考虑历史轨迹知识的梯级水库群生态调度优化方法与流程
本发明涉及梯级水库群生态调度技术领域,具体涉及一种考虑历史轨迹知识的梯级水库群生态调度优化方法。
背景技术:
伴随着我国水利事业飞速迅猛发展,各个流域大规模梯级水库群不断建成运营,发挥了巨大的防洪、发电、航运等社会效益和经济效益,但也急剧改变了原始的天然径流水文情势,对河流生态系统的结构和工程也产生了诸多不利的影响,包括河道萎缩、泥沙淤积、生物多样性减少。为减缓水库运行对河道生态环境的负面影响,水库群生态调度作为一种典型的非工程措施,通过调整水库群的运行方式,获取生态系统稳定及保持物种多样性最为合适的径流过程。可见,开展水库群生态调度非常有必要,受到国内外的广泛关注。
梯级水库群生态调度问题具有大规模、高维度、多阶段、强约束、非线性等特点,传统的动态规划方法(dp)应用于求解梯级水库群联合优化调度问题时,无法避免地面临严重的维数灾问题。
离散微分动态规划方法(dddp)是一种以逐次渐进逼近理论为核心的动态规划改进方法。其基本思路是:首先,根据经验或其他方法获得满足各项复杂约束条件的初始轨迹;然后,在该轨迹的邻域内对各电站不同时段的状态变量进行离散形成廊道;其次,基于常规动态规划方法在各时段离散状态组合间进行优化,寻找出新的最优轨迹作为下次迭代的试验轨迹,反复迭代直至满足收敛条件。但dddp在处理大规模水库群优化调度问题时,仍然存在维数灾、早熟收敛、搜索能力不足等缺陷。
因此,亟待对dddp的计算机理进行有效改进,提高水库群联合调度问题的计算效率和求解精度。
重心反向学习是近年来依托反向学习提出的新智能计算技术,其基本思想是充分利用群体的搜索信息,评估当前状态及其重心反向状态,择优使用,从而加速搜索进程。由于dddp是逐阶段计算过程,没有群体的概念,本次将各阶段的状态视为一个个体,这样若干个不同阶段的状态则可视为一个群体。为了有效利用历史轨迹信息,本次提出了考虑不同历史轨迹的变尺度重心反向学习,即选取不同尺度的阶段个数,然后组成一个群体并计算重心反向状态,来挖掘生成多样性的搜索信息,提高全局搜索能力。
本发明成果考虑历史轨迹所携带的知识信息,采用变尺度重心反向学习与dddp相结合,通过变尺度重心反向学习寻找优化轨迹,来有效克服dddp的局部收敛问题,提高方法的求解效率和计算精度,对大规模水库群优化调度问题具有良好的支撑应用价值。
技术实现要素:
本发明的目的就是针对上述技术的不足,提供一种考虑历史轨迹知识的梯级水库群生态调度优化方法,解决dddp在复杂水电系统优化调度求解时存在的局部收敛问题。
为实现上述目的,本发明所设计的考虑历史轨迹知识的梯级水库群生态调度优化方法,包括如下步骤:
1)确定初始计算条件,包括梯级水库群生态调度的优化目标函数、约束条件和决策变量;
2)设定计算参数,包括最大迭代次数m、最大变尺度重心反向学习次数k、各水库初始离散步长、收敛精度ε、水库数目n和调度期时段数目t;
3)采用常规动态规划方法生成满足各约束条件的各个水库的初始轨迹ω1,并将其存入历史轨迹库
