基于神经网络敏感性分析的微表情识别方法
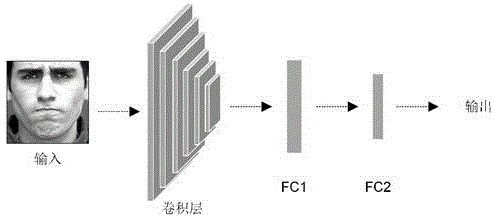
本发明属于计算机图像处理
技术领域:
,涉及一种基于神经网络敏感性分析的微表情识别方法。
背景技术:
:微表情是人类面部肌肉的细微而短暂的动作,当一个人试图隐藏他或她的真实情绪时,这些微表情会不由自主地发生。与传统的宏表情相比,微表情识别在刑事审讯、国土安全和心理治疗等领域存在着巨大的潜力。因此,近年来科研人员对微表情的研究兴趣迅速增加。然而,无论是人工识别微表情还是自动识别微表情,微表情低强度和短持续时间的特性仍然是微表情识别面临的主要挑战。在当前的机器学习方法中,视频中微表情判别方法多基于连续帧的微表情,根据其变化幅度提取相应特征并进行判别,比如光流法和局部二值模式法。其中,光流法通过检测帧与帧之间像素的变化来测量亮度的变化,进而对微表情进行辨别。使用神经网络对微表情进行判别的过程中,在每一层都会提取到不同层次的人脸特征。然而,在之前的基于深度学习的微表情识别方法中,很少有将低层次的有效特征和高层次的特征进行结合并进行综合判别。技术实现要素:本发明针对现有技术的不足,提供了一种基于神经网络敏感性分析的微表情识别方法,该方法在微表情识别应用上具有高精度的特点。本发明具体是:步骤s1:设计一个常规的包含9层卷积层以及1层全连接层(fc1)和1层logit层(全连接层fc2)的卷积神经网络结构(详见表1)。表1步骤s1中基础网络结构及参数设置阶段层输入格式步长通道数1conv4×4224×2242322conv3×3112×1121643conv3×3&pooling110×11011284conv3×355×5512565conv3×355×5522566conv3×3&pooling28×2812567conv3×314×1415128conv3×314×1415129conv3×3&pooling14×14151210fc1&dropout7×7×512-102411fc21024-nclasses步骤s2:选择imagenet数据库中的前200类事物在步骤s1中的卷积神经网络进行训练,得到网络模型。步骤s3:选择宏表情数据集ck+对由步骤s2得到的网络模型进行迁移学习,并得到相应的网络模型。具体地,本发明在步骤s3中的迁移学习时,冻结了步骤s2得到的网络模型前6层的参数。同时,由于步骤s2中需要分成200类,而步骤s3中ck+仅有7类,步骤s3中卷积神经网络最后一层的全连接层神经元个数也由200个修改为7个。步骤s4:使用神经网络敏感性分析工具testingwithconceptactivationvectors(tcav)对步骤s3得到的网络模型每一层进行敏感性测试。具体地,本发明在步骤s4中根据人脸肌肉将人脸分成数个感兴趣区域,并将这些区域作为测试样例对神经网络模型进行敏感性测试。步骤s5:根据步骤s4中得到的敏感性测试结果,对步骤s3中的神经网络进行修改。具体地,将对人脸感兴趣区域敏感性评分最高的层的输出结果分流到一个新的分支中。该分支包含一层卷积层以及一层全连接层。并将该分支的全连接层与原本网络结构的全连接层进行拼接,并在其后添加一个分类器(logit层,图5的fc2)。即,将神经网络浅层的低级特征与深层的高级特征进行融合,联合判别微表情。这个添加了分支的网络结构即为最终的神经网络结构。具体地,浅层的低级特征指神经网络前几层提取到的图像信息,通常为点、线、纹理以及颜色等信息。深层高级特征指神经网络后几层提取到的信息。在步骤s5中,高级特征为嘴角、鼻翼等高阶的概念。步骤s6:根据步骤s5中得到的最终神经网络结构在微表情数据库上进行迁移学习,得到最终的网络模型。具体地,步骤s6中使用的数据库是由casmeⅱ、smic、samm数据库中选择68个测试人员的微表情图片组成的联合数据库。该联合数据库的所有微表情被明确地分成3种类别,分别是积极的、消极的以及惊讶的。具体地,本发明在步骤s6中进行迁移学习时,锁定了由步骤s3中得到的前10层的参数(详见表1),仅对步骤s5中添加的分支以及全连接层进行训练。