一种基于图表征融合的问句生成方法及装置与流程
本发明涉及文本生成技术领域,尤其涉及一种基于图表征融合的问句生成方法及装置。
背景技术:
作为自然语言处理的子任务,问句生成的一个关键应用是为教育领域生成用于阅读理解材料的问题。问句生成模块也可以部署为聊天机器人的组件,使得在多轮对话中聊天机器人能够提出一些问题,提升用户的交互体验。不仅如此,问句生成也能够帮助机器阅读理解任务获取丰富的问答对,辅助机器阅读理解模型的训练,从而开启机器理解人类语言的大门。
早期研究中,问句生成的常规方法是基于规则的方法,其通常步骤可以归纳为:1.文本预处理,包括句法解析,句子简化,语义角色标注;2.根据规则或者语义角色标注方法,识别需要被提问的目标;3.使用规则或模板匹配等方式生成多个问题;4.基于设计好的特征对生成问题进行排序。基于规则的方法,存在的明显缺点包括,需要人为制定规则和模板,制定规则的成本较高,制定的规则只能针对特定领域、扩展性较差,可处理的问题类型有限等。
近年来研究者们不断尝试用神经网络做问句生成。受到机器翻译任务的启发,神经网络的问句生成通常被定义为序列到序列(sequence-to-sequence,seq2seq)的学习问题,一种通常的做法是用两个循环神经网络(recurrentneuralnetwork,rnn)分别作为编码器和解码器,编码器对输入的文本序列逐一编码,解码器结合注意力机制(attentionmechanism),输出一段问句序列。基于神经网络的方法,可以端到端进行训练,不需要人工制定规则,同时通过数据驱动,只要有足够的数据,不同领域的内容也可以方便地复用模型。但是,神经网络方法由于普遍采用rnn做序列化编码,与人类理解文本的推理过程不一致,而且忽略了文本的语法结构等信息,所以生成问句的质量仍然有待提升。
综上所述,现有的方法存在的问题有:1、基于规则的方法需要人工制定规则,成本较高、规则的扩展性较差、可处理的问题类型有限;2、基于传统的神经网络seq2seq的方法仅利用词向量等特征,忽略了文本的语法结构等信息;3、单纯的seq2seq对文本进行序列化的建模,与人类理解文本的推理过程不一致,导致生成的问题变得生硬。
技术实现要素:
本发明的目的在于提供一种基于图表征的问句生成方法及装置,用于解决现有的基于规则的方法存在规则制定成本较高、规则的扩展性较差、可处理的问题类型有限等问题,以及基于神经网络seq2seq的方法忽略了文本的语法结构、与人类理解文本的推理过程不一致导致生成的问句质量受影响等问题。
本发明通过以下技术方案来实现上述目的:
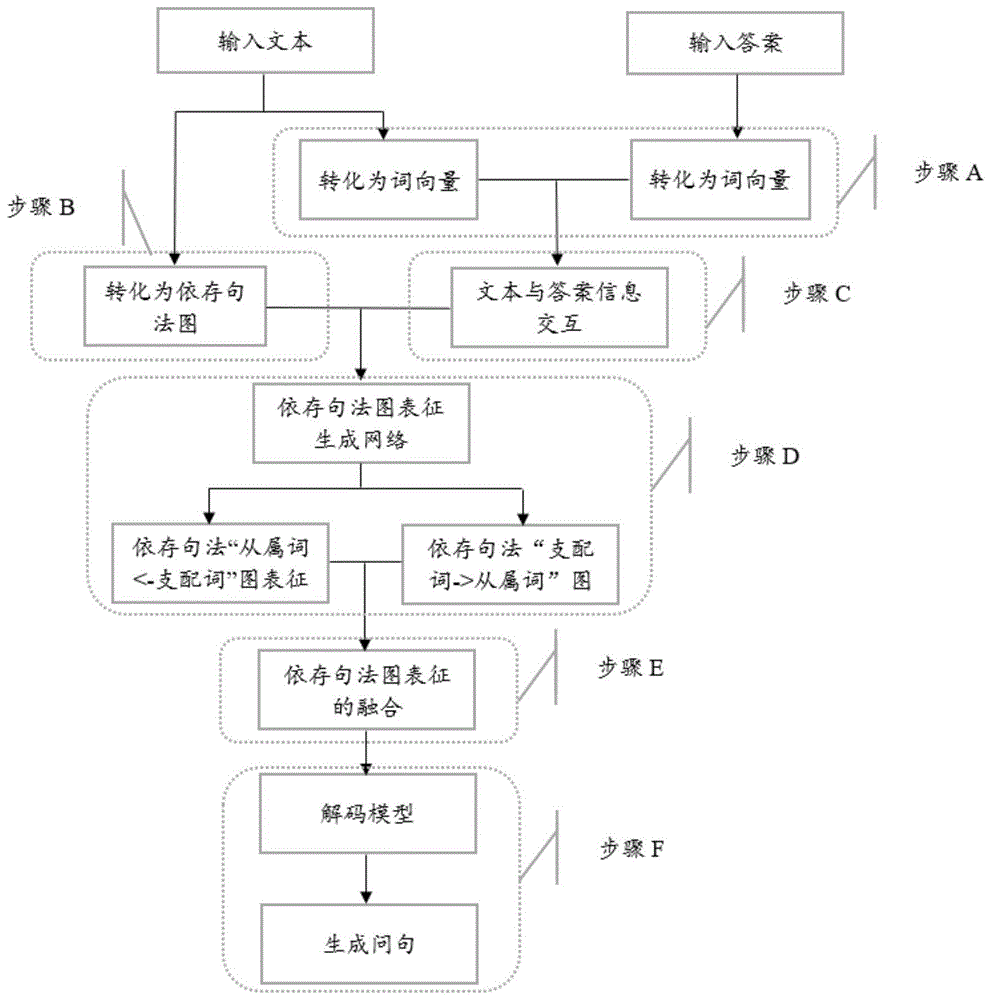
一种基于图表征融合的问句生成方法,包括以下步骤:
a、初始化文本、答案的语义编码序列;
b、通过对文本的句法分析,获取文本每个句子的依存句法树,构建整个文本的依存句法图;
c、将文本信息和答案信息进行交互,为文本编码引入答案信息,得到文本的交互编码;
d、基于文本的依存句法图,结合文本的交互编码,构建文本的依存句法图在两个方向的图表征;
e、将文本在依存句法图两个方向的图表征进行融合,得到最终的图表征;
