农田氮径流量估算方法、装置、计算机设备及存储介质与流程
本发明涉及环境保护领域,尤其涉及一种农田氮径流量估算方法、装置、计算机设备及存储介质。
背景技术:
近年来我国由于化肥的大量施用,导致田间氮素盈余量不断增加,过量盈余的氮素对周边水体富营养化产生了很大风险,对其径流量的准确估算是减排的先决条件。然而,现有的农田氮径流量估算方法通常是基于以下公式计算得到:
runoff=rr×nrate+r0(1)
rr=(runoff-r0)/nrate(2)
其中,runoff为单位面积农田氮径流量、rr为肥料氮径流率、nrate为施氮强度、r0为背景氮流失量,即不施肥情况下农田氮径流量。
上述公式(1)和(2)在大尺度区域农田氮径流量的核算结果存在很大的不确定性,不仅难以体现空间上的差异性和年际间的波动性,且默认runoff与nrate之间是一种线性的响应关系,因此可能会导致在施氮量高值和低值区域的核算结果有偏差。
技术实现要素:
本发明实施例提供一种农田氮径流量估算方法、装置、计算机设备及存储介质,以提高对农田的氮径流量估算的准确度。
本发明实施例提供一种农田氮径流量估算方法,用于对大尺度研究区域的农田氮径流量进行估算,包括:
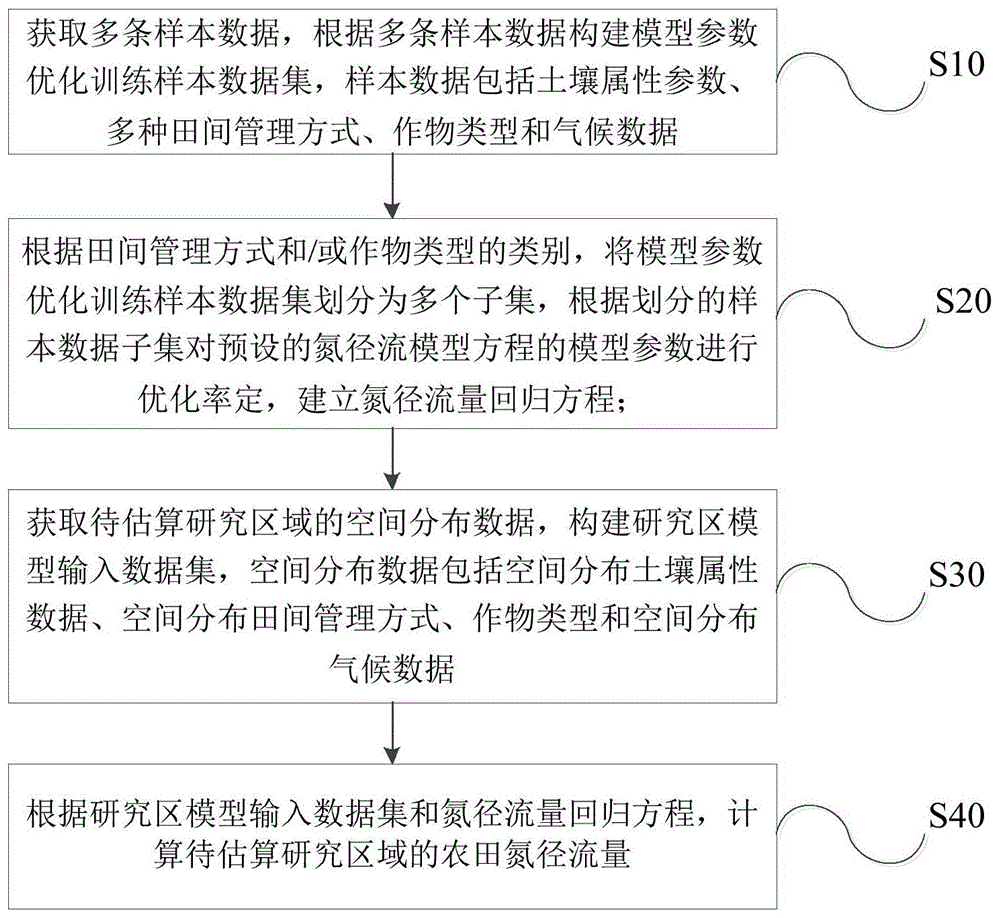
获取多条样本数据,根据多条样本数据构建模型参数优化训练样本数据集,样本数据包括土壤属性参数、多种田间管理方式、作物类型和气候数据;
根据田间管理方式和/或作物类型的类别,将模型参数优化训练样本数据集划分为多个子集,根据划分的样本数据子集对预设的氮径流模型方程的模型参数进行优化率定,建立氮径流量回归方程;
获取待估算研究区域的空间分布数据,构建研究区模型输入数据集,所述空间分布数据包括空间分布土壤属性数据、空间分布田间管理方式、作物类型和空间分布气候数据;
根据研究区模型输入数据集和氮径流量回归方程,计算待估算研究区域的农田氮径流量。
优选地,所述样本数据还包括氮径流率和背景氮流失量,所述根据所述田间管理方式的种类和/或所述作物类型,将所述样本数据划分为多个子集,包括:
分析不同的所述田间管理方式和/或所述作物类型对应的氮径流率和/或背景氮流失量的差异,并将所述氮径流率和/或背景氮流失量的差异大于预设值的所述田间管理方式或所述作物类型作为分类变量;
根据所述分类变量,采用决策树模型将所述样本数据分为多个子集,每个子集对应所述分类变量的不同区间范围。
优选地,所述土壤属性参数包括多种土壤属性参数,所述气候参数包括多种气候参数,所述根据划分的样本数据子集对预设的氮径流模型方程的模型参数进行优化率定,包括:
根据所述样本数据子集对所述土壤属性参数和气候参数进行共线性诊断分析和显著性分析,从中剔除共线性大于预设值,且显著性小于预设值的变量,得到各子集对应模型回归方程的自变量;
采用全局优化算法分别对所述氮径流的参数进行优化率定,得到所述氮径流量回归方程。
优选地,所述采用全局优化算法分别对所述氮径流的参数进行优化率定,得到所述氮径流量回归方程,包括:
采用全局优化算法对所述样本土壤属性参数和所述样本气候参数进行优化率定,得到背景氮流失量率定参数;根据所述背景氮流失量率定参数建立背景氮流失量回归方程;
采用全局优化算法对所述样本土壤属性参数、样本气候参数及田间管理方式进行优化率定,得到氮径流率率定参数;根据所述氮径流率率定参数建立氮径流率回归方程;
根据所述背景氮流失量回归方程及氮径流率回归方程确定所述氮径流量回归方程。
优选地,所述根据研究区模型输入数据集和氮径流量回归方程,计算待估算研究区域的农田氮径流量,包括:
将所述空间分布土壤属性数据、所述空间分布气候数据输入到所述背景氮流失量回归方程中,计算所述研究区域的背景氮流失量;
将所述空间分布土壤属性数据、所述空间分布气候数据及空间分布田间管理方式输入到对应的所述氮径流率回归方程中,计算所述研究区域的氮径流率;
