基于YOLO-RGGNet的机器人端人脸检测方法与流程
基于yolo-rggnet的机器人端人脸检测方法
技术领域
1.本发明涉及深度学习目标检测和机器人交叉领域,尤其是涉及了基于yolo-rggnet的机器人端人脸检测方法。
背景技术:
2.在计算机视觉领域里,对人脸识别与定位对于机器人、基于手机的智能app、智能显示器支架等应用场合都是一个不可或缺的功能。这种定位通常需要采用双目摄像机、深度摄像机、激光/微波雷达等技术实现,随之而来的是系统硬件成本和算法计算复杂度的提升。
3.传统的人脸识别算法包括几何特征方法、支持向量机、pca等。几何特征方法速度快,但识别率较低。支持向量机和pca方法准确率相对较高,但需要大量的训练样本。
4.近年来,基于深度学习的人脸识别方法faceboxes、mtcnn和facenet等,在精度和速度方面都有了巨大的进步,但是这类算法参数量大、资源内存消耗多、实时性不高,不易直接移植到机器人等嵌入式智能终端平台。而随着生活水平的提高,人们迫切需求一种类似于人与人之间的场景真实的人机交互方式,从机器人平台获得更好的情感体验,因而拥有人脸识别、真实情感对话的服务能力的机器人越来越引起人们的关注。如果能将深度学习和机器人结合,构建一种能根据人脸位置变动而实时进行头部转向的的易于移植的人机交互系统,将对开发具有情感和社交智能的个性化机器人方向灌入巨大的潜力,进而对未来人机交互领域产生重大的意义。
技术实现要素:
5.针对现有技术的不足,本发明提出了基于yolo-rggnet的机器人端人脸检测方法,能高效识别出自然环境中人脸并且在机器人平台检测速度快、鲁棒性高。
6.基于yolo-rggnet的机器人端人脸检测方法,具体包括以下步骤:
7.步骤1、建立数据集
8.从互联网采集或者拍摄自然场景下的人脸图片,并对图像进行预处理操作扩充数据后划分训练集和验证集,然后标注图像中人脸框的高度、宽度和左上角坐标。
9.作为优选,对图像进行预处理的操作包括几何变换、高斯模糊和亮度对比度随机调节。
10.步骤2、构建分类预测网络模型
11.s2.1、构建特征提取部分
12.使用5个rggblock残差模块代替yolov3网络中原有的5个残差块和下采样模块,构建轻量化的darkrggnet-44特征提取网络,网络结构依次为3x3卷积块conv0和5个rggblock残差模块;rggblock残差模块包括一个rggnet下采样残差单元块和多个rggnet残差单元,5个rggblock残差模块中rggnet残差单元的个数依次为1、2、2、2、1个。rggnet残差单元的结构为将输入的特征依次经过rgg module1、bn层、relu激活层、rgg module2和bn层后再与恒
等映射后的输入特征进行通道拼接操作;rggnet下采样残差单元块的结构为在rggnet残差单元的relu激活层后依次插入1个步长为2的深度可分离卷积、bn层和relu激活层。
13.其中,rgg module将通道数为c的输入特征图p
in
特征分离为通道数为εc的特征图p
rep
和通道数为(1-ε)c的特征图p
red
,再使用1x1的卷积块提取特征图p
red
的隐含细节信息,将其与使用group-ghost module提取p
rep
得到的重要信息进行通道拼接。group-ghost module将ghost module的本征特征图分为k组后先经过1x1的卷积块得到多样化的特征图后再进行一次ghost操作生成多个随机特征,再将随机特征与经过恒等映射的本征特征进行拼接。
14.s2.2、构建预测部分
15.将yolov3原fpn网络中52x52预测层和26x26预测层中的“concat+cbl*5”模块替换为cec模块,并将52x52预测层中cec模块的输出输入到26x26预测层的cec模块中。将26x26预测层的cec模块的输出与13x13预测层的cbl*5操作的输出一同输入到13x13预测层的cec模块后,再将结果与第5个rggblock残差模块的输出经过rfa模块后加权相加,再经过cbl和conv操作后作为13x13预测层的输出。
