药物研发知识库构建方法及装置与流程
[0001]
本发明涉及信息处理技术领域,具体涉及一种药物研发知识库构建方法及装置。
背景技术:
[0002]
知识库,又称为智能数据库或人工智能数据库,是基于知识的数据库,具有智能性,任何一个信息处理系统都离不开数据和知识库的支持。目前,领域知识库的构建通常是由人工来完成,比如由领域内的专家等人员来完成,但是这种通过人工来构建领域知识库需要耗费大量时间、精力,效率低而且不易维护,尤其是药物研发领域,不仅与人类关系非常密切,而且该领域的知识体系也极为庞杂,不仅包括疾病、药品、检查手段、检查设备、治疗方式等显性知识,还包括疾病诊断经验、疾病产生原因、相关并发症等隐形知识,并且这些知识相互关联。因此如何高效、全面地建立药物研发知识库是业界急需解决的一个问题。
技术实现要素:
[0003]
本发明提供一种药物研发知识库构建方法及装置,以解决现有技术中通过人工方式构建知识库效率低、时间长、不易维护的问题,实现药物研发知识库构建的自动化处理。
[0004]
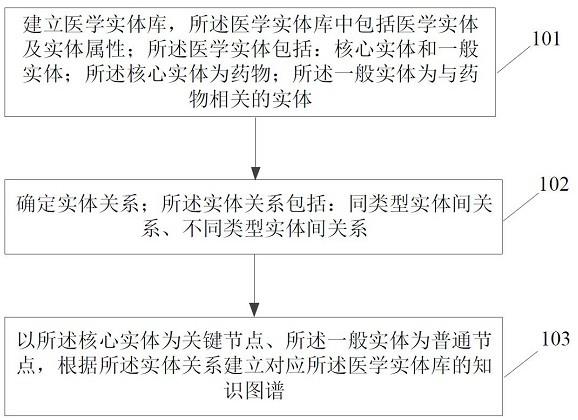
为此,本发明提供如下技术方案:一种药物研发知识库构建方法,所述方法包括:建立医学实体库,所述医学实体库中包括医学实体及实体属性;所述医学实体包括:核心实体和一般实体;所述核心实体为药物;所述一般实体为与药物相关的实体;确定实体关系;所述实体关系包括:同类型实体间关系、不同类型实体间关系;以所述核心实体为关键节点、所述一般实体为普通节点,根据所述实体关系建立对应所述医学实体库的知识图谱。
[0005]
可选地,所述建立医学实体库包括:从医学相关的结构化数据中抽取医学实体,建立医学实体库;采集医学相关语料;从所述语料中抽取医学实体,并将抽取的医学实体补充到所述医学实体库中。
[0006]
可选地,所述采集医学相关语料包括:从以下任意一种或多种数据源采集医学相关语料:医学相关的文献、专利、新闻、网页。
[0007]
可选地,所述确定实体关系包括以下任意一种或多种方式:采用基于规则的方法从所述医学相关语料中抽取实体关系;采用基于深度学习模型的方法从所述医学相关语料中抽取实体关系。
[0008]
可选地,所述一般实体包括:靶点、适应症、公司;所述同类型实体间关系包括:药物实体关系、公司实体关系;所述药物实体关系包括:协同作用、拮抗作用;所述公司实体关系包括:母公司、子公司、分公司;业务领域的合作、转让和受让;所述不同类型实体间关系包括:药物与适应症的关系、药物与靶点的关系、药物与公司
的关系。
[0009]
一种药物研发知识库构建装置,所述装置包括:实体库建立模块,用于建立医学实体库,所述医学实体库中包括医学实体及实体属性;所述医学实体包括:核心实体和一般实体;所述核心实体为药物;所述一般实体为与药物相关的实体;实体关系确定模块,用于确定实体关系;所述实体关系包括:同类型实体间关系、不同类型实体间关系;知识图谱生成模块,用于以所述核心实体为关键节点、所述一般实体为普通节点,根据所述实体关系建立对应所述医学实体库的知识图谱。
[0010]
可选地,所述实体库建立模块包括:医学实体库建立单元,用于从医学相关的结构化数据中抽取医学实体,建立医学实体库;数据采集单元,用于采集医学相关语料;实体抽取单元,用于从所述语料中抽取医学实体;维护单元,用于将所述实体抽取单元抽取的医学实体补充到所述医学实体库中。
[0011]
可选地,所述数据采集单元,具体用于从以下任意一种或多种数据源采集医学相关语料:医学相关的文献、专利、新闻、网页。
[0012]
可选地,所述实体关系确定模块包括:第一确定单元,用于采用基于规则的方法从所述医学相关语料中抽取实体关系;和/或第二确定单元,用于采用基于深度学习模型的方法从所述医学相关语料中抽取实体关系。
