一种基于动态主题窗口模型的多轮对话下意图识别方法与流程
本发明涉及机器学习与自然语言处理领域,更具体地说是一种基于动态主题窗口模型的多轮对话下意图识别方法。
背景技术:
构建一个可以使用自然语言与人自动连贯地互动交流的人机对话系统一直是学术研究和商业应用的巨大挑战。从应用的角度来看,对话系统可以分为两大类,即面向任务型导向的对话系统和面向聊天的对话系统。我们的发明专利是面向任务型导向人机对话系统中的意图识别。在现有的面向任务型导向人机对话系统中,其对话文本具有以下三个特点:第一,语句中口头表达的比例比较高,同一概念有多种表达方式;其次,短文本的比例比较高,用户在每一轮的输入表达相对较短,有些输入可能只有几个词;第三,多轮对话中每轮的对话内容可能不是独立的,即有时对话的内容很难通过在单轮对话中阐述清楚,此时则可能需要结合上下文信息来帮助理解对话。通过多轮对话可以收集更多的语义信息,更准确的识别出提问者的意图。在实际应用场景中,无论是语音识别还是人的语言表述都是非精确的,这无形之中大大增加了机器人对用户的意图理解难度。如何正确识别提问者的意图,一直以来都是多轮对话系统研究的重点之一。
早期的意图识别方法是将其视为语义话语分类问题,主要包括基于规则模板的方法、使用统计特征的方法以及基于机器学习分类算法的方法。基于规则模板的方法,通常针对于一些符合一定的规则的,并且结构非常相似的句子。它需要人为地构建规则模板和类别信息,即哪些关键字对应于哪个意图。然后,通过规则模板解析的方式来确定提问者的意图。基于规则的对话系统无法支持真正的开放域对话,一旦超出规则的范围,系统就无法识别,而且这种方式不仅人工成本高、效率低而且不易扩展。基于统计特征的方法,是使用意图词典进行词频统计,取出现最频繁的词对应的意图为提问者的意图,这种方法虽然相对简单,但是其识别效果不好。基于机器学习的方法通常使用分类器,如naivebayes,supportvectormachine,logisticregressive等等,这些方法实现多意图识别的常用方法是为每个意图训练一个分类器,构成一个分类链,然后逐层使用它,这种方法在意图识别的准确性上有了显著的提高,但是这类方法大多不能解决稀疏矩阵的问题,只能依靠大量的标记语料库,同样无法降低人工成本。
近些年来,随着深度学习不断的发展,利用神经网络模型去处理对话系统中意图识别的诸多问题也逐渐成为了主流趋势。其主要思想是将抽象问题转化为具体问题,即将意图识别任务转化为对意图的分类任务,类似于文本中的聚类任务,通过使用文本分类算法达到意图识别的效果。
技术实现要素:
本发明的目的在于:为了解决复杂任务型会话场景中简短的口头表达以及内容宽泛等因素导致的多轮对话系统中意图识别误检率高的问题。提出了一种基于动态主题窗口模型的多轮对话下意图识别方法。该方法通过有效的利用上下文相关的语境信息,克服了复杂会话场景下简短的口头表述以及内容宽泛的困难问题,并可以有效地识别出的提问者的意图,在面向任务型智能对话系统的发展中具有重要帮助。
为了实现上述目的,本发明采用了如下技术方案:
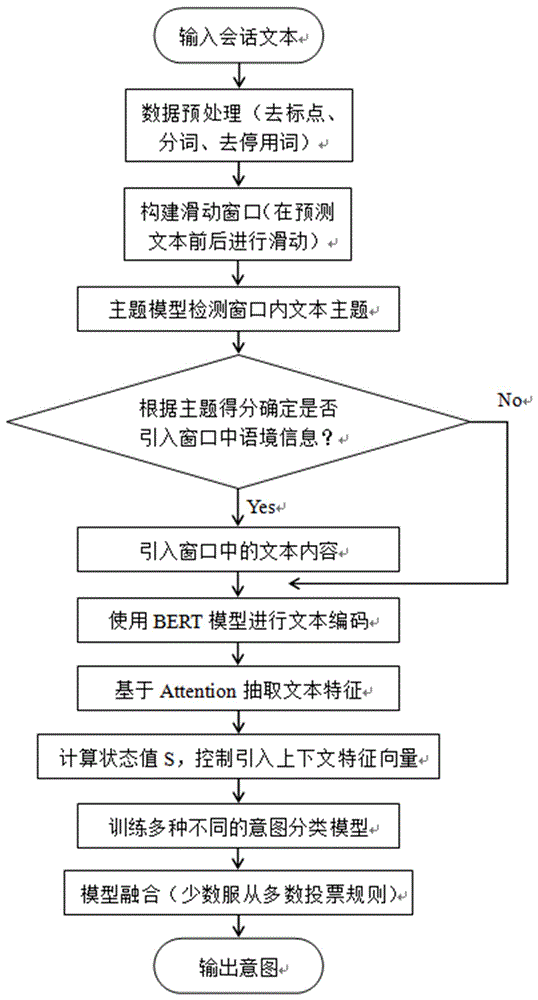
步骤(1)、数据预处理:去标点、分词以及去停用词;
步骤(2)、构建一个动态主题窗口模型去预测待识别文本周围的主题,根据预测结果来引入窗口语境信息;
步骤(3)、使用bert模型对步骤(2)中得到的语境信息进行编码,并基于attention机制来抽取上下文相关语境信息的特征向量,通过计算一个状态值来控制引入的上下文相关的语境信息特征;
步骤(4)、最后,根据抽取到的特征向量来训练不同的意图分类模型,将所有分类模型进行融合,采用投票方式,即可给出意图识别结果;
与现有技术相比,本发明有益效果体现在:
1、首先,使用基于深度学习的方法,可以更好的迁移使用。对于不同领域的意图识别任务来说,只需要更换该领域标注过的意图数据,进行重新训练模型即可。相比于传统的基于规则模板的方法,不需要考虑用户表述的规范性,省去了人工制定模板的成本,而且更易于扩展。
2、其次,相对只使用当前文本信息进行意图识别的方法来说,通过使用主题模型可以控制是否需要引入一定范围内的上下文相关的语境信息,从而能更有效的提升分类算法的性能,也能减少从全文引入不必要的语境信息所带来的噪声的影响。
3、最后,相对传统的意图识别方法,基于深度学习的方法具有更精准的识别效果,并且采用多模型融合的策略能进一步提升意图识别的效果。
附图说明
图1为本发明方法流程图;
图2为本发明意图识别算法结构图;
图3为本发明使用的lda主题模型图;
图4为本发明使用bert模型的编码过程图;