f、根据文本的依存句法图表征,利用问句生成模块生成问句序列。
进一步方案为,所述步骤a中初始化语义编码序列的方法包括:采用词向量随机初始化的表示方法,或基于深度学习的语言模型训练得到的向量表示方法。
进一步方案为,所述步骤b中获取文本每个句子的依存句法树的方法包括:对句子进行依存句法分析。
进一步方案为,所述步骤b中构建整个文本的依存句法图的方法包括:多棵依存句法树合并为依存句法图。
进一步方案为,所述步骤c中将文本信息和答案信息进行交互的方法包括:对步骤a中得到的文本词向量和答案词向量进行深度对齐。
进一步方案为,所述步骤d中构建文本基于依存句法图的两个方向图表征的方法包括:利用自回归模型迭代计算图表征。
进一步方案为,所述步骤e中将文本在依存句法图两个方向的图表征进行融合的方法包括:多个单词的图表征融合为一个句子图表征、两个方向的图表征融合。
进一步方案为,所述步骤f中所述问句生成模块的方法包括:基于循环神经网络的解码模块,文本表征和解码模块输出之间的注意力交互。
进一步方案为,还包括将词向量输入所述问句生成模块进行训练的方法,包括:所述问句生成模块损失函数的设定、迭代更新,所述问句生成模块参数的方法的设定,对所述问句生成模块中各层参数的初始化,各个网络层之间的连接以及对齐。
本发明另一方面还提供了一种基于图表征的问句生成装置,包括:
语义编码初始化模块,用于对输入的文本和答案进行分词,然后将单词转化为对应的词向量;
句法分析模块,用于对文本进行依存句法分析,生成对应的依存句法图;
文本与答案交互模块,用于将答案信息与文本信息进行交互,得到包含答案信息的文本向量;
基于依存句法的图表征构建模块,用于构建文本的基于依存句法关系的图表征;
图表征信息融合模块,用于对整个文本在两个方向的图表征进行融合,同时对文本所有单词的图表征进行融合;
问句生成模块,用于在得到文本的图表征之后对其进行解码并生成质量最优的问句。
本发明的有益效果在于:
本发明的一种基于图表征融合的问句生成方法,不需要人工制定规则,能够端到端生成问句;突破了传统seq2seq只能序列化处理文本而忽略了文本结构信息的局限,通过在文本编码中引入依存句法信息来模仿人类的推理过程,利用文本结构信息来优化生成问句的质量。
本发明的一种基于图表征融合的问句生成装置,给定一段文本和答案,在不依赖人工制定规则模板的条件下,能够端到端生成问句,并且能考虑文本的依存句法等信息,使得生成的问句接近人工提问的质量。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例或现有技术描述中所需要实用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明中的基于图表征的问句生成方法流程图;
图2为本发明中的一棵依存句法树的示例图;
图3为本发明中的多棵依存句法树合并为依存句法图的示例图;
图4为本发明中的基于图表征的问句生成装置结构框图;
