特征图的编码初始化值;
[0040]
b)、每个平行注意层head
i
的计算过程为:
[0041][0042]
其中为可训练权重参数,d
model
表示位置编码矩阵的通道数。
[0043]
进一步的,数据处理模块的计算过程为:
[0044]
y=layernorm(x+sublayer(x)),
[0045]
y表示每个编码单元或解码单元的输出,sublayer(
·
)是一个完全连接的前馈网络,构建前向数据处理模块,layernorm(
·
)表示层归一化处理,x为输入数据,即经过多角度自注意机制处理后的数据y
multihead
;
[0046]
sublayer(
·
)计算过程表示为:
[0047]
sublayer(x)=max(0,xw
1
+b
1
)w
2
+b
2
,
[0048]
其中,w
1
,w
2
为训练权重,b
1
,b
2
为偏置,为输入数据,即经过多角度自注意机制处理后的数据y
multihead
。
[0049]
进一步的,对矩阵x_embed、y_embed进行优化的过程为:其中dim_t是[0,128)的连续序列,d
model
表示位置编码矩阵的通道数,pe
x_embed
,pe
y_embed
的维度是将pe
x_embed
,pe
y_embed
按第3维度进行拼接,并进行维度顺序变换,获得最终的位置编码矩阵维度为[d
model
,h,w]。
[0050]
进一步的,本方法模型训练过程中的损失函数由三部分组成,分别为loss
giou
目标giou面积损失、目标框位置1范数损失loss
box
、loss
class
类别损失,则整体损失函数可以表示为:loss=w
giou
×
loss
giou
+w
box
×
loss
box
+w
class
×
loss
class
,其中w
giou
,w
box
,w
class
为相应损失权重,基于整体损失函数对模型进行优化。
[0051]
进一步的,关键帧图像目标位置预测模块的输出box的维度为[100,4],即最多可以预测100个目标位置,其中box
i
=[cx
i
,cy
i
,h
i
,w
i
],0≤i<100为第i个目标的中中心点坐
标、目标框高度、目标框宽度。
[0052]
进一步的,连接帧图像动作类别预测模块的输出class的维度为[100,nuclass+1],即最多可以预测100个目标位置,numclass为动作类别数。
[0053]
进一步的,m=6。
[0054]
进一步的,k=6。
[0055]
进一步的,步骤s01中连续读取16帧图像数据,连续帧图像数据的维度为[16,3,h,w],3表示读取帧图像为3通道rgb图像,h,w表示网络输入图像的高度和宽度。
[0056]
本发明的有益效果:本发明介绍了一种基于自我注意力机制的行为识别方法,该方法采用基于多角度注意机制的关键帧目标位置预测和连续帧动作类别预测模块,在完成连续帧动作检测的同时,可以实现目标定位功能。
[0057]
方法中以基于多角度注意机制的关键帧目标位置预测和连续帧动作类别预测模块代替3d卷积网络,解决了3d卷积网络模型计算量较大的问题,并提高了模型在gpu上的并行计算能力,同时,基于多角度注意机制的关键帧目标位置预测和连续帧动作类别预测模块,可避免因为3d卷积在不同深度学习框架下,模型转换或部署时兼容性较弱的问题。
附图说明
[0058]
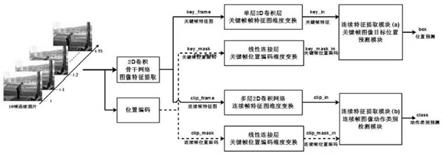
图1为本方法的流程图;
[0059]
图2为编码模块和解码模块的流程图。
具体实施方式
[0060]
下面结合附图和具体实施例对本发明作进一步的说明。
[0061]
实施例1
[0062]
本实施例公开一种基于自我注意力机制的行为识别方法,如图1所示,包括以下步骤:
[0063]
s01)、连续帧图像读取
[0064]
以关键帧为首帧图像,在连续时间序列下连续读取16帧图像数据input,同时读取关键帧目标标签信息target,并构建位置编码初始矩阵mask。
[0065]