图5为本发明控制模块中状态信号的实现。
具体实施方式
本实施例中,一种基于动态主题窗口模型的多轮对话下意图识别方法。数据流程图如图1所示。其中意图识别算法框架主要分为三大模块:编码模块、控制模块和分类模块,如图2所示,具体地说是按如下步骤进行:
步骤(1)、数据预处理:去标点、分词以及去停用词;
步骤(1.1)、首先将对话文本进行去标点、去特殊符号如表情符号,其次去重;
步骤(1.2)、然后,使用特定领域的分词工具pkuseg对文本进行分词,从而在一定程度上消除歧义词的影响;
步骤(1.3)、最后,采用公开的停用词库对分词结果进行去停用词操作。
步骤(2)、编码模块,构建一个动态主题窗口模型去预测待识别文本周围的主题;
步骤(2.1)、首先构建一个包含对话轮数为2的窗口,在预测文本qi前后进行对话轮数大小为1的滑动操作,记为sw(qi-1ai-1,qiai),其中qiai为第i轮的一轮对话,前后滑动的对话轮数距离待预测文本不超过3轮;
步骤(2.2)、其次、构建lda模型;
步骤(2.2.1)、先建立一个主题库,其中有一个主题的标记为无意图,为每个主题选取一定数量的能反应该主题的词语;
步骤(2.2.2)、如图3所示,lda模型分为两个过程,
其中k为主题个数,m为文本总数,
步骤(2.2.3)、根据联合概率分布,使用gibbssampling对其进行采样,假设已经观测到的词wi=t,则由贝叶斯法则得到公式(2)如下所示:
结合联合概率分布可推得公式(3):
由dirichlet参数估计的公式:
最后得到lda模型的gibbssampling公式,如公式(6)所示,最终确定预测文本的主题。
其中zi=k为第k个主题中的第i个词,
步骤(2.3)、最后,使用构建lda模型进行步骤(2.1)中的操作,即窗口每滑动一次,使用lda模型进行预测一次。通过计算每个主题对应的得分确定编码过程中需要引入对应的窗口下语境信息。统计无意图主题所占比例如果超过0.5,则不需要引入上下文语境信息。
步骤(3)、首先使用bert模型对步骤(2)中获得的文本进行编码,如图4所示,首先将每一条的对话文本拆分成单个字,分别进行tokenembedding、segmentembedding、positionembedding,然后进行求和,求和结果输入到bert中编码为连续向量空间的向量,得到每条对话的编码向量,编码公式如公式(7)所示:
其中
其次,基于attention机制来相关性较高的语特征向量,对于第i个待预测文本的编码向量
最后计算出的相关程度值的集合经过softmax进行归一化就得到了符合概率分布取值区间的注意力分配概率分布数值。
控制模块,如图5所示,通过计算一个状态值s来控制引入上下文相关的语境信息特征,如公式(9)所示:
其中vh为对话文本中第i个待预测文本的上下文编码向量,wts为权重。
步骤(4)、分类模块,根据抽取到的特征向量来训练不同的意图分类模型,选取的分类模型要求模型之间相互独立,即模型之间的相关性尽可能的小。构建一个分类器,将第i个待预测文本的编码向量
目标函数采用binarycrossentropy,n表示样本的总数,x表示样本,yi表示目标标签向量的第i维度,oi表示预测标签向量的第i维度,目标标签向量y和预测标签向量o是维度为标签集合大小的向量。如公式(11)所示:
对于分类器,还可以使用现有的分类算法来实现如textcnn、fasttext等等。
最后采用多模型融合的优化策略进一步提升意图识别的准确率。对于模型融合的原则,采用少数服从多数的投票方式进行处理。假设有m个意图,m0表示没有意图,m1表示编号为1的意图,m2表示编号为2的意图......,mi=1表示存在编号为i的意图,使用n个分类器得到n个分类的结果,对每个分类器设置一个权重wtc,权重满足公式(12):
wtc1+wtc2+wtc3+…+wtcn=1(12)
根据这n个结果,统计每个意图得票的数量。对于统计结果可能存在如下两种情况:
只有一个意图得票数最多,取该意图作为最终意图识别结果。
存在两个或两个以上的意图得票数量相同且是最多的。针对这种情况,我们采用分类器加权求和的方式来确定意图。假设存在两个意图mi,mj(0≤i,j≤m且i≠j)满足条件,计算这两个意图对应的分类器权重之和,如公式(13)所示:
最后对计算的结果取最大值,最大值对应的意图作为最终意图识别结果,若存在相同的最大值,则这两个意图均作为最终的结果。最后得到意图识别的最终结果。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!