一种SPARQL联合查询的数据源选择方法
本发明涉及数据库技术领域,尤其涉及一种sparql联合查询的数据源选择方法。
背景技术:
在数据源选择方法中,为了确保得到100%的召回率,大多数的sparql(全称为sparqlprotocolandrdfquerylanguage,是为rdf开发的一种查询语言和数据获取协议)查询联合方法执行三元模式的数据源选择方法(tpwss)。tpwss的目标是确保找到各个查询三元模式的相关数据源。然而,由于某个数据源的查询结果在执行和其他在相同查询中的三元模式的结果连接后可能被排除,可能造成相关的资源并不能产生完整的最终查询结果集。这些数据源的过度选择增加了网络传输负担,而且对整个查询处理时间的影响很大。基于连接的数据源选择方法旨在选择出那些对三元模式结果有贡献和得到最后查询结果的三元模式的数据源。如果通过消除不需要的资源,数据源选择做的越好那么将可以获得越有效的查询执行计划。
hibiscus是一个针对于tpwss的基于连接的数据源选择方法,该方法以只选择出导致最后查询结果集的数据源为目标提出来的。该方法依赖于包含在数据源中的权限资源uri索引,根据不同的uri进行数据源查询,然后进行剪枝。它能够删除与最后查询结果集无关的源,从而提高查询处理时间。但是当uri相同时,这种方法就失效了。
技术实现要素:
(一)要解决的技术问题
为了解决现有技术的上述问题,本发明提供一种sparql联合查询的数据源选择方法。
(二)技术方案
为了达到上述目的,本发明采用的主要技术方案包括:
一种sparql联合查询的数据源选择方法,所述方法包括:
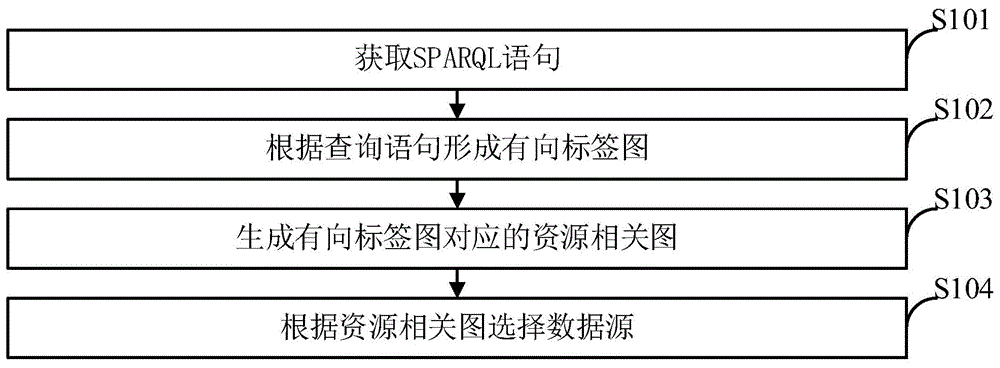
s101,获取sparql语句;
s102,根据所述查询语句形成有向标签图;
s103,生成所述有向标签图对应的资源相关图;
s104,根据所述资源相关图选择数据源。
可选地,所述s102具体包括:
s102-1,确定查询语句中的三元组gi,其中,i为三元组标识,任一三元组i包括主语si,谓语pi,宾语oi;
s102-2,将所有三元组中的主语、谓语、宾语形成集合v,并将v中每一个元素作为有向标签图g中的一个点;
s102-3,在每一三元组中si对应的点vsi至oi对应的点voi之间连接一条由vsi指向voi的边ei,将所有ei形成集合e,所述e中每一个元素作为有向标签图g中的一个边;其中,vsi为边ei的头顶点,voi为ei的尾顶点;
s102-4,确定每条边对应的数据源λei以及每两条边之间的连接节点类型λvt;
s102-5,形成有向标签图g=(v,e,λe,λvt)。
可选地,连接节点类型λvt为如下的一种:星型,路径型,汇聚型;
所述星型中两条边的头顶点相同;
所述路径型中第一边的尾顶点为第二边的头顶点;
所述汇聚型中两条边的尾顶点相同。
可选地,所述s103具体包括:
s103-1,将每个三元组gi作为资源相关图的一个点pi;
s103-2,根据三元组在所述有向标签图中对应的边之间的连接节点类型生成其在资源相关图中对应点之间的边;
其中,所述资源相关图中任一点的点属性为该点所表示的三元组在所述有向标签图中对应的边的数据源。
可选地,所述s103-2具体包括:
对于任两个三元组g1和g2,在p1和p2之间连接一条边,且该边由第一点指向第二点,该边的边属性由g1和g2在所述有向标签图中对应的边之间的连接节点类型确定;其中,p1为g1在资源相关图中对应的点,p2为g2在资源相关图中对应的点,若第一点为p1,则第二点为p2;若第一点为p2,则第二点为p1;