4)初始化迭代次数m=1;
5)当历史轨迹库
①初始化变尺度重心反向次数k=1;
②随机生成在1到y之间的正整数y,有1≤y≤y;
③从历史轨迹库
其中,
④由重心反向原理,计算当前轨迹
⑤比较重心反向轨迹和当前轨迹,如果
⑥令k=k+1,如果k≤k,转步骤②,否则转步骤(6);
6)实施常规dddp算法,在当前轨迹的可行范围内形成一个搜索廊道,在搜索廊道内使用常规动态规划方法寻求当前最优轨迹,并将当前最优轨迹按递进顺序,存入并扩充历史轨迹库
7)算相邻两次最优轨迹各时段的水位差值,若
8)令m=m+1,若m>m,则转至步骤9),否则转至步骤5);
9)停止计算,输出最终的最优轨迹。
本发明与现有技术相比,具有以下优点:
1、以dddp为基础框架,通过挖掘历史轨迹过程携带的知识信息,对当前轨迹进行变尺度重心反向学习,得到结果更好的优化轨迹;
2、充分利用了历史轨迹知识信息,通过变尺度重心反向学习来挖掘生成多样性的搜索信息,提高了全局搜索能力,有效克服了传统算法的局部收敛问题。
附图说明
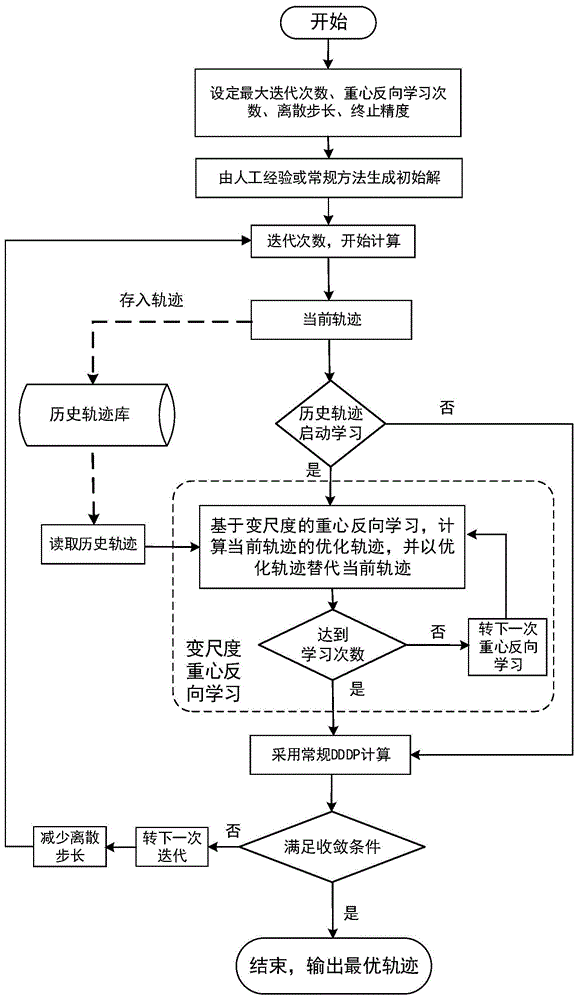
图1为本发明考虑历史轨迹知识的梯级水库群生态调度优化方法的流程图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步的详细说明。
如图1所示,如图所示,一种考虑历史轨迹知识的梯级水库群生态调度优化方法,包括如下步骤:
1)确定初始计算条件,包括梯级水库群生态调度的优化目标函数、约束条件和决策变量,
其中,梯级水库群生态调度模型可以描述为:已知各水库调度期初始水位、末水位和入库径流过程以及区间径流过程,在满足各水库相应的水位、流量等复杂约束的情况下,以梯级水库群的生态溢水量和生态缺水量之和最小为优化目标,梯级水库群生态调度目标函数的数学表达式为:
minf=minveco=min(vecoover+vecolack)
式中:veco为梯级水库群总生态溢缺水量(m3),vecoover为梯级水库群总生态溢水量(m3),vecolack为梯级水库群总生态缺水量(m3);oi,j为水库i在时段j的出库流量(m3/s),
需要满足的约束条件,主要包括:
(1)水量平衡约束:
式中,vi,j为水库i在j时段末的库容值(m3),ii,j为水库i在j时段的入库流量(m3/s);
(2)水力联系约束:
式中,ri,j为水库i在j时段的区间流量(m3/s),ui为水库i的上游水库数目,ou,j为上游水库i在j时段的出库流量(m3/s);
(3)时段水位约束:
式中,zi,j为水库i在j时段的坝前水位值(m),
(4)出库流量约束:
式中,
(5)初末水位约束:
zi,0=zi,start,zi,t=zi,end
式中,zi,star和zi,end分别为水库i的调度期初始水库水位(m)和调度期末控制水位(m);
(6)水库出力约束:
式中,pi,j为水库i在j时段的出力(kw),
(7)非负约束:各种变量均为非负值;