根据所述研究区域的背景氮流失量、氮径流率,采用以下计算式计算所述研究区域的氮径流量:
runoff=rr×nrate+r0
其中,runoff为所述研究区域的氮径流量,rr为所述研究区域的氮径流率,r0为所述研究区域的背景氮流失量,nrate为预设的施氮强度。
优选地,采用配对样本t检验,分析不同的所述田间管理方式,和所述作物类型参数的对应的氮径流率的差异。
优选地,所述氮径流模型方程包括:
氮径流率方程:rr=[σ(α·x)+a]·nrate+[σ(β·x)+b];
背景氮流失量方程:r0=σ(γ·x)+c;
其中,所述rr为氮径流率,所述r0为背景氮流失量,所述α,β,γ,a,b,c均为常数项,所述x为影响氮径流量的因子,所述nrate为施氮强度。
本发明实施例还提供一种农田氮径流量估算装置,用于对研究区域的氮径流量进行估算,所述氮径流量估算装置包括:样本数据获取单元、回归方程建立单元、空间分布数据获取单元和计算单元;
所述样本数据获取单元用于获取多条样本数据,根据多条样本数据构建模型参数优化训练样本数据集,样本数据包括土壤属性参数、多种田间管理方式、作物类型和气候数据;
所述回归方程建立单元用于根据田间管理方式和/或作物类型的类别,将模型参数优化训练样本数据集划分为多个子集,根据划分的样本数据子集对预设的氮径流模型方程的模型参数进行优化率定,建立氮径流量回归方程;
所述空间分布数据获取单元用于获取待估算研究区域的空间分布数据,构建研究区模型输入数据集,所述空间分布数据包括空间分布土壤属性数据、空间分布田间管理方式、作物类型和空间分布气候数据;
所述计算单元用于根据研究区模型输入数据集和氮径流量回归方程,计算待估算研究区域的农田氮径流量。
本发明实施例还提供一种计算机设备,包括存储器和处理器,所述存储器中存储有氮径流估算程序,所述处理器用于执行上述氮径流估算程序时实现上述农田氮径流量估算方法的步骤。
本发明实施例还提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述农田氮径流量估算方法的步骤。
本发明实施例的氮径流量估算方法、装置、计算机设备及存储介质考虑了氮径流量与施氮量之间的非线性响应关系,构建了氮径流率回归方程,使得在施氮量高值和低值区域也能较为准确的核算农田氮径流量。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对本发明实施例的描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1是本发明一实施例中氮径流量估算方法的流程图;
图2是采用配对样本t检验方法对氮径流率进行差异性分析的分析图;
图3是本发明实施例中的研究区域示意图;
图4是本发明实施例对背景氮流失量进行差异性分析的分析图;
图5是本发明实施例中氮肥施用强度空间分布示意图;
图6是本发明实施例中计算氮径流量的空间分布结果示意图;
图7a是采用本发明实施例的氮径流量估算方法的计算结果的示意图;
图7b及图7c是采用现有方案计算的氮径流量的计算结果的示意图;
图8是本发明一实施例中氮径流量估算装置的原理框图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在本发明的描述中,需要说明的是,术语“第一”、“第二”、“第三”等仅用于区分描述,而不能理解为指示或暗示相对重要性。
本发明实施例提出一种农田氮径流量估算方法,用于对研究区域的农田、坡地的等耕作地的氮径流量进行估算。本发明实施例将结合具体的实验过程,进行说明。具体地,如图1所示,该方法包括以下步骤:
s10:获取多条样本数据,根据多条样本数据构建模型参数优化训练样本数据集,样本数据包括土壤属性参数、多种田间管理方式、作物类型和气候数据。