其中,若g1和g2在所述有向标签图中对应的边之间的连接节点类型为路径型,则第一点对应路径类型中的第一边,第二点对应路径类型中的第二边;若g1和g2在所述有向标签图中对应的边之间的连接节点类型为星型,或者,汇聚型,则第一点所对应的三元组在sparql语句中的执行顺序,先于第二点所对应的三元组在sparql语句中的执行顺序。
可选地,所述该边的边属性由g1和g2在所述有向标签图中对应的边之间的连接节点类型确定,包括:
若g1和g2在所述有向标签图中对应的边之间的连接节点类型为星型,则该边的边属性为主语-主语连接关系ss;
若g1和g2在所述有向标签图中对应的边之间的连接节点类型为路径型,则该边的边属性为宾语-主语连接关系os;
若g1和g2在所述有向标签图中对应的边之间的连接节点类型为汇聚型,则该边的边属性为宾语-宾语连接关系oo。
可选地,所述s104具体包括:
步骤1,依次选取资源相关图中的各点,执行下述1或2;
1,若选择的点存在出边,则执行下述1)至4);所述出边连接所述选择的点与第三点,且所述出边由所述选择的点指向所述第三点,第三点为所述资源相关图中的其他点;
1)获取选择的点的点属性以及对应的出边,
2)对于所述点属性中的每个数据源,设置空集合temp;
3)对于每一条出边,执行下述(1)至(4),
(1)获取其边属性及对应的第三点;
(2)获取第三点对应的点属性;
(3)确定与(1)中获得的边属性以及(2)中获得的点属性对应的资源;
(4)根据(2)中获得的点属性以及(3)中确定的资源,更新temp,重复执行(1),直至所有出边均执行3);
4)若temp为空集合,则将2)中选择的数据源,从步骤1中选择的点中移除;
2,若选择的点不存在出边,则从所述资源相关图中删除选择的点;
步骤2,根据当前资源相关图中所有点的点属性所包括的数据源选择的数据源。
可选地,所述根据(2)中获得的点属性以及(3)中确定的资源,更新temp,包括:
若根据(2)中获得的点属性中包括(3)中确定的资源,则将(2)中获得的点属性中的资源添加至temp中;或者,将(3)中确定的资源添加至temp中;或者,将(2)中获得的点属性中的资源与(3)中确定的资源的交集添加至temp中,或者,将(2)中获得的点属性中的资源与(3)中确定的资源的并集添加至temp中。
可选地,所述步骤2具体包括:
步骤2-1,确定当前资源相关图中所有点的权重;
步骤2-2,确定所有点的权重均值;
步骤2-3,确定当前资源相关图中所有点的点属性所包括的数据源的并集;
步骤2-4,确定步骤2-3得到的并集中每个元素的频次,所述任一元素的频次为,所述任一元素被包括在点属性中的总数量;
步骤2-5,根据步骤2-4确定的各元素的频次,确定频次均值和标准差;
步骤2-6,将频次不小于频次均值*标准差*权重均值的数据源作为选择的数据源。
可选地,所述步骤2-1具体包括:
对于步骤2当前资源相关图中的任一点k,
确定k的入度in1和出度out1;
确定k各出边对应的第四点;
确定各第四点的入度in2和出度out2;
确定所有in2的最大值和所有out2的最小值;
将(in1/所有in2的最大值)+(out1/所有out2的最小值)确定为k的权重。
(三)有益效果
本发明的有益效果是:根据查询语句形成有向标签图;生成有向标签图对应的资源相关图;根据资源相关图选择数据源,可以明显减少数据源选择的数量和选择时间。
附图说明
图1为本申请一实施例提供的一种sparql联合查询的数据源选择方法的流程示意图;
图2为本申请一实施例提供的一种数据集和相应的查询结果集的示意图;
图3为本申请一实施例提供的一种查询ssq1和hsq3的有向标签图示意图;