具体地,本发明在步骤s6中进行训练时使用了留一验证法准则(loso)进行试验。对于联合数据库中68个测试人员,每次选择1位测试人员所有的微表情图片作为测试集,其他67个测试人员所有的微表情图片作为训练集进行训练。如此操作分别进行68次,即每位测试人员的微表情图片都作为测试集并得到一个独立的网络模型。最终得到68个网络模型以及对应的68个测试结果。具体地,对于68个测试结果,分别统计其uar值和uf1值,得到最终结果。本发明的有益效果:本发明运用神经网络敏感性分析技术对训练好的神经网络模型进行量化分析,并根据结果对神经网络结构进行修改,运用特征融合技术将敏感性高即作用大的浅层的低级特征与深层的高级特征进行融合,提高了微表情识别准确率。附图说明图1表示步骤s1中的神经网络结构。图2表示人脸感兴趣区域划分。图3表示使用敏感性分析工具tcav计算原理。图4表示使用敏感性分析工具tcav得到的结果。图5表示步骤s5中得到的神经网络的结构。具体实施方式下面将结合附图对本发明加以详细说明,应指出的是,所描述的实施例仅旨在便于对本发明的理解,而对其不起任何限定作用。图1表示步骤s1中的神经网络结构。首先,设计了一个常规的9层神经网络结构。本发明在第一阶段使用imagenet数据集进行训练及测试。由于第一阶段的训练只需关注纹理特征、颜色特征等浅层特征,本发明中选取imagenet的前200个类进行训练和测试。训练时采用了初始学习率为3e-4的adam优化器进行优化。优化时使用的损失函数公式为:其中,l表示损失值,n表示类别总数,yic表示样本i的指示变量,如果类别c和样本i的类别相同就是1,否则是0,pic表示预测样本i属于类别c的概率。经过100个迭代的训练,top-1和top-5的错误率分别为32.50%和12.35%。具体地,top-1和top-5为imagenet大赛的评价指标。其中,top-1表示样本实际标签与神经网络预测结果相同,top-5表示样本实际标签在神经网络预测概率最高的前5个结果之中。由于宏表情比微表情更容易识别,因此本发明中首先使用扩展的cohn-kanade数据库(ck+)对模型进行微调。ck+数据库包括了123个对象的593个图像序列,其中327个序列用情感标签标记。除了中性标签外,ck+还有7种情绪类别:生气、蔑视、厌恶、害怕、快乐、伤心和惊讶。本发明中将每个有表情标签的序列的最后4帧提取出来,并按照9:1的比例划分为训练集和测试集。此外,训练集中的受试者将不会被选入到测试集中,即,避免相似人脸存在的干扰。对于训练集,使用诸如旋转和翻转之类的数据增强技术获得总共4113张图片。然后,锁定步骤s2得到的网络模型的前6层参数,并从第7层卷积层开始进行微调。在此步骤中,adam优化器的初始学习率被设置为3e-4,批大小(batchsize)为16。准确率最终达到100%。图2表示人脸感兴趣区域的划分情况,这些感兴趣区域被手工从与表情无关的imdb-wiki数据库中截取出来。在步骤s4中,这些感兴趣区域的图片被输入到tcav中以进行敏感性分析。根据相关文献所示,以人脸动作单元为基础的人脸感兴趣区域在人脸表情识别中起到重要作用。因此,量化地研究人脸感兴趣区域在神经网络中的敏感度对于研究如何使用神经网络进行微表情判别有重要作用。如图2所示,人脸感兴趣区域分为6组:r1-r6。需要注意的是,由于部分人脸动作单元有重叠区域,所以本发明中截取的人脸感兴趣区域并不严格地对应于相应的人脸动作单元。在截取人脸感兴趣区域图像时基于人脸感兴趣区域的中心近似裁剪,最后将截取到的人脸感兴趣区域图片缩放到神经网络输入层的大小,在本发明中即为224×224。需要注意的是,本发明讲的“并不严格对应”指:当人脸表情动作幅度大或者人脸有点倾斜时,由于感兴趣区域使用矩形框截取,因此人脸感兴趣区域之间可能存在重叠关系。具体地,在从数据库中截取人脸感兴趣区域时,为保证tcav测试的准确性,本发明只选择高分辨率的原始图片,同时均匀多样地选择样本。例如,选择的样本有不同的肤色以及感兴趣区域有不同的角度等。图3表示使用敏感性分析工具tcav计算原理。在本发明中,tcav被用来检测感兴趣区域在神经网络每一层中的敏感性。