连续帧图像数据input的维度为[16,3,h,w],其中h,w表示网络输入图像的高度和宽度,3表示读取帧图像为3通道rgb图像。
[0066]
目标标签信息target,包含图像关键帧的目标位置信息和动作类别信息。
[0067]
对连续16帧图像,采用相同的数据预处理操作,因此对于16帧连续图片,可以采用一个二维的[h,w]的全1矩阵mask作为位置编码初始矩阵,其中h,w表示网络输入图像的高度和宽度。
[0068]
s02)、基于2d卷积骨干网络进行图像特征提取
[0069]
将读取的连续16帧图像数据的每一帧输入2d卷积骨干网络,获取每一帧的图像特征,并将每一帧的特征图片进行拼接,从而获取连续帧特征图clip_frame。
[0070]
关键帧图像为连续帧图像数据中的第一帧,则关键帧的特征图取连续帧特征图的第一帧,即key_frame=clip_frame[0],key_frame表示关键帧特征图,clip_frame表示连续帧特征图。
[0071]
2d卷积骨干网络的输入数据维度为[16,3,h,w],获取的连续帧特征图clip_frame维度为其中关键帧特征图的维度为
[0072]
s03)、位置编码
[0073]
由于模型不包含重复性和3d卷积,因此为了使模型能够利用序列的顺序,我们必须注入一些有关标记在序列中的相对或绝对位置的信息。为此,我们在编码器和解码器堆栈底部的输入中添加位置编码矩阵。
[0074]
本步骤的输入数据为步骤s01中构建的位置编码初始矩阵mask。
[0075]
首先将步骤s01的位置编码初始矩阵按列方向进行逐列累加,获得矩阵x_embed,即:对于x_embed中第j列数据,可以表示为:
[0076][0077]
其中,mask[:,n]表示位置编码初始矩阵mask中的第n列,x_embed[:,j]表示输出数据的第j列,0≤j≤w。
[0078]
然后将步骤s01的位置编码矩阵按列方向进行逐列累加,获得矩阵y_embed,即:对于y_embed中第i行数据,可以表示为:
[0079][0080]
其中,mask
m
表示位置掩码mask,中的第m行,0≤i≤h。
[0081]
下面对按列累加过程进行解释说明。假设mask矩阵是一个维度是[5,5]的全1矩阵,即:
[0082][0083]
对上述mask进行按列累加操作获取输出矩阵x_embed,则:
[0084]
x_embed的第0列为:
[0085][0086]
x_embed的第1列输出为:
[0087][0088]
x_embed的第2列输出为:
[0089][0090]
x_embed的第4列输出为:
[0091][0092]
最终获得的x_embed的最终输出为:
[0093][0094]
下面对按行累加过程进行解释说明。假设mask矩阵是一个维度是[5,5]的全1矩阵,即:
[0095][0096]
对上述mask进行按列累加操作获取输出矩阵y_embed,则:
[0097]
y_embed的第0行为:
[0098]
y_embed[0,:]=mask[0,:]=[1 1 1 1 1]
[0099]
y_embed的第1行输出为:
[0100]
y_embed[0,:]=mask[0,:]+mask[1,:]=[1 1 1 1 1]+[1 1 1 1 1]=[2 2 2 2 2]
[0101]
y_embed的第2行输出为:
[0102]
y_embed[2,:]=mask[0,:]+mask[1,:]+mask[2,:]=[1 1 1 1 1]+[1 1 1 1 1]+[1 1 1 1 1]=[3 3 3 3 3]
[0103]
最终获得的y_embed的最终输出为:
[0104][0105]
然后使用不同频率的正弦和余弦函数,对生成的x_embed和y_embed进行优化处理,优化过程为:
[0106][0107][0108]
其中,dim_t是[0,128)的连续序列,d
model
表示位置编码矩阵的通道数,本实施例中,d
model
=256,输出数据pe
x_embed
、pe