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将对本发明的技术方案进行详细的描述。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所得到的所有其它实施方式,都属于本发明所保护的范围。
实施例一:
图1示出了本发明一种基于图表征的问句生成方法的流程图,包括以下步骤:
a、初始化文本、答案的语义编码序列。
初始化语义编码序列的方法,包括:词向量随机初始化的表示方法,词向量在模型训练过程中根据模型参数的迭代更新而更新。
初始化语义编码序列的方法,还包括:基于深度学习的语言模型训练得到的词向量,这样的词向量有glove,word2vec,bert等。
b、获取文本每个句子的依存句法树,进而构建整个文本的依存句法图。
获取文本每个句子的依存句法树的方法,包括:对句子进行依存句法分析的方法。
具体为,对句子进行依存句法分析的方法,包括:基于图的依存句法分析方法,将依存句法分析问题转化为从完全有向图中寻找最大生成树的问题;基于转移的依存句法分析方法,将依存句法分析问题转化为寻找最优动作序列的问题。
依存句法树构建的一个例子是:对句子t=“新鲜的水果有营养”,分词得到tokst=[“新鲜”,“的”,“水果”,“有”,“营养”],用节点表示为nodest=[1,2,3,4,5],构建的依存句法树为treet={[1->2],[1<-3],[3<-4],[4->5]},如图2所示。
构建整个文本的依存句法图的方法,包括:将构建的多棵依存句法树合并为一个依存句法图的方法。
合并依存句法树的做法是:把句子之间的相邻节点用无向边连接起来,得到一个新的图,如图3所示。
c、将文本信息和答案信息进行交互,为文本编码引入答案信息,得到文本的交互编码。
将文本信息和答案信息进行交互的方法,包括:对步骤a中得到的文本词向量和答案词向量进行深度对齐的方法。
对步骤a中得到的文本词向量和答案词向量进行深度对齐的做法是:注意力机制,深度对齐网络(deepalignmentnetwork,dan)等。
d、基于文本的依存句法图,结合文本的交互编码,构建文本的依存句法图在两个方向的图表征。
构建文本基于依存句法图的两个方向图表征的方法,包括:利用自回归模型迭代计算图表征的方法。
自回归模型包括:门控循环单元(gatedrecurrentunit,gru),长短期记忆网络(long-shorttermmemory,lstm)。
利用自回归模型迭代计算图表征的方法的做法是:将每个文本单词看作一个节点,在第k轮(k=1,2,…,k;k是设定的迭代轮数阈值),根据文本的依存句法图来聚合一个节点与其相邻节点信息,根据节点第k轮的聚合信息和节点第k-1轮的表征,利用自回归模型计算得到节点的第k轮表征。
根据文本的依存句法图来聚合一个节点与其相邻节点信息之前,通过依存句法图的“支配词->从属词”和“从属词<-支配词”两种方向来决定一个节点的相邻节点。例如,在构建“支配词->从属词”方向的图表征时,每个节点只和其所有从属词节点进行聚合;在构建“从属词<-支配词”方向的图表征时,每个节点只和其所有支配词节点进行聚合。
e、融合文本在依存句法图两个方向的图表征,得到最终的图表征。