具体地,在进行氮径流量估算之前,需要先构建好氮径流量估算的模型。由于农田氮径流量runoff是由肥料氮径流量(rr×nrate)和r0共同决定的,因此本发明实施例考虑runoff与nrate之间的非线性响应关系,并结合气候、土壤属性和田间管理方式等变量的影响,建立了如式(3)-(7)所示的氮径流模型方程:
δrrj(xk)=σ(αkj·xk)+aj,(5)
对上述公式进行整理计算,得到:
runoffj=[σ(αkj·xk)+aj]·nrate2+[σ(βkj·xk)+bj]·nrate+σ(γkj·xk)+cj(8)
其中,公式(3)-(8)中各个参数的含义为:
j:模型方程个数,不同方程表示runoff与nrate响应关系存在空间异质性;
δrr:氮径流率对施氮强度的一阶导数,δrr=drr/dnrate;rr0:农田总氮流失量对施氮强度的一阶导数,指当施氮强度为0时的初始rr;x:指除施氮量外影响runoff的其他因子,如,降水量、灌溉量、气温、土壤总氮含量、土壤粘粒含量、土壤有机质含量、土壤ph和田间管理方式等;k:模型除施氮量外影响因素的个数;α,β,γ,a,b,c:常数项。
在本实施例中,样本数据是指实验地的农田氮径流实验数据,样本数据包括土壤属性参数、多种田间管理方式、作物类型参数、气候参数、氮径流率、背景氮流失量等。需要说明的是,上述样本数据中的背景氮流失量是指实验地未施肥情况下的氮径流量,具体可以通过从样本数据中筛选出未施肥的实验数据,并将其氮径流量作为背景氮流失量。
上述样本数据可以通过查阅文献,刊物等方式获得。具体地,每一条样本数据的参数类型可如表1所示。需要说明的是,由于样本数据是从不同学者发表的文献或刊文中获取的,那么可能会存在实验方法、监测指标不一致等问题,导致部分指标缺失。如果是样本土壤属性缺失,那么可根据实验地的经纬度从“中国土壤数据库”找到对应的市县,查找相应的土种,补充缺失的指标。如果是气候参数缺失,例如气温和降雨量等,则可根据实验地点和时间,从中国气象数据共享网找到最邻近气象站点,近似替代实验点的状况,补充缺失的气象数据。如果是田间管理方式缺失,则可从此实验地点相近的相似文献或者通过调查等方式补充。
表1数据指标体系
如上表1所示,土壤属性参数可以包括总氮含量、有机质含量、粘粒含量、总磷含量、有效磷含量、容重、ph等,田间管理方式包括肥料类型、施肥方式、施肥次数、灌溉方式、耕作方式等,气候参数包括气温、降雨量等。各种不同的数据均对应有不同的参数值,如田间管理方式中,肥料类型可以有尿素、碳酸氢铵、有机肥、有机无机配施等。作物类型可以有水稻、玉米、柑橘、蔬菜类等,示例性地,样本数据可如附表1和附表2所示。
s20:根据田间管理方式和/或作物类型的类别,将模型参数优化训练样本数据集划分为多个子集,根据划分的样本数据子集分别对预设的氮径流模型方程的模型参数进行优化率定,建立氮径流量回归方程。
示例性地,如上述表1所示,田间管理方式的种类有:肥料类型、施肥方式、灌溉方式和耕作方式等,按照田间管理方式的种类,对样本数据进行分类。例如,根据田间管理方式的种类——肥料类型,将样本数据划分为两类——“有机无机配施”一类,其他肥料为一类。需要说明的是,上述样本数据的划分不限定于根据肥料类型划分,还可以根据施肥方式、作物类型等划分这里不进行具体限定,还可以根据作物类型参数进行划分,例如,根据作物类型,将样本数据划分为蔬菜类、柑橘类、玉米类、水稻类等。
上述步骤s20列举出了多种对样本数据所对应的条件进行分类的实施方式,在一个可选的实施方式中,可以根据不同类别的样本数据的氮径流率和/或背景氮流失量的差异确定出如何对样本数据所对应的条件进行分类:
s21:分析不同的田间管理方式和/或作物类型的对应的氮径流率和/或背景氮流失量的差异,并将氮径流率和/或背景氮流失量的差异大于预设值的田间管理方式或作物类型作为分类变量。
