一种硬件代码生成和性能评估方法与流程
本发明属于嵌入式计算领域,涉及一种硬件代码生成和性能评估方法。
背景技术:
近年来随着航空机载处理系统等复杂嵌入式计算系统对于智能计算要求的不断提高,以深度神经网络为代表的人工智能算法逐步推广应用,例如用于智能图像目标分类的alexnet、vgg、mobilenet等卷积神经网络算法模型,用于智能目标检测的ssd、yolo、fastr-cnn等卷积神经网络算法模型,以及lstm、gru等循环神经网络模型。但是,复杂嵌入式计算系统面临着多种智能任务场景,例如图像识别、语音识别、目标定位、目标确认、决策控制等,需要在统一的嵌入式智能计算模块中能够运行多种深度神经网络智能算法,并且能够快速实现高层次算法模型在智能计算硬件模块的加载运行。目前,国内外推出的专用型智能计算芯片,例如海思的hi3559a、昇腾310等仅支持目标识别等图像类应用,而寒武纪mlu系列通用型智能计算芯片难以面向不同智能算法进行优化,在性能功耗方面还有待提高,另外目前智能计算芯片普遍存在指令集不成熟、开发工具软件使用不方便、难以开展准确性能评估等问题。嵌入式智能计算模块是包含fpga可编程硬件资源的嵌入式计算单元,能够通过将人工智能算法转化成硬件逻辑并在fpga内部配置,来实现对多种智能算法的支持,因此,它对于嵌入式智能计算系统的统型化、微型化、按需定义配置都具有重要意义。然而,目前还无法实现从高层次人工智能算法模型向硬件代码快速转换,以及开展人工智能算法在嵌入式智能计算模块的有效性能评估。
技术实现要素:
为了解决上述背景中提及的问题,本发明提供了一种硬件代码生成和性能评估方法,解决深度神经网络智能算法的快速硬件加载和性能评估问题,加快复杂嵌入式计算系统的人工智能算法设计部署,提升处理能力和资源利用率。
本申请提供一种硬件代码生成和性能评估方法,所述方法应用于嵌入式计算系统,所述嵌入式计算系统包括至少一个可配置的嵌入式智能计算模块,所述嵌入式智能计算模块内部包含fpga,所述fpga可配置至少两种深度神经网络算法类型;所述方法包括:
对深度神经网络算法模型的结构、数据类型、运算类型和处理流程进行分析,生成深度神经网络算法模型解析报告;
根据所述深度神经网络算法模型解析报告,在智能计算单元ip库中选择对应运算类型的智能计算单元ip,进行实例化并选择最优的互连网络结构;
将所述深度神经网络算法模型解析报告中所有运算,一一对应映射到所述智能计算单元ip的实例上;生成深度神经网络算法在嵌入式智能计算模块的硬件配置方案;
根据所述硬件配置方案,生成深度神经网络算法的可综合硬件代码,并通过硬件综合软件生成可加载到嵌入式智能计算模块的二进制文件;
以所述深度神经网络算法模型为测试基准,进行功能仿真和性能分析,获得性能分析报告和时序图。
优选的,所述深度神经网络算法模型解析报告包括:深度神经网络的算法类型;网络层数;每层的特征图数据格式、特征图、特征图数据位宽、参数数据格式、参数数据位宽;每层的运算类型;算法不同层之间的数据流向。
优选的,所述智能计算单元ip库,是面向深度神经网络算法运算类型的硬件可综合处理单元ip的集合,包括向量乘加、池化、激活函数、分类;每种ip单元的数据格式和数据位宽可配置;
所述互连网络结构,是根据不同智能计算单元ip实例之间数据流向选择的网络结构,包括点到点直连、共享总线、交叉开关、交换网络。
优选的,将所述深度神经网络算法模型解析报告中所有运算,一一对应映射到所述智能计算单元ip的实例上,具体包括:
采用一种多目标优化的任务-资源映射算法,包括遗传算法、粒子群算法、模拟退火算法、蚁群算法,优化目标包括嵌入式智能计算模块的处理时延最小、硬件资源消耗最小。
优选的,所述深度神经网络算法模型测试基准,包括用于智能图像目标分类的alexnet、vgg、mobilenet卷积神经网络算法模型;用于智能目标检测的ssd、yolo、fastr-cnn卷积神经网络算法模型,lstm、gru循环神经网络模型。