图4为本申请一实施例提供的一种星型连接节点示意图;
图5为本申请一实施例提供的一种路径型连接节点示意图;
图6为本申请一实施例提供的一种汇聚型连接节点示意图;
图7为本申请一实施例提供的一种混合型连接节点示意图;
图8为本申请一实施例提供的一种hsq3的资源相关图;
图9为本申请一实施例提供的一种fedx、lgsm和hibiscus的资源选择示意图;
图10为本申请一实施例提供的一种fedx、lgsm和hibiscus的查询运行时间示意图;
图11为本申请一实施例提供的一种splendid、lgsm和hibiscus的资源选择示意图;
图12为本申请一实施例提供的一种splendid、lgsm和hibiscus查询执行时间示意图。
具体实施方式
为了更好的解释本发明,以便于理解,下面结合附图,通过具体实施方式,对本发明作详细描述。
有效的数据源选择方法致使更多的有效查询执行计划的产生,因此它是sparql联合查询处理的一个重要优化步骤。过度选择的数据源选择方法由于检索了无关的中间结果从而增加了网络传输,从而增加了查询处理时间。基于连接的数据源选择方法针对这一问题进行了很好的改善。本发明提供了一种sparql联合查询的数据源选择方法,该方法在多个sparql端点的联合查询中使用,根据查询语句形成有向标签图;生成有向标签图对应的资源相关图;根据资源相关图选择数据源,可以明显减少数据源选择的数量和选择时间。
rdf资源通过使用uri(unifiedresourceidentifier资源统一标识符)来识别。每个uri是由统一的等级序列成分组成的语法。即:scheme,authority,path,query,andfragment。
例如,在图2中使用的前缀ns1=<http://auth1/scma/>是由schemehttp,authorityauth1,pathscma组成。在发明同时参考前两个组件(path,authority)作为uri的authority。图2中#tp表示三元模式资源选择的总数量,查询语句中数据源加粗的为最后的查询结果集,即#optimaltp.source的数量。不同类型的查询通过查询语句选择出与三元组匹配的数据集中的三元模式,从而确定相关的数据集。例如,在查询ssq1中,与三元模式<?s;cp:p1;?v1>匹配的三元组是数据集d1中的<ns1_3:s1cp:p1ns1_3:o11>和数据集d2中的<ns1_2:s1cp:p1ns2:o21>。因此查询ssq1的三元模式<?s;cp:p1;?v1>的相关数据源集是{d1,d2}。
查询rdf的标准是sparql,sparql查询的结果被称作结果集。查询结果集的每一个元素是一组绑定变量。联合sparql查询被定义为在一组数据源d={d1,…,dn}上执行的查询。给定一个sparql查询q,如果至少有一个绑定变量属于q结果集中的元素且这个元素能够在d中被找到,那么数据源d∈d被称作对q有贡献。
1、数据源
本发明中的数据源d∈d对于三元模式tpi∈tp是相关的,如果最少有一个在d中的三元组匹配tpi,其中tpi是第i个三元模式,tp是三元模式的集合,d是数据源的集合。对于tpi的相关数据源集
例如,ssq1的三元模式<?s;cp:p1;?v1>的相关数据源集是{d1,d2}。三元模式的相关数据源很可能对完整查询q的最后结果集是没有贡献的。这是因为当在查询q中执行和其他三元模式的结果连接时,来自三元模式的一个特定源d的计算结果可能被排除。例如,考虑ssq1,在执行两个三元模式的结果连接时,对于<?s;cp:p1;?v1>的结果和对于<?s;cp:p2;?v1>的结果被排除。