示例性地,在步骤s21中,可以以田间管理方式的种类和作物类型为依据,将所有样本数据划分为多个样本子集,例如,根据施肥次数(1次、2次)将所有样本数据划分为两类、根据施肥方式(撒施、深施)将所有样本数据划分为两类、根据肥料类型(有机无机配施、复合肥和尿素)将所有样本数据划分为两类、根据作物类型参数(水稻、玉米、柑橘、蔬菜类和其它)将所有样本数据划分为多个子集,接着采用配对样本t检验,分析不同类别下的样本数据中的氮径流率和/或背景氮流失量的差异,若该类别的样本数据中的氮径流率和/或背景氮流失量相较于其他类别,具有显著性差异(也即差异大于预设值),则将该类别作为分类变量,以便进行后续的分类。
示例性地,如图2所示,经过配对样本t检验可知,类别为肥料类型(有机无机配施、复合肥、尿素)的对应的氮径流率具有显著性差异,因此将肥料类型作为分类变量。
s22:根据分类变量,采用决策树模型将样本数据所对应的条件分为多个子集,每个子集对应分类变量的不同区间范围。
以上述分类变量为肥料类型为例,采用决策树模型将所有样本数据进行分类,以将样本数据划分为与肥料类型相关的两类数据——“有机无机配施”分为一类,“复合肥”和“尿素”分为另一类。上述决策树模型可以是决策树cart算法。
由于在寻找田间管理和作物类型等的分类结点时,采用人工分类的方法,主观性太大,往往不能找到最优的分节点。决策树模型通过对象的特征来预测对象所属的类别,能处理其它算法不能处理的非数值型数据,大大提高了模型预测的精度。
通过上述过程,将模型参数优化训练样本数据集进行分类后,根据划分的样本数据子集对预设的氮径流模型方程的模型参数进行优化率定,建立每类所述样本数据对应的氮径流率回归方程,具体过程包括:
以上述类别为“有机无机配施”,以及“复合肥”和“尿素”的样本数据为例,将“有机无机配施”对应的土壤属性参数和气候参数进行优化率定,得到氮径流量模型方程氮径流率率定参数,也即得到公式(5)和公式(6):中的[σ(αkj·xk)+aj]和[σ(βkj·xk)+bj]。
具体地,可采用全局最优算法(shuffledcomplexevolution-ua,sce-ua)来对土壤属性参数和气候参数进行优化率定。由于土壤属性参数中包含了多种土壤属性参数,气候参数包含了多种气候参数,但是并非每一参数都会对氮径流量的计算产生影响,因此,在使用全局最优算法进行优化率定之前,需要对土壤属性参数和气候参数进行筛选。
具体地,根据分类后的模型参数优化训练样本数据集对预设的氮径流模型方程的模型参数进行优化率定,建立每类所述样本数据对应的氮径流率回归方程可包括以下步骤:
s23:根据样本数据子集对土壤属性参数和气候参数进行共线性诊断分析和显著性分析,从中剔除共线性大于预设值,且显著性小于预设值的土壤属性参数和/或气候参数,得到各子集对应模型回归方程的自变量。
具体地,分别以氮径流量为自变量,土壤属性参数和气候参数为因变量,通过共线性分析和p值检验,从土壤属性参数和/或气候参数中去除共线性高以及与氮径流量相关关系不显著的土壤属性参数和/或气候参数(也即对氮径流量影响不显著的土壤属性参数和/或气候参数),得到各子集对应模型回归方程的自变量。
s24:采用全局优化算法分别对所述氮径流模型方程的参数进行优化,得到所述氮径流量回归方程。
全局优化算法集成了随机搜索算法、单纯形法、聚类分析及生物竞争演化等方法的优点,能有效处理目标函数反映面存在的粗糙、不敏感区及不凸起等问题,且不受局部最小点的干扰,是一种有效地解决非线性约束最优化问题的方法。相较于现有方案中采用已有的区域恒定值的农田氮径流系数来说,本发明采用全局优化算法优化率定模型连续变量的参数,提高了模型参数优化效率,全局寻优更彻底,提高了模型预测的精度。