[0013]
可选地,所述一般实体包括:靶点、适应症、公司;所述同类型实体间关系包括:药物实体关系、公司实体关系;所述药物实体关系包括:协同作用、拮抗作用;所述公司实体关系包括:母公司、子公司、分公司;业务领域的合作、转让和受让;所述不同类型实体间关系包括:药物与适应症的关系、药物与靶点的关系、药物与公司的关系。
[0014]
本发明实施例提供的药物研发知识库构建方法及装置,通过建立医学实体库,确定实体关系,以核心实体为关键节点、以一般实体为普通节点,根据所述实体关系建立对应所述医学实体库的知识图谱。本发明实施例的方案对涉及药物多领域的复杂药物数据通过知识图谱形式来展示相关数据及实体间逻辑关系,从而方便用户理解药物数据间关系,快速解读或描述药物复杂知识;而且,构建成知识库后,方便药物数据处理,以及药物数据应用方向探索与推理。
附图说明
[0015]
图1是本发明实施例药物研发知识库构建方法的流程图;图2是本发明实施例中核心实体与一般实体的串联关系示意图;图3是本发明实施例中基于规则的方法从所述医学相关语料中抽取实体关系的示例;图4是本发明实施例药物研发知识库构建装置的结构框图;
图5是本发明实施例中实体库建立模块的一种结构框图。
具体实施方式
[0016]
医药领域药物数据不仅具有行业专业特点,而且结合药物研发还涉及众多领域。针对这些特点,本发明实施例提供一种药物研发知识库构建方法及装置,通过建立医学实体库,确定实体关系,以核心实体为关键节点、以一般实体为普通节点,根据所述实体关系建立对应所述医学实体库的知识图谱。
[0017]
如图1所示,是本发明实施例药物研发知识库构建方法的流程图,包括以下步骤:步骤101,建立医学实体库,所述医学实体库中包括医学实体及实体属性;所述医学实体包括:核心实体和一般实体;所述核心实体为药物;所述一般实体为与药物相关的实体。
[0018]
所述一般实体比如可以包括但不限于:靶点、适应症、公司等;所述实体属性是对实体起限定作用的描述信息,比如:药物的属性包括:名称、剂型、给药途径、药物类型、nme、复方、注册分类等。
[0019]
适应症的属性包括:疾病名称、病因、解剖学位置、疾病分类等。
[0020]
公司的属性包括:地区、母公司、子公司、业务领域、企业分类等。
[0021]
靶点的属性包括:靶点分类;非信号通路的靶点的二级属性蛋白、核酸、脂质、糖类;蛋白和核酸类靶点的三级属性如基因、序列等。
[0022]
各实体数据主要来自于公开的文献、官网数据和行业内数据库等非结构化数据、半结构化数据和结构化数据。
[0023]
比如,具体可以按照以下方式建立医学实体库:(1)建立医学实体库;从医学相关的结构化数据中抽取医学实体,建立医学实体库;在实际应用中,可以采用关系型数据库(如mysql)存储实体属性(不用于关联的字段),例如,实体的图片url等;采用图数据库(如neo4j)存储实体的主要字段及关系,用于知识推理(图推理、上下位推理、等价推理、不一致检测、知识发现)。
[0024]
从结构化数据中抽取医学实体至图数据库流程如下:根据医学实体及其属性,设计数据库表结构;在已有的专业数据库内创建mapping视图,将数据抽取至上述数据库表中;采用d2rq工具生成rdf文件;将rdf文件导入图数据库中。
[0025]
(2)通过多种数据源抽取医学实体,对医学实体库进行补充和维护:采集医学相关语料,比如,可以从以下任意一种或多种数据源采集医学相关语料:医学相关的文献、专利、新闻、网页,当然在实际应用中并不仅限于这些数据源;然后从所述语料中抽取医学实体,将抽取的医学实体补充到所述医学实体库(即上述图数据库)中。
[0026]
