一种采用双向长短期记忆网络的方面级情感分析方法与流程
[0001]
本发明涉及一种方面级情感分析方法,特别是一种采用双向长短期记忆网络的方面级情感分析方法,属于计算机技术领域中的情感分析领域。
背景技术:
[0002]
随着互联网的迅猛发展,社交媒体已深入到人们日常生活和工作中的方方面面。越来越多的人愿意在网络上表达自己的态度和情感,而非单纯地浏览与接受。人们希望通过相应的技术对这些评论文本进行自动化处理、分析,提取有价值的知识。在这样的应用需求背景下,出现了针对文本的情感分析技术,即通过计算机手段,帮助用户快速获取、整理和分析相关评论信息的过程。
[0003]
方面级情感分析是情感分析领域中一种更为细化的模型。目前,常见的方面级情感分析方法主要分为以下三个方面:1.基于情感词典和语言规则的方法,其更接近于传统情感分析方法利用情感词典的解决思路,需要使用标注好的情感词典或语言规则来判别情感极性;2.基于机器学习的方法,此方法较为广泛地应用于方面级情感分析领域,其主要思想是将方面级情感分析任务建模成为分类问题;3.基于其他建模问题的方法,常用的建模方案包括序列标注和阅读理解等。然而上述方法大多是用单一的方法去解决方面级情感分析问题,无论是算法模型的可解释性、有效性还是应用性,都还有改进的空间。
技术实现要素:
[0004]
针对上述现有技术,本发明要解决的技术问题是提供一种解决了传统情感分析算法中的单一性和笼统性问题的采用双向长短期记忆网络的方面级情感分析方法,利用双向长短期记忆网络分析用户的评论信息,并在双向长短期记忆网络模型中引入注意力机制,更加准确的对用户评论中不同方面的情感极性进行判断。
[0005]
为解决上述技术问题,本发明的一种采用双向长短期记忆网络的方面级情感分析方法,包括以下步骤:
[0006]
步骤1:数据预处理,具体为:进行数据清洗并将其词向量化,采用word2vec模型来将数据转换成向量形式,该矩阵维度为n
×
d,其中n是数据所包含的单词数,d为单个词向量的维度;
[0007]
步骤2:建立带有方面感知的双向长短期记忆网络,具体为:将步骤1得到的词向量作为双向长短期记忆网络的序列化输入,使模型分别从两个方向上提取文本的语义特征,同时把方面向量合并到双向长短期记忆网络单元中,设计三个方面门来控制分别被导入到输入门、遗忘门和输出门中的方面向量数量,最终获得每个时间步上的隐藏层状态和带有方面感知的句子整体表示;
[0008]
步骤3:建立基于多重注意力模型的encoder-decoder模型,具体为:在encoder-decoder模型中引入注意力机制,将双向长短期记忆网络输出的隐藏层状态与方面信息相结合,并进行注意力操作,最终提取特征表示;
[0009]
步骤4:情感极性分析,具体为:所用数据集经过步骤3的模型的训练建立不同方面与其相应情感词之间的联系,针对不同方面的文本经过全连接层和softmax函数后,输出待分类样本在每个情感分类上的概率,即可得到与不同方面相对应的情感极性。
[0010]
本发明还包括:
[0011]
1.步骤2中的双向长短期记忆网络具体为:
[0012]
a
i
=σ(w
ai
[a,h
t-1
]+b
ai
)
[0013]
i
t
=σ(w
i
[x
t
,h
t-1
]+a
i
⊙
a+b
i
)
[0014]
a
f
=σ(w
af
[a,h
t-1
]+b
af
)
[0015]
f
t
=σ(w
f
[x
t
,h
t-1
]+a
f
⊙
a+b
f
)
[0016][0017][0018]
a
o
=σ(w
ao
[a,h
t-1
]+b
ao
)
[0019]
o
t
=σ(w
o
[x
t
,h
t-1
]+a
o
⊙
a+b
o
)
[0020]
h
t
=o
t
*tanh(c
t
)
[0021]
其中,x
t
为时间步长t对应的上下文词的输入嵌入向量,a为方面向量,h
t-1
为前一隐藏状态,h
t
为该时间步长隐藏状态,σ和tanh为sigmoid和正切函数,
⊙
表示元素的乘法,w
ai
,w
af
,w
ao
∈r
da
×
(dc+da)
,w
i
,w
f
,w
c
,w
o
∈r
dc
×
2dc
为加权矩阵,b
ai
,b
af
,b
ao
∈r
da
,b
i
,b
f
,b
c
,b
o
∈r
dc
为偏置,da,dc为方面向量维数和隐藏单元数,i
t
,f
t
,o
t
∈r
dc
分别代表输入门、遗忘门和输出门,a
i
,a
f
,a
o
∈r
da
分别代表方面输入门、方面遗忘门和方面输出门。
[0022]
2.步骤3中encoder-decoder模型包括编码模型和解码模型,编码部分对于长度为n的句子,隐藏层输出矩阵为h=[h1,h2,
…
,h
n