当卷积神经网络模型对不同的输入样本进行分类时,在该模型内部的隐藏层中会产生不同的激活向量,即每个神经元有不同的激活值。tcav中,cav表示一个隐藏层激活值超平面的法向量。此激活空间是通过输入一组特定感兴趣区域图片和随机概念的图片,并分别收集某一特定隐藏层的激活值获得的。这个超平面的法向量将目标概念的激活向量和随机概念的激活向量(如图3中的鸟、灯和鳄鱼等)分开。对于某一类人脸表情的识别,人脸感兴趣区域概念的敏感性可以通过计算在特定隐藏层激活空间内法向量方向上的变化来获得,其公式如下所示:其中sc,k,l(x)表示样本x被网络模型判定为类别k时,概念c在模型第l层的方向导数,即cav,由支持向量机(svm)得到。表示概念c在模型第l层的激活向量,fl(x)表示输入样本x在第l层的激活值,hl,k(fl(x))表示输入样本x在神经网络logit层的激活值。最后,tcav计算全部的cav值,并通过以下公式计算tcav分数:其中,xk表示标签为k的所有输入样本的集合。tcavc,k,l范围为0-1,且tcavc,k,l值越大,敏感性越高。值得注意的是,如果目标概念与随机概念的tcavc,k,l的方差齐性p-value大于0.05,则认为在判断类别为k的样本时概念c在网络模型第l层并不敏感,则此时tcavc,k,l=0。具体地,在本发明中,tcav分数越高代表在该层激活空间中,输入的概念对该类别的人脸表情的判断起较重要的作用。图4表示使用敏感性分析工具tcav得到的结果。在图4中一共有8个柱形图,其中前7个柱形图中的每一张柱形图分别对应于ck+中的一个特定情绪。在每个柱形图中,水平坐标有6组(r1-r6,代表第1-6个人脸感兴趣区域),每组中的7列表示感兴趣区域对于此柱状图代表的表情在卷积层conv2-conv8(对应表1中的第2卷积层至第8卷积层)的tcav分数。最后一张柱形图显示了tcav的平均得分。从结果可以看出,大多数cav测试在第3卷积层(conv3)上得到高分。例如,在“厌恶”(disgust)子图中,所有的人脸感兴趣区域概念都返回相当高的tcav分数,表示在判断“厌恶”这个概念时,在神经网络第3卷积层(conv3)对人脸感兴趣区域的敏感性很高。从最后一个柱状图可以看到,对于全部感兴趣区域,第3卷积层(conv3)的tcav平均分数最高,为0.60,而第8卷积层(conv8)的tcav平均分数仅为0.06。因此,可以推断第3卷积层是神经网络在判断人脸表情时,对人脸感兴趣区域最敏感的层。换句话说,第3卷积层的激活空间中包含了最丰富的人脸感兴趣区域的信息。根据此结果,本发明通过提取第3卷积层的激活值并与原神经网络的高级特征融合来提高人脸感兴趣区域的作用,进而提高微表情识别准确率。特征融合的公式如下:ycat=concatenate(yfc-1,yfc-fe)(4)其中,ycat∈r1024+32表示特征融合拼接的全连接层,r1024+32表示该层神经元个数,yfc-1∈r1024表示步骤s3中神经网络第1层全连接层的输出,r1024表示该全连接层的神经元个数,yfc-fe∈r32表示步骤s5提出的特征提取分支的全连接层输出,r32表示该部分的神经元个数。图5表示步骤s5中得到的神经网络的结构,在神经网络训练中,融合不同尺度的特征是一个有用的手段。低层的特征分辨率较高,包含更多位置、纹理等信息。但由于经过的卷积更少,低层的特征表达的语义信息更少,噪声更多。相比之下,高层特征具有更多的语义信息。因此,将低层特征和高层特征进行高效的融合能有效地改善神经网络识别性能。本发明使用该神经网络在联合数据库上进行loso训练得到68个测试对象的结果。在本发明中,使用uf1和uar来评价神经网络模型。uf1被广泛用于评估不平衡的多类模型,因为它为所有类提供了相等的权重。为了计算uf1,首先应该获得68次测试中每个类的真阳性(tpc)、假阳性(fpc)和假阴性(fnc)。其中,真阳性表示神经网络预测结果与测试集实际标签相同,都为某一类c。假阳性表示神经网络预测结果为某一类c,而实际标签为其他类。假阴性表示神经网络预测结果不为某一类c而实际标签为该类。