优选的,以所述深度神经网络算法模型为测试基准,进行功能仿真,具体包括:深度神经网络算法模型的硬件配置是否能够正常加载;嵌入式智能计算模块中fpga的逻辑资源数量是否满足深度神经网络算法模型配置需要;测试数据集是否能够正常输入;深度神经网络算法功能是否正常,所述深度神经网络算法功能包括目标识别、语音识别、任务决策;算法运行结果是否能够正常输出、显示;
优选的,以所述深度神经网络算法模型为测试基准,进行性能分析,具体包括:深度神经网络算法模型在嵌入式智能计算模块上的运行速度、平均准确率、占用fpga资源数量、功耗。
优选的,深度神经网络智能算法的类型包括卷积神经网络cnn和循环神经网络rnn。
本发明的优点在于:一种硬件代码生成和性能评估方法包括:深度神经网络的算法模型解析、智能计算单元ip实例化及互连网络结构选择、算法-智能计算单元ip映射及网络配置优化、可综合硬件代码生成、功能仿真和性能分析,能够支撑深度神经网络算法模型解析-硬件配置-硬件代码生成-功能仿真-性能分析整个流程,实现深度神经网络智能算法的快速硬件加载和性能评估,提升嵌入式智能计算系统的处理能力和资源利用率
附图说明
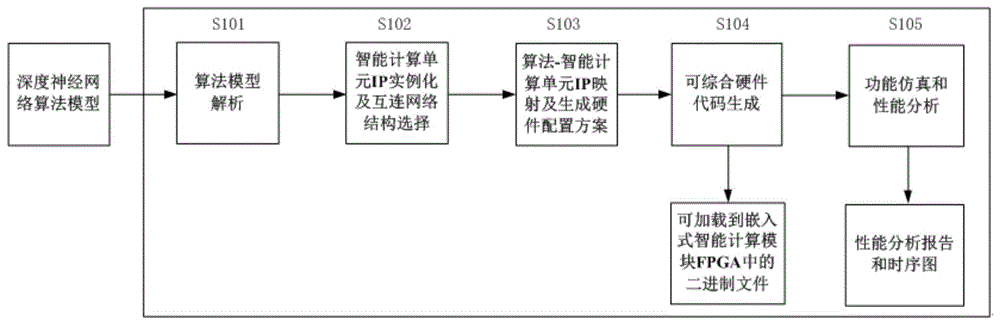
图1为本发明实施例提供的一种硬件代码生成和性能评估方法的流程示意图。
具体实施方式
实施例一
本发明实施例提供了一种硬件代码生成和性能评估方法,其特征在于,应用于嵌入式计算系统,所述嵌入式计算系统包括至少一个可配置的嵌入式智能计算模块;所述可配置的嵌入式智能计算模块,内部包含fpga可编程硬件资源,可以通过配置运行卷积神经网络cnn和循环神经网络rnn深度神经网络智能算法,可配置的智能算法类型至少两种;
所述硬件代码生成和性能评估方法包括以下步骤:
(1)深度神经网络的算法模型解析;
(2)智能计算单元ip实例化及互连网络结构选择;
(3)算法-智能计算单元ip映射及网络配置优化;
(4)可综合硬件代码生成;
(5)功能仿真和性能分析;
所述硬件代码生成和性能评估方法的输出包括:可加载到嵌入式智能计算模块fpga中的二进制文件、性能分析报告和时序图。
进一步的,所述深度神经网络的算法模型解析是对人工智能应用的深度神经网络算法模型的结构、数据类型、运算类型、处理流程进行分析,生成深度神经网络算法模型解析报告;
所述深度神经网络,包括:用于智能视频/图像目标识别的卷积神经网络,用于智能语音识别、智能决策控制的循环神经网络,以及其它应用场景自定义的深度神经网络;
所述深度神经网络算法模型,包括:基于caffe、tensorflow、pytorch开发框架的算法模型,以及用c、c++、python、matlab、java高层次编程语言编写的算法模型;
所述智能算法模型解析报告,包括:深度神经网络的算法类型;网络层数;每层的特征图数据格式、特征图数据位宽、参数数据格式、参数数据位宽;每层的运算类型;算法不同层之间的数据流向。
进一步的,所述智能计算单元ip实例化及互连网络结构选择是根据所述深度神经网络算法模型解析报告,在智能计算单元ip库中选择对应运算类型的智能计算单元ip,并按照特征图及参数数据格式和位宽进行实例化;并按照算法不同层之间的数据流向选择最优的互连网络结构;
所述智能计算单元ip库,是面向深度神经网络算法运算类型的硬件可综合的处理单元ip的集合,包括向量乘加、池化、激活函数、分类;每种智能计算单元ip的数据格式和数据位宽可配置;
所述互连结构,是根据不同智能计算单元ip实例之间数据流向选择的网络结构,包括点到点直连、共享总线、交叉开关、交换网络。
进一步的,所述算法-智能计算单元ip映射及网络配置优化是将所述深度神经网络算法模型解析报告中所有运算,一一对应映射到所述嵌入式智能计算单元ip实例上;并根据算法模型不同层之间数据流量对所述互连结构中节点间链路的带宽进行配置优化,生成深度神经网络算法在嵌入式智能计算模块的硬件配置方案;
所述算法-智能计算单元ip映射,采用一种多目标优化的任务-资源映射算法,包括遗传算法、粒子群算法、模拟退火算法、蚁群算法,优化目标包括嵌入式智能计算模块的处理时延最小、硬件资源消耗最小;
所述网络配置优化,是根据所述深度神经网络算法模型解析报告中不同层运算之间数据流量对智能计算单元ip链路的数据带宽配置优化,按照数据流量大小等比例配置链路带宽,保证不同智能计算单元ip之间的数据传输时延一致。
