一种基于资源预调度故障极速恢复的operator装置的制作方法
[0001]
本发明涉及云原生基础设施领域,特别涉及一种基于资源预调度故障极速恢复的operator装置。
背景技术:
[0002]
目前基于云原生技术资源调度有三种:单体调度(集中式结构,一个中央调度器,如:borg/kubernetes),两层调度(树形结构,一个中央调度器,多个第二层调度器如:mesos/yarn)以及共享状态调度(分布式结构,多个对等调度器,如google的omega)。
[0003]
1,单体调度采用master/slave架构,由一台或多台服务器组成master节点,系统内所有的数据都存储在master节点中,系统内的所有业务均先由master处理,多个slave节点与master连接,并将自己的资源信息汇报给master,由master统一资源和任务调度。master一旦检测到服务失败或与期望值不符,并下发指令重新调度和生成(如图1所示);
[0004]
2,两层调度:把资源和任务分开调度,一层只负责资源管理和分配,一层负责任务与资源匹配(如图2所示);
[0005]
3,共享状态调度:分布式调度,每个调度器支持共享集群状态,包括资源状态和任务状态,提升调度效率(如图3所示)。
技术实现要素:
[0006]
本发明要解决的技术问题是克服现有技术的缺陷,提供一种基于资源预调度故障极速恢复的operator装置。
[0007]
为了解决上述技术问题,本发明提供了如下的技术方案:
[0008]
本发明一种基于资源预调度故障极速恢复的operator装置,包括以下步骤:
[0009]
s1.在原调度系统上扩展智能预调度ipod装置(ipod:intelligentprescheduleroperatordevice),针对kubernetes系统可通过crd(customresourcedefinition)方式扩展,针对其他调度系统需要通过第三方插件方式;
[0010]
s2.具体包括两种调度方式:
[0011]
一种是批处理任务,通常需要几分钟/小时处理,这种对短时间的波动不是很敏感,为了保证数据一致性,避免重复计算,故障发生时,智能调度器ipod进行故障预测,提前采用预锁定资源,一旦发生故障,跳过资源申请阶段,加速恢复;
[0012]
另一种是长服务,长时间运行不停止的服务,对短时间波动很敏感,要求能够毫秒/秒级返回(如web服务),故障发生前,ipod进行故障预测,预先调度服务,进行无缝切换;
[0013]
s3.ipod服务可靠性预测算法:
[0014]
1)work节点画像特征;
[0015]
2)task画像特征;
[0016]
3)计算过程:
[0017]
a)按照特征画像描述,分别计算节点画像特征和task画像特征,分别更新到失败
队列,队列长度为10。更新方法:当队列未填满时直接填充队列,当队列已满按照k-mediods无监督聚类方法,进行合并(k=10),从新形成10条记录;
[0018]
b)分别计算与10组的余弦相似度求均值,且失败队列至少须有1组;
[0019]
c)余弦相似度>0.8和在线模型预测开启预调度,同时0.8作为初始参数,本任务修正参数为0;
[0020]
d)超时(15分钟)任务未失败则取消预调度,并记录预调度次数,累计3次修正更新相识度阈值及本任务的初始矫正参数减去0.2进行修正;
[0021]
e)同时对于未预测成功的的调度任务进行记录进行合并,以及任务参数修正,按加上0.2修正;
[0022]
f)重复a-e步骤。
[0023]
与现有技术相比,本发明的有益效果如下:
[0024]
本发明在故障发生时,对于批任务通过ipod预锁定资源显著降低批任务故障恢复的时间,极速恢复故障,对于长服务,ipod预调度实现无缝进行故障恢复,服务可靠性得到极大提升。
附图说明
[0025]
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
[0026]
图1是本发明的实施例示意图之一;
[0027]
图2是本发明的实施例示意图之一;
[0028]
图3是本发明的实施例示意图之一;
[0029]
图4是本发明的实施例示意图之一;
[0030]
图5是本发明的实施例示意图之一;
[0031]
图6是本发明的实施例示意图之一;
[0032]
图7是本发明的实施例示意图之一;
[0033]
图8是本发明的实施例示意图之一。
具体实施方式
[0034]
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
[0035]
实施例1
[0036]
本发明如图1-8所示,本发明提供一种基于资源预调度故障极速恢复的operator装置,包括以下步骤:
[0037]
s1.在原调度系统上扩展智能预调度ipod装置(ipod:intelligentprescheduleroperatordevice),针对kubernetes系统可通过crd(customresourcedefinition)方式扩展,针对其他调度系统需要通过第三方插件方式(如图1所示);
[0038]
s2.具体包括两种调度方式(如图2所示):
[0039]
一种是批处理任务,通常需要几分钟/小时处理,这种对短时间的波动不是很敏感,为了保证数据一致性,避免重复计算,故障发生时,智能调度器ipod进行故障预测,提前
采用预锁定资源,一旦发生故障,跳过资源申请阶段,加速恢复;
[0040]
另一种是长服务,长时间运行不停止的服务,对短时间波动很敏感,要求能够毫秒/秒级返回(如web服务),故障发生前,ipod进行故障预测,预先调度服务,进行无缝切换;
[0041]
s3.ipod服务可靠性预测算法:
[0042]
1)work节点画像特征:
[0043]
[0044][0045]
2)task画像特征:
[0046][0047]
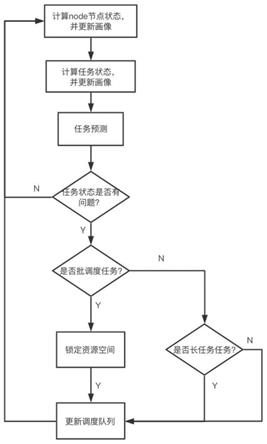
3)计算过程(如图3):
[0048]
a)按照特征画像描述,分别计算节点画像特征和task画像特征,分别更新到失败队列,队列长度为10。更新方法:当队列未填满时直接填充队列,当队列已满按照k-mediods无监督聚类方法,进行合并(k=10),从新形成10条记录;
[0049]
b)分别计算与10组的余弦相似度求均值,且失败队列至少须有1组;
[0050]
c)余弦相似度>0.8和在线模型预测开启预调度,同时0.8作为初始参数,本任务修正参数为0;
[0051]
d)超时(15分钟)任务未失败则取消预调度,并记录预调度次数,累计3次修正更新相识度阈值及本任务的初始矫正参数减去0.2进行修正;
[0052]
e)同时对于未预测成功的的调度任务进行记录进行合并,以及任务参数修正,按加上0.2修正;
[0053]
f)重复a-e步骤(如图4);
[0054]
具体的,operator主流程(如图5);
[0055]
operator与调度队列处理流程(如图6)。
[0056]
根据图7,还有以下示例(如图8所示):
[0057]
1)创建ipod项目;
[0058]
2)通过添加自定义资源(crd)定义新的资源api;
[0059]
3)指定使用sdkapi来和master/schedulewatch状态和资源;
[0060]
4)定义ipod协调逻辑;
[0061]
5)使用operatorsdk构建并生成ipod部署清单;
[0062]
6)容器化后部署到集群。
[0063]
本申请相对现有技术而言,所具有的优点和效果
[0064]
本发明在故障发生时,对于批任务通过ipod预锁定资源显著降低批任务故障恢复的时间,极速恢复故障,对于长服务,ipod预调度实现无缝进行故障恢复,服务可靠性得到极大提升。
[0065]
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1