对于三元模式tpi∈tp,包含相关数据源集d∈ri的最佳的数据源集
通过本发明所提供的sparql联合查询的数据源选择方法,可以在给定一组数据源d和查询q,找到q的每个三元模式tpi的最佳数据源集oi∈d。
参见图1,本方案的实现过程如下。
s101,获取sparql语句。
s102,根据查询语句形成有向标签图。
具体的,
s102-1,确定查询语句中的三元组gi。
其中,i为三元组标识,任一三元组i包括主语si,谓语pi,宾语oi。
s102-2,将所有三元组中的主语、谓语、宾语形成集合v,并将v中每一个元素作为有向标签图g中的一个点。
s102-3,在每一三元组中si对应的点vsi至oi对应的点voi之间连接一条由vsi指向voi的边ei,将所有ei形成集合e,e中每一个元素作为有向标签图g中的一个边。
其中,vsi为边ei的头顶点,voi为ei的尾顶点。
连接节点类型λvt为如下的一种:星型,路径型,汇聚型。
星型中两条边的头顶点相同。
路径型中第一边的尾顶点为第二边的头顶点。
汇聚型中两条边的尾顶点相同。
s102-4,确定每条边对应的数据源λei以及每两条边之间的连接节点类型λvt。
s102-5,形成有向标签图g=(v,e,λe,λvt)。
大多数用于sparql端点联合系统的源选择方法只执行tpwss,即,他们找到查询语句的每个三元模式的相关数据源集并且不考虑最佳数据源集。本发明的方法通过删除来自每个相关数据源集的非相关数据源,得到最佳的数据源集,这种方法依赖于一个有向标签图。
sparql查询中的每个基本图模式(bgp)能够单独执行。因此,主要关注如何将单个bgp执行优化。有向标签图是bgps的合并。为了确保bgps单独处理,需要保证bgps的表示不相交,即使他们包含相同的节点。bgp的有向标签图表示被正式定义如下:
如图3所示,一个sparql查询的每一个基本图模式(bgp)能够被表达并作为有向标签图g=(v,e,λe,λvt),其中:
⑴v=vs∪vp∪vo是gi的顶点的集合。vs是gi的所有主语集合,vp是gi的所有谓语的集合,vo是gi的所有宾语的集合;
⑵
⑶λe:e→2d是一个边标签函数。给定边e∈e,它的边标签是数据源
⑷λvt是顶点类型分配函数。给定一个顶点v∈v,如果这个顶点参与了至少一个连接,那么它的顶点类型可以是星型,路径型,汇集型。星型顶点有多于一个出边并且没有入边。路径型顶点仅仅只有一个出边和入边。一个顶点如果不参与任何连接,可称作简单型。
图2中所给出的例子ssq1的有向标签图如图3(a)所示,hsq3的有向标签图如图3(b)中所示。
本发明所提供的方法可以在给定一个查询q,q表示为一组标签图{g1,…,gx}(在查询q中每个gi代表一个bgp)的情况下,找到生成一个最佳数据源的每个标签图的边标签。
对于连接节点类型λvt,为如下的一种:星型,路径型,汇聚型:
①星型连接节点:正如先前所提及,星型连接节点只有一个出边没有入边。如图4所给定的连接节点的例子,其中两个三元组通过一个共同的主语(?s1)连接。查询第一个三元组得到的结果只有数据集d1。查询第二个三元组得到的结果有数据集d1,d2和d3。把这两个三元组标记为两个新的节点。其中,将三元组?s1cp:p1?v1标记为a节点,三元组?s1cp:p0?v0标记为b节点,那么节点a和b之间是主语-主语连接关系(ss)。