可选地,在本发明的一些实施例中,上述步骤s24,采用全局优化算法分别对所述氮径流的参数进行优化率定,得到所述氮径流量回归方程的具体过程可以包括:
s24a:采用全局优化算法对所述样本土壤属性参数和所述样本气候参数进行优化率定,得到背景氮流失量率定参数;根据所述背景氮流失量率定参数建立背景氮流失量回归方程;
s24b:采用全局优化算法对所述样本土壤属性参数、样本气候参数及田间管理方式进行优化率定,得到氮径流率率定参数;根据所述氮径流率率定参数建立氮径流率回归方程;
s24c:根据所述背景氮流失量回归方程及氮径流率回归方程确定所述氮径流量回归方程。
可选地,在本发明的一些实施例中,上述步骤s24a,计算背景氮流失量r0对应的回归方程的过程主要包括:
s241:获取多条与所述样本数据对应的对照样本数据,对照样本数据包括背景氮流失量。
其中,对照样本数据的参数类型可如表1。示例性地,对照样本数据可如附表1和附表2中的数据编号1.1对应的数据所示。当然,上述对照样本数据的获取方式也可如步骤s10中样本数据的获取方式一样,或者说,样本数据和对照样本数据同时获取。
s242:根据背景氮流失量,采用全局优化算法对土壤属性参数和气候参数进行优化率定,得到背景氮流失量率定参数。
本步骤所优化率定的土壤属性参数和气候参数,可以是根据步骤s23进行数据筛选过后得到的数据。
s243:根据所述背景氮流失量率定参数,建立背景氮流失量回归方程。
通过步骤s243,将背景氮流失量率定参数代入到对应的氮径流模型方程中,得到背景氮流失量回归方程。
在上述氮径流模型方程中,与背景氮流失量对应的方程为公式(7)。示例性地,对上述对照样本数据采用上述步骤进行处理后,得到的背景氮流失量回归方程为:r0=0.015·p+2.36·tn,其中,p是降雨量,tn是总氮。
可选地,在本发明的一些实施例中,上述步骤s24b,计算氮径流率rr对应的回归方程的过程主要包括:
s244:获取多条与所述样本数据对应的对照样本数据,对照样本数据包括氮径流率。
其中,对照样本数据的参数类型可如表1。示例性地,对照样本数据可如附表1和附表2中的数据编号1.2对应的数据所示。当然,上述对照样本数据的获取方式也可如步骤s10中样本数据的获取方式一样,或者说,样本数据和对照样本数据同时获取。
s245:根据氮径流率,采用全局优化算法对土壤属性参数、气候参数及田间管理方式进行优化率定,得到氮径流率率定参数。
本步骤所优化率定的土壤属性参数、气候参数及田间管理方式,可以是根据步骤s23进行数据筛选过后得到的数据。
s246:根据所述氮径流率率定参数,建立氮径流率回归方程。
通过步骤s246,将氮径流率率定参数代入到对应的氮径流模型方程中,得到氮径流率回归方程。
示例性地,与以分类变量为有机无机肥配施,以及复合肥和尿素为例,对土壤属性参数和气候参数进行优化率的之后,得到的氮径流率回归方程为:
有机无机肥配施:rr=-(4.97e-04·som)×nrate+6.01e-03·p+0.085·clay(9)复合肥和尿素:rr=(7.11e-05·p-0.0031·ph)×nrate+2.62(10)
其中,p表示降雨量,som、tn、clay和ph分别表示土壤有机质、总氮、粘粒和ph含量。
s30:获取待估算研究区域的空间分布数据,构建研究区模型输入数据集,所述空间分布数据包括空间分布土壤属性数据、空间分布气候数据和空间分布田间管理方式数据等。
待估算研究区域的空间分布数据包括空间分布土壤属性数据、空间分布气候数据和空间田间管理方式等,可以理解地,“空间分布数据”、“空间分布土壤属性数据”等中的“空间”是指研究区域。示例性地,可以根据研究区域所在地的统计年鉴下载区域内,各县区氮肥、复合肥使用量和耕地面积数据,计算各县区单位耕地面积的氮肥施用强度,空间田间管理方式咨询研究区内各地市农业管理部门和当地农民获得。可以理解地,上述空间分布数据的获取方式只是为了有助于理解而进行的举例说明,本实施例对空间分布数据的获取方式不做限定。