进一步的,所述可综合硬件代码生成是根据深度神经网络算法的硬件配置方案,生成深度神经网络算法的可综合硬件代码,并通过硬件综合软件生成可加载到嵌入式智能计算模块的二进制文件;
进一步的,所述功能仿真和性能分析是以深度神经网络算法模型为测试基准的开展的仿真分析;
所述深度神经网络算法模型测试基准,包括用于智能图像目标分类的alexnet、vgg、mobilenet卷积神经网络算法模型,用于智能目标检测的ssd、yolo、fastr-cnn卷积神经网络算法模型,lstm、gru循环神经网络模型,以及其它自定义的深度神经网络算法模型;
所述功能仿真是对深度神经网络算法模型在嵌入式智能计算模块上运行的功能性验证,包括:深度神经网络算法模型的硬件配置是否能够正常加载;嵌入式智能计算模块中fpga的逻辑资源数量是否满足深度神经网络算法模型配置需要;测试数据集是否能够正常输入;深度神经网络算法功能是否正常,如目标识别、语音识别、任务决策功能;算法运行结果是否能够正常输出、显示;
所述性能分析是对深度神经网络算法模型在嵌入式智能计算模块上运行的性能和时序进行分析,包括:深度神经网络算法模型在嵌入式智能计算模块上的运行速度、平均准确率、占用fpga资源数量、功耗。
实施例二
以下结合附图对本发明进行详述。
参见图1,为本发明实施例提供的一种硬件代码生成和性能评估方法的流程示意图,所述方法主要包括:
s101,深度神经网络的算法模型解析,解析深度神经网络算法模型的结构、数据类型、运算类型、处理流程,生成深度神经网络算法模型解析报告;
s102,智能计算单元ip实例化及互连网络结构选择,首先根据深度神经网络算法模型解析报告,在智能计算单元ip库中选择对应运算类型的智能计算单元ip,并按照特征图及参数数据格式和位宽进行实例化,然后按照算法不同层之间的数据流向选择最优的互连网络结构;
s103,算法-智能计算单元ip映射及网络配置优化,首先将深度神经网络算法模型解析报告中所有运算,一一对应映射到嵌入式智能计算单元ip实例上,然后根据算法模型不同层之间数据流量对互连结构中节点间链路的带宽进行配置优化,生成深度神经网络算法在嵌入式智能计算模块的硬件配置方案;
s104,可综合硬件代码生成,根据深度神经网络算法的硬件配置方案,生成深度神经网络算法的可综合硬件代码,并通过硬件综合软件生成可加载到嵌入式智能计算模块的二进制文件;
s105,嵌入式智能计算模块的功能仿真和性能分析,首先验证深度神经网络算法模型的硬件配置是否能够正常加载,嵌入式智能计算模块中fpga的逻辑资源数量是否满足深度神经网络算法模型配置需要,测试数据集是否能够正常输入,深度神经网络算法功能是否正常,算法运行结果是否能够正常输出、显示功能,然后分析深度神经网络算法模型在嵌入式智能计算模块上的运行速度、平均准确率、占用fpga资源数量、功耗性能指标。
本发明提供一种硬件代码生成和性能评估方法,属于嵌入式计算领域。方法包括:深度神经网络的算法模型解析、智能计算单元ip实例化及互连网络结构选择、算法-智能计算单元ip映射及网络配置优化、可综合硬件代码生成、功能仿真和性能分析。该方法支持的输入包括卷积神经网络cnn和循环神经网络rnn深度神经网络算法模型,能够生成深度神经网络算法可加载到嵌入式智能计算模块中fpga的二进制文件,以及在嵌入式智能计算模块运行的性能分析报告和时序图。通过在嵌入式智能计算模块实现多种深度神经网络智能算法的硬件代码生成和性能评估,可加快航空机载计算机等复杂嵌入式计算系统的人工智能算法设计部署,提升嵌入式智能计算模块的处理能力和资源利用率。
以上所述,仅为本公开的具体实施方式,但本公开的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本公开揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本公开的保护范围之内。因此,未公开的保护范围应以权利要求的保护范围为主。
- 还没有人留言评论。精彩留言会获得点赞!