另外,为了保证补充到医学实体库中的医学实体的准确性,还可进一步统计抽取出的每个医学实体出现的频次,当该医学实体出现的频次高于设定阈值(例如,10次)时,再将其补充到所述医学实体库中。
[0027]
进一步地,为了保证所述医学实体库的质量,还可以将待补充的医学实体交由专家来审核,审核通过的再纳入到所述医学实体库中。
[0028]
需要说明的是,在实际应用中,所述医学实体库的建立还可以采用其他方式,比
如,采集多种医学相关数据源,对其中的文本序列进行分词,根据分词得到的各词单元查找领域知识库得到所述文本序列中的医学实体,比如药物、适应症等;再比如,还可以利用分类器确定所述文本序列中的医学实体。当然,还可有其他方式,对此本发明实施例不做限定。
[0029]
需要说明的是,在实际应用中,针对不同类型的医学实体,可以根据其特点,使用不同的方法和数据源来得到相应的医学实体并补充到所述医学实体库中,并对医学实体库进行更新和维护。下面以适应症和靶点进行举例说明。
[0030]
对于适应症实体:方法一:与临床注册、新闻和公司年报等信息相比,上市药物的获批适应症是标准化术语的重要来源。为此,可以按照以下方式获取适应症实体:1)构建原始适应症第一信息表,从美国fda、欧盟ema、日本pmda、中国nmpa药品说明书等数据源中抽取适应症实体;2)对原始适应症第一信息表进行同义词合并处理得到第二信息表,即针对适应症抽取词的自身集合内进行合并;可通过字符处理(去“,”、空格等)、大小写转换、英文单复数、时态归一化等方式进行,最终将原始适应症第一信息表转换为第二信息表;3)对合并处理后的第二信息表中的适应症字符串进行药物nda/bla注册号频次统计;4)对第二信息表中的适应症信息进行国际通用标准库(mesh)同义词关系映射;所述同义词关系映射是指将所述适应症信息和mesh中的词条及其同义词进行匹配。这个步骤是抽取的实体非标准集合向标准集合映射的过程。mesh与其他标准库(如icd)又可通过一定关系映射,因此可扩展此知识库的应用范围。
[0031]
5)对于不能映射的适应症字符串,如果其在不同数据源中出现的频次大于设定阈值(比如10次),则将其补充到所述医学实体库中;出现频次低于所述阈值的适应症字符串作为备用实体词条。
[0032]
方法二:常见的临床试验公示平台是主要的临床新药信息获取途径,常见如美国临床试验公示平台clinicaltrials.gov、中国临床试验登记与信息公示平台、who国际临床试验注册平台、欧洲eu clinical trials register。此外,公司年报、投融资交易新闻、专利信息是公司在研项目的重要披露渠道。为此,还可以按照以下方式获取适应症实体:1)对多个临床源信息进行医学实体标定,比如药物、公司、适应症等多维度信息标定,当出现新适应症词条时作为备用实体词条;2)对备用实体词条进行周期性频次分析(如每个月进行一次备用词条词频统计),如果出现频次低于设定阈值(比如10次)的词条进行近似映射;近似映射常用的方法是将下级词条近似为上级词条,如“chronic liver failure(慢性肝功能衰竭)”近似映射为“liver failure(肝功能衰竭)”;同时慢性肝功能衰竭作为备用数据;如果出现频次大于等于设定阈值,则启用该词条,并将其映射到mesh层级结构。例如,“慢性肝功能衰竭”从各个归一化数据源出现频次超过阈值时,将其从备用实体词条转换为正式的适应症词条;3)备用实体词条释放后,对该词条的映射层级进行调整。
[0033]
对于靶点实体:靶点按类型分为非信号通路靶点、信号通路靶点和其他。其中,非信号通路靶点以具体的分子实体为标志,药物与靶点实体发生直接相互作用,产生药理学效应。非信号靶点分子