y_embed
的维度是
[0109]
将pe
x_embed
,pe
y_embed
按第3维度进行拼接,获得[h,w,d
model
]的矩阵,并进行维度顺序变换,获得最终的位置编码矩阵clip_mask,其维度为[d
model
,h,w]。
[0110]
由于关键帧数据与连续帧数据均在用相同的图像处理过程,因此,设定关键帧数据位置编码矩阵与连续帧位置编码矩阵相同,即:
[0111]
key_mask=clip_mask,key_mask表示关键帧位置编码矩阵,clip_mask表示连续帧位置编码矩阵。
[0112]
s04)、关键帧图像目标位置预测
[0113]
采用连续特征提取模块(a),以关键帧图像key_frame为输入数据,用于预测目标框,具体步骤为:
[0114]
s41)、使用单层2d卷积网络对关键帧特征图进行通道压缩,关键帧key_frame为:key_frame=clip_frame[0,:,:,:],维度为经过变换后,输出特征key_in的维度为
[0115]
s42)、使用线性连接层对关键帧位置编码矩阵进行宽高压缩,关键帧位置编码矩阵key_mask的维度为[256,h,w],经过变换后输出位置编码矩阵key_mask_in的维度变为
[0116]
s43)、将通道压缩后的关键帧特征图与宽高压缩后的关键帧位置编码矩阵输入关键帧图像目标预测模块,关键帧图像目标预测模块进行关键帧图像目标位置预测;
[0117]
s05)、连续帧动作预测:
[0118]
s51)、使用多层2d卷积网络对连续帧特征图进行通道压缩,连续帧特征图clip_
frame的维度融合后维度为经通道压缩后,获取的clip_in的维度为
[0119]
s52)、使用线性连接层对连续帧位置编码矩阵进行宽高压缩,连续帧位置编码clip_mask的维度为[256,h,w],经过变换后输出位置编码clip_mask_in的维度变为
[0120]
s53)、将通道压缩后的连续帧特征图与宽高压缩后的连续帧位置编码矩阵输入连续帧图像动作类别检测模块,连续帧图像动作类别检测模块进行连接帧动作类别预测。
[0121]
本实施例中,步骤s04的关键帧图像目标预测模块与步骤s05的连续帧图像动作类别检测模块具有相同的结构,均包括编码模块和解码模块;
[0122]
如图2所示,编码模块包括m个串联的编码单元,每个编码单元包括1个多角度注意机制模块和1个数据处理模块,第一个编码单元的输入为通道压缩后的关键帧/连续帧特征图、宽高压缩后的关键帧/连续帧位置编码矩阵,后续编码单元的输入为前一个编码单元的输出;
[0123]
如图2所示,解码模块包括k个串联的解码单元和1个前置多角度注意机制模块,每个解码单元包括1个多角度注意机制模块和1个数据处理模块,前置多角度注意机制模块的输入为宽高压缩后的关键帧/连续帧位置编码矩阵、输出编码初始化值,第一个解码单元的输入为前置多角度注意机制模块的输出和编码模块的输出,后续解码单元的输入为前一个解码单元的输出;
[0124]
上述多角度注意机制模块采用多个平行注意层共同关注来自不同位置的不同表示空间的信息,即对其输入进行多角度注意机制处理,然后通过数据处理模块对多角度注意机制处理后的数据进行残余连接和归一化处理;
[0125]
最终解码器的输出即为预测的关键帧图像目标位置或连续帧图像动作类别。
[0126]
本实施例中,多角度注意机制模块的计算过程为:
[0127]
a)、y
multihead
=multihead(q,k,v)=concat(head
1
,head
2
,
…
,head
h
)w
o
,
[0128]
其中,head
1
,head
2
,
…
head
h
为h个平行注意层,为可训练权重,d
model
表示位置编码矩阵的通道数,concat(
·
)表示拼接操作,q,k,v为输入数据,对于编码器中第一个编码单元,q和k相等,等于通道压缩后的帧特征图与宽高压缩后的位置编码矩阵的和,v等于通道压缩后的帧特征图,即q=k=key_frame_in+key_mask_in(关键帧计算时)