s40:根据研究区模型输入数据集和氮径流量回归方程,计算待估算研究区域的氮径流量。
具体地,根据公式(3)计算研究区域的氮径流量,具体步骤包括:
s401:根据公式(7)将空间分布土壤属性数据、空间分布气候数据输入到背景氮流失量回归方程中,计算研究区域的背景氮流失量;
s402:根据公式(4)将空间分布土壤属性数据、空间分布气候数据输入到对应的氮径流率回归方程中,计算研究区域的氮径流率;
s403:根据研究区域的背景氮流失量、氮径流率,采用公式(3)计算所述研究区域的氮径流量。
上述实施例通过获取氮径流模型,并对样本数据进行分类,再对土壤属性参数和气候参数进行优化率定,以建立氮径流率回归方程。由于样本数据中包含了土壤属性参数、气候参数和田间管理方式等,因此,本实施例考虑了气候、土壤属性和田间管理方式等因素对runoff的影响,以及氮径流量与施氮量之间的非线性响应关系,构建了氮径流率回归方程,并将空间分布土壤属性数据、所述空间分布气候数据输入到氮径流率回归方程,以计算氮径流量,由此估算得到的研究区域的氮径流量准确率和空间分辨率更高。
上述实施例之所以考虑:1)氮径流量与施氮量之间的非线性响应关系;2)土壤、气候属性和田间管理方式对氮径流量的影响,原因在于:
1)由于农作物对氮肥的吸收是有阈值的,当施氮量超过其阈值时,作物不再吸收,多余的氮肥发生径流损失,造成氮径流量随着施氮量增加而加速流失的结果。本发明实施例考虑了氮径流量与施氮量(如施氮强度)之间的非线性响应关系,使得在施氮量高值和低值区域也能较为准确的核算农田氮径流量。
2)农田的氮径流量往往产生于年内几次大暴雨事件,而极端的干旱也会造成局地的降雨难以产生径流,不易造成氮的径流流失,因此,本发明实施例还考虑了气候对氮径流量的影响,使得在极端气候的区域和年份,其核算结果更为真实准确。
3)本发明实施例还考虑了土壤属性的影响,土壤粘性会影响田面水的下渗率,土壤总氮含量影响了氮背景径流量,土壤ph、有机质含量等属性会影响氮素在土壤中的迁移转化,以上这些土壤属性均会间接的影响农田的氮径流量,且土壤的空间异质性非常大。
4)不同肥料类型、施肥方式、灌溉方式和作物类型等人为活动均是农田的氮径流过程的重要影响因素,本发明实施例针对不同田间管理和作物类型开展分类模拟,体现了各地区和不同作物人为活动的影响。
以下结合具体应用实例,对本发明实施例的农田氮径流量估算方法的具体实现过程做进一步说明。
在此实施例中,是以如图3所示的研究区域为例,核算其氮径流量。
步骤一:模型参数优化训练样本数据集建立
(1)收集研究区内氮径流实验数据
基于webofscience和中国期刊网数据库,以“nitrogen”+“runoff”或“loss”+“cropland”或“farmland”为英文主题词,以“氮流失”或“氮径流”或“氮损失”为中文主题词对1900-2016年间所有文献进行检索,筛选出实验地点在研究区内的文献。最终获取研究区实验文章20篇,实验点位20个(如图3所示)。对照表1整理并记录文献中的原位观测数据,获得原位观测的runoff、nrate、实验期间环境因子及人为管理措施等信息。
可选地,在本发明实施例中,还可对实验缺失数据进行补充。
通过实验样地经纬度从中国气象数据共享网中找到最邻近气象站点,近似替代实验点的状况,依据实验时间补充缺失的降雨量和气温数据。再通过经纬度从中国土壤数据库中找到相应的市县,以及匹配的土种,补充缺失的土壤属性。针对缺失的灌溉和耕作等田间管理方式,按照当地常规方式补充。当地常规田间管理方式则通过文献调研、向当地农业管理部门咨询及实地调查等多种渠道获取。将实验中未施肥的对照实验观测的runoff作为该实验地的r0,如附表1中的数据编号1.1所示,同时通过式(2)计算rr。最终形成训练样本数据146条,由于数据量多,仅将一小部分数据列于表中(如附表1所示)。