②路径型连接节点:路径型连接节点包含一个入边和出边。在图5中给定的这个节点的例子中,第一个三元组的宾语(?p)用于第二个三元组的主语,因此组成了宾语-主语连接。将这两个三元组标记为两个新的节点,其中,将三元组?v2cp:p4?p标记为节点a,将三元组?pcp:p3?v1标记为节点b,那么节点a和b之间是宾语-主语连接关系(os)。
③汇聚型的连接节点:汇聚型的连接节点仅仅包含入边并且不包含出边。图6描述了汇聚型连接节点的例子。汇聚型连接节点作为两个三元组之间的宾语-宾语连接的一个结果被创建。将三元组?v1cp:p6?s标记为节点a,将三元组?v2cp:p2?s标记为节点b,那么节点a和b之间是宾语-宾语连接关系(oo)。
对于多个点组成的图,其可能构成为混合型。
④混合型连接节点:至少包括一个出边和多于一个的入边或者一个入边和多于一个的出边的节点被称作混合节点。图7描述了混合节点。一个混合节点是汇聚型,路径型和星型查询的组合。将三元组?v1cp:p6?h标记为节点a,将三元组ns4:s2cp:p2?h标记为节点b,将三元组?hcp:p7?v2标记为节点c。那么节点a和b是宾语-宾语连接关系(oo),节点a和c是宾语-主语连接关系(os),节点b和节点c是宾语-主语关系(os)。
s103,生成有向标签图对应的资源相关图。
具体的,
s103-1,将每个三元组gi作为资源相关图的一个点pi。
s103-2,根据三元组在有向标签图中对应的边之间的连接节点类型生成其在资源相关图中对应点之间的边。
其中,资源相关图中任一点的点属性为该点所表示的三元组在有向标签图中对应的边的数据源。
如,对于任两个三元组g1和g2,在p1和p2之间连接一条边,且该边由第一点指向第二点,该边的边属性由g1和g2在有向标签图中对应的边之间的连接节点类型确定。其中,p1为g1在资源相关图中对应的点,p2为g2在资源相关图中对应的点,若第一点为p1,则第二点为p2。若第一点为p2,则第二点为p1。
其中,若g1和g2在有向标签图中对应的边之间的连接节点类型为路径型,则第一点对应路径类型中的第一边,第二点对应路径类型中的第二边。若g1和g2在有向标签图中对应的边之间的连接节点类型为星型,或者,汇聚型,则第一点所对应的三元组在sparql语句中的执行顺序,先于第二点所对应的三元组在sparql语句中的执行顺序。
本步骤中该边的边属性由g1和g2在有向标签图中对应的边之间的连接节点类型确定的具体实现过程如下:
若g1和g2在有向标签图中对应的边之间的连接节点类型为星型,则该边的边属性为主语-主语连接关系ss。
若g1和g2在有向标签图中对应的边之间的连接节点类型为路径型,则该边的边属性为宾语-主语连接关系os。
若g1和g2在有向标签图中对应的边之间的连接节点类型为汇聚型,则该边的边属性为宾语-宾语连接关系oo。
由上述的几种查询类型的例子可知,将图中的每个三元组标记为节点后,各个节点之间存在着主语-主语,主语-宾语,宾语-宾语连接关系。本步骤可以将图3所示的标签图简化成基于节点的资源相关图(srg)。其中把图中的各个三元组进行标记,如表1所示:
表1hsq3查询例子
根据表1,得到的资源相关图如图8所示:
s104,根据资源相关图选择数据源。
具体的,
步骤1,依次选取资源相关图中的各点,执行下述1或2。
1,若选择的点存在出边,则执行下述1)至4)。出边连接选择的点与第三点,且出边由选择的点指向第三点,第三点为资源相关图中的其他点。
1)获取选择的点的点属性以及对应的出边,
2)对于点属性中的每个数据源,设置空集合temp。
3)对于每一条出边,执行下述(1)至(4),
(1)获取其边属性及对应的第三点。
(2)获取第三点对应的点属性。
(3)确定与(1)中获得的边属性以及(2)中获得的点属性对应的资源。