16.所述cec模块包括concat操作、esenet模块和cblx5操作;其中esenet模块的结构为:将输入的特征依次经过全局平均池化、全连接层和sigmoid操作将通道中的空间特征编码为1x1的全局特征,然后与恒等映射后的输入特征进行点加权操作,计算公式为:
[0017][0018]
其中f为输入特征图,σ为sigmoid函数,h、w分别为特征图高度和宽度,
·
表示加权相加,fc为全连接层操作。
[0019]
所述rfa模块通过自适应池化模块将尺度为s的输入特征图更改为不同尺度的n个上下文特征,然后通过1x1的卷积操作对n个不同尺度的上下文特征进行通道降维,再通过上采样模块将其统一放大到s尺度,最后通过asf模块进行空间融合后输出。
[0020]
所述asf模块的结构为:将输入的特征依次经过通道合并操作、1x1的卷积操作、3x3的卷积操作和通道分离操作后与恒等映射后的输入特征进行通道特征增强操作后输出。
[0021]
rfa模块的计算公式为:
[0022][0023]
其中f为输入特征图,a
i
为自适应尺度参数,表示通道特征增强操作,cu
n
表示对第n个特征图进行conv降维操作+upsa下采样操作,cat为通道拼接操作。
[0024]
步骤3、模型训练与优化
[0025]
向步骤2中构建的分类预测网络模型输入训练集进行迭代训练,并在每次迭代完成时进行验证,保存当前模型的权重文件与此前训练中最好的模型权重文件,使用adam算法对模型进行优化,当迭代次数为60、80、100或120时,进行学习率衰减,计算公式为:
[0026]
[0027]
其中α’表示衰减后的学习率,α表示初始学习率,r表示衰减率,epoch为当前训练的迭代次数,start表示开始进行学习率衰减的迭代次数,v表示衰减速度。
[0028]
训练达到设置的迭代次数时,结束训练,并保存最好的模型权重文件。
[0029]
作为优选,设置初始学习率α为0.01,衰减率r为0.9,衰减速度v为5。
[0030]
作为优选,设置的迭代次数为300次。
[0031]
步骤4、模型测试
[0032]
使用移动端机器人的摄像头对周围环境进行实时录像,通过步骤3训练优化好的分类预测网络模型对采集的视频帧图像进行分析,输出图像中人脸框的高度、宽度以及左上角坐标。
[0033]
步骤5、目标定位与人机交互
[0034]
采用trif-map方法将分类预测模型输出的人脸框位置信息转换为机器人坐标系信息,具体包括:
[0035]
s5.1、根据分类预测模型输出的人脸框位置信息确定目标中心点坐标(x,y)和宽度b
w
、高度b
h
;
[0036]
s5.2、获取目标的实际尺寸大小;
[0037]
s5.3、由trif-map方法,计算出目标实际位置偏离摄像头的偏航角θ
yaw
、俯仰角θ
pitch
以及距离ξ
dis
:
[0038][0039][0040][0041]
其中,f为机器人相机焦距。
[0042]
机器人根据上述计算结果,实时控制头部跟随人脸位置进行转动,实现人脸检测与人机交互。
[0043]
本发明具有以下有益效果:
[0044]
1、使用改进的轻量化yolov3网络代替原主干网络,从而减少网络计算量和浮点数,提高检测速度,满足交互的实时检测要求;
[0045]
2、在检测网络中引入通道注意力模块和残差特征增强模块,并在原三个预测层通过跨层级特征拼接产生新的预测层以提高多尺度检测网络的检测精度,满足精确检测的要求;
[0046]
3、采用trif-map算法将基于图像的人脸检测位置转换成机器人空间位置坐标,从而完成机器人端的人脸跟随检测,满足真实场景人机交互要求。
附图说明
[0047]
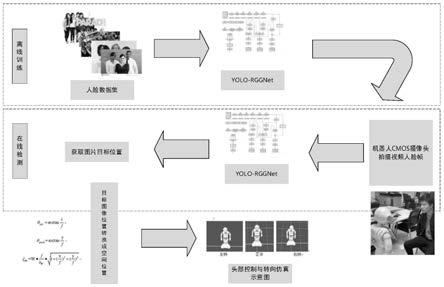
图1为本发明人脸检测与人机交互方法的流程框图。
[0048]
图2为特征提取网络中rggnet下采样残差单元和rggnet残差单元结构图。
[0049]