[0129]
或者q=k=clip_frame_in+clip_mask_in(连续帧计算时),
[0130]
v=key_frame_in(关键帧计算是)或者v=clip_frame_in(连续帧计算时),
[0131]
对于编码器的其他编码单元,q、k、v等于前一个编码单元的输出。
[0132]
对于编码器的前置多角度注意机制模块,q和k相等,等于输出编码初始化值与宽高压缩后的位置编码矩阵的和,v等于输出编码初始化值,即
[0133]
q=k=key_frame_c+key_mask_in(关键帧计算时),
[0134]
或者q=k=clip_frame_c+clip_mask_in(连续帧计算时),
[0135]
v=key_frame_c(关键帧计算时)或者v=clip_frame_c(连续帧计算时),
[0136]
对于解码模块的第一个解码单元,q和k相等,等于编码模块的输出,v等于前置多角度注意机制模块的输出,对于解码模块的其他解码单元,q、k、v等于前一个解码单元的输出;
[0137]
其中,key_in表示通道压缩后的关键帧特征图,key_mask_in表示宽高压缩后的关键帧位置编码矩阵,clip_in表示通道压缩后的连续帧特征图,clip_mask_in表示宽高压缩后的连续帧位置编码矩阵,key_frame_c表示关键帧特征图的编码初始化值,clip_frame_c表示连续帧特征图的编码初始化值。
[0138]
b)、每个平行注意层head
i
的计算过程为:
[0139][0140]
其中为可训练权重参数,d
model
表示位置编码矩阵的通道数。
[0141]
本实施例中,数据处理模块的计算过程为:
[0142]
y=layernorm(x+sublayer(x)),
[0143]
y表示每个编码单元或解码单元的输出,sublayer(
·
)是一个完全连接的前馈网络,构建前向数据处理模块,layernorm(
·
)表示层归一化处理,x为输入数据,即经过多角度自注意机制处理后的数据y
multihead
;
[0144]
sublayer(
·
)计算过程表示为:
[0145]
sublayer(x)=max(0,xw
1
+b
1
)w
2
+b
2
,
[0146]
其中,w
1
,w
2
为训练权重,b
1
,b
2
为偏置,为输入数据,即经过多角度自注意机制处理后的数据y
multihead
。
[0147]
本实施例中,本方法模型训练过程中的损失函数由三部分组成,分别为loss
giou
目标giou面积损失、目标框位置1范数损失loss
box
、loss
class
类别损失,则整体损失函数可以表示为:loss=w
giou
×
loss
giou
+w
box
×
loss
box
+w
class
×
loss
class
,其中w
giou
,w
box
,w
class
为相应损失权重,基于整体损失函数对模型进行优化。
[0148]
本实施例中,关键帧图像目标位置预测模块的输出box的维度为[100,4],即最多可以预测100个目标位置,其中box
i
=[cx
i
,cy
i
,h
i
,w
i
],0≤i<100为第i个目标的中中心点坐标、目标框高度、目标框宽度。
[0149]
本实施例中,连接帧图像动作类别预测模块的输出class的维度为[100,nuclass+1],即最多可以预测100个目标位置,numclass为动作类别数。
[0150]
本实施例中,m=k=6,当然,m和k也可以取其他的值。
[0151]
本实施例所述方法解决了3d卷积网络模型参数较多、计算量较大的问题,两个预测模块的gpu并行能力较强,可降低模型运算时间。两个预测模块已已有算子为基础组成而成,在不同深度学习框架兼容性较强。本发明以两个预测模块为核心,构建了以一种新的连
续帧动作识别方法,实现对于连续帧的动作检测及目标定位任务。
[0152]
以上描述的仅是本发明的基本原理和优选实施例,本领域技术人员根据本发明做出的改进和替换,属于本发明的保护范围。