一种高效通信且保护隐私的个性化联邦学习方法
1.本发明涉及联邦学习技术领域,更具体的,涉及一种高效通信且保护隐私的个性化联邦学习方法。
背景技术:
2.机器学习在计算机视觉,语音识别和自然语言处理等领域取得了巨大成就。为了利用海量数据完成大规模机器学习训练任务,分布式机器学习被提出并引起广泛关注。联邦学习是一种新型的分布式机器学习方式。在联邦学习中,由于中央中央服务器利用联邦平均(fedavg)算法来聚合来自各个客户端的模型更新,参与联邦训练的各方在训练结束后得到的是一个统一的全局模型。现有的联邦学习算法大多关注的是提升联邦学习的全局模型效果。然而在联邦环境中,众多客户端上的自有数据往往是非独立同分布的,这样训练得到的全局模型很难适配每一个客户端,也就是说,全局模型很可能还不如单独客户端训练得到的模型表现出色。这样联合客户端训练的联邦学习将失去意义。因此个性化联邦学习是十分必要的。然而现有的个性化联邦学习方法仅强调个性化客户端模型的重要性,没有实现个性化客户端本地模型与全局模型的平衡,导致全局模型效果损失明显。
3.现有技术中,如2020年08月28日公开的中国专利,一种在隐私保护下的去中心化联邦机器学习方法,公开号为cn111600707a,解决了现有联邦学习易受dos攻击、参数中央服务器单点故障等缺点;结合pvss可验证秘密分发协议保护参与者模型参数免受模型反演攻击、数据成员推理攻击。同时保证了在每一次训练任务由不同的参与者来进行参数聚合,当出现不信任的聚合者或者其遭受攻击时,可自行恢复正常,增加了联邦学习的鲁棒性;同时还保证了联邦学习的性能,有效地改善了联邦学习的安全训练环境,但没有实现个性化客户端本地模型与全局模型的平衡。
技术实现要素:
4.本发明为克服现有的个性化联邦学习方法没有实现个性化客户端本地模型与全局模型的平衡的技术缺陷,提供一种高效通信且保护隐私的个性化联邦学习方法。
5.为解决上述技术问题,本发明的技术方案如下:
6.一种高效通信且保护隐私的个性化联邦学习方法,包括以下步骤:
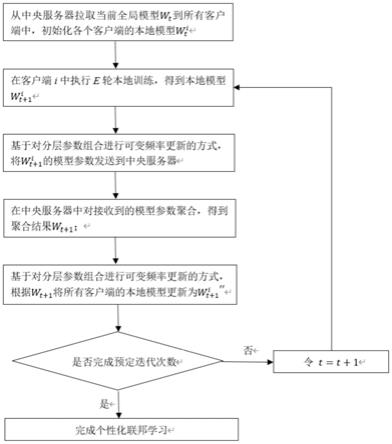
7.s1:从中央服务器拉取当前全局模型w
t
到所有客户端中,初始化各个客户端的本地模型其中,i为客户端序号,t为当前个性化联邦学习的轮数;
8.s2:在客户端i中执行e轮本地训练,得到新的本地模型
9.s3:基于对分层参数组合进行可变频率更新的方式,将的模型参数发送到中央服务器;
10.s4:在中央服务器中对接收到的模型参数聚合,得到聚合结果w
t+1
;
11.s5:基于对分层参数组合进行可变频率更新的方式,根据w
t+1
将所有客户端的本地
模型更新为
12.s6:判断是否完成预定迭代次数;
13.若是,则完成个性化联邦学习;
14.若否,则令t=t+1,并返回步骤s2进行下一轮个性化联邦学习。
15.优选的,在步骤s2中,每轮个性化联邦学习中只选取k个客户端执行本地训练;其中,客户端总个数为k,k在k中的占比为c。
16.优选的,在步骤s2中,依照预先设定的数据批大小b将客户端i上的数据分成个批次,并设为集合
17.对于根据以下公式执行本地训练,得到本地模型
[0018][0019]
其中,n
i
为客户端i上的数据量,b
i
为集合中的元素,为客户端i上执行本地训练前的模型参数,η为学习率,l为客户端上的损失函数。
[0020]
优选的,当个性化联邦学习的训练对象为深度神经网络模型时,将深度神经网络模型视作全局层和个性化层的组合;
[0021]
其中,将深度神经网络模型的浅层网络部分定义为全局层,负责提取客户端数据的全局特征;将深度神经网络模型的深层网络部分定义为个性化层,负责捕获客户端数据的个性化特征。
[0022]
优选的,在步骤s3中,对分层参数组合进行可变频率更新的方式具体包括:
[0023]
若当前处于个性化联邦学习的早期,即0<t≤t*p,且t%f
earlier
≠0时或者当前处于个性化联邦学习的后期,即t*p<t≤t,且t%f
latet
≠0时,则只将浅层部分的模型参数发送到中央服务器;
[0024]
若当前处于个性化联邦学习的早期,即0<t≤t*p,且t%f
earlier
=0时或者当前处于个性化联邦学习的后期,即t*p<t≤t,且t%f
later
=0时,则将所有层的模型参数发送至中央服务器;
[0025]
其中,t为个性化联邦学习的当前轮数,t为个性化联邦学习的总轮数,p为个性化联邦学习前期的轮数占比,f
earlier
为个性化联邦学习前期发送所有层的模型参数至中央服务器的周期,f
later
为个性化联邦学习后期发送所有层的模型参数至中央服务器的周期。