步骤二:模型参数优化率定
(1)针对样本数据集中的分类变量,可划分不同类别,例如:施肥次数(1次、2次)、施肥方式(撒施、深施)、肥料类型(有机无机配施、复合肥、尿素)和作物类型(水稻、玉米、柑橘、蔬菜类和其它,如图4所示),配对样本t检验分析结果显示:尿素和有机无机肥料配施之间的rr有显著性差异,如图2所示。由于施肥方式中“深施”实验数据样本量过小(2个),因而没有考虑其显著性差异。于是将肥料类型变量纳入需要优化率定的分类变量中。
(2)具体地,可在matlab平台上,实现决策树cart算法,优化肥料类型变量的参数,分节点的寻找结果为“有机无机配施”分为一类,“复合肥”+“尿素”分为另一类。于是,将rr训练样本数据集按照上述分节点分为两类数据。
(3)分别针对上述两类rr样本数据和r0样本数据中的连续变量开展共线性诊断分析,以及对rr与r0影响的显著性分析,剔除共线性高以及对rr与r0影响不显著的变量(年均气温和灌溉量)。
(4)分别针对每类数据集保留下的连续变量,在matlab平台上实现sce-ua算法,优化率定参数,建立分类回归方程,如下:
r0=0.015·p+2.36·tn(9)
有机无机肥配施:rr=-(4.97e-04·som)×nrate+6.01e-03·p+0.085·clay(10)
其它肥料:rr=(7.11e-05·p-0.0031·ph)×nrate+2.62(11)
上式中,p是降雨量,som、tn、clay和ph分别是土壤有机质、总氮、粘粒和ph含量。
步骤三:待核算区域土壤属性、气候和田间管理数据获取
以2012年为例,从研究区各地市统计年鉴下载区域内各县区氮肥、复合肥使用量和耕地面积数据,计算各县区单位耕地面积的氮肥施用强度。在arcgis平台上,结合土地利用类型分布数据,可视化氮肥施用强度空间分布(如图5所示)。从全球土壤属性数据库(hwsdv1.2)中下载土壤属性数据,在arcgis平台上截取研究区范围内土壤属性。田间管理方式可根据研究区内各地市农业管理部门和当地农民所采集的数据获得。
步骤四:研究区农田氮径流量空间模拟
基于步骤一和步骤二所建立的rr与r0模型,输入步骤三中获取的自然环境与田间管理方式空间分布数据,分别模拟研究区内rr与r0的空间分布,再经过公示(3)计算得到runoff空间分布结果。结果如图6所示,其中,图6中a图所示为研究区的氮径流量runoff的空间分布结果,图6中b图所示为研究区的背景氮流失量的空间分布结果,图6中c图所示为研究区内的氮径流率的空间分布结果。根据该分布结果可知,研究区内氮径流强度平均值为31kg/ha/yr,平均氮肥径流率平均值为3.9%,农田背景氮径流强度平均值为17kg/ha/yr。
基于现有方案对中国农田氮径流量空间分布开展过研究,现将本发明方法得到的模拟结果与之对比,结果显示:基于本发明方法的模拟结果具备较高的空间分辨率,如图7a-图7c所示,其中,图7a所示为采用本发明实施例的氮径流量估算方法所计算得到的氮径流量的分布结果,图7b所示为采用现有的wangetal.提出的方案所得到的氮径流量的分布结果,图7c所示为采用现有的guetal.提出的方案所得到的氮径流量的分布结果,其中,图7b及图7c中的虚线方框所对应的即对应于本发明实施例所针对的研究区域的大致范围。此外,采用现有方案对本发明构建的样本数据的runoff开展预测,对比本发明方法的预测精度,结果显示:基于本发明方法预测的可决系数(r2)提高了0.39,均方根误差(rmse)降低了7.8kg/ha(如表2所示),在模型预测精度上也有较大的提高。
表2
本发明的另一实施例还提出一种农田氮径流量估算装置,用于对研究区域的氮径流量进行估算,如图8所示,所述农田氮径流量估算装置包括:样本数据获取单元10、回归方程建立单元20、空间分布数据获取单元30和计算单元40;