以蛋白、核酸、多糖、脂质等单体或复合体分子为代表。信号通路类靶点为生理生化现象,如细胞凋亡、炎症反应、衰老等。此种情况下,对应药物的实体靶点未知,或者与实体靶点结合后,可以介导相关的生理现象。其他类型为靶点不明确数据。
[0034]
在本发明实施例中,可以将靶点按以下方式进行分类:可以直接关联到公开的蛋白质、基因库等的靶点,属于“非信号通路类靶点”;不能归类到非信号通路靶点和其他靶点的数据,归类到“信号通路类靶点”;不能归类到上述两种情况的靶点归为“其他靶点”。
[0035]
实体类分子分为蛋白质类、核酸、脂质、糖类。其中,绝大多数实体靶点为蛋白质,如单分子蛋白、多亚基蛋白或多蛋白复合体。蛋白类靶点可以实现自动维护和校验,少数的核酸、脂质和糖类可通过人工维护。
[0036]
比如,对单分子蛋白质靶点的更新维护可以有以下几种方式:1)公开源维护,如genecard,uniprot,chembl的id号;2)功能介绍,获取公开数据库uniprot的function字段内容;3)序列信息,获取uniprot的sequence的经典序列,按照fasta格式存储;4)别名信息,uniprot、genecards的别名汇总去重,剔除酶编号ec等命名信息;5)层级关系,以mesh层级框架作为树形结构基础,通过hgnc的基因家族、chembl层级等进行层级辅助。对于mesh中不包含的蛋白靶点,则进行近似功能蛋白归类处理。
[0037]
再比如,对复合蛋白靶点的更新维护,可以仅维护各亚基组分的uniprot号,genecards号。
[0038]
需要说明的是,考虑到药物领域大量数据是以英文为主要文字形式,因此,本发明方案不仅可以从中文医学相关资料中抽取医学实体建立中文药物研发知识库,而且还可以对其他语种的数据源进行医学实体抽取,并结合中文本地化校验过程,通过原文(其他语言如英文)与译文(中文)、译文(中文)与原文(其他语言)交叉比对、词频比对、专家比对处理,形成数据国际化与本地化知识并存储到知识库本地化分支实体中。比如,英文和小语种术语以umls(unified medical language system,统一医学语言系统)进行关联,对umls未涵盖的最新icd-11等进行维护;中文术语以中国临床试验登记与信息公示平台、中国药品说明书、公开发表文献的关键词等进行核对。
[0039]
步骤102,确定实体关系;所述实体关系包括:同类型实体间关系、不同类型实体间关系。
[0040]
所述同类型实体间关系包括但不限于:药物实体关系、公司实体关系。其中:所述药物实体关系包括:协同作用(比如相加、增强、增敏等)、拮抗作用(比如相减、抵抗等);所述公司实体关系包括:母公司、子公司、分公司;业务领域的合作、转让和受让。
[0041]
所述不同类型实体间关系包括但不限于:药物与适应症的关系(比如治疗、预防、诊断、诱导等)、药物与靶点的关系(比如增敏、降解、稳定、抑制、刺激、激动、降解增强、部分激动、增强、诱导、反向激动、激活、结合、拮抗、供体、催化、调节、清除、阻滞等)、药物与公司的关系(比如原研、在研、非在研、受让)。
[0042]
在本发明实施例中,核心实体串联各个一般实体,一般实体与核心实体存在关联关系,如图2所示示例。这样,通过一般实体从不同维度以关系的方式大大丰富了药物信息。例如,通过药物、靶点实体关系,描述药物作用机理;通过药物、适应症实体关系,描述药物用途;通过药物、公司实体关系,描述药物研发历史和商业情报信息等。
[0043]
这样可以进行实体间的关系推理,任意两个普通实体间的关系可以通过核心实体跳转。例如,公司a在疾病领域的研发投入,需要通过公司a的药物研发情况进行推断。
[0044]