将文本在依存句法图两个方向的图表征进行融合的方法,包括:多个单词的图表征融合为整个文本图表征的方法,两个方向的图表征融合的方法。
多个单词的图表征融合为一个句子图表征的方法,包括:将多个单词的图表征序列输入池化层进行下采样得到整个文本的图表征。
池化层可以采用的操作不局限于最大池化、平均池化等。
两个方向的图表征融合的方法,包括:图表征的拼接,图表征的相加,图表征的门控融合等。
f、根据文本的依存句法图表征,利用问句生成模块生成问句序列。
问句生成模块采用的方法,包括:基于循环神经网络的解码模块,文本表征和解码模块输出之间的注意力交互机制。
基于循环神经网络的解码模块可以采用的网络单元为lstm或者gru。
基于神经网络的解码模块的网络单元进行解码之前,需要用整个文本的图表征来初始化解码模块网络单元的隐藏层。
文本表征和解码模块输出之间的注意力交互机制,可以采用softattention机制,使得解码时关注更重要的单词,淡化非重要单词的影响。
所述基于图表征的问句生成方法还包括:所述联合模型损失函数的设定,迭代更新所述联合模型参数的方法的设定,对所述联合模型中各层参数的初始化,各个网络层之间的连接以及对齐,对所述联合模型进行训练等。
采用最大间隔损失函数对联合模型参数进行优化,并加入正则化公式来提高模型的泛化能力;训练过程中,当损失值不在合理范围内时,调整联合模型参数并继续训练,直到损失值下降到合理范围内时,将该模型作为问句生成联合模型。
通过本发明实施例一提供的一种基于图表征的问句生成方法,不需人工制定规则,只要有足够的训练数据就可以训练问句生成模型,为传统的seq2seq神经网络引入了文本的依存句法等信息,以此来优化生成的问句。
实施例二:
图4示出了本发明中的基于图表征的问句生成装置结构框图,包括:
语义编码初始化模块,用于对输入的文本和答案进行分词,然后将单词转化为对应的词向量;
句法分析模块,用于对文本进行依存句法分析,生成对应的依存句法图;
文本与答案交互模块,用于将答案信息与文本信息进行交互,得到包含答案信息的文本向量;
基于依存句法的图表征构建模块,用于构建基于依存句法关系的文本图表征;
图表征信息融合模块,用于对整个文本在两个方向的图表征进行融合,同时对文本所有单词的图表征进行融合;
问句生成模块,用于在得到文本的图表征之后对其进行解码并生成质量最优的问句。
需要说明的是,本实施例中的各模块(或单元)是逻辑意义上的,具体实现时,多个模块(或单元)可以合并成一个模块(或单元),一个模块(或单元)也可以拆分成多个模块(或单元)。
通过本发明实施例二提供的一种基于图表征的问句生成装置,给定一段文本和答案,在不依赖人工制定规则模板的条件下,能够端到端生成问句,并且能考虑文本的依存句法等信息,使得生成的问句接近人工提问的质量。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合,为了避免不必要的重复,本发明对各种可能的组合方式不再另行说明。此外,本发明的各种不同的实施方式之间也可以进行任意组合,只要其不违背本发明的思想,其同样应当视为本发明所公开的内容。
- 还没有人留言评论。精彩留言会获得点赞!