所述样本数据获取单元10用于获取多条样本数据,根据多条样本数据构建模型参数优化训练样本数据集,样本数据包括土壤属性参数、多种田间管理方式、作物类型和气候数据;详细内容可参见上述任意方法实施例的步骤s10的相关描述,在此不再赘述;
所述回归方程建立单元20用于根据田间管理方式和/或作物类型的类别,将模型参数优化训练样本数据集划分为多个子集,根据划分的样本数据子集对预设的氮径流模型方程的模型参数进行优化率定,建立氮径流量回归方程;详细内容可参见上述任意方法实施例的步骤s20的相关描述,在此不再赘述;
所述空间分布数据获取单元30用于获取待估算研究区域的空间分布数据,构建研究区模型输入数据集,所述空间分布数据包括空间分布土壤属性数据、空间分布田间管理方式、作物类型和空间分布气候数据;详细内容可参见上述任意方法实施例的步骤s30的相关描述,在此不再赘述;
所述计算单元40用于根据研究区模型输入数据集和氮径流量回归方程,计算待估算研究区域的农田氮径流量;详细内容可参见上述任意方法实施例的步骤s40的相关描述,在此不再赘述。
本实施例中的各个单元与上述农田氮径流量估算方法的步骤一一对应,具体限定也可参照上述农田氮径流量估算方法的步骤,在此不再赘述。
上述实施例通过获取氮径流模型,并对样本数据进行分类,再对土壤属性参数和气候参数进行优化率定,以建立氮径流率回归方程。由于样本数据中包含了土壤属性参数、气候参数和田间管理方式等,因此,本实施例考虑了气候、土壤属性和田间管理方式等因素对runoff的影响,以及氮径流量与施氮量之间的非线性响应关系,构建了氮径流率回归方程,并将空间分布土壤属性数据、所述空间分布气候数据输入到氮径流率回归方程,以计算氮径流量,由此估算得到的研究区域的氮径流量,结合了土壤属性和气候数据,更加真实贴切,准确率更高。
所属领域的技术人员可以清楚地了解到,为了描述的方便和简洁,仅以上述各功能单元、模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能单元、模块完成,即将所述装置的内部结构划分成不同的功能单元或模块,以完成以上描述的全部或者部分功能。
在一个实施例中,提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行计算机程序时实现上述氮径流量估算方法的步骤。
在一个实施例中,提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现上述农田氮径流量估算方法的步骤。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本发明所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(rom)、可编程rom(prom)、电可编程rom(eprom)、电可擦除可编程rom(eeprom)或闪存。易失性存储器可包括随机存取存储器(ram)或者外部高速缓冲存储器。作为说明而非局限,ram以多种形式可得,诸如静态ram(sram)、动态ram(dram)、同步dram(sdram)、双数据率sdram(ddrsdram)、增强型sdram(esdram)、同步链路(synchlink)dram(sldram)、存储器总线(rambus)直接ram(rdram)、直接存储器总线动态ram(drdram)、以及存储器总线动态ram(rdram)等。
以上所述实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围,均应包含在本发明的保护范围之内。
附表1
附表2(续附表1)
- 还没有人留言评论。精彩留言会获得点赞!