在本发明实施例中,确定实体关系可以采用以下任意一种或多种方式:1. 采用基于规则的方法从所述医学相关语料中抽取实体关系比如,为固定格式的指南(或教材)类文本制作规则映射模板,例如图3所示,设置以下规则:从段落“(一)适用对象”中抽取疾病名称;从段落“(二)诊断依据”中抽取症状,此段落抽取的实体是疾病的“有现象表达”关系;从段落“(七)药物选择与使用时机”中抽取药物名称,此段落抽取的实体是疾病的“被..治疗”关系。
[0045]
使用专业词汇表及ac自动机算法抽取上述各段落中的实体,根据预置规则,填充实体与实体间关系。
[0046]
2)采用基于深度学习模型的方法从所述医学相关语料中抽取实体关系比如,从新闻、文献、专利等文本数据中统计实体共现次数(例如,5次),筛选获得共现实体集合,抽取共现实体上下文段落作为预测语料,供深度学习模型使用,使用基于深度学习的nlp (natural language processing,自然语言处理) 算法模型预测实体间关系。
[0047]
步骤103,以所述核心实体为关键节点、所述一般实体为普通节点,根据所述实体关系建立对应所述医学实体库的知识图谱。
[0048]
所述知识图谱是一种图谱组织形式,通过语义关联将各种实体关联起来。知识图谱将结构化、非结构化的数据通过数据抽取、融合在一起,体现了数据治理、语义连接的思想,有利于大规模数据的利用和迁移。
[0049]
本发明实施例提供的药物研发知识库构建方法,通过建立医学实体库,确定实体关系,以核心实体为关键节点、以一般实体为普通节点,根据所述实体关系建立对应所述医学实体库的知识图谱。本发明实施例的方案对涉及药物多领域的复杂药物数据通过知识图谱形式来展示相关数据及实体间逻辑关系,从而方便用户理解药物数据间关系,快速解读或描述药物复杂知识;而且,构建成知识库后,方便药物数据处理,以及药物数据应用方向探索与推理。
[0050]
相应地,本发明实施例还提供一种药物研发知识库构建装置,如图4所示,是该装置的一种结构框图。
[0051]
在该实施例中,所述装置包括以下各模块:实体库建立模块401,用于建立医学实体库,所述医学实体库中包括医学实体及实体属性;所述医学实体包括:核心实体和一般实体;所述核心实体为药物;所述一般实体为与药物相关的实体,比如靶点、适应症、公司等;实体关系确定模块402,用于确定实体关系;所述实体关系包括:同类型实体间关系、不同类型实体间关系;知识图谱生成模块403,用于以所述核心实体为关键节点、所述一般实体为普通节点,根据所述实体关系建立对应所述医学实体库的知识图谱。
[0052]
在本发明实施例中,各实体数据主要来自于公开的文献、官网数据和行业内数据库等非结构化数据、半结构化数据和结构化数据。
[0053]
如图5所示,所述实体库建立模块401的一种具体实现方式可以包括以下各单元:
医学实体库建立单元51,用于从医学相关的结构化数据中抽取医学实体,建立医学实体库50;数据采集单元52,用于采集医学相关语料;比如,可以从以下任意一种或多种数据源采集医学相关语料:医学相关的文献、专利、新闻、网页等,当然还可以有其他数据源,对此不做限定;实体抽取单元53,用于从所述语料中抽取医学实体;维护单元54,用于将所述实体抽取单元53抽取的医学实体补充到所述医学实体库50中。
[0054]
需要说明的是,在实际应用中,可以采用关系型数据库(如mysql)存储实体属性(不用于关联的字段),例如,实体的图片url等;采用图数据库(如neo4j)存储实体的主要字段及关系,用于知识推理(图推理、上下位推理、等价推理、不一致检测、知识发现)。
[0055]
进一步地,在所述实体库建立模块的另一实施例中,还可包括统计单元(未图示),用于统计所述实体抽取单元53抽取出的每个医学实体出现的频次,当该医学实体出现的频次高于设定阈值(例如,10次)时,再触发所述维护单元54将其补充到所述医学实体库中。
[0056]