[0026]
优选的,还包括:对从客户端发往中央服务器的模型参数添加高斯噪声。
[0027]
优选的,在客户端i中按照以下公式只将浅层部分的模型参数发送到中央服务器,并添加高斯噪声:
[0028][0029]
其中,为从客户端i发送到中央服务器的模型参数;m为掩蔽矩阵,用于掩蔽深层参数参与聚合;dp∈(0,1],用于控制噪声的影响程度;rn~n(0,σ2),即rn服从均值为0,方差为σ2的正态分布。
[0030]
优选的,在客户端i中按照以下公式将所有层的模型参数发送至中央服务器,并添加高斯噪声:
[0031][0032]
其中,为从客户端i发送到中央服务器的模型参数;dp∈(0,1],用于控制噪声的影响程度;rn~n(0,σ2),即rn服从均值为0,方差为σ2的正态分布。
[0033]
优选的,个性化联邦学习中客户端在前期发送所有层的模型参数至服务器的频率要高于后期发送的频率,即
[0034]
优选的,在步骤s4中,
[0035]
在每轮个性化联邦学习中通过以下公式对中央服务器接收到的模型参数进行聚合操作,得到聚合结果w
t+1
:
[0036][0037]
其中,k为客户端的总个数,c为每轮参与个性化联邦学习的客户端占比,n
i
为客户端i上的数据量,n为每轮参与个性化联邦学习的全部客户端上的数据量,为发送到中央服务器的模型参数。
[0038]
与现有技术相比,本发明技术方案的有益效果是:
[0039]
本发明提供了一种高效通信且保护隐私的个性化联邦学习方法,基于对分层参数组合进行可变频率更新的方式进行个性化联邦学习,能够有效实现全局模型和个性化模型的平衡;同时,能够减少个性化联邦学习中的参数通信量,实现轻便高效的通信效率。
附图说明
[0040]
图1为本发明的技术方案实施步骤流程示意图;
[0041]
图2为本发明中采用深度神经网络模型进行图像分类任务的示意图;
[0042]
图3为本发明中个性化联邦学习的可变频率示意图;
[0043]
图4为本发明中个性化联邦学习的分层参数示意图。
具体实施方式
[0044]
附图仅用于示例性说明,不能理解为对本专利的限制;
[0045]
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
[0046]
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
[0047]
下面结合附图和实施例对本发明的技术方案做进一步的说明。
[0048]
实施例1
[0049]
如图1所示,一种高效通信且保护隐私的个性化联邦学习方法,包括以下步骤:
[0050]
s1:从中央服务器拉取当前全局模型w
t
到所有客户端中,初始化各个客户端的本地模型其中,i为客户端序号,t为当前个性化联邦学习的轮数;
[0051]
s2:在客户端i中执行e轮本地训练,得到新的本地模型
[0052]
s3:基于对分层参数组合进行可变频率更新的方式,将的模型参数发送到中
央服务器;
[0053]
s4:在中央服务器中对接收到的模型参数聚合,得到聚合结果w
t+1
;
[0054]
s5:基于对分层参数组合进行可变频率更新的方式,根据w
t+1
将所有客户端的本地模型更新为
[0055]
s6:判断是否完成预定迭代次数;
[0056]
若是,则完成个性化联邦学习;
[0057]
若否,则令t=t+1,并返回步骤s2进行下一轮个性化联邦学习。
[0058]
更具体的,在步骤s2中,每轮个性化联邦学习中只选取k个客户端执行本地训练;其中,客户端总个数为k,k在k中的占比为c。
[0059]
在具体实施过程中,考虑到客户端与中央服务器通信的带宽与延迟限制,每次在k个客户端中选择占比为c的客户端,构成集合st参与当前第t轮的个性化联邦学习。被选中的客户端需要完成预先设定轮数e的本地训练。
[0060]
更具体的,在步骤s2中,依照预先设定的数据批大小b将客户端i上的数据分成个批次,并设为集合
[0061]
对于根据以下公式执行本地训练,得到本地模型
[0062][0063]
其中,n
i
为客户端i上的数据量,b
i
为集合中的元素,为客户端i上执行本地训练前的模型参数,η为学习率,l为客户端上的损失函数。
[0064]
更具体的,当个性化联邦学习的训练对象为深度神经网络模型时,以采用深度神经网络模型进行图像分类任务为例:图像中包含的普遍且一般性的特征通常由深度神经网络模型的浅层网络部分捕获,而更高级且特有的特征则由深层网络部分识别。如图2所示,靠近输入图片的浅层网络部分提取的往往是低阶特征,靠近输出的深层网络部分提取的是高阶特征。在个性化联邦学习中,根据全局模型与客户端本地模型的定义:全局模型主要关注于客户端上数据的普遍低阶特征,本地模型则主要聚焦于客户端上数据的特有高阶特征。因此我们将用于个性化联邦学习的深度神经网络模型视作全局模型和个性化模型的组合,其中将深度神经网络模型的浅层网络部分定义为全局层,深层网络部分定义为个性化层。