(4)根据(2)中获得的点属性以及(3)中确定的资源,更新temp,重复执行(1),直至所有出边均执行3)。
更新temp的方案为:若根据(2)中获得的点属性中包括(3)中确定的资源,则将(2)中获得的点属性中的资源添加至temp中。或者,将(3)中确定的资源添加至temp中。或者,将(2)中获得的点属性中的资源与(3)中确定的资源的交集添加至temp中,或者,将(2)中获得的点属性中的资源与(3)中确定的资源的并集添加至temp中。
4)若temp为空集合,则将2)中选择的数据源,从步骤1中选择的点中移除。
2,若选择的点不存在出边,则从资源相关图中删除选择的点。
步骤2,根据当前资源相关图中所有点的点属性所包括的数据源选择的数据源。
步骤2具体包括:
步骤2-1,确定当前资源相关图中所有点的权重。
其中权重确定方案为:
对于步骤2当前资源相关图中的任一点k,
确定k的入度in1和出度out1。
确定k各出边对应的第四点。
确定各第四点的入度in2和出度out2。
确定所有in2的最大值和所有out2的最小值。
将(in1/所有in2的最大值)+(out1/所有out2的最小值)确定为k的权重。
通过权重可以体现资源相关图中各点入度与出度之间的关系,入度多,出度少的点更加重要。
步骤2-2,确定所有点的权重均值。
步骤2-3,确定当前资源相关图中所有点的点属性所包括的数据源的并集。
步骤2-4,确定步骤2-3得到的并集中每个元素的频次,任一元素的频次为,任一元素被包括在点属性中的总数量。
步骤2-5,根据步骤2-4确定的各元素的频次,确定频次均值和标准差。
步骤2-6,将频次不小于频次均值*标准差*权重均值的数据源作为选择的数据源。
通过频次可以在所有点对应的数据源中,选择被更多个点所对应的数据源作为最终选择的数据源,提升了数据源选择的准确性,以及选择效率。
如图8所示,hsq3的资源相关图是一有向图。用pi表示资源相关图的节点。那么图8的五个节点分别表示为p1p2,p3,p4,p5,且这五个节点是有顺序的。每个节点至少有一个数据源,而这些数据源并不是都能得到最后的查询结果。
在具体实现时,可以通过如下的算法实现本发明提供的sparql联合查询的数据源选择方法。
上述算法通过将一个三元组连接到其他三元组检查这个三元组是否对结果有贡献从而判断三元组的每个相关数据源(行1-19);如果三元组的相关数据源的所有检测结果均不为真,那么删除来自三元组的相关数据源的数据源(行15-17)。如果通过连接一个数据源上的三元组发现没有其他三元组产生结果,那么删除来自三元组相关的数据源集(21-22)。本发明所提供的方法,将关联数据中的主语-主语,主语-宾语和宾语-宾语的连接信息存储在索引结构中,并且将绑定主语、宾语的类和三元模式的绑定宾语相互关联,用这种方法选择相关的数据源集。
本发明所提供的方法进行了fedbench数据集的评估。选择来自fedbench基准上的跨领域(crossdomain,cd)和生命科学领域(lifescience,ls)的数据集合。查询关注多个数据源上的查询处理和不同的连接复杂性,查询结果集大小以及所涉及的数据源的数量和查询结构(即,星型,链型或混合型)等相关方面。表2提出了fedbench基准测试查询语句特征信息。在这两个场景中使用的数据源是lod的一部分。表3示出了fedbench数据集,在fedbench项目中提供了数据集的详细信息和多个先进的统计数据。
表2
表3