图3为预测网络中的通道注意力模块esenet和残差特征增强模块rfa结构图。
[0050]
图4为本发明构建的分类预测网络模型。
[0051]
图5为人脸图像位置信息转换成pepper机器人坐标系位置trif-map示意图。
[0052]
图6为实施例中相机坐标系下的pepper机器人响应人脸位置信息的动作示意图。
[0053]
图7为实施例中世界坐标系下的pepper机器人响应人脸位置信息的动作示意图。
具体实施方式
[0054]
以下结合附图对本发明作进一步的解释说明;
[0055]
基于yolo-rggnet的机器人端人脸检测方法,如图1所示,具体包括以下步骤:
[0056]
步骤1、建立数据集
[0057]
使用机器人拍摄自然场景,得到5000张包含人脸的图像,对这些图像进行几何变换、高斯模糊和亮度对比度随机调节,扩充至8000张,并按6:2的比例随机划分为训练集和验证集,使用标注工具labelimg标注图像中人脸框的高度、宽度以及左上角坐标,将标注后的json文件制作成txt格式的coco数据集,生成对应的lable文件。
[0058]
步骤2、构建分类预测网络模型
[0059]
s2.1、构建特征提取部分
[0060]
如图2所示,使用5个rggblock残差模块代替yolov3网络中原有的5个残差块和下采样模块,构建轻量化的darkrggnet-44特征提取网络,改善原网络训练复杂和识别速度慢的问题。改进后的特征提取网络结构为3x3卷积块conv0和5个rggblock残差模块;rggblock残差模块包括一个rggnet下采样残差单元块和多个rggnet残差单元,5个rggblock残差模块中rggnet残差单元的个数依次为1、2、2、2、1个。rggnet残差单元的结构为将输入的特征依次经过rgg module1、bn层、relu激活层、rgg module2和bn层后再与恒等映射后的输入特征进行通道拼接操作;rggnet下采样残差单元块的结构为在rggnet残差单元的relu激活层后依次插入1个步长为2的深度可分离卷积、bn层和relu激活层。其中,rgg module1模块用作扩展层,增加通道数量,rgg module2模块用于减少通道数量,使通道数与恒等映射路径匹配;rggnet下采样残差单元可以减少网络参数与计算量,并且提高模型训练与检测的速度。
[0061]
其中,rgg module将通道数为c的输入特征图p
in
特征分离为通道数为εc的特征图p
rep
和通道数为(1-ε)c的特征图p
red
,再使用1x1的卷积块提取特征图p
red
的隐含细节信息,将其与使用group-ghost module提取p
rep
得到的重要信息进行通道拼接。group-ghost module将ghost module的本征特征图分为k组后先经过1x1的卷积块得到多样化的特征图后再进行一次ghost操作生成多个随机特征,再将随机特征与经过恒等映射的本征特征进行拼接。
[0062]
s2.2、构建预测部分
[0063]
如图3所示,将yolov3原fpn网络中52x52预测层和26x26预测层中的“concat+cbl*5”模块替换为cec模块,并将52x52预测层中cec模块的输出输入到26x26预测层的cec模块中;将26x26预测层的cec模块的输出与13x13预测层的cbl*5操作的输出一同输入到13x13预测层的cec模块后,再将结果与第5个rggblock残差模块的输出经过rfa模块后加权相加,再经过cbl和conv操作后作为13x13预测层的输出;
[0064]
所述cec模块包括concat操作、esenet模块和cblx5操作;其中esenet模块将注意力机制融入fpn-ac检测网络中,在降低网络参数量的同时平衡语义特征的信息冗余,增强特征表达能力,提高网络精度,esenet模块将senet模块中的全连接层数量减少为一个,具体结构为:将输入的特征依次经过全局平均池化、全连接层和sigmoid操作将通道中的空间特征编码为1x1的全局特征,然后与恒等映射后的输入特征进行点加权操作,计算公式为:
[0065][0066]
其中f为输入特征图,σ为sigmoid函数,h、w分别为特征图高度和宽度,
·
表示加权相加,fc为全连接层操作。
[0067]
所述rfa模块是为了增强残差特征,以解决输出尺寸为13x13的预测分支由于特征通道的减少而导致的信息丢失问题,rfa模块通过自适应池化模块将尺度为s的输入特征图更改为不同尺度的n个上下文特征,然后通过1x1的卷积操作对n个不同尺度的上下文特征进行通道降维,再通过上采样模块将其统一放大到s尺度,最后通过asf模块进行空间融合后输出。
[0068]
所述asf模块的结构为:将输入的特征依次经过通道合并操作、1x1的卷积操作、3x3的卷积操作和通道分离操作后与恒等映射后的输入特征进行通道特征增强操作后输出。
[0069]
rfa模块的计算公式为:
[0070][0071]
其中f为输入特征图,a
i
为自适应尺度参数,表示通道特征增强操作,cu
n
表示对第n个特征图进行conv降维操作+upsa下采样操作,cat为通道拼接操作。
[0072]
步骤3、模型训练与优化
[0073]
如图4所示,向步骤2中构建的分类预测网络模型输入训练集进行迭代训练,每次迭代完成时进行验证,保存当前模型的权重文件与此前训练中最好的模型权重文件,使用adam算法对模型进行优化,当迭代次数达到80次时进行学习率衰减,计算公式为:
[0074][0075]
其中α’表示衰减后的学习率,epoch为当前训练的迭代次数,设置初始学习率α=0.01,衰减率r=0.9,衰减速度v=5。
[0076]
迭代训练300次后,结束训练与优化,保存最好的模型权重文件。
[0077]
步骤4、模型测试
[0078]
使用移动端机器人的摄像头对周围环境进行实时录像,通过步骤3训练优化好的分类预测网络模型对采集的视频帧图像进行分析,输出图像中人脸框的中心点坐标与左上角坐标。测试结果如下表所示:
[0079]
模型flops(b)weights(m)time-spent/msmap/%148.47249129.7780.52226.6211592.5684.78
329.18121103.3585.46431.32134114.4287.79
[0080]
其中模型1为yolov3网络模型,模型2为仅使用rggblock残差模块对yolov3进行改进的网络模型,模型3为本发明中仅在预测部分插入esenet模块和rfa模块的分类预测模型,模型4为本发明提出的分类预测网络模型;flops表示模型的浮点数,weights表示模型权重参数,time-spent表示检测一张图片耗费的时间,map表示检测平均正确率。
[0081]
由表中数据可以得到,本发明提出的分类预测网络模型,识别速度和准确率都优于改进前的yolov3网络,同时还具有稳定性好、抗干扰能力强、通用性高等优点。
[0082]
步骤5、目标定位与人机交互
[0083]
如图5所示,采用trif-map方法将分类预测模型输出的人脸框位置信息转换为机器人坐标系信息,具体包括:
[0084]
s5.1、根据分类预测模型输出的人脸框位置信息确定目标中心点坐标(x,y)和宽度b
w
、高度b
h
;
[0085]
s5.2、获取目标的实际尺寸大小h
fact
×
w
fact
;
[0086]
s5.3、由trif-map方法,计算出目标实际位置偏离摄像头的偏航角θ
yaw
、俯仰角θ
pitch
以及距离ξ
dis
:
[0087][0088][0089][0090]
其中,f为机器人相机焦距。
[0091]
机器人根据上述计算结果,实时控制头部跟随人脸位置进行转动,实现人脸检测与人机交互,如图6、7所示。
[0092]
上述具体实施方式用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明作出的任何修改和改变,都落入本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1