[0065]
更具体的,在步骤s3中,对分层参数组合进行可变频率更新的方式具体包括:
[0066]
若当前处于个性化联邦学习的早期,即0<t≤t*p,且t%f
earlier
≠0时或者当前处于个性化联邦学习的后期,即t*p<t≤t,且t%f
later
≠0时,则只将浅层部分的模型参数发送到中央服务器;
[0067]
若当前处于个性化联邦学习的早期,即0<t≤t*p,且t%f
earlier
=0时或者当前处于个性化联邦学习的后期,即t*p<t≤t,且t%f
later
=0时,则将所有层的模型参数发送至中央服务器;
[0068]
其中,t为个性化联邦学习的当前轮数,t为个性化联邦学习的总轮数,p为个性化联邦学习前期的轮数占比,f
earlier
为个性化联邦学习前期发送所有层的模型参数至中央服务器的周期,f
later
为个性化联邦学习后期发送所有层的模型参数至中央服务器的周期。
[0069]
在具体实施过程中,如图3
‑
4所示,采用基于可变频率的分层参数方式进行个性化联邦学习,在个性化联邦学习的前后期,只有当t%f
earlier
=0或t%f
later
=0时,客户端才会发送模型的所有层参数至中央服务器。而在其他情况下,客户端对深层参数进行掩蔽,仅发送浅层参数至中央服务器,通信量明显下降,有效降低通信代价。在图3中,个性化联邦学习在前期的更新周期设为4,后期的更新周期设为8。即在前期,每4轮执行一次所有层参数的聚合平均;在后期,每8轮执行一次所有层参数的聚合平均。
[0070]
更具体的,还包括:对从客户端发往中央服务器的模型参数添加高斯噪声。
[0071]
在具体实施过程中,基于差分隐私按层为客户端发往中央服务器的模型参数中添加高斯噪声,对真实参数进行加密,进一步地保护客户端隐私。
[0072]
更具体的,在客户端i中按照以下公式只将浅层部分的模型参数发送到中央服务器,并添加高斯噪声:
[0073][0074]
其中,为从客户端i发送到中央服务器的模型参数;m为掩蔽矩阵,用于掩蔽深层参数参与聚合;dp∈(0,1],用于控制噪声的影响程度;rn~n(0,σ2),即rn服从均值为0,方差为σ2的正态分布。
[0075]
更具体的,在客户端i中按照以下公式将所有层的模型参数发送至中央服务器,并添加高斯噪声:
[0076][0077]
其中,为从客户端i发送到中央服务器的模型参数;dp∈(0,1],用于控制噪声的影响程度;rn~n(0,σ2),即rn服从均值为0,方差为σ2的正态分布。
[0078]
更具体的,个性化联邦学习中客户端在前期发送所有层的模型参数至服务器的频率要高于后期发送的频率,即
[0079]
在具体实施过程中,按照累积学习策略,在个性化联邦学习的前期,重心是提取客户端上的全局特征;在个性化联邦学习的后期,重心是个性化客户端上的本地模型。因此在本实施例中,个性化联邦学习后期的所有层参数聚合频率要低于前期,以便客户端上的本地模型具备个性化的能力,从而平衡个性化联邦学习中的全局模型和个性化模型的效果。
[0080]
更具体的,在步骤s4中,
[0081]
在每轮个性化联邦学习中通过以下公式对中央服务器接收到的模型参数进行聚合操作,得到聚合结果w
t+1
:
[0082][0083]
其中,k为客户端的总个数,c为每轮参与个性化联邦学习的客户端占比,n
i
为客户端i上的数据量,n为每轮参与个性化联邦学习的全部客户端上的数据量,为发送到中央服务器的模型参数。
[0084]
在具体实施过程中,当0<t≤t*p且t%f
earlier
≠0时或t*p<t≤t且t%f
later
≠0时,客户端仅发送深度神经网络模型浅层部分的参数进行所有层参数聚合,因此在中央服务器
执行操作后,在步骤s5中各客户端也仅需更新本地模型浅层部分的参数,保持深层部分参数不变,即客户端上个性化层的参数只取决于自身数据。而当0<t≤t*p且t%f
earlier
=0时或t*p<t≤t且t%f
later
=0时,客户端发送了网络模型的所有参数至中央服务器,中央服务器按照前后期不同的预设周期(f
earlier
和f
later
)对其执行周期性的聚合平均,在步骤s5中各客户端将需要更新所有层的参数。
[0085]
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1