决策变量为水位;
2)设定计算参数,包括最大迭代次数m、最大变尺度重心反向学习次数k、各水库初始离散步长、收敛精度ε、水库数目n和调度期时段数目t;
3)采用常规动态规划方法生成满足各约束条件的各个水库的初始轨迹ω1,并将其存入历史轨迹库
4)初始化迭代次数m=1;
5)当历史轨迹库
①初始化变尺度重心反向次数k=1;
②随机生成在1到y之间的正整数y,有1≤y≤y;
③从历史轨迹库
其中,
④由重心反向原理,计算当前轨迹
⑤比较重心反向轨迹和当前轨迹,如果
⑥令k=k+1,如果k≤k,转步骤②,否则转步骤(6);
6)实施常规dddp算法,在当前轨迹的可行范围内形成一个搜索廊道,在搜索廊道内使用常规动态规划方法寻求当前最优轨迹,并将当前最优轨迹按递进顺序,存入并扩充历史轨迹库
7)算相邻两次最优轨迹各时段的水位差值,若
8)令m=m+1,若m>m,则转至步骤9),否则转至步骤5);
9)停止计算,输出最终的最优轨迹。
以我国乌江为例进行研究。乌江是长江上游右岸的最大支流,流域面积87920km2,干流全长1037km,多年平均流量1690m3/s,多年平均径流量534亿m3。现以我国乌江干流上的洪家渡、东风、索风营、乌江渡、构皮滩、彭水六座电站的梯级水库群生态调度问题为例进行研究。
选取三种来水频率(30%、50%、70%)作为实施工况,分别采用本发明方法与dddp开展梯级水库群生态调度。表1列出了本发明方法与dddp的生态溢缺水量计算结果。
表1本发明方法和dddp计算结果对比情况
计算结果表明,本发明方法相比于dddp,其优势体现在:①在所有来水情况下,本发明方法的计算结果均优于dddp,对应于三种来水频率分别提高1.0%左右,结果较为显著;②本发明方法计算时间均小于dddp,对应于三种来水频率可均减少计算时间89%左右,随着水库计算规模增加,计算性能优势更为凸显。
由此可见,本发明与已有dddp相比,在每次迭代前考虑历史轨迹知识,通过变尺度重心反向学习来优化搜索过程,不仅具有更好的全局搜索能力,而且有更高的计算效率,是一种梯级水库群生态优化调度的有效工具,对有效维持河流生态健康具有较好地决策支撑作用。
总之,梯级水库群生态调度是一个具有大规模、高维度、多阶段、强约束、非线性的复杂耦合最优控制问题,包含水位、库容、流量等众多约束条件,行之有效的高效求解面临较大的技术瓶颈。
dddp应用于该问题优化求解时,随着电站数目和离散数目增加,易陷入局部收敛。本发明充分分析了梯级水库群生态调度问题及dddp特点,在给定初始调度过程后,以离散微分动态规划方法(dddp)为基础框架,首先在每次迭代前,通过挖掘历史轨迹过程携带的知识信息,对当前轨迹进行变尺度重心反向学习,得到结果更好的优化轨迹;然后在优化轨迹的基础上进行离散迭代求解;最后通过迭代寻优逐次逼近全局最优解。本发明充分利用了历史轨迹知识信息,通过变尺度重心反向学习来挖掘生成多样性的搜索信息,提高全局搜索能力,以有效克服dddp的局部收敛问题。
- 还没有人留言评论。精彩留言会获得点赞!