由于国内防火墙的限制和网络延迟,访问远程sparql端点很困难。因此将基准测试所需要的数据集全部下载到一个独立的物理virtuoso服务器。所有的实验是在一个内存8g的计算机上进行的,inter(r)core(tm)i3-3110mcpu2.04ghz,系统使用ubunto10.04和64位javavm1.7.0_75。本实验是在本地网络上运行的,因此网络传输代价可以忽略不计。
实验时,将发明的sparql联合查询的数据源选择方法表示为lgsm,将lgsm用到fedx和splendid两个联合查询系统上面,并和原来的fedx和splendid进行结果对比。特别地,也和hibiscus这个数据源选择方法进行对比来验证性能。实验结果分别如图9和图10所示。对于每一个查询,测量指标是:(1)数据源选择的个数,(2)数据源选择时间(msec)。每一组fedbench查询执行5次,结果取平均值。其中,s代表fedx的原始数据源选择个数;us代表fedx应用本文所提方法后的数据源选择个数;hs代表hibiscus方法的数据源选择个数。et代表原联合查询系统查询运行时间;et*代表改进后的系统查询运行时间,ht代表hibiscus方法的系统查询运行时间。
对于在fedx查询系统上进行的实验,实验结果如图9中所示,使用lgsm后,在跨领域和生命科学领域中,除了cd2,ls1,ls4得到选择的数据源的个数持平,在其他部分与最后查询结果无关的资源选择数量都大大减少了。在查询运行时间方面,实验结果如图10中所示,lgsm的使用除了在ls6上查询时间因为过长而人为终止,运行时间没有报告以外,其他运行时间都有所减少。与hibiscus对比,查询运行时间也有所减少。因此lgsm整体上提高了查询性能。
对于在splendid系统上进行的实验对比,实验结果如图11所示,将基于连接和图的数据源选择方法应用于系统后,除了部分得到的选择资源个数与原系统相同以外,其他资源选择个数都比原系统所得选择个数少。与hibiscus对比,在数据源选择个数方面只有在ls5和ls7中明显地减少,其他都持平。但是如图12所示,改进后的系统的查询执行时间明显比splendid系统的执行时间快。而与hibiscus对比,只有在cd1、cd3、cd6,ls5上的运行时间比hibiscus的运行时间少,通过对比,在数据源选择和运行时间方面,基于连接和图的源选择方法在ls5都有明显的改善,可以看出运行时间和数据源减少有很大的关系。基于连接和图的源选择方法在splendid上的查询执行时间比fedx上更加明显地显示出了优势。因此有效地源选择是整个联合查询优化的关键因素之一。
有益效果:根据查询语句形成有向标签图;生成有向标签图对应的资源相关图;根据资源相关图选择数据源,可以明显减少数据源选择的数量和选择时间。
需要明确的是,本发明并不局限于上文所描述并在图中示出的特定配置和处理。为了简明起见,这里省略了对已知方法的详细描述。在上述实施例中,描述和示出了若干具体的步骤作为示例。但是,本发明的方法过程并不限于所描述和示出的具体步骤,本领域的技术人员可以在领会本发明的精神后,作出各种改变、修改和添加,或者改变步骤之间的顺序。
还需要说明的是,本发明中提及的示例性实施例,基于一系列的步骤或者装置描述一些方法或系统。但是,本发明不局限于上述步骤的顺序,也就是说,可以按照实施例中提及的顺序执行步骤,也可以不同于实施例中的顺序,或者若干步骤同时执行。
最后应说明的是:以上所述的各实施例仅用于说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或全部技术特征进行等同替换;而这些修改或替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!