每个类的f1分数(f1c)和uf1可以通过以下公式计算:其中,n为类别总数。uar分数也被称为平均准确度,它可以通过以下公式计算:其中,n为类别总数,nc表示真实标签第c类的样本总数。实验结果为表明本发明方法具有更高的微表情识别准确率,特将本发明与其他方法在由casmeⅱ、smic、samm数据集组成的联合数据集上进行测试比较,比较结果如表2所示。表中的其他方法引用文献如下:[1]zhao,g.,pietikainen,m.:dynamictexturerecognitionusinglocalbinarypatternswithanapplicationtofacialexpressions.ieeetransactionsonpatternanalysisandmachineintelligence.29(6),915–928(2007)[2]liong,s.t.,see,j.,wong,k.,phan,r.c.w.:lessismore:micro-expressionrecognitionfromvideousingapexframe.signalprocessing:imagecommunication.62,82-92(2018)[3]gan,y.s.,liong,s.t.,yau,w.c.,huang,y.c.,tan,l.k.:off-apexnetonmicro-expressionrecognitionsystem.signalprocessing:imagecommunication.74,129-139(2019)[4]vanquang,n.,chun,j.,tokuyama,t.:capsulenetformicro-expressionrecognition.in:ieeeinternationalconferenceonautomaticface&gesturerecognition(fg2019),pp.1-7(2019)[5]zhou,l.,mao,q.,xue,l.:dual-inceptionnetworkforcross-databasemicro-expressionrecognition.in:ieeeinternationalconferenceonautomaticface&gesturerecognition(fg2019),pp.1-5(2019)[6]liong,s.t.,gan,y.s.,see,j.,khor,h.q.,huang,y.c.:shallowtriplestreamthree-dimensionalcnn(ststnet)formicro-expressionrecognition.in:ieeeinternationalconferenceonautomaticface&gesturerecognition(fg2019),pp.1-5(2019)[7]liu,y.,du,h.,zheng,l.,gedeon,t.:aneuralmicro-expressionrecognizer.in:ieeeinternationalconferenceonautomaticface&gesturerecognition(fg2019),pp.1-4(2019)表2联合数据集上各种方法结果比较从表中可以看到,采用本发明提出的方法,在由casmeⅱ、smic、samm数据集组成的联合数据集上均有效地提高了微表情识别的uf1值和uar值,达到当前最佳识别结果。综上,本发明使用迁移学习技术进行预训练,并利用tcav工具对神经网络进行敏感性分析,根据敏感性分析结果进行特征融合的迁移学习。上述的实验结果表明,本发明提出的方法能提高特征融合的效率并能较大地提高微表情识别的准确率。前面已经具体描述了本发明的实施方案,应当理解,对于一个具有本
技术领域:
的普通技能的人,不在背离本发明的范围的情况下,在上述的和在附加的权利要求中特别提出的本发明的范围内进行变化和调整能同样达到本发明的目的。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1