],生成句子的整体表示v
s
,满足:
[0023][0024]
解码部分由方面注意力模块组成,其中模块数量n与数据集的方面总个数相同,即一个方面注意力模块对应一个特定的方面;当输入句子包含有多个方面时,编码得到的输出h将被分别送入对应的方面注意力模块中,在每个方面注意力模块中,各有一个对应的方面信息,即方面向量v
ai
,首先,方面向量v
ai
与输入矩阵h中的每个隐状态进行拼接,再进行注意力计算,最后通过加权平均,获得有关特定方面的文本表示,具体为:
[0025]
e
ti
=tanh(w
ai
[h
t
,v
ai
]+b
ai
)
[0026][0027][0028]
其中,i为第i个方面注意力模块,w
ai
∈r
d+m
为注意力的权重矩阵,b
ai
为注意力的偏置项,e
ti
是t
i
时刻注意力分数,e
ji
是ji时刻注意力分数,α
ti
是注意力权重值。
[0029]
本发明的有益效果:本发明提出的基于双向长短期记忆网络的方面及情感分析方法可以有效的改善传统的情感分析算法中对不同方面情感分析的单一性及笼统型问题,提
高了方面级别情感分析的准确性,对相关企业、用户及研究者均有重大意义。实验数据表明,该算法所判断出的结果比传统的情感分析算法具有更高的精度。
附图说明
[0030]
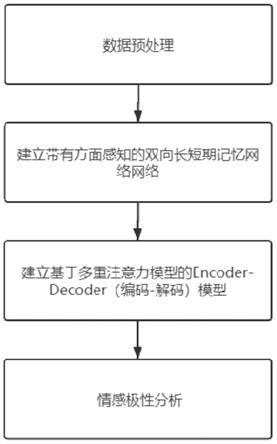
图1是基于基于双向长短期记忆网络的方面级情感分析方法的基本流程图。
[0031]
图2是word2vec中skip-gram模型的基本原理。
[0032]
图3是带有方面感知的双向长短期记忆网络模型。
[0033]
图4是基于注意力模型的encoder-decoder模型。
具体实施方式
[0034]
下面结合附图对本发明具体实施方式做进一步说明。
[0035]
本发明技术方案实施方式具体为:
[0036]
(1)数据预处理:进行数据清洗并将其词向量化。词向量化是文本表示的一部分,主要是将数据转换为计算机可以识别的形式。此处采用word2vec模型来将数据转换成向量形式,该矩阵维度为n
×
d,其中n是数据所包含的单词数,d为单个词向量的维度。
[0037]
(2)建立带有方面感知的双向长短期记忆网络:将预处理后的词向量作为双向长短期记忆网络网络的序列化输入,使模型分别从两个方向上提取文本的语义特征。同时把方面向量合并到经典的双向长短期记忆网络单元中,设计三个方面门来控制有多少方面向量分别被导入到输入门、遗忘门和输出门中。最终获得每个时间步上的隐藏层状态和带有方面感知的句子整体表示。
[0038]
(3)建立基于多重注意力模型的encoder-decoder(编码-解码)模型:encoder-decoder模型是自然语言处理中的一种成熟的序列化模型,但其将整个序列的信息压缩到一个固定长度的向量的特点会使一些信息会被稀释掉,输入的序列越长,这种现象越严重,降低了解码的准确度。因此,本发明在encoder-decoder模型中引入注意力机制。引入注意力机制后的encoder-decoder(编码-解码)模型可以将双向长短期记忆网络输出的隐藏层状态与方面信息相结合,并进行注意力操作,最终提取重要词语的特征表示。
[0039]
(4)情感极性分析:所用数据集经过上述模型的训练最终可以建立不同方面与其相应情感词之间的联系,针对不同方面的文本经过全连接层和softmax函数后,得到最终分析结果。同时为证明本发明方法的准确性,选用f1值指标分别与其他经典方法进行对比试验。
[0040]
结合图1,本发明具体包括以下步骤:
[0041]
1.数据预处理:首先进行数据清洗,其主要任务是完成分词、去除停用词等工作,其中英文的数据集还会涉及到大小写转换等任务。然后进行进行数据词向量化。词向量化是文本表示的一部分,主要是将数据转换为计算机可以识别的形式。此处采用word2vec模型来将数据转换成向量形式,该模型生成的词向量是一种分布式的词向量表示,其中的skip-gram模型利用深度学习方法,训练出有维度的词向量,这些词向量的相似度就代表了词语的相似度。该模型利用上下文预测的方法,即通过一个大小为n的窗口计算窗口中心词出现的概率。其基本原理如图2所示。将词向量作为模型的输入层(input),中心词作为映射层(projection),最终得到周围词,即输出层(output)。
[0042]
2.建立带有方面感知的双向长短期记忆网络:传统的双向长短期记忆网络包含三个门(输入门,忘记门和输出门)以控制信息流。对于方面级情感分析问题来说,“方面”是至关重要的一个因素,因此本发明将方面向量合并到传统的双向长短期记忆网络单元中,并设计了三个方面的门,以控制将方面向量分别输入到输入门,忘记门和输出门的数量。这样就可以利用先前的隐藏状态和方面本身来控制方面在传统双向长短期记忆网络的三个门中的导入量。带有方面感知的双向长短期记忆网络网络结构如附图3所示,可以将其形式化如下:
[0043]
a
i
=σ(w
ai
[a,h
t-1
]+b
ai
)
ꢀꢀ
(1)
[0044]
i
t
=σ(w
i
[x
t
,h
t-1
]+a
i
⊙
a+b
i
)
ꢀꢀ
(2)
[0045]
a
f
=σ(w
af
[a,h
t-1
]+b
af
)
ꢀꢀ
(3)
[0046]
f
t
=σ(w
f
[x
t
,h
t-1
]+a
f
⊙
a+b
f
)
ꢀꢀ
(4)
[0047][0048][0049]
a
o
=σ(w
ao
[a,h
t-1
]+b
ao
)
ꢀꢀ
(7)
[0050]
o
t
=σ(w
o
[x
t
,h
t-1
]+a
o
⊙
a+b
o
)
ꢀꢀ
(8)
[0051]
h
t
=o
t
*tanh(c
t
)
ꢀꢀ
(9)
[0052]
其中x
t
为时间步长t对应的上下文词的输入嵌入向量,a为方面向量,h
t-1
为前一隐藏状态,h
t
为该时间步长隐藏状态,σ和tan h为sigmoid和正切函数,
⊙
表示元素的乘法,w
ai
,w
af
,w
ao
∈r
da
×
(dc+da)
,w
i
,w
f
,w
c
,w
o
∈r
dc
×
2dc
为加权矩阵,b
ai
,b
af
,b
ao
∈r
da
,b
i
,b
f
,b
c
,b
o
∈r
dc
为偏置,da,dc为方面向量维数和隐藏单元数。i
t
,f
t
,o
t
∈r
dc
分别代表输入门、遗忘门和输出门。类似地,a
i
,a
f
,a
o
∈r
da
分别代表方面输入门、方面遗忘门和方面输出门。
[0053]
3.建立基于注意力模型的encoder-decoder(编码-解码)模型:encoder-decoder模型主要是由encoder(编码)模型和decoder(解码)模型两部分组成,其中编码部分为带有方面感知的双向长短期记忆网络网络所述过程。对于长度为n的句子,隐藏层输出矩阵为h=[h1,h2,
…
,h
n
],即编码部分的输出结果为h,分别送入多个方面注意力模块中。同时生成句子的整体表示v
s
,如式(10)所示:
[0054][0055]
解码部分由多个方面注意力模块组成,其中模块数量n与数据集的方面总个数相同,即一个方面注意力模块对应一个特定的方面。当输入句子包含有多个方面时,编码得到的输出h将被分别送入对应的方面注意力模块中。在每个方面注意力模块中,各有一个对应的方面信息,即方面向量v
ai
。首先,方面向量v
ai
与输入矩阵h中的每个隐状态进行拼接,再进行注意力计算,最后通过加权平均,获得有关特定方面的文本表示。计算方法如下:
[0056]
e
ti
=tanh(w
ai
[h
t
,v
ai
]+b
ai
)
ꢀꢀ
(11)
[0057]
[0058][0059]
其中i为第i个方面注意力模块,w
ai
∈r
d+m
为注意力的权重矩阵,b
ai
为注意力的偏置项。基于注意力模型的encoder-decoder(编码-解码)模型如图4所示。
[0060]
4.情感极性分析:将有关特定方面的文本表示v
ci
送入全连接层,通过softmax函数输出待分类样本在每个情感分类上的概率,即可得到与不同方面相对应的情感极性,如式(14)所示:
[0061]
p
i
=softmax(w
pt
v
ci
+b
pi
)
ꢀꢀ
(14)
[0062]
其中p
i
=(p
i1
,p
i2
,
…
,p
ic
),w
pi
∈r
c
×
d
为全连接层的权重矩阵,b
pi
为全连接层的偏置项,c为类别数。
[0063]
为证明本发明方法的准确性,选用f1值指标进行对比试验。f1值是查准率和查全率的调和平均,其计算公式如下:
[0064][0065]
本发明选用5个经典模型进行三分类对比试验,实验结果如表1所示。从对比结果可以看出,bi-lstm模型在消极分类和中性分类f1值上,比lstm模型分别提升了3.39%和5.21%。对比bi-lstm、ae-lstm和atae-lstm这三个模型可以得出,在消极分类效果差不多的情况下加入方面信息或使用注意力机制,能使中性分类效果得到明显改善,分别提升了5.04%和5.93%。最后,本发明提出的方法在三分类f1值上,比atae-lstm模型分别提升了0.83%、2.28%和4.93%,同样在中性分类效果上改善明显。这表明本发明提出的方法能有效地处理情感极性模糊、表达不清晰等情况下的句子。
[0066]
表1对比试验结果
[0067][0068]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1