需要说明的是,在实际应用中,针对不同类型的医学实体,可以根据其特点,使用不同的方法和数据源来得到相应的医学实体并补充到所述医学实体库中,并对医学实体库进行更新和维护,对此本发明实施例不做限定。
[0057]
在本发明实施例中,所述同类型实体间关系包括:药物实体关系、公司实体关系;所述药物实体关系包括:协同作用、拮抗作用等;所述公司实体关系包括:母公司、子公司、分公司;业务领域的合作、转让和受让等。所述不同类型实体间关系包括:药物与适应症的关系、药物与靶点的关系、药物与公司的关系等。
[0058]
确定实体关系可以采用以下任意一种或多种方式,比如,实体关系确定模块402可以包括:第一确定单元、和/或第二确定单元。其中:所述第一确定单元用于采用基于规则的方法从所述医学相关语料中抽取实体关系;所述第二确定单元用于采用基于深度学习模型的方法从所述医学相关语料中抽取实体关系。
[0059]
需要说明的是,对于上述本发明装置各实施例而言,由于各模块、单元的功能实现与相应的方法中类似,因此对所述质控物质选择装置各实施例描述得比较简单,相关之处可参见方法实施例的相应部分说明。
[0060]
本发明实施例提供的药物研发知识库构建装置,通过建立医学实体库,确定实体关系,以核心实体为关键节点、以一般实体为普通节点,根据所述实体关系建立对应所述医学实体库的知识图谱。本发明实施例的方案对涉及药物多领域的复杂药物数据通过知识图谱形式来展示相关数据及实体间逻辑关系,从而方便用户理解药物数据间关系,快速解读或描述药物复杂知识;而且,构建成知识库后,方便药物数据处理,以及药物数据应用方向探索与推理。
[0061]
本发明实施例的方案,通过建立药物实体与其他医学实体的多样性关联,用知识图谱的形式组织和管理知识库中的知识,大大减少了领域专家维护管理知识库的重复劳动力,提高了领域用户获取领域知识的方便性和灵活性。
[0062]
需要说明的是,本发明的说明书和权利要求书及上述附图中的术语
ꢀ“
包括”和“具
有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
[0063]
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。而且,以上所描述的系统实施例仅仅是示意性的,其中作为分离部件说明的模块和单元可以是或者也可以不是物理上分开的,即可以位于一个网络单元上,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
[0064]
本领域普通技术人员可以理解实现上述方法实施方式中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,所述的程序可以存储于计算机可读取存储介质中,这里所称的存储介质,如:rom/ram、磁碟、光盘等。
[0065]
相应地,本发明实施例还提供一种用于药物研发知识库构建方法的装置,该装置是一种电子设备,比如,可以是移动终端、计算机、平板设备、个人数字助理等。所述电子设备可以包括一个或多个处理器、存储器;其中,所述存储器用于存储计算机可执行指令,所述处理器用于执行所述计算机可执行指令,以实现前面各实施例所述的方法。
[0066]
以上对本发明实施例进行了详细介绍,本文中应用了具体实施方式对本发明进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及装置,其仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围,本说明书内容不应理解为对